Asynchronous Episodic Deep Deterministic Policy Gradient: Towards Continuous control in Computationally Complex Environments -논문 리뷰
강화학습 논문 리뷰
논문 출처: https://arxiv.org/abs/1903.00827
Introduction
오늘은 이전에 소개한 Prioritized-Experience-Replay 처럼 Sample에 우선순위를 두어 Sample-Efficient 를 높인 논문을 소개하겠다.
Prioritized-Experience-Replay에서는 TD-Error 가 높은 데이터에 우선순위를 뒀는데 그 이유는 DQN의 목적이 최적 Q함수에 근사하는 것이기 때문에 Error가 높은 데이터를 우선적으로 학습시켜 빠르게 근사시킨다.
반면에 이 논문에서는 Episodic-Reward가 높은 데이터에 우선순위를 둬 Actor-Critic 계열의 알고리즘도 Prioritized-Experience-Replay를 사용할 수 있게 하였으며 성능 또한 실험적으로 우수함이 밝혀졌다. Actor-Critic은 본래 Policy-Gradient에서 유도된 알고리즘인데 Policy-Gradient는 가치 함수를 근사하는 게 목적이 아니라 Expected-Reward를 최대화 하는 정책을 찾는게 목적이기 때문에 TD-Error 보다는 High Reward에 집중하는 것이 직관적으로 맞다. (물론 Actor-Critic은 가치 함수를 근사시키는 과정을 포함한다.)
Episodic-Reward를 기반으로 한 Prioritized-Experience-Replay를 DDPG에 적용해 Action Space가 Continuous한 경우에도 높은 성능 향샹을 이룬 과정을 이 논문을 통해 알아가자.
Related Works
Experience Replay
Prioritized Experience Replay weights the replay probabilities of experiences according to their measured temporal difference errors
하지만 이 논문에서는 High-reward를 주는 데이터에 우선순위를 주는 Episodic Control방법을 사용한다.
Episodic Control
Episodic Control은 해마의 작용에서 영감을 얻어 만들어진 method인데 인간은 자신의 기억속에서 최고의 경험을 토대로 행동을 계획 수정한다. 이전 논문에서는 Discrete Action Space에 한해서 Episodic Control을 이용했으나 이 연구에서는 DDPG를 이용해 Continuous Action space에서도 Episodic Control을 이용하는 방법을 고안했다.
Noise for Exploration
DDPG알고리즘은 Continuous한 Action Space에 맞춰 만들어진 RL 알고리즘이지만 취할 수 있는 Action은 Discrete다. 이런 문제점과 Action에 Exploration을 첨가하기 위해 DDPG는 Action에 Noisy를 더하는데 보통 Ornstein-Uhlenbeck을 사용한다. 이 연구에서는 저것과 다른 새로운 Noisy를 사용한다.
DDPG
DDPG는 Actor-Critic 계열의 알고리즘이다. Actor-Critic은 Expected-Return을 최대화 하라는 Policy-Gradient의 목표에 더해 Critic 신경망은 가치 함수를 근사해야 한다는 총 2개의 목표를 가진다. 보통 Actor-Critic은 V 함수를 근사하지만 DDPG는 Q함수를 근사한다는 점이 다르다. 이런 특성 때문에 DDPG는 Actor-Critic과 DQN의 공통 분모로도 분류한다.
Loss-Function
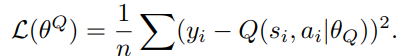
Gradient
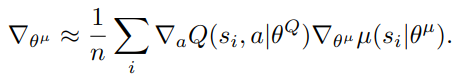
TD-Target
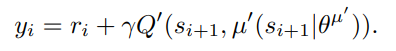
Incremental Target Updating
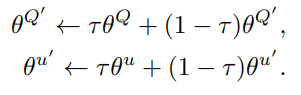
DDPG는 Actor와 Critic을 복사한 Target Network을 둬 학습이 안정적으로 이루어질 수 있게 하였다. TD-Target 역시 신경망으로 정의되었기 때문에 학습에 따라 TD-Target가 심하게 변해 불안정해질 수 있다. 그래서 DDPG는 기존 신경망을 Updating한 후 Updating한 신경망에 적은 가중치를 둬 Target-Network를 점진적으로 Updating한다.
Methodology
AE-DDPG
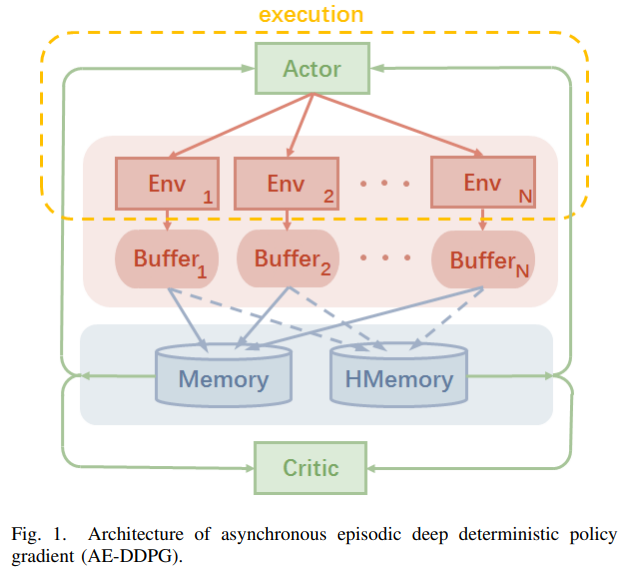
AE-DDPG 는 동시에 여러 환경에서 Agent를 학습 시키고 비동기적으로 발생한 데이터를 Buffer에 저장한 후 우선순위를 기반으로 학습을 진행한다.
Bio-Inspired Episodic Experience Replay **(가장 중요)
Model-Free RL의 고질적인 문제는 Sample-Efficient가 낮다는 것이다. 왜냐하면 대부분의 Data가 학습에 별 도움이 되지 않고 (보상이 낮거나 Temporal Difference가 크지 않기 때문이다.) 비슷한 Transition이 너무 많기 때문이다.
이 연구에서는 해마 작용에 영감을 얻은 Episodic-Control을 기반으로한 Bio-Inspired Episodic Experience Replay를 소개한다.
Samle Storation
우선 HMemory,Memory 2개의 Experience Replay Memory를 구성하는데 HMemory는 High Reward Transition을 담기 위한 메모리다.
먼저, 한 에피소드가 끝날 때까지 Agent가 만드는 모든 Transition을 Memory에 저장한다.
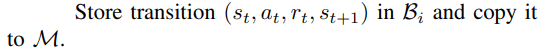
두번째, Episode가 끝나면 각 Transition의 Episodic Reward를 계산한다.

세번째, 기존 보다 Episodic Reward가 큰 Transition을 HMemory에 넣는다. 값을 갱신한다.
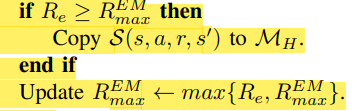
이 과정을 계속 반복한다. 위 방식을 사용하는 이유는 계속되는 경험에서 비슷한 데이터가 아닌 더 좋은 경험들을 저장하기 위해서다.
Sampling
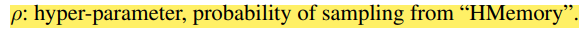
를 설정하고 매 샘플마다 random number를 뽑아 저 값보다 작으면 HMemory에서 뽑고 크면 그냥 Memory에서 Randomly Sampling을 진행한다.
이런 방법은 인간은 특정 Task에서 최고의 경험을 더 잘 기억하고 그것을 토대로 행동을 개선 계획하는 경향을 가진다는 우리의 직관과도 들어맞는다.
Pseudocode
- Sample Storation

- Data Sampling

Random walk noise for exploration
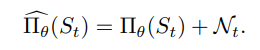
DDPG 신경망에서 나오는 Action은 Discrete하며 Exploration을 부추기기 위해 보통 Noisy를 첨가한다.
탐색을 위해 가장 좋은 Noisy는 직관적으로 Temporally Correlated하고 Instantly Uncorrelated한 것이 좋다.
이 연구에서는 power law noise with spectrum을 사용하였다.
탐색 관점에서 Random Walk Noise는 장기적으로는 Correlation한 Action을 취하기 때문에 유기적인 탐색을 가능하게 해 Efficiency of Exploration을 높였고 단기적으로는 Uncorrelated하기에 Sample Diversity를 풍부하게 하였다.
Experimental Result
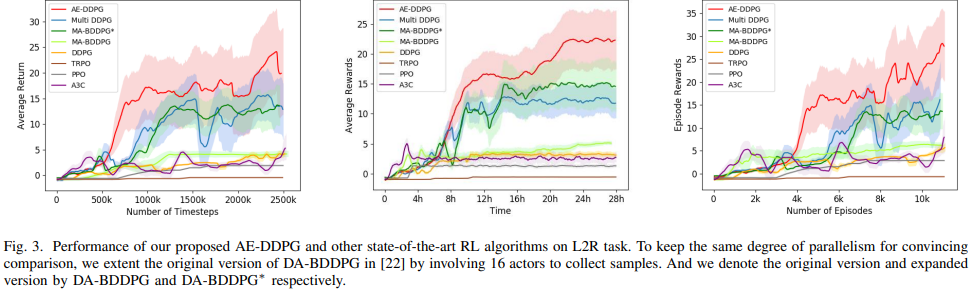
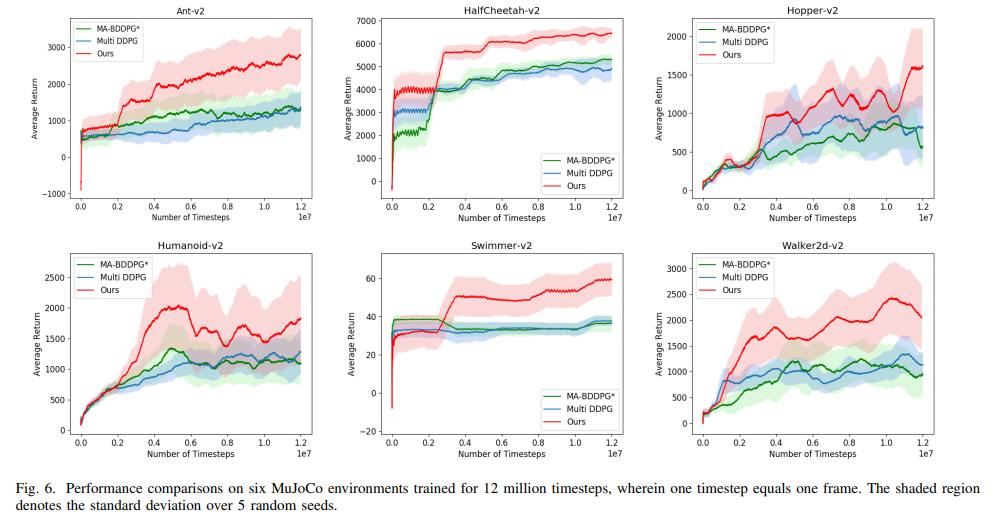
MuJoCo 게임을 통한 알고리즘 성능 비교다. 확인할 수 있듯이 Episodic Experience Replay를 사용한 AE-DDPG가 높은 성능을 발휘하는 것을 확인할 수 있다.
Conclusion
이 논문에서는 Sample-Efficient를 높이기 위해 DQN에서 사용한 Prioritized Experience Replay를 Episodic-Reward Based로 바꿈으로써 Actor-Critic 계열의 알고리즘도 Prioritized Experience Replay를 사용할 수 있게 하였다.
