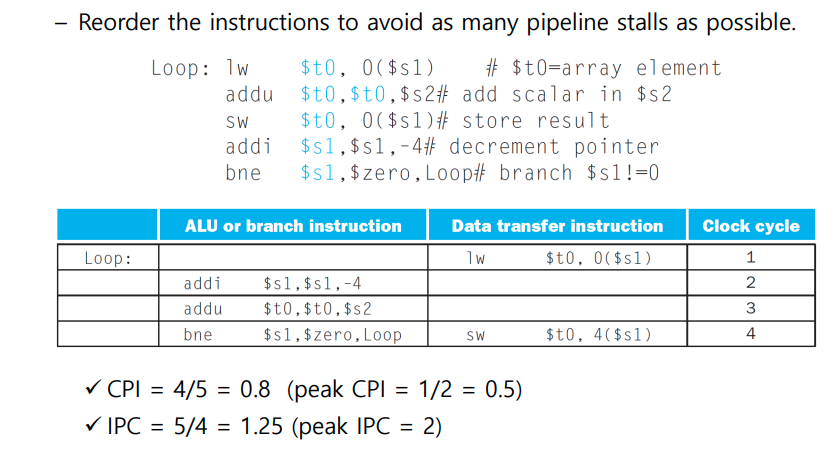
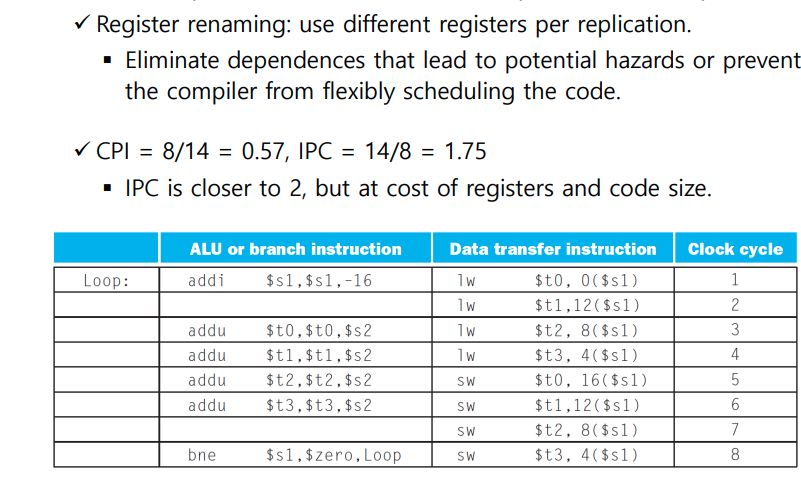
예제 족보 문제 풀이
Processor
- Pipelining이란?
- Pipelining is a implementation technique in which multiple instructions are overlapped in execution
- Multi-stage로 나누고 (Pipe) 붙인다 (lining)
- 속도는 쪼개신 Stage의 갯수에 비례해서 빨라진다.
- Stage 중에 가장 길게 걸리는 것 기준으로 Clock Cycle 정의
Pipelined Datapath and Control
- Total Five Stages
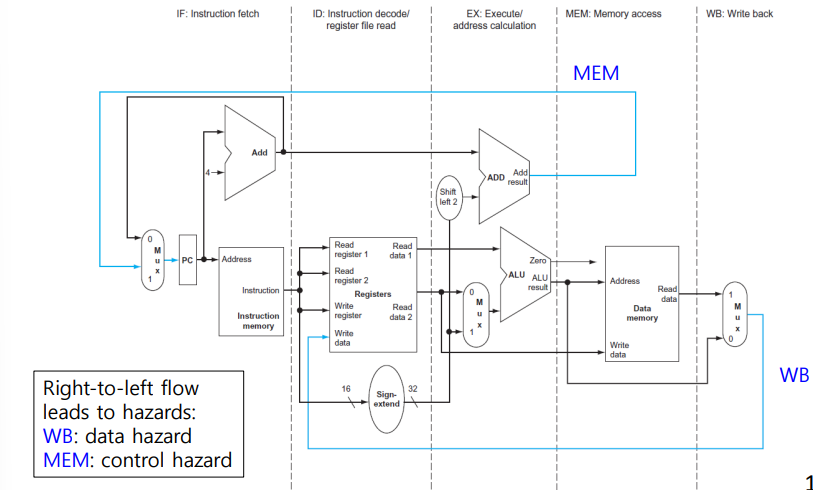
- Control Signal
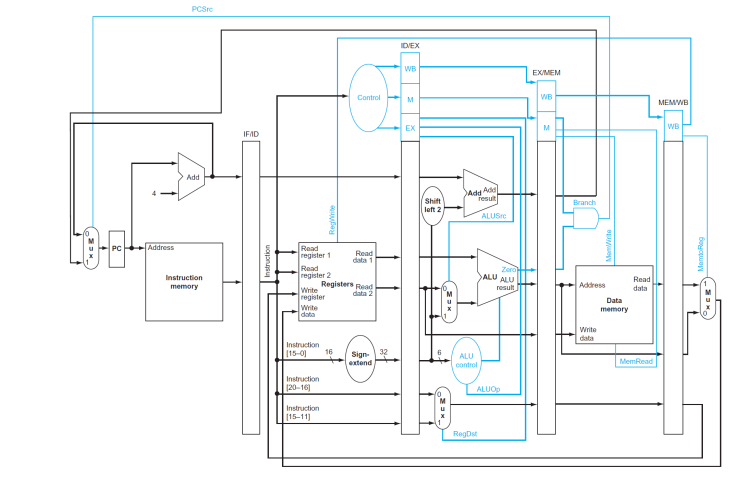
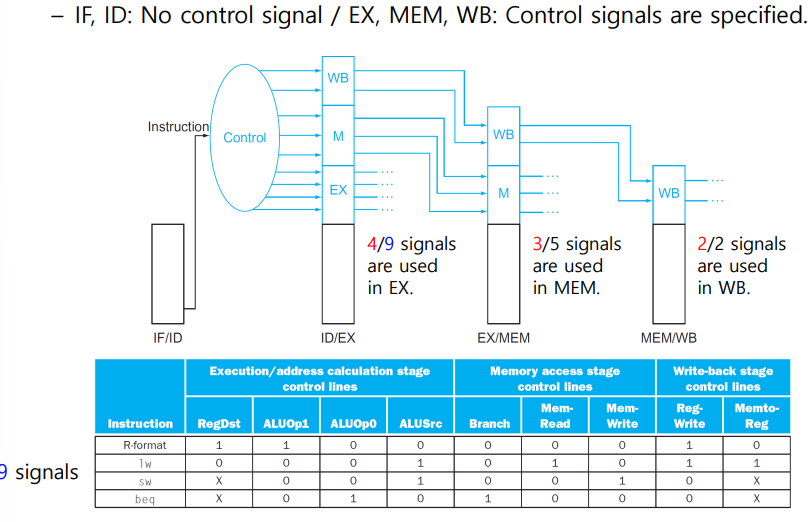
Pipeline Hazard
- Pipeline Hazard: 이상적인 Pipelining은 매 cycle마다 insturction이 시작되고, 종료되는 것이다. 이것이 불가능한 상황을 Hazard라고 한다.
- 다음 instructio이 following clock cycle에서 실행 될 수 없는 상황
- 종류
- Structural Hazard: 하드웨어상
- Data Hazard: 이전 istruction의 결과가 필요한 경우
- 만약 어떠한 조취를 취하지 않는다면 2 clock cycle을 stall 해야 한다.
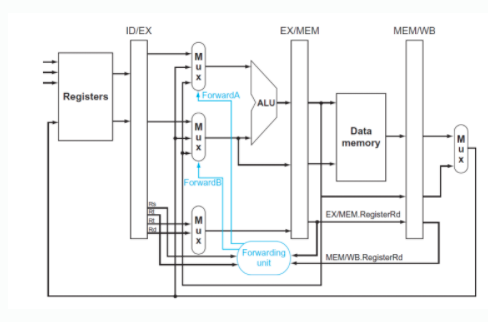
- forwarding(bypassing)으로 해결 가능 -> 대신 forwarding unit을 추가해야 한다.
- Load-use data hazard의 경우는 이것도 도지 않아서 한 cycle 무조건 stall해야 한다. 하지만 빨리 찾는 게 최고기 때문에 ID 단계에서 Hazazrd Detection unit이 빠르게 감지함
- Control Hazard
- branch 문의 결과는 EXE에서 나오기 때문에 생김
- 만약 yes라 진행하고 계속하면 이전 insturciton들이 모두 날라감
- ID 단계에서 각을 잰다. (그러면 1 cycle만 보내면 된다.)
- Prediction 사용 (2bit prediction 연속으로 2번 틀릴 때 Prediction을 바꾼다.)
Data Hazard
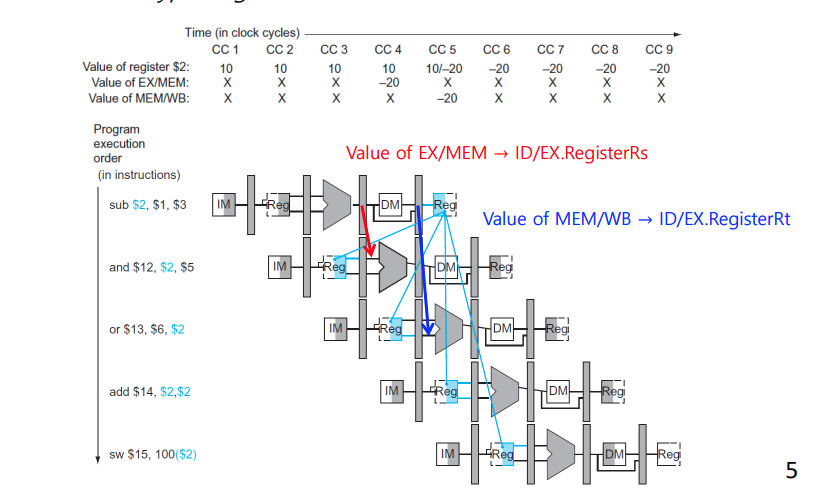
-
Data Hazard : Data Hazard는 2사이클 쉬고 그 다음에 실행하면 생기지 않는 문제
-
EX Hazard : 바로 앞 Instruction
-
MEM Hazard : 2번 째 앞 Instruction
-
Load-use Data Hazard : 바로 앞 ㅇ
EX Hazard

MEM Hazard

Load-Use Data Hazard
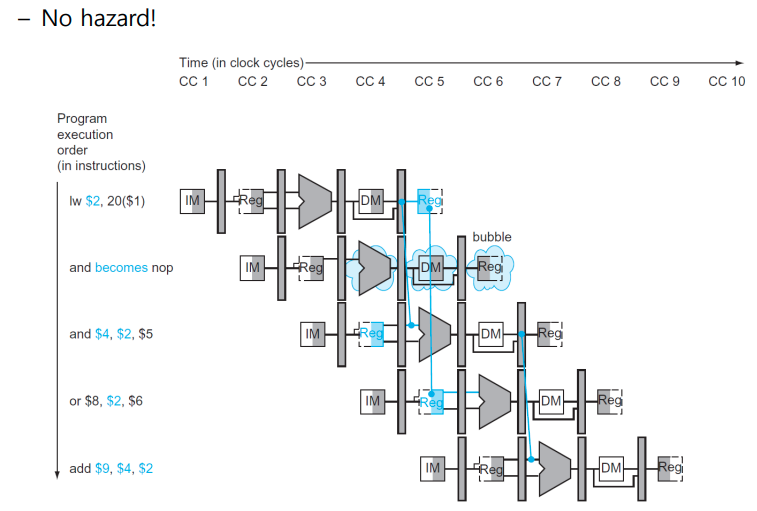
MemRead를 쓰는 lw,sw 바로 다음 쓰는 경우는 forwarding 자체가 불가능하므로 1 cycle stall하고 다음 실행한다. 여기서는 관측이 핵심

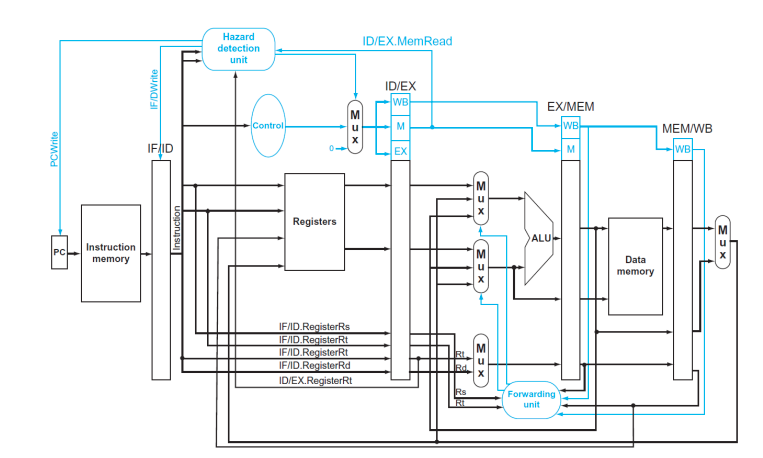
- ID stage에서 Load-use data hazard를 발견하면 EX MEM and WB를 nop시킨다.
- PC update를 막고 (다시 실행시켜야 하니) , IF/ID를 보존시킨다. (그거 다시 실행해야 하거든)
Control Hazared
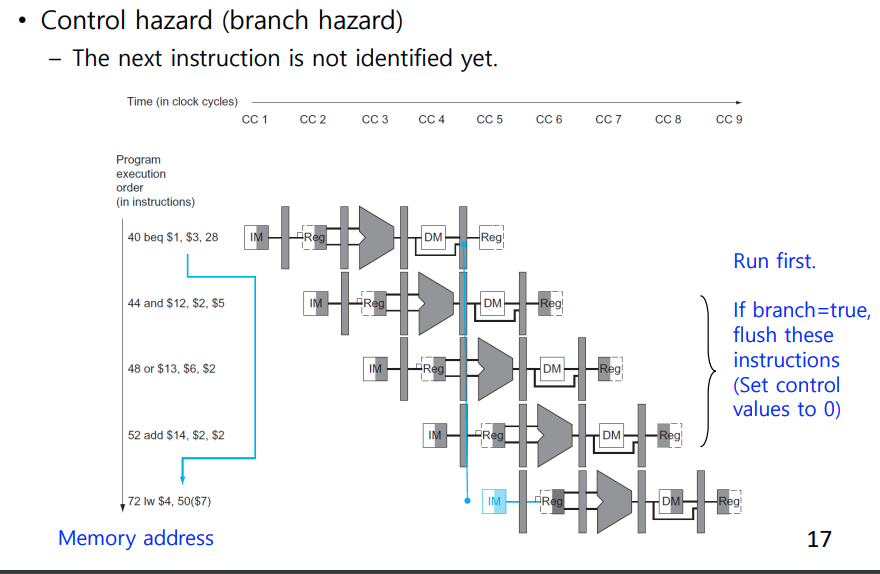
- 까딱하면 3 cycle stall한 것과 다를바 없는 상황이 발생한다.
- 아예 ID에서 Compare하게 함으로써 1 cycle만 희생하자.
- Target address adder
- register comparator
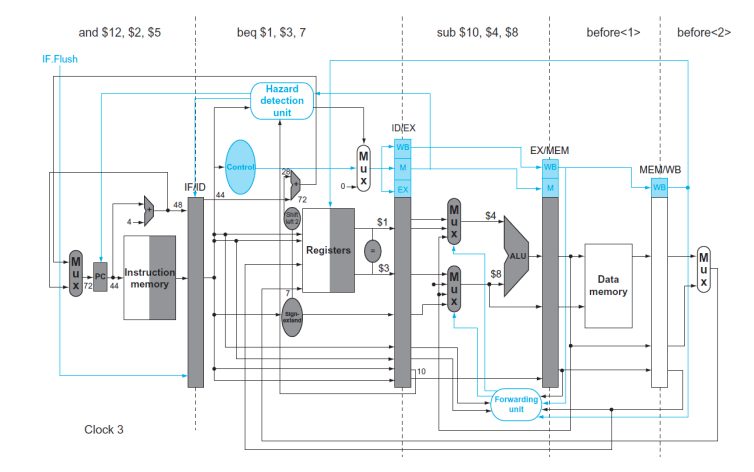
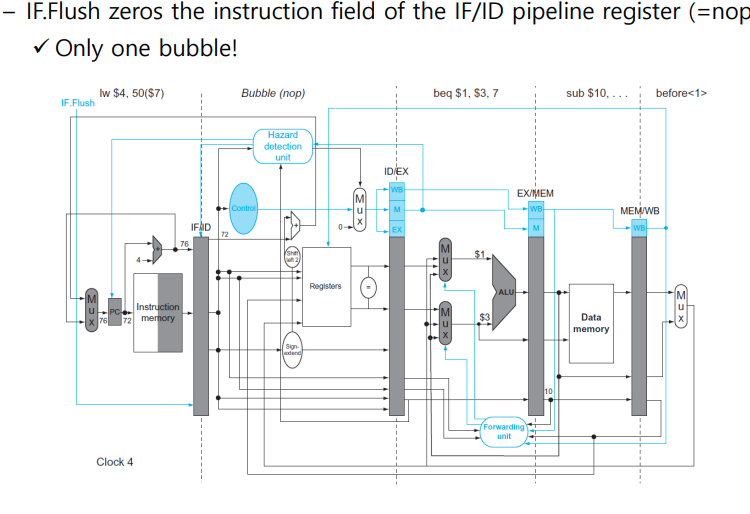
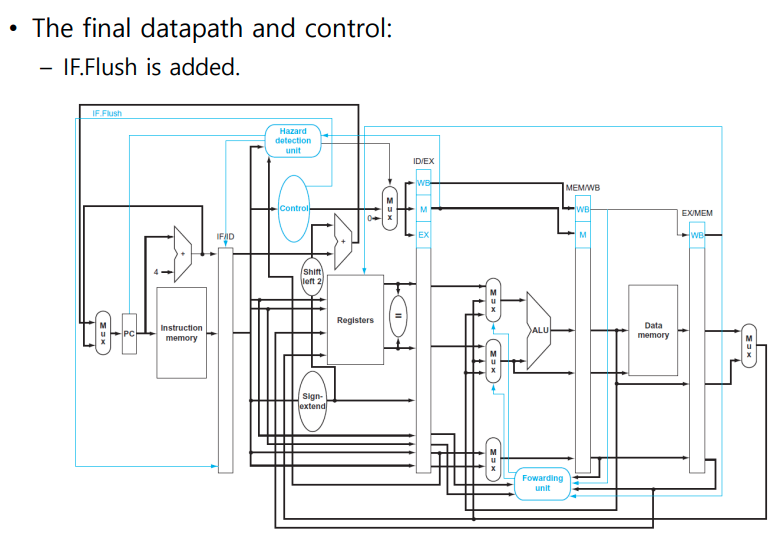
- IF.Flush control signal
- MEM stage의 branch decision을 ID Stage로 옮긴다.

Exceptions
-
Tow Types of Exceptions
- Undefined instructio -> 8000 0000 (hex)
- Arithmetic overflow -> 8000 0180(hex)
-
Consider overflow on add in EX stage:
- add $1, $2, $1
- prevent $1 from being updated to a new value
- complete previous instructions
- Flush add and subsequent insturctions (EX.FLUSH) (ID.FLUSH IF.FLUSH 작성)
- set Cause and PEC(PC+4)
- Transfer control to handler(vectored instrups)
Exceptions in Pipeline

Parallelism via Instruction
- Pipelining exploits the parallelism
among instructions. This parallelism is called Instruction-level parallelism(ILP) - To enhance ILP
- 더 많이 쪼갠다.
- Multiple Issue
- 이경우 CPI가 <1이 되므로 역수인 IPC를 많이 사용한다.
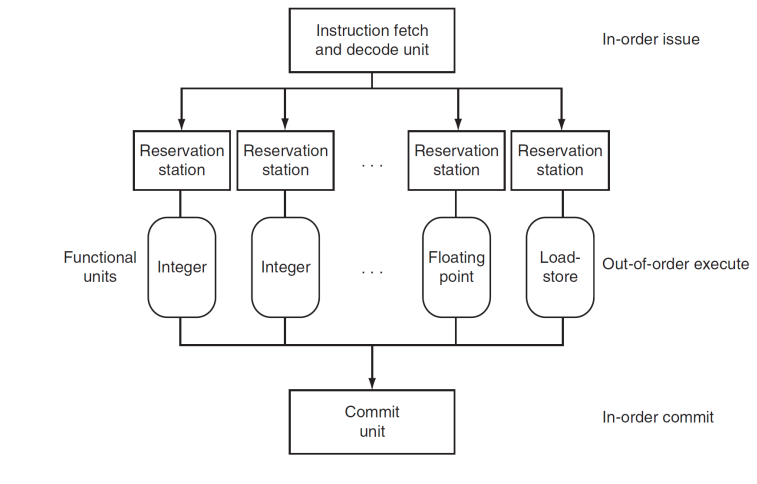
Static multiple issue
Dynamic Pipeline Scheduling
- Superscalar processor includes dynamic pipeline scheduling
족보









Memory
Multilevel Cache

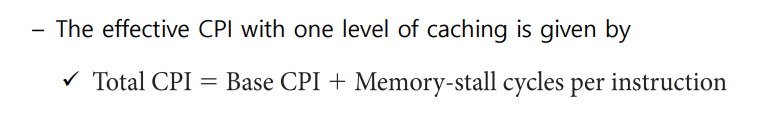






Disk Rotation 문제

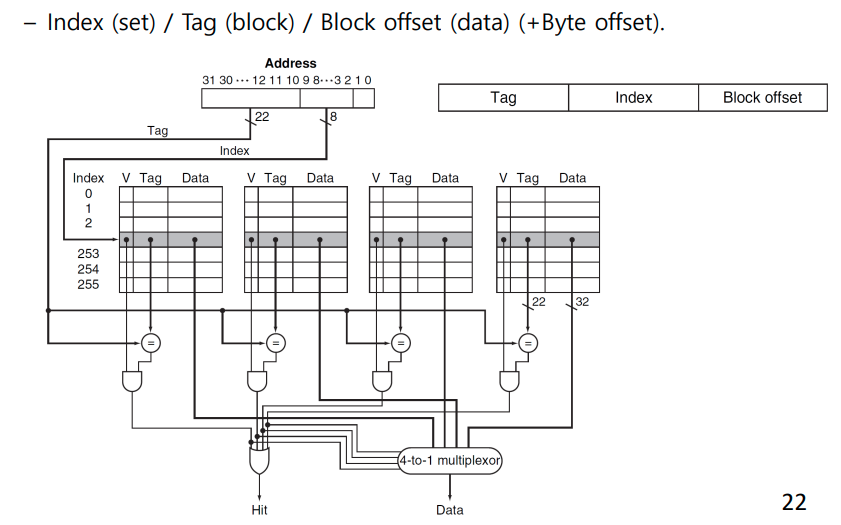
Bits in a Cache

이런 류의 문제는 우선 전체 Cache Data Field size가 몇인지 파악해야 한다.
16KiB는 4X2^10개의 단어이다.
한 block당 4개의 word를 가질 수 있으니 2^10개의 cache block이 있다.
이로부터 index는 10bit word bit는 2bit이다. (offset은 4)
32 bit address는 =18(tag)+10(index)+2(word)+2(byte)
**Cache는 valid tag word로 구성 됨**
한 block의 bit는 (4*32+1(valid)+18(tag))=147 bits
그 블록이 2^10개 있으니
147 Kibibits
이걸 byte로 바꾸면 18.4KiBMapping an Address to a Multiword Cache Block

이 문제는 일단 32bit address를 잘 파악해야 한다
64 blocks이니 index는 6bits
block size는 4word이니 2bits
offset 2bits
그다음 주소를 binary로 바꾼다.
그리고 뒤에서 4칸 자르고(offset) 거기서 6칸까지가 block number 상징
1200 이
10010110000
앞에 4칸 자르면
1001011
여기서부터 6칸
001011 -> 11
즉 11 block number에 배당된다.Caculating Cache Performance
[CPU Excution Time을 구해야하면 총 Cycle과 Clock Cycle time을 찾으면 끝난다.]
- 개념 훑고 가자
- CPU time= (CPU execution + Memory-stall clock cycles) X Clock cycle time이다.
- 즉 CPU 고유의 연산 말고도 메모리 가져오는 데 걸리는 시간까지 더해야 한다는 뜻이지
- Memory stall은 다시 read-stall write-stall로 나뉜다


우선 총 Cycle을 구해보자.
Instruction Cache miss = 2%*100*I=2I
Data Cache Miss=36%*I*4%*100=1.44I
CPU 본연=2I
5.44Average Memoyr Access Time
- AMAT: Hit Time(Memory Access Time) + Miss rate * Miss Penalty

AMAT=1clock + 0.05X20=2clock
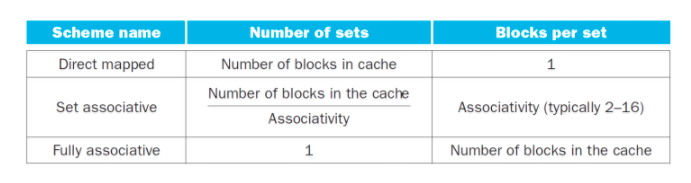
2nsAssociative Caches
- Direct mapped(One-way set associative)
- 각각의 block이 하나의 set이다.
- 갈 수 잇는 곳이 정해져 있지.
- N-way
- N개 까지 같은 집합 -> 순서 없이 들어갈 수 있다.
- 그래서 N개 comparator가 필요함


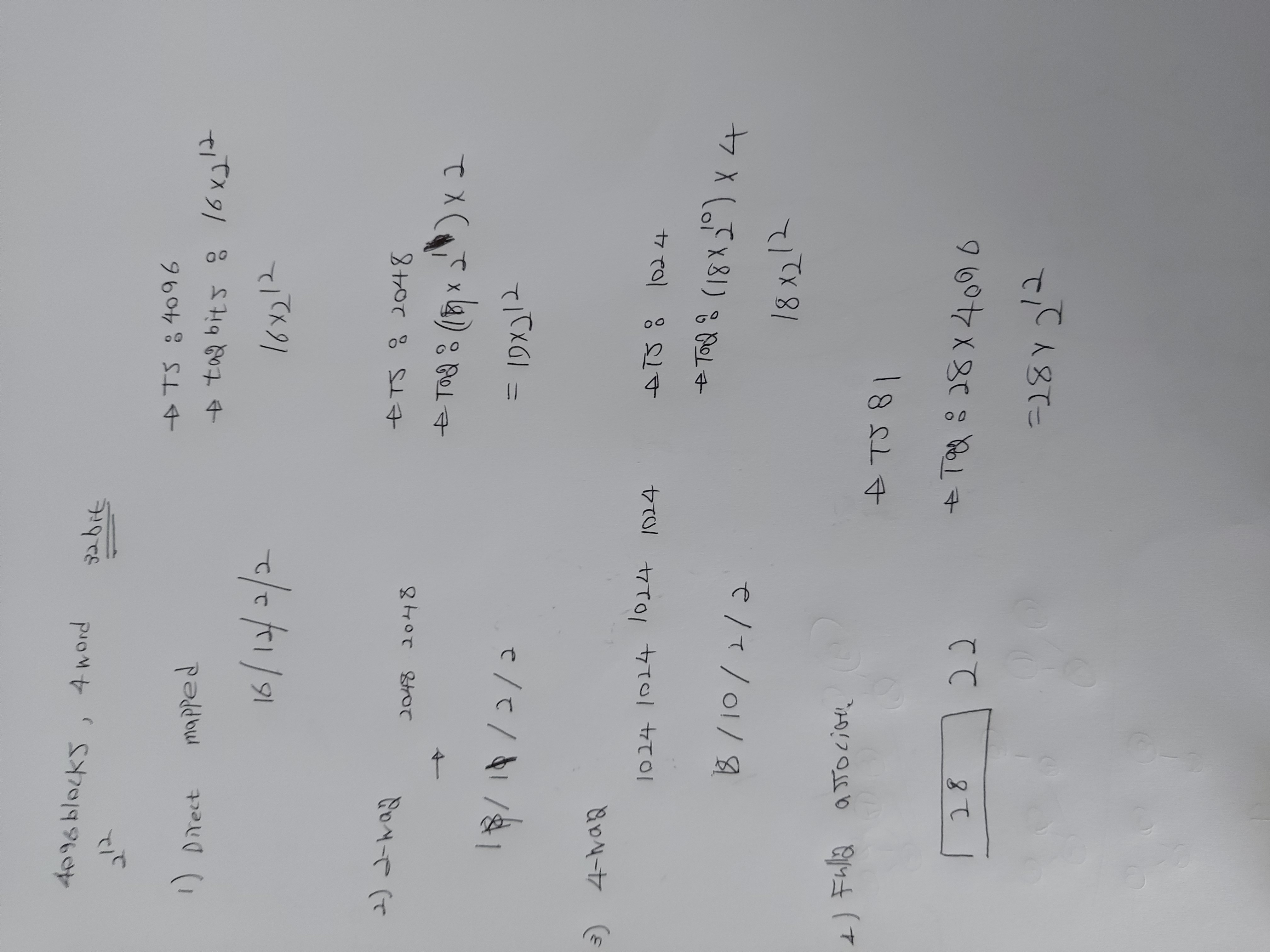
Multilevel Cache
- 왜 Multilevel Cache를 사용하지? AMAT를 줄일 수 있기 때문

base cpi : 1.0
main memory access time: 100ns*4GHz=400cycles
secondary memory access time: 20cycles
primary cache miss rate:2%
L2 cache miss rate: 0.5%
with L2
1+0.02*20+0.005*400=3.4 cycles
without L2
1+0.02*400=9 cycles
Multilevel 사용하는게 AMAT 줄이는데 더 중요하다.Dependability
- Reliablity (MTTF)
- AFR
- Mean time between failures
- Availability= MFFT/(MTTF+MTTR)
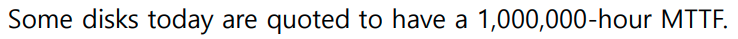


(365*24)/1000000=0.00876
0.00876*100000=876 개 디스크가 1년에 고장난다.
하루 평균 2개씩Hamming SEC
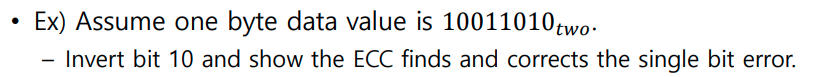

1위치 :1,3,5,7,9,11 확인 -> 통과짝수
2위치 : 2,3,6,7,10,11 확인 -> 홀수 (문제발생_
4위치 : 4,5,6,7,12 확인 -> 통과 짝수
8위치 : 8,9,10,11,12 -> 홀수 (문제 발생)
2+8번째 bit에서 문제가 발생 1을 0으로 바꿔야 문제 해결Virtual Memory
-
정의
- 가상 메몸리는 메모리가 실제 메모리보다 많아 보이게 하는 기술이다, 어떤 프로세스가 실행될 때 메모리에 해당 프로세스 전체가 올라가지 않더라도 실행이 가능하다는 점에 착안하여 고안되었다.
-
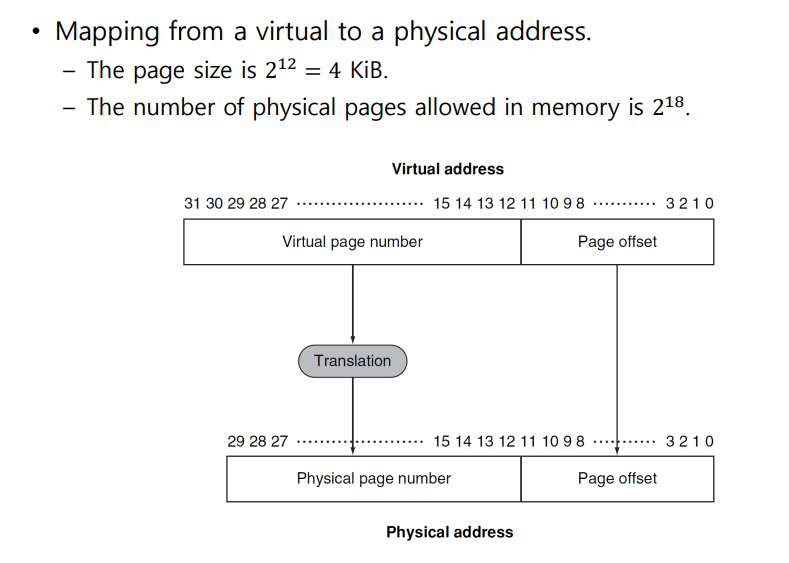
Virtual Memory Mapping
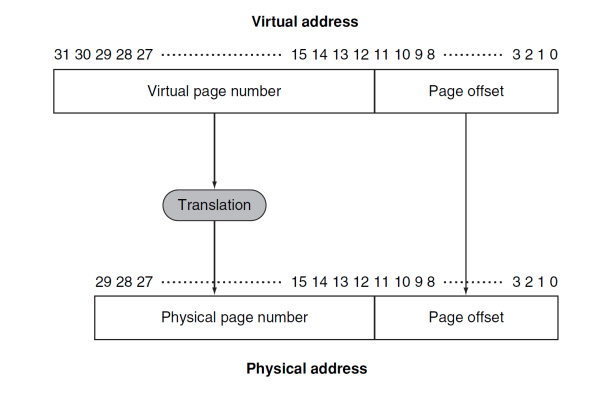
- 프로그램은 물리적 주소를 ㅈ도 모른다 그냥 가상 주소를 쓴다.
- 그러므로 가상 주소를 가져오면 그걸 물리적 주소로 바꿔줘야 하는데 그거를 하는 계 바로 Page Table이다.
- 가승 주소 테이블이 크기 때문에 그게 전부 Physical Memory에 있지 않고 일부는 Disk에 있다.
- 그래서 Processor의 가상 주소 중에서 물리적 메모리 주소에 매핑되지 못한 경우 Valid 0으로 표시하고 거기 Page가 필요한 경우 PageFault라고 하고 Disk의 Swap space에 가서 가져온다.
-
Page Table
- Virtual Address를 Physical Address로 바꿔주는 역할
- 주소와 더불에 3개의 bit (valid,reference,dirty)
- reference: 최근 가져왔는가 그게 아니면 0이 되고 LRU 방식으로 replacement 된다.
- dirty: 갱신된 내용이 아직 메인메모리에 반영되 되지 않으면 1 write-through write-back방식으로 반영이 되면 0이 된다.
- page fault 줄이려면 fully associative placement write-back, LRU를 쓰자
-
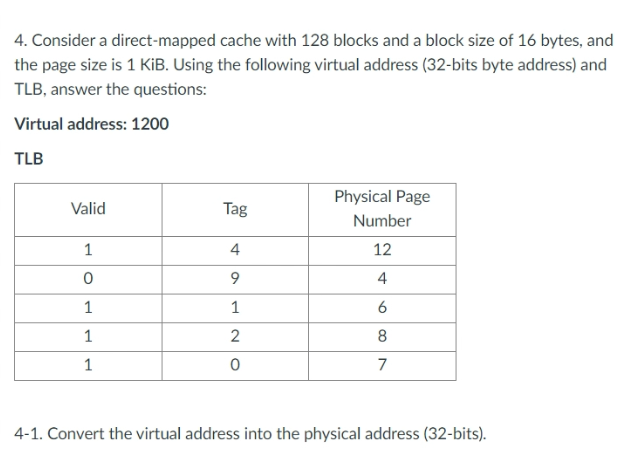
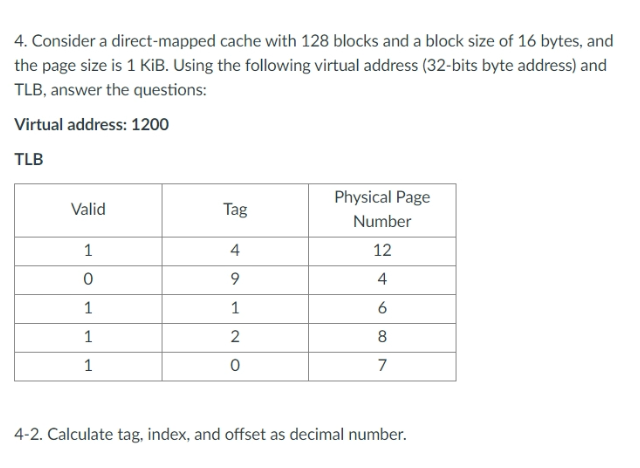
TLB
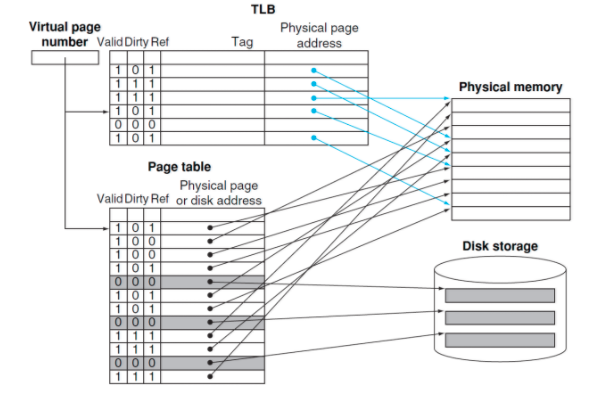
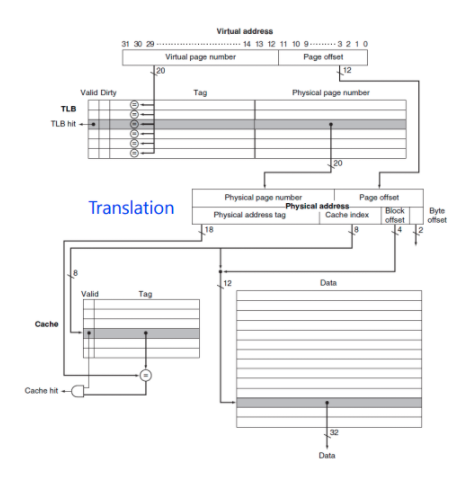
- PageTable은 메인메모리에 있기 때문에 왓다갔다 너무 시간이 많이 걸려
- CPU 안에 Table의 Cache를 만들자 그것이 TLB(TLB는 cache다 tag가 있기 때문에 위 사진 보니 Fully-Associative Cache
-
최종 알고리즘
- VA를 TLB로 보낸다.
- TLB에서 hit가 나면 물리적 주소로 매핑하낟.
- miss가 나면 page table로 이동해 해당 주소의 값을 TLB로 가져온다.
- 만약 page fault가 나면 디스크의 swawp sapce를 참조해서 데이터를 물리적 메로리로 가져와 저장하고 page table이 이 주소를 가르키도록 수정한다. 만약 빈 공간이 없다면 LRU
- page table -> TLB update
- page fault가 아닌 경우 TLB만 업데이트

족보



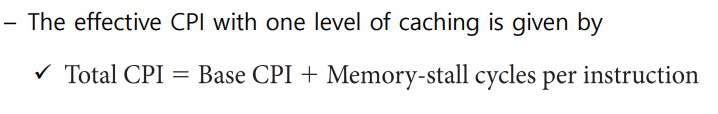



MultiProcessor
- Goal of the multiprocessor: Higher performance by using multiple processors
Exceptoins In a Pipeline
-
Datapath with controls to handle exceptions
-
8000 0000(hex) 8000 0180(hex) (vectored interrupt)
- vectored interrupts: an interrupt that determins the address from the cause of the exception
-
Ex.Flush
-
Cause
-
EPC(PC+4)
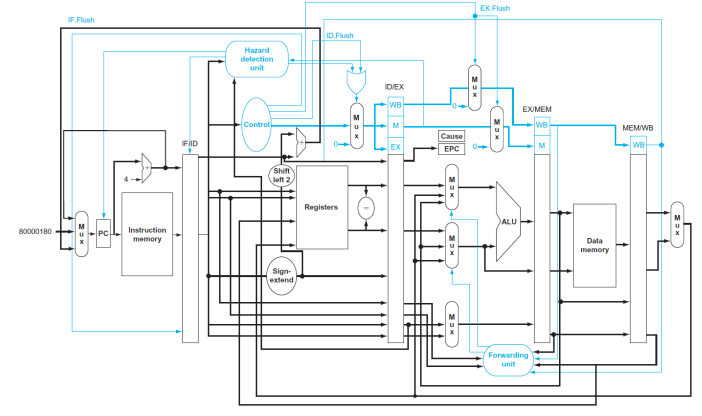
-
Exception이 발생했을 때 행동요령
- PC+4를 EPC에 저장한다
- cuase를 Cause Register에 저장한다.
- vector address
- jumpt to handler at exception vector address
-
예시

- In clock cycle6, add instruction is in EX stage
- The overflow is detected during that phase, and 80000 0180(hex) is forced into the PC
- In clock cycle 7 , the add and following instructions are flushed(Ex.Flush), and the first instruction of the exception code is fetched
- The address of the instruction folowing the add is saved to EPC: 4C(hex)+4=50(hex)
-
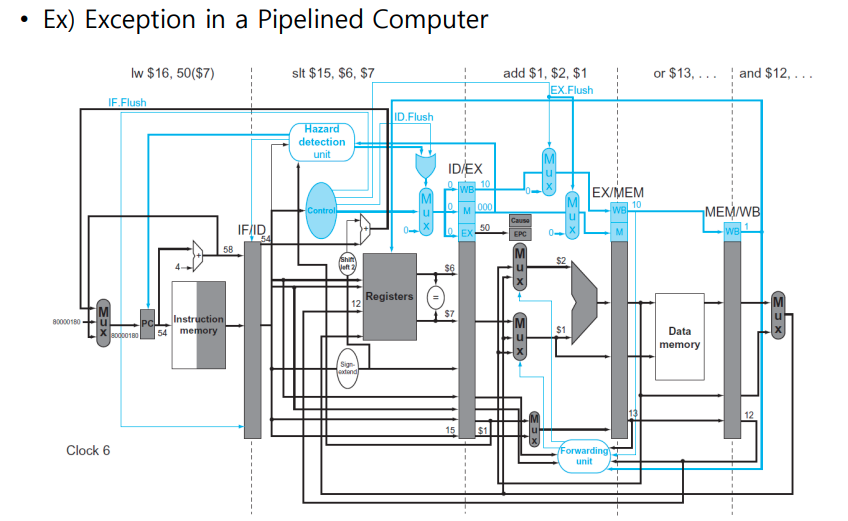
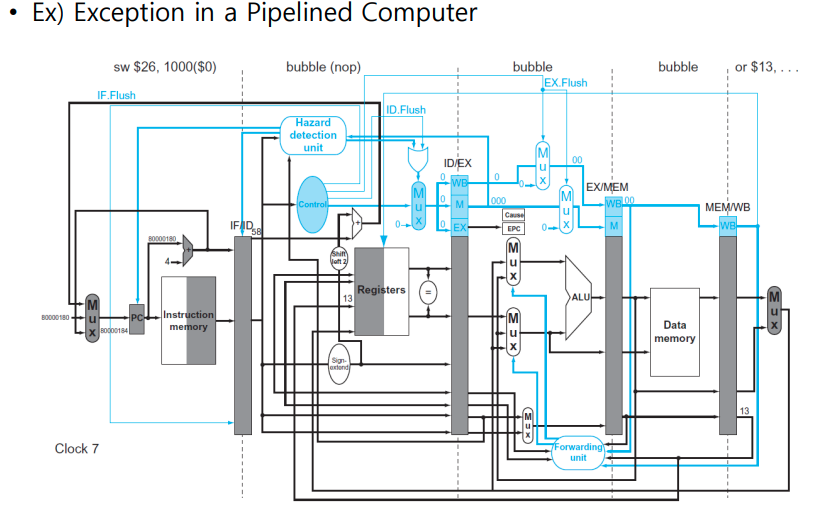
Parallelism via Instructions
-
Pipelining exploits the parallelism among instructions
-
Instruction-Level-Parallelism(ILP)
-
Increase depth of the pipeline to overlap more instructions
- stage를 더 쪼개서 clock cycle을 작게한다.
-
Multiple issue
- Multiple instructions are launched in one clock cycle.
- static multiple issue by compiler
- Dynamic multiple issue using dynamic pipeline scheduling
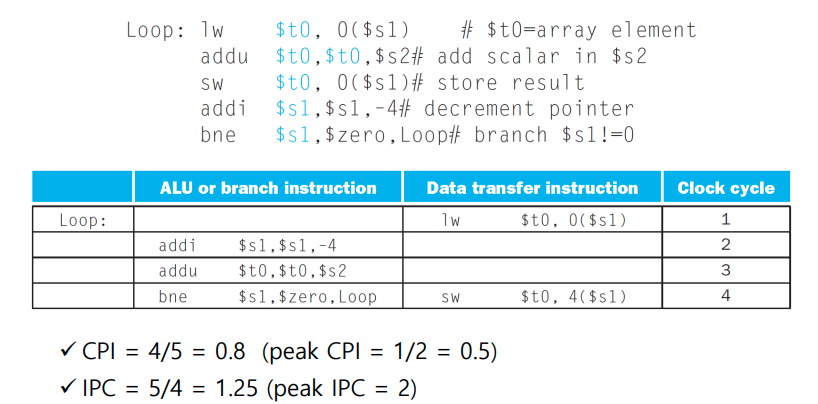
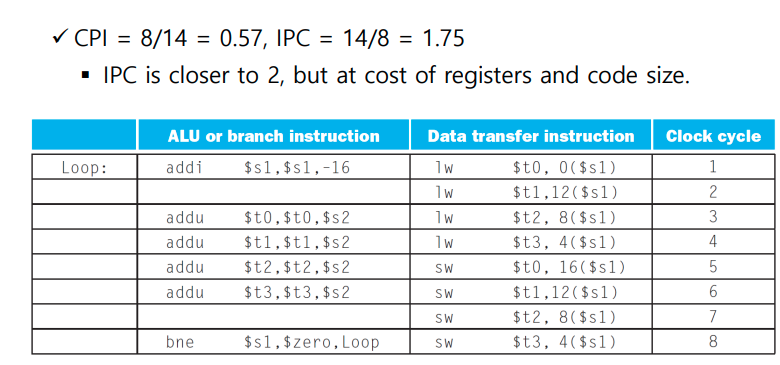
- IPC 사용 CPI 역관계
- Multiple instructions are launched in one clock cycle.
-
Statistically scheduled pipeline:
- ALU/Branch,and the load/store (64-bits aligned)
- Pad an unused instruction with nop
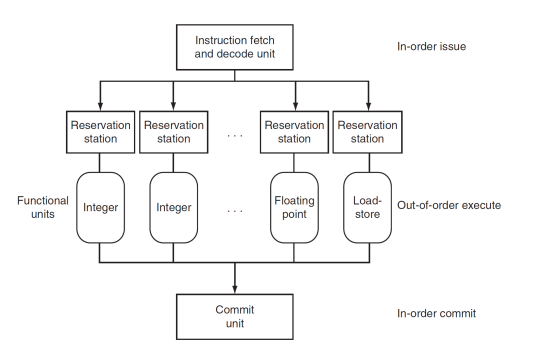
Multiprocessor
- Multiprocessor: 컴퓨터가 여러대
- Multicore microprocessor: CPU안에 core가 여러대 컴은 1대
- Task-level vs Instruction level parallelism
- Multiple(single) program on multiple processors
- Difficulties of parallel software
- Partitioning
- Coordination: synchronization
- Commuhnications
Amdahl's Law



- Strong Scaling: 문제 변화 없이 processor만 키운다
- Weak Scaling: processor도 키우면서 문제 강도 역시 키워서 Performance를 측정한다.
-
Load Balancing Problem
- 잘한다고 잘한만큼 비례하게 일을 몰아주면 망한다.
- 시간 지연은 가장 오래 걸리는 녀석 기준으로 맞춰지기 때문

Vector Architecture
-
Strong vs Weak Scaling
- Strong: 문제는 변화없이 processor만 확장한다.
- Weak: 문제와 processor 모두 키운다.
-
Vector Architecture:
- SIMD의 전형
- 형렬연산 같은 경우 loop를 계속 돌아야 하지만 Vectore Architecture를 사용하면 한번에 수행된다.
- vector의 각 요소의 연산은 독립적이다. -> data hazard가 일어나지 않는다.
- MIMD 보다 구현이 쉽다.
- latency는 vector 하나 통째로 들고올때뿐 기존에는 word마다 latency가 발생하였다.
- Loop 가 아니기 때문에 Control Hazard가 말끔히 해소된다.
- instruction-fetch bandwidth: 코드 길이가 확연히 줄어든다.

- lv,sv : load/store vector
- addv.d : add vectors of double
- addvs.d: add sclar to each element of vector of ouble
Hardware Multithreading
-
Fine-grained multithreading
- cycle 바뀔때마다 thread를 바꿔서 실행한다.
- Round Robin
-
Coarse-grained multithreading
- stall이 길때
-
Simultaneous multithreading
- function unit 비여있으면 순서 상관없이 다 집어넣는다.
- 물론 연산이 끝나면 다시 in-order 배열한다.
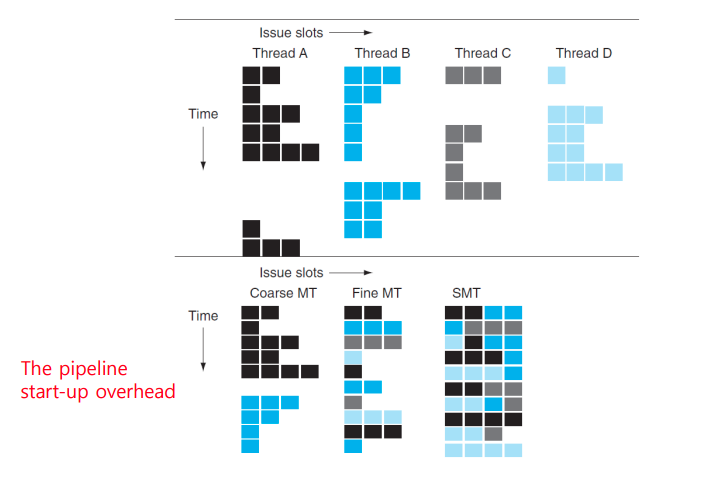
Types of Multiprocessors
Shared Memory Multiprocessor (SMP)
-
single physical address를 공유한다.
-
Synchronize shared variables using locks
-
Access time: UMA vs NUMA
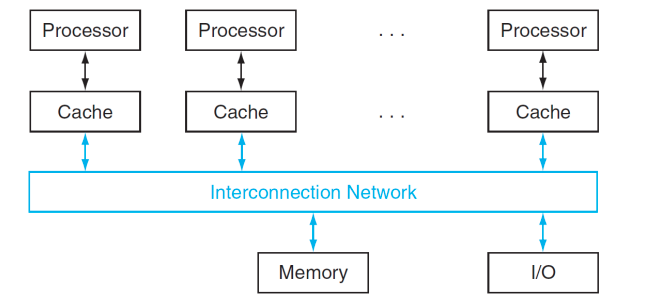
-
SUM Reduction
-
Divide and conquer
-
Half the processors add pairss, then quarter
-
need to synchronize between reduction steps

Message-Passing Processor
-
-
Each processor has private physical address space
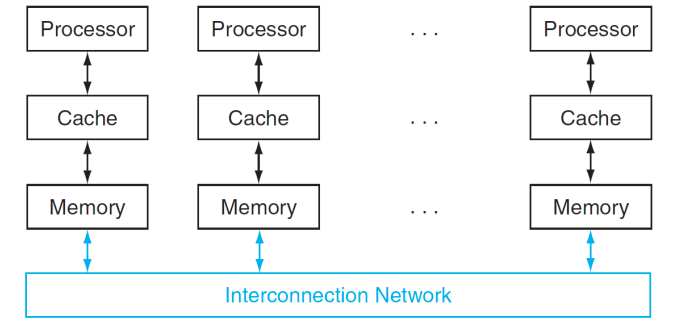
-
SUM Reduction
- Half of the processors send and the other half receive and add
- the quarter send, and the other quarther receive and add
- 각자의 memory가 있기 때문에 send receive 해야 한다.

Cluster
-
A collection of independent computeres
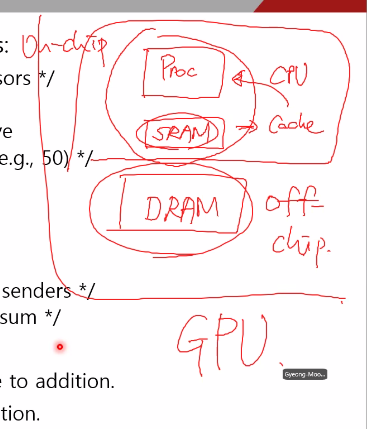
GPU Architecture
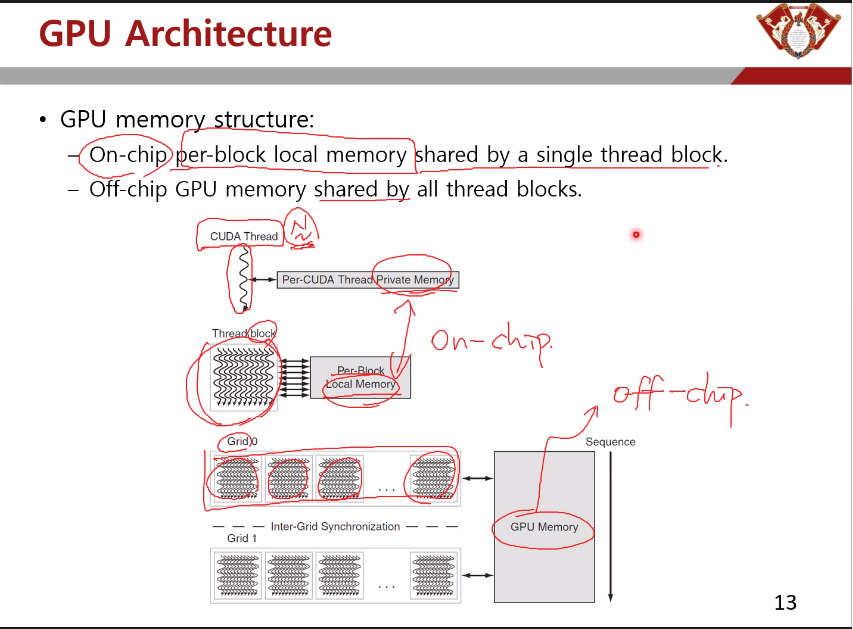
-
CUDA Thread: a vertical cut of a thread of SIMD instructions corresponding to one element executed by one SIME Lane
-
Thread Block: a vectorized loop executed on a multithreaded SIME processor
-
Thread Block의 묶음
-
GPU Memory: DRAM of GPU , Off-chip
-
Local Memory: Fast local SRAM
Interconnection Networks
-
Network Topologies
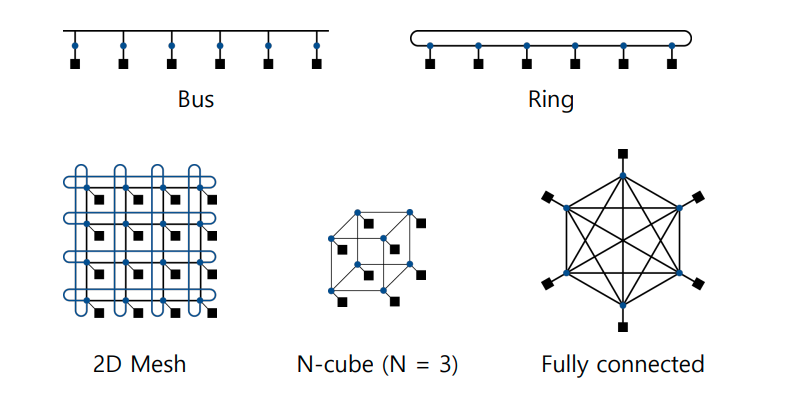
-
Network Performance
- Throughput(bandwidth)
- Link bandwidth
- Network bandwidth: 링크 갯수 X Link bandwidth
- Bisection bandwidth: Link bandwidth X total number of bisected links(반갈죽해서 거기 지나는 link 갯수)
- worst case split of the multiprocessor
- Example
- L:L
- N.B : 15L
- BB : 9L
- Multistage Network
- crossbar: switch
- omega network: switch box
Performance Benchmark
Berkeley Design Patterns : 13 design patterns(kernels)
- Throughput(bandwidth)
-
Giga Floating-point Operation per second : GFLOPS (성능지표)
-
Arithmetic intensity: byte당 얼마나 많은 FLOPs가 있는가
-

Optimizing Performance
-
Optimize FP Performance
- Balance the number of add & multiply operations
- ILP SIMD 적극 이용
-
Memory Usage
-
Software prefetching: 미리 데이터를 대기한다
-
memory affinity(메모리 친화도) : NUMA Processor가 다른 processor에 가지 않아도 자기 memory에 데이터가 있도록 만든다.
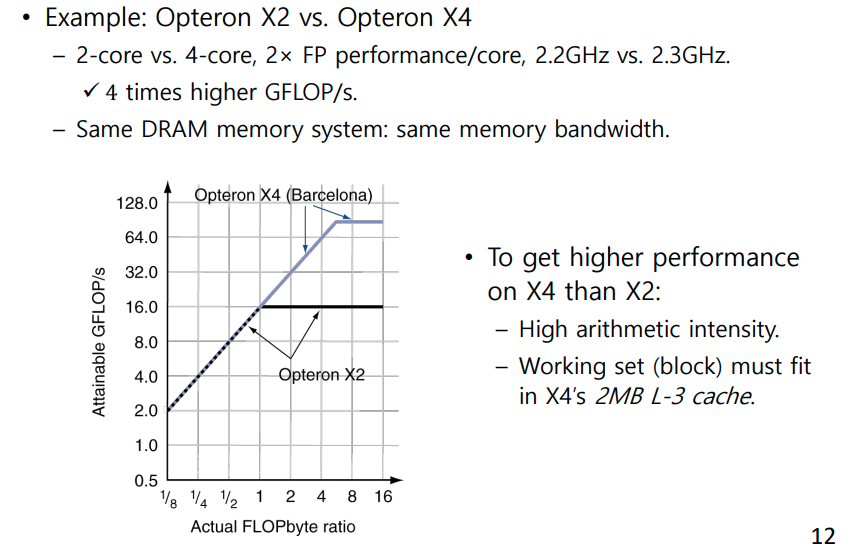
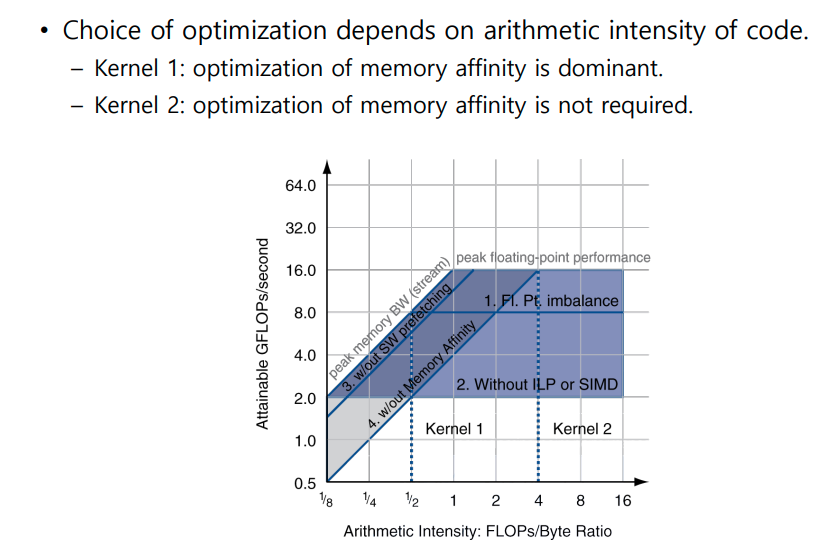
족보




-
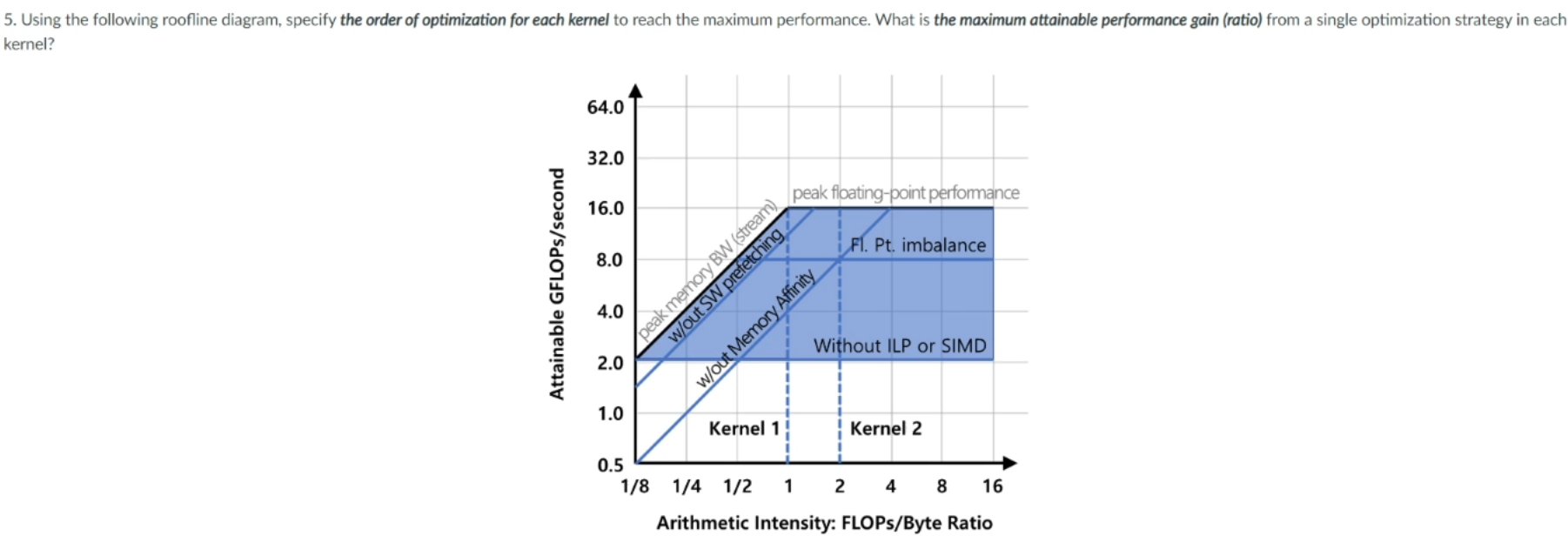
과제
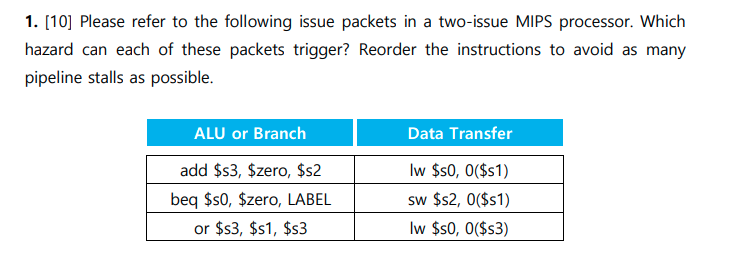

- 2.1
- 2.2
- 2.3
- 2.4



