Introduction
-
Goal: connecting multiple computers to get higher performance
- multiprocessor: CPU가 여러대
- Scalability (more processors)
- availability(continuity) -> 하나 고장나도 다른 게 작동 하냐?
- power efficienty
-
Task-level (process-level) parallelism
- multiple processors이 여러 processes를 동시에 돌ㄹ니다. -> High throughput for independent jobs
- 여러 processor들이 independent jobs를 동시에 돌리니 throughput이 당연히 올라가지 (한번에 많이 집어넣을 수 있는 지표)
-
Parallel processing program
- 한 프로그램을 여러 processor에 돌린다.
-
Multicore microprocessor
- A processor with multiple cores sharing a single physical address space
Already covered parallelism

Parallel programming
- Parallel software is hard to programming
- Partitioning
- divide same size of sub-tasks
- Some processors should wait for others to do the next task
- 만약 한쪽에 일감을 몰아주면 엄청 기다려야해서 Parallel 안하니만 못한 일이 발생할 수 있다.
- Coordination: synchronization(or scheduling) is time-consuming
- 서로 synchro 맞추는 것도 일이다.
- Communications overhead
- Partitioning
Amdahl's law
Sequential: multiprocessor로도 성능향상 불가능
Parallel: multiprocessor로 시간 단축 가능

- 핵심: 모든 기능의 성능을 향상 시킬 수 없기 때문에 향상된 부분만 시간 절약을 고려해야 한다.



Multiprocessor로 줄일 수 있는 건 Concurrent 밖에 없기 때문에 fraction을 나눈다. 100은 processor가 100개이기 때문
Bigger Problem


- 절대적 speedup 수치는 processor 가 많을수록 커지기는 하지만 이상치와 비교해서는 오히려 퍼센트가 떨어진다.
- Processor가 많더라도 제대로 성능을 내기 위해서는 더 bigger하고 어려운 문제가 있어야 한다. 아니면 이상치에 근접하지 않는다. (full power 못 냄)
Strong vs Weak Scaling
-
Strong scaling
- Speedup achieved on a multiprocessor without increasing the size of the problem

- Speedup achieved on a multiprocessor without increasing the size of the problem
-
Weak Scaling
- Speedup achieved on a multiprocessor while increasing the size of the problem proportially to the increase in the number of processors
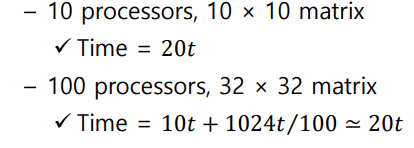
- Speedup achieved on a multiprocessor while increasing the size of the problem proportially to the increase in the number of processors
- processor가 많을수록 그것과 비례하게 문제가 커야 제대로 speed-up이 된다.
Load Balancing Problem
- 핵심: 일감 몰아주기는 재앙이다.
- one processor가 다른 processor보다 n배 잘한다고 일감을 n배 몰아주면 ㅈ된다.


Instruction and Data Streams
-
SISD; uniprocessor
-
SIMD: vector architecture(ex; 128-bits adder)
-
MIMD
-
SPMD: single program Multiple data
- a single program that runs on all processors of an MIMD computer
- Conditional statements when different processors should execute
different sections of code
Vector Architecture
-
핵심: 만약 행렬 연산을 한다고 가정하면 SISD에서는 loop를 돌며 배열 각각을 Memory에서 가져와서 따로 계산해야 한다. 하지만 Vector Architecture는 그걸 한번에 다 들고와 Parallel하게 계산한다.

-
Basic philosophy of vector architecture
- Data are collected from memory into registers
- Operate registers using pipelined execution units (ALU)
- Results are stored from registers to memory
-
Vector Extension to MIPS
- 32 vector registers (a register has 64 elements - 64 bits in an element) -> loop 64번 돌 걸 vector register 쓰면 한번에 64개를 가져와 병렬처리연산 가능
- lv,sv:load/store vector
- addv.d:add vectors of double
- addvs.d:add scalar to each element of vector of double
-
significantly reduce intruction-fetch bandwidth(Intruction 길이가 확실히 줄어든다.)
Example: DAXPY(Double precision axX plus Y)
Y=aX+Y
l.d $f0,a($sp) : load scalr a
lv $v1,0($s0) : load vector x
mulvs.d $v2,$v1,$f0 : vector-scalr mul
lv $v3,0($s1) : load vector y
addv.d $v4,$v2,$v3 : add y
sv $v4,0($s1)
vs

Vector vs Scalar
- 한번에 가져와 처리하니 반복문이 없다. -> 시간 매우 절약,코드 길이도 매우 짤아짐
- 병렬연산이기 때문에 결과가 독립적 -> Data Hazard가 발생하지 않는다.
- SIMD는 MIMD보다는 구현하기 쉽지
- Latency는 오직 entire vector을 register에 가져올 때 생김 반면 원래 방식은 word 하나하나 따로 가져와야 하기 때문에 latency가 큼
- Branch 구문이 필요 없기 때문에 Control hazard가 발생하지 않는다.
Process vs Thread
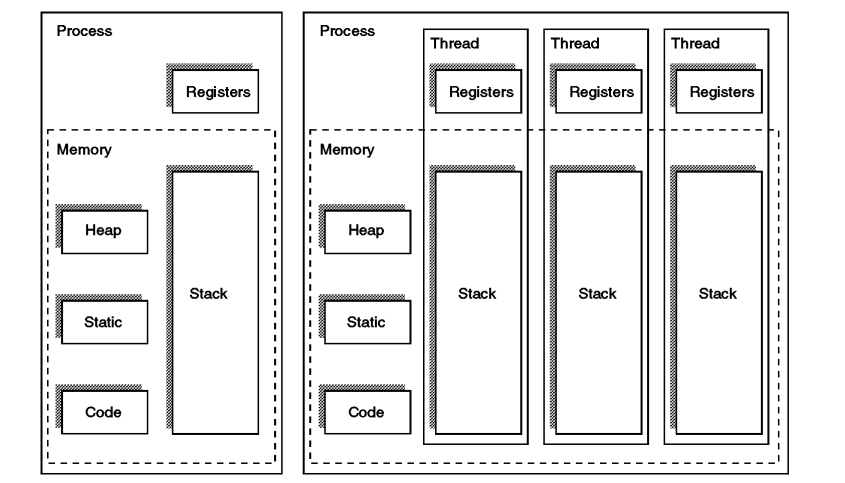
- A thread is a unit of process and one process can consist of multiple threads
Hardware Multithreading
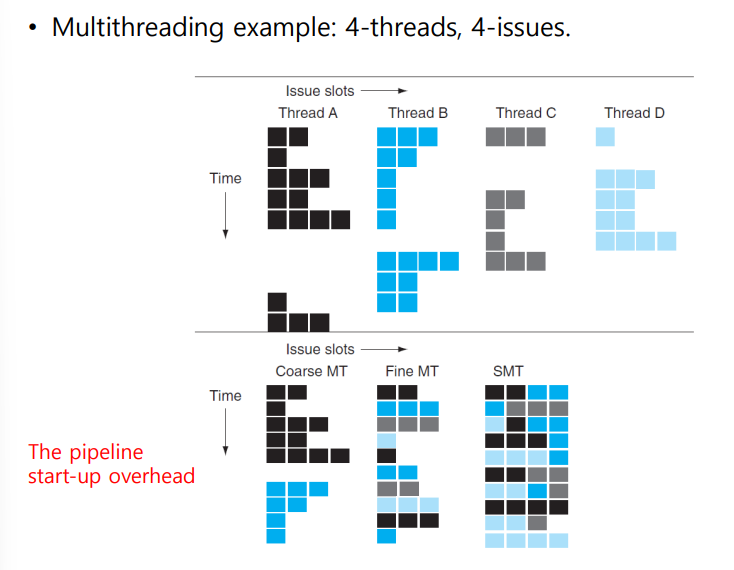
- Coarse-grained multithreading
- Only switch on long stall
- Fine-grained multithreading
- Swich threads after each cycle
- Simultaneous multithreading
- Utilize multiple-issue dynamically scheduled processor

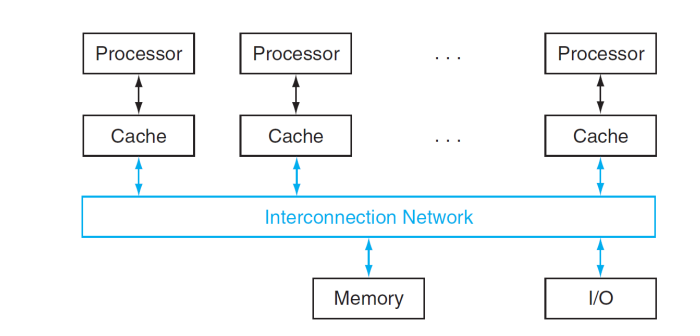
Shared Memory Multiprocessor
- 핵심 UMA(SMP) vs NUMA(Message-passing processor)
- Hardware provides single physical address space for all processors
- synchronize shared variables using locks
- All processors share one physical address space
Lock and Unlock synchronization operations
- shared memory이기 때문에 lock unlock이 있어야 synchronization이 된다.

SUM REDUCTION
- 여러 processor로 병렬처리로 덧셈을 할 것

- 전략
- reduction: divide and conquer
- half the processors and pairs, then quarter
- need to synchronize between reduction steps
GPU


Message-Passing Processor

- Cluster : a collection of independent computers
- each has private memory and OS
- connected using I/O system(Ethernet)
- Suitable for applications with idependent tasks
- problems : Administration cost,low interconnect bandwidth
- SUM REDUCTION
- initial summation on each processor

- half of the processors sne, and the other half receive and add.

- initial summation on each processor
Interonnection Networks
Network Topologies (NUMA)

- Performance
- Throughput (bandwidth == Network bandwdth)
- Link bandwidth X total number of links == The peak transfer rate
- Bisection bandwidth : Link bandwidth X total number of bisected links
- 전체 네트워크를 2개의 섹션으로 나눴을 때 나눠진 섹션에 연결되는 모든 링크들을 더햇을 때(?)
- worst case를 측정하기 위함
- Example (Fully,시험 가능성 높음)
- L:L
- N.B:L*T(15)=15L
- B.B: 9*L =9L
- Throughput (bandwidth == Network bandwdth)
Multistage Networks
- node마다 스위치를 둔다.
- 여러 스텝을 거쳐야 메세지를 송부할 수 있다.
- 대표적으로 crossbar omega network가 있다.

- 연결 거리를 단축시켜 성능을 개선할 수 있다.
Benchmark(strong weak scaling 복습하기)
- Berkeley Design Pattern (13 design patterns) (kernels==problems)
- 13 problems
- strong or weak
- reprogram yes (다른 언어로 테스트 할 수 있다.)
- Linpack : matrix linear algebra
- SPECrate: parallel run of SPEC CPU programs (job level parallelism) -> 작업을 던져주고 평가
- SPLASH: strong scaling
- NAS(NASA Advanced Supercomputing)
- computational fluid dynamics kernel
- PARSEC(Princeton)
Modeling performance(초당 byte를 얼마나 옮길 수 있나)
- GFLOPs/sec==GFLOPS
- Giga Floating point Operations per second
- measured using computational kernels from Berkeley Design patterns (13개의 커널로 multiprocessor의 GFLOPs/sec 성능을 평가한다. 높을 수록 성능이 좋은 것이다.)
- Arithmetic intensity of a kernel (problem)

오른쪽으로 갈 수록 FLOPS가 크다 - peak memory bytes/sec (using Stream benchmark, memory bandwidth와 관련)

- 1초에 얼마만큼 Byte에 access할 수 있느냐 -> 이게 클수록 memory bandwidth가 좋다.
- Peak GFLOPS(from data sheet) -> 이미 정해져 있다. (hard ware limits)
- the shape of graph looks like roofline

(기울기는 memory bandwidth가 결정 하지만 수렴점은 코어가 결정)

연산강도는 kernel에 의해 결정 kernel이 결정되면 x축이 결정
-
Optimize FP performance
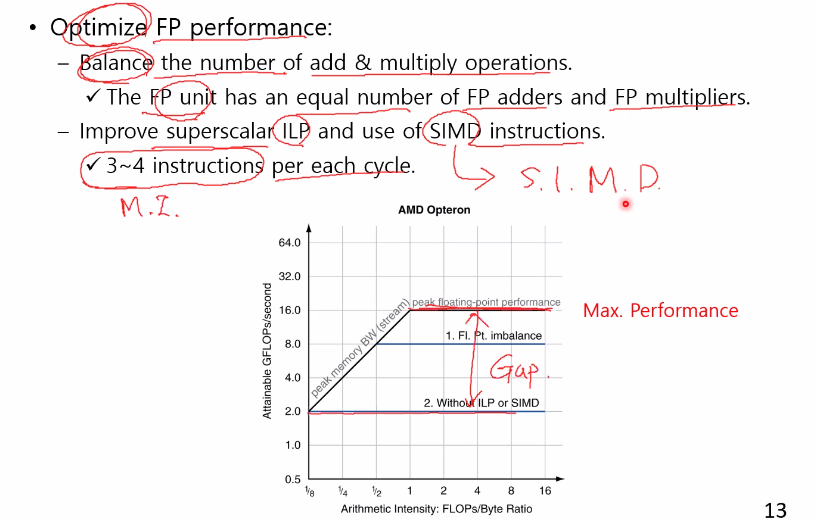
-
연산강도가 작으면 memory bandwidth의 영향을 받는다.
-
연산강도가 일정 구간을 지나면 peak에 영향을 받는다.
Optimizing Performance
- 메모리 사용 최적화
- software prefetching: 데이터가 필요하기 전에 미리 준비한다.
- memory affinity(메모리 친화도) : NUMA Processor가 다른 processor에 가지 않아도 자기 memory에 데이터가 있도록 만든다.

경우에 따라 don't care가 있으니 잘 살펴봐야 한다.
연산강도: 컴퓨터가 처리해야 할 연산이 많다., GFLOPS로 결정 4가지 optimization skill, 그래프
6-4 (REVIEW)
- Fallacy 1 암달의 법칙은 병렬처리에서도 명백하게 동작한다.
- 우리가 사용하는 processor수가 많아질수록 performance가 향상한다.
- weak scaling: linear speedup 달성
- Fallacy 2 Peak performance tracks observed performance
- 실제로는 갭이 존재한다. Peak으로 갈 수 없는 이유는 bottleneck 때문
- sequential,parallel 이 분리되었기 때문이다.
- Pitfall 1 : multiprocessor를 고려하지 않고 소프트웨어를 개발하는 것은 멍청한 생각이다.
- fallacy : memory bandwidth가 충부닣 제공되지 않으면 좋은 performance를 달성할 수 없다.
fine MT : round-robin
