
이번에도 한기영 강사님께 일주일간 딥러닝을 배웠다
정말 이해하기 쉽고 친절하게 자세히 알려주셨다.
1. 모델과 모델링
Model
- 데이터로부터 패턴을 찾아, 수학식으로 정리해 놓은 것
모델링
- 가능한 한 오차가 적은 모델을 만드는 과정
모델의 목적
- 샘플을 가지고 전체를 추정
최적의 모델
- 가능한 한 오차가 가장 작은 모델
2. 딥러닝
- 머신러닝의 한 분야로, 데이터를 통해 컴퓨터가 패턴을 학습하고 예측을 수행할 수 있도록 하는 기술
- 다층 신경망을 사용해 복잡한 데이터의 특징을 자동으로 학습함
2.1 학습 방법
- NAN 조치
- 가변수화
- 스케일링
- 모델 구조 + 컴파일
- 학습 + 학습곡선
- 예측 및 검증
2.2. 딥러닝 개념 - 가중치 조정
- 아래 단계를 반복
- 조금씩 weight를 조정
- 오차가 들어드는 지 확인
- 언제까지?
- 지정한 횟수까지
- 혹은 더이상 오차가 줄지 않을때까지
학습한다는 것은 = 오차를 최소화하는 파라미터 값을 찾는다는 의미
: 모델링의 목표
2.3 학습 절차
model.fit(x_train,y_train) 하는 순간
- 가중치에 값 할당
- 예측 결과 뽑기
- 오차 계산
- 오차를 줄이는 방법으로 가중치 조정 (Optimizer : Adam)
- 다시 1단계로 돌아가 반복 (오차 변동이 거의 없으면 끝)
3. 딥러닝 모델링 - Regression
- 딥러닝은 스케일링을 필요로 함
- 방법 1. Normalization(정규화)
- 모든 값의 범위를 0~1로 변환
- 방법 2. Standardization(표준화)
- 모든 값을 평균=0, 표준편차=1
- 방법 1. Normalization(정규화)
#스케일러 선언
scaler=MinMaxScaler()
#train 셋으로 fitting 적용
x_train=scaler.fit_transform(x_train_
#validation 셋은 적용만!
x_val=scaler.transform(x_val)3.1 딥러닝-Dense
Input :Input(shape=( , ))
- 분석 단위에 대한 shape
- 1차원 : (feature 수, )
- 2차원 : (rows,cols)
Output : Dense()
- 예측 결과가 1개 변수
#메모리 정리
clear_session()
#Sequential 타입
model=Sequential([Input(shape=(nfeatures,)),
Dense(1)])3.2 딥러닝-Compile
-
선언된 모델에 대해 몇가지 설정한 후 컴퓨터가 이해할 수 있는 형태로 변환하는 작업
-
loss function
- 오차 계산을 무엇으로 할 지 결정
- 회귀 모델 : mse
- 분류 모델 : cross entropy
-
Optimizer
- 오차를 최소화하도록 가중치를 업데이트하는 역할
- Adam : 최근 딥러닝에서 가장 성능이 좋은 Optimizer로 평가
- learning_rate : 업데이트 할 비율
3.3 딥러닝 - 학습
- Epoch 반복 횟수
- 주어진 train set을 몇 번 반복 학습할지 결정
- 반복해서 학습하면서 최적의 가중치를 찾음
- 최적의 epoch 값은 케이스마다 다름
- validation split=0.2
- train 데이터에서 20%를 검증셋으로 분리
- batch size
- 배치 단위로 학습, 기본값 32
- 전체 데이터를 적절히 나눠서
- .history
- 학습을 수행하는 과정 중에
- 가중치가 업데이트 되면서
- 학습 시 계산된 오차 기록
- 그것을 저장 후 차트 그리기
history=model.fit(x_train,y_train,epochs=20,validation_split=.2).history
3.4 학습 곡선
- 모델 학습이 잘 되었는지 파악하기 위한 그래프
- 정답은 아니지만, 학습 경향을 파악하는데 유용
- 각 epoch 마다 train error와 val error가 어떻게 줄어들고 있는지 확인
바람직한 학습 곡선
-
초기에 epoch에서는 오차가 크게 줄고
-
오차 하락이 꺾이면서
-
점차 완만해짐
-
학습곡선의 모양새는 다양함
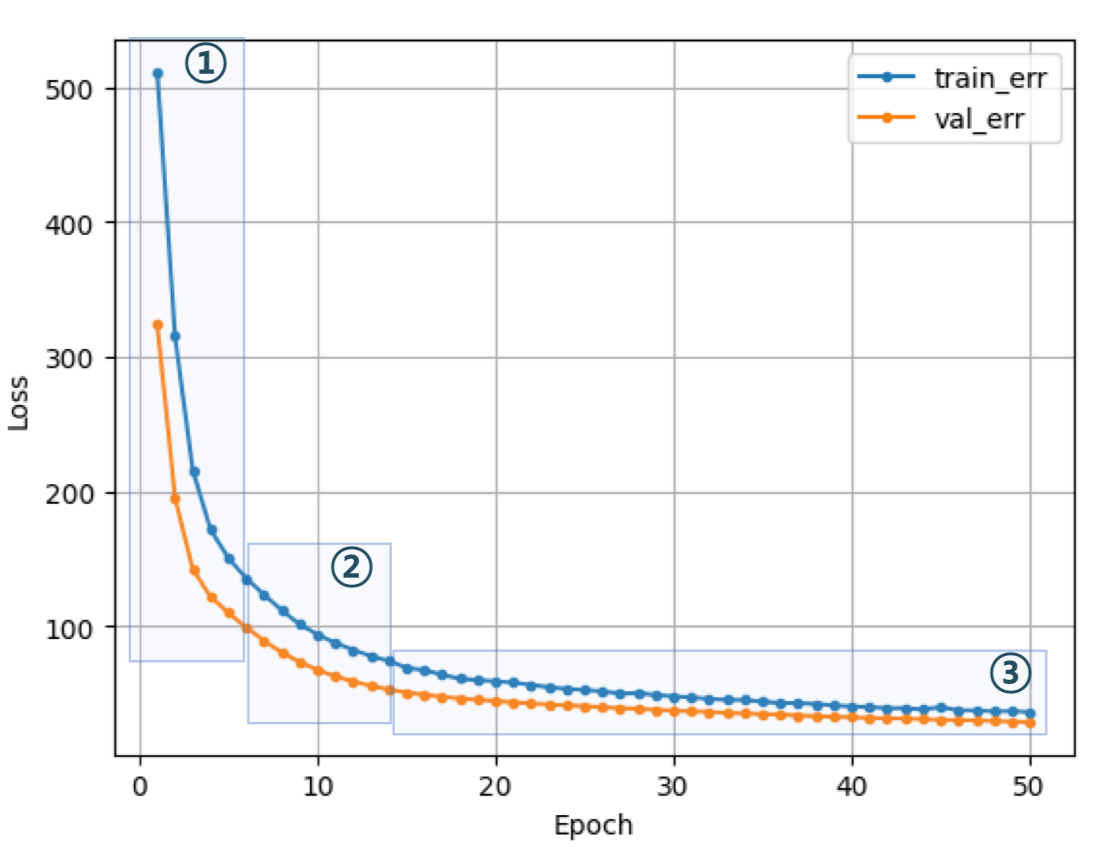
바람직하지 않은 학습 곡선
1. 학습이 덜 됨
- 오차가 줄어들다가 학습이 끝남
- 조치 : 학습을 더!
- epoch 수를 늘리거나
- learning rate을 크게 한다
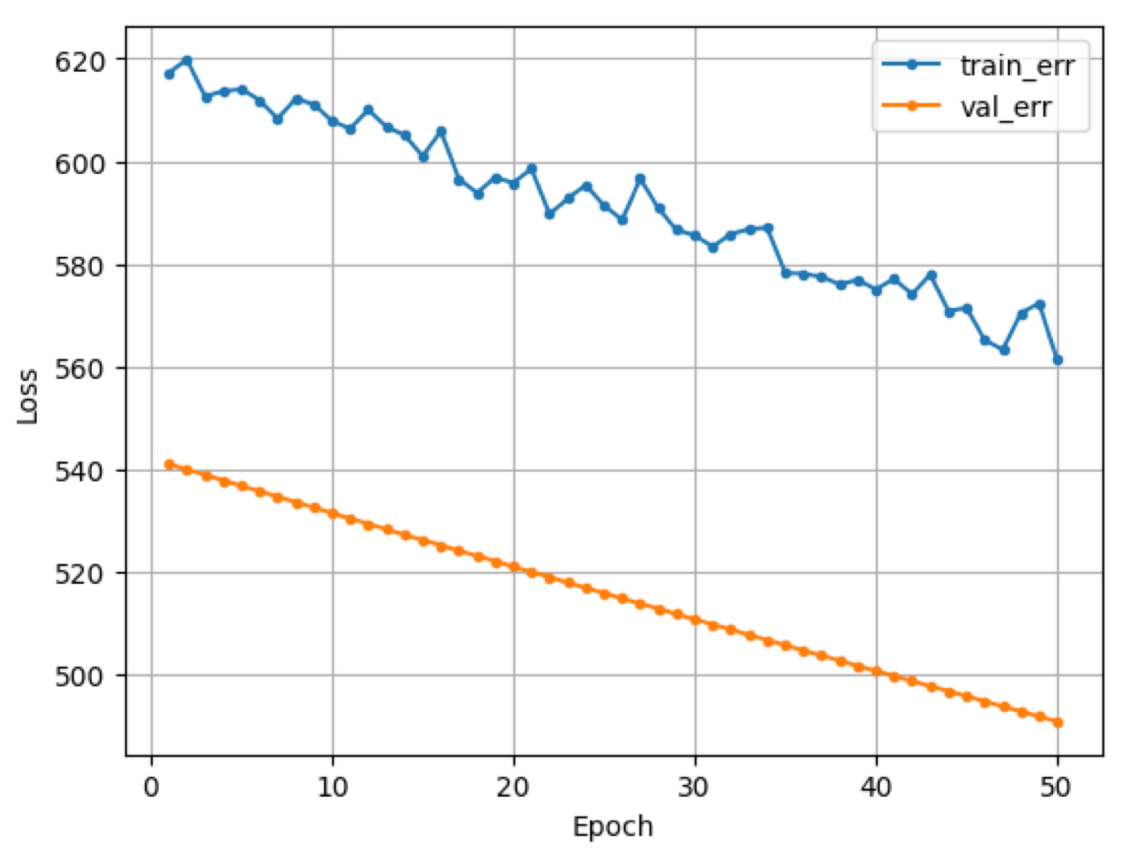
2.train err가 들쭉날쭉
- 가중치 조정이 세밀하지 않음
- 조치 : 조금씩 업데이트
- learning rate을 작게
- learning rate을 작게
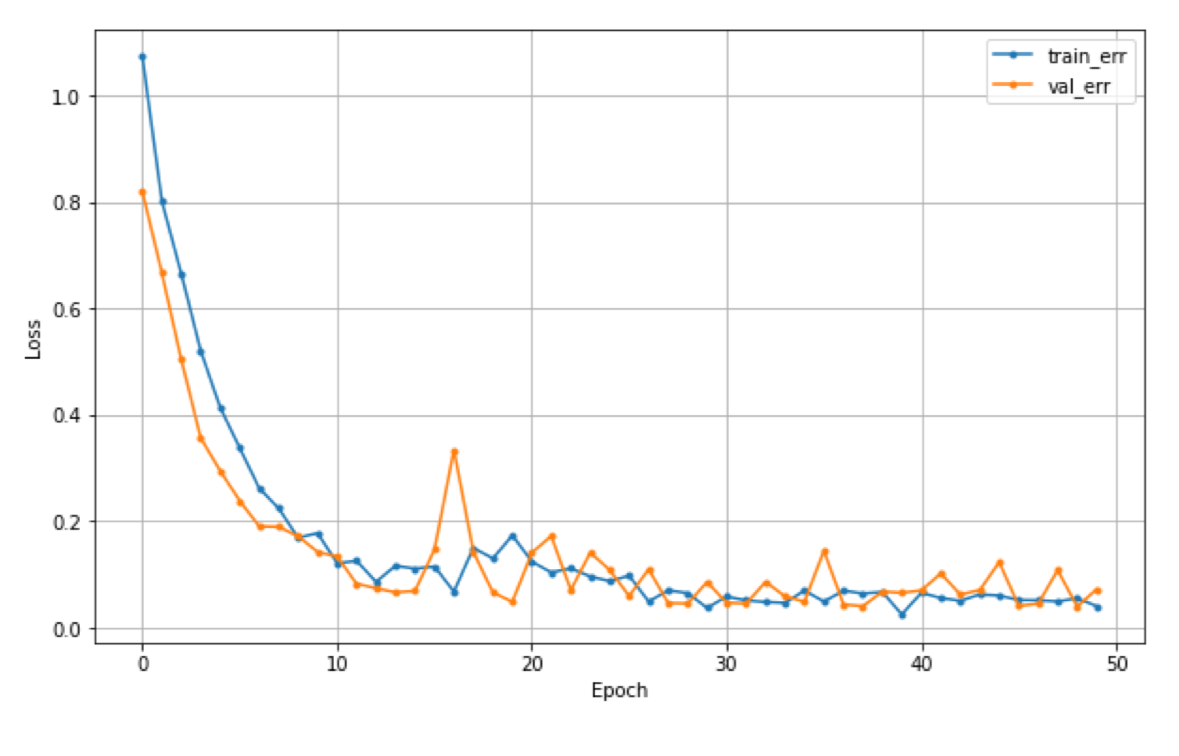
3. 과적합
- Train error는 계속 줄어드는데 val_error는 어느 순간 커지기 시작
- 너무 과도하게 학습이 된 경우
- 조치 : epoch 줄이기
3.5 Hidden layer
- Activation : 활성화 함수는 보통 relu 사용
model3=Sequential([Input(shape=(nfeatures,)),Dense(2,activation='relu'),Dense(1)])- 보통 점차 줄여감 하지만 !! 정답이라는 것은 없다
3.6 활성화 함수
- 현재 레이어의 결과값을 다음 레이어로 어떻게 전달할지 결정/변환해주는 함수
- 활성화 함수 없이 히든 레이어를 추가하면 그냥 선형회귀 모델
- Hidden Layer 에서는 선형함수를 비선형 함수로 변환
- Output Layer에서는 결과값을 다른 값으로 변환해주는 역할
- 주로 분류 모델에서 필요
4. Feature Representation
4.1 Hidden Layer에서는 무슨 일이 일어나는가?
- 연결
- 모든 노드 간에 연결을 할 수 있지만, 연결을 제어할 수도 있다
- 학습
- 예측 값과 실제 값을 비교하며, loss function으로 오차를 계산하고
- 오차를 줄이기 위해, 파라미터(가중치)를 업데이트!
- 오차를 최소화하는 파라미터 찾음
- 뭔가 새로운 특징을 만들어냄
- 그 특징은 분명이 예측된 값과 실제 값 사이의 오차를 최소화해주는 유익한 특징
- Hidden Layerdㅔ서는 기존 데이터가 새롭게 표현됨! 이것이 Feature Engineering
5. 딥러닝 모델링 - 이진분류
- Node의 결과를 변화해주는 함수가 필요 : 활성 함수
- 이진 분류에서 사용되는 loss function : binary crossentropy
- 회귀와 다른 점은 분류 모델 출력 층의 활성화 함수가 시그모이드라는 것(sigmoid)
- 예측 결과 : 0~1 사이 확률 값
- 예측 결과에 대한 후속 처리
- 결과를 0.5를 기준으로 잘라서 1,0으로 변환
pred=model.predict(x_val)
print(pred[:5])
pred=np.where(pred=0.5,1,0)6. 딥러닝 모델링 - 다중분류
- 다중분류 모델에서 Output Layer의 node 수는 y의 범주 수와 같음
- Sigmoid : 각 클래스로 예측한 값을 하나의 확률 값으로 변환
- 다중 분류 오차 계산 : Cross Entropy
- 정수 인코딩 + sparse_categorical_crossentropy
- 원핫 인코딩 + categorical_crossentropy
- 예측 결과에 대한 후속 처리
- 예측결과 : 각 클래스별 확률값
- 그 중 가장 큰 값의 인덱스로 변환 : np.argmax()
pred=model.predict(x_val_
pred_1=pred.argmax(axis=1)7. 성능 관리
모델링의 목적
- 학습용 데이터에 있는 패턴으로 그 외 데이터를 적절히 예측
- 학습한 패턴은 학습용 데이터를 잘 설명할 뿐만 아니라, 모집단의 다른 데이터(val,test)도 잘 예측해야함
모델의 복잡도
- 너무 단순한 모델은 train,val 성능이 떨어짐
- 너무 복잡한 모델은 train 성능이 높고, val 성능이 떨어짐
적절한 지점을 찾기 위해서는 다양한 실험을 해야한다
과적합이 문제가 되는 이유
- 모델이 복잡해지면 가짜 패턴까지 학습하게 된다
- 가짜 패턴
- 학습 데이터에만 존재하는 패턴
- 모집단 전체의 특성이 아님
- 학습 데이터 이외의 다른 데이터셋에서는 성능이 저하
적절한 모델을 만드는 방법
- 적절한 복잡도 지점
- 알고리즘마다 각각 복잡도 조절 방법이 존재
- 복잡도를 조금씩 조절해 가면서 train error와 validation error 측정하고 비교
딥러닝에서 조절한 대상
- Epoch와 learning rate
- 모델 구조 : hidden layer ,node 수
- 파라미터가 많을 수록 복잡한 모델이기 때문에 감소하는 것이 적잘한 모델을 만드는 방법이 될 수 있음
- Early Stopping
- 반복횟수가 많으면 과적합될 수 있음
- val error 더 이상 줄지 않으면 멈출 것
- monitor: 기본값 val loss
- min_delta : 오차의 최소값에서 변화량이 몇 이상 되어야 하는지 지정
- patience : 오차가 줄어들지 않는 상황을 몇 번 기다려줄것인지 지정
from keras.callbacks import EarlyStopping es=EarlyStopping(moitor='val_loss',min_delta=0,patience=0)- fit 안에 지정
- callbacks : epoch 단위로 학습이 진행되는 동안, 중간에 개입할 task 지정
model.fit(x_train,y_train,epochs=100,validation_split=0.2,callbacks=[es]) - DropOut
- 과적합을 줄이기 위해 사용되는 규제 기법 중 하나
- 학습시, 신경망의 일부 뉴런을 임의로 비활성화 : 모델을 강제로 일반화
- 학습시 적용 절차
- 훈련 배치에서 랜덤하게 선택된 일부 뉴런을 제거
- 제거된 뉴런은 해당 배치에 대한 순천파 및 역전파 과정에서 비활성화
- 이를 통해 뉴런들 간의 복잡한 의존성을 줄여줌
- 매 epochs마다 다른 부분 집합의 뉴런 비활성화 : 앙상블 효과
- 보통 0.2~0.5 사이의 범위 지정 (0.4이면 hidden layer의 노드 중 40프로 임의로 제외)
- 가중치 규제하기
8. Functional API
- 모델을 좀 더 복잡하게 구성
- 모델을 분리해서 사용 가능
- 다중 입력, 다중 출력 가능
- 레이어 : 앞 레이어 연결 지정
- Model 함수로 시작과 끝 연결해서 선언
#모델 구성
input_1=Input(shape=(nfeatures1,),name='input_1'#레이어 이름은 지정안해도 됨)
input_2=Input(shape=(nfeatures2,),name='input_2'#레이어 이름은 지정안해도 됨)
#입력을 위한 레이어
hl1_1=Dense(10,activation='relu')(input_1)
hl1_2=Dense(10,activation='relu')(input_2)
#두 히든레이어 옆으로 합치기
cbl=concatenate([hl1_1,hl1_2])
#추가레이어
hl2=Dense(8,activation='relu')(cbl)
output=Dense(1)(hl2)
#모델 선언
model=Model=(inputs=[input_1,input_2],outputs=output)
시계열 모델은 패스..
느낀 점
학교 다니면서 딥러닝 스터디도 하고 몇번 접해봤지만, 너무 어려워서 딥러닝은 나의 길이 아니구나...라는 생각을 많이했다. 그러한 이유로 딥러닝만 나오면 기피하였다...ㅎㅎ
하지만, 이번 기회에 어렵게만 느꼈던 딥러닝을 알 수 있던 기회여서 좋았다!
한기영 강사님 최고 ...🥺

안녕하세요