
논문 출처: https://ecai2020.eu/papers/230_paper.pdf
Introduction


기존 강화학습을 이용한 Visual Tracking 알고리즘들은 Exploration 전략이 부족해 Local Optimal(non-target detection)에 빠지는 경우가 많았고 이것을 극복하지 못했다. 이 연구에서는 Exploration을 Entropy로 정의해 현재까지 많이 사용되고 있는 강화학습에서 가장 유명한 SAC 알고리즘을 이용해 Exploration을 강화하였다.
Background
SAC
Value Estimation

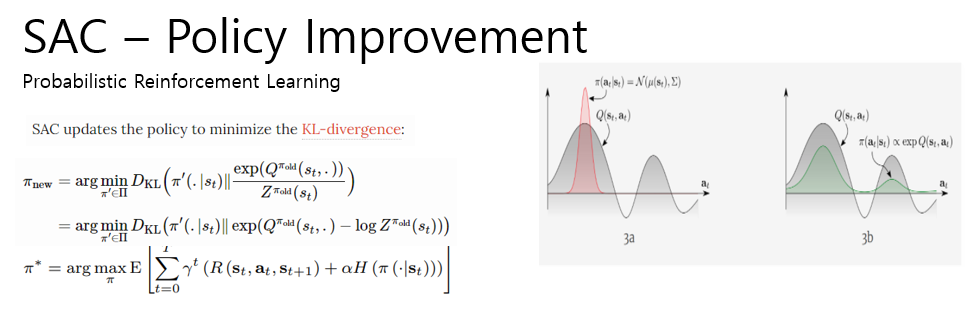
Policy Improvement

MDP formulation
Overview
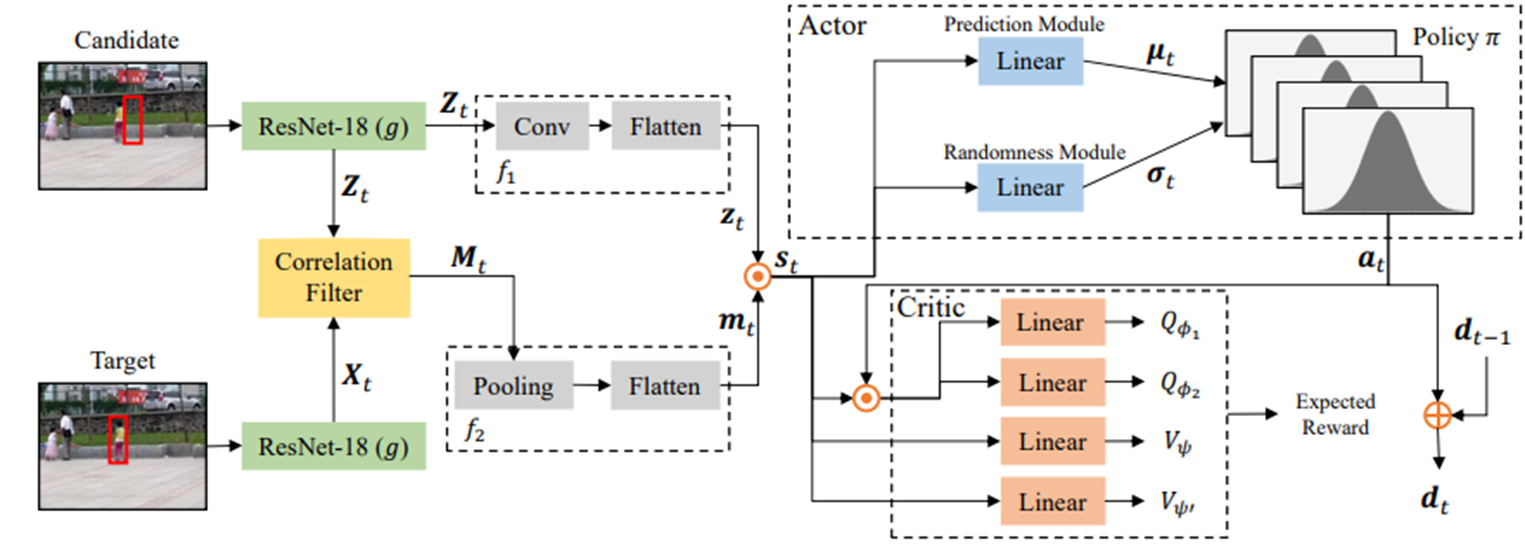
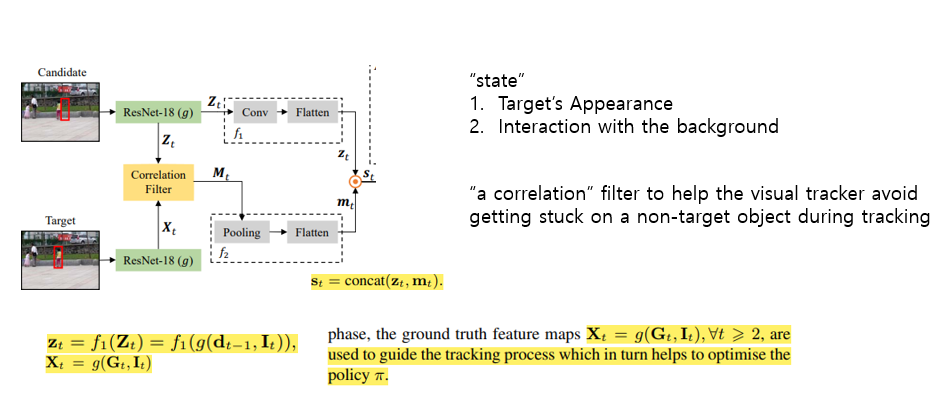
State
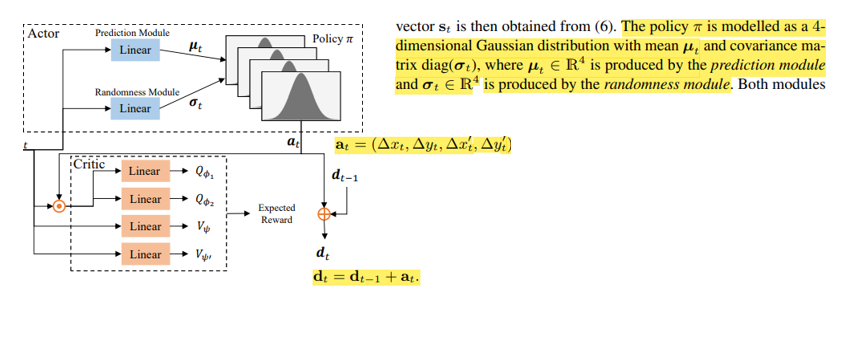
Action
Reward
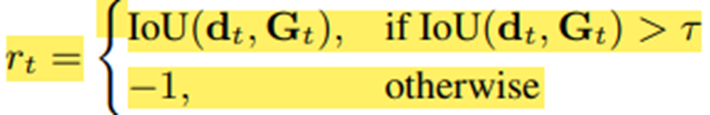
Psuedocode

Experiment
Training Dataset

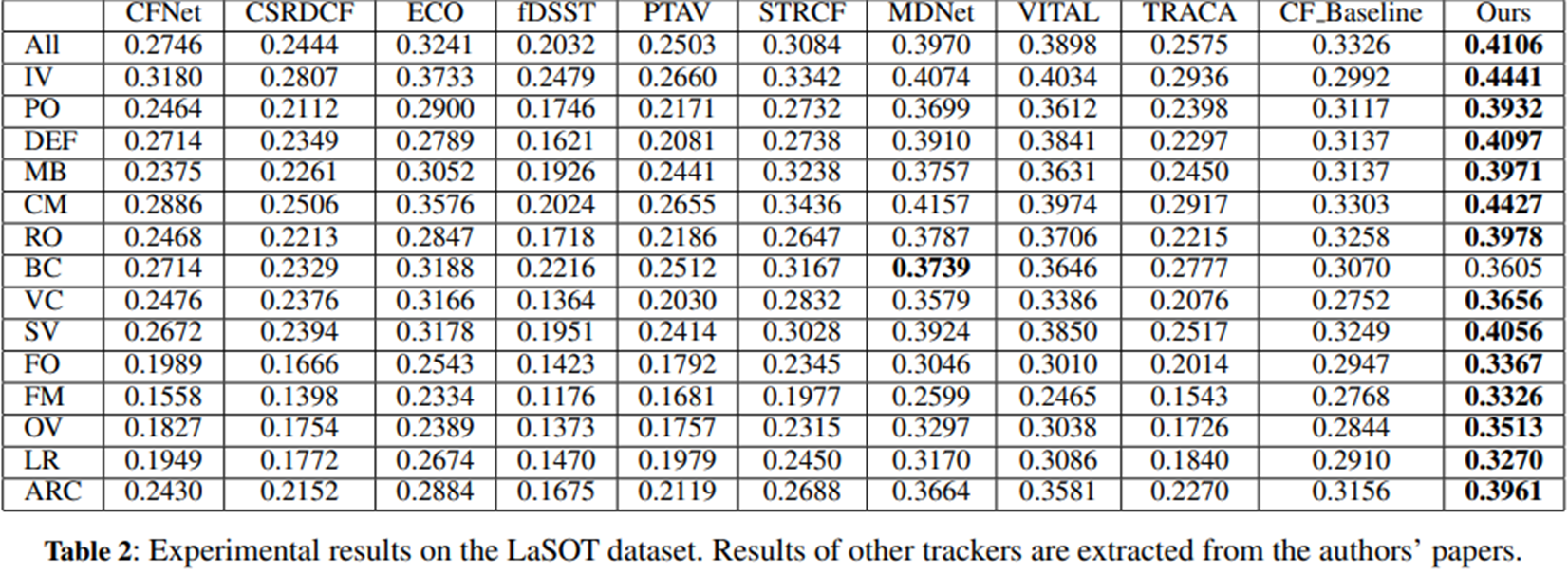

Test- OTB100,UAV123
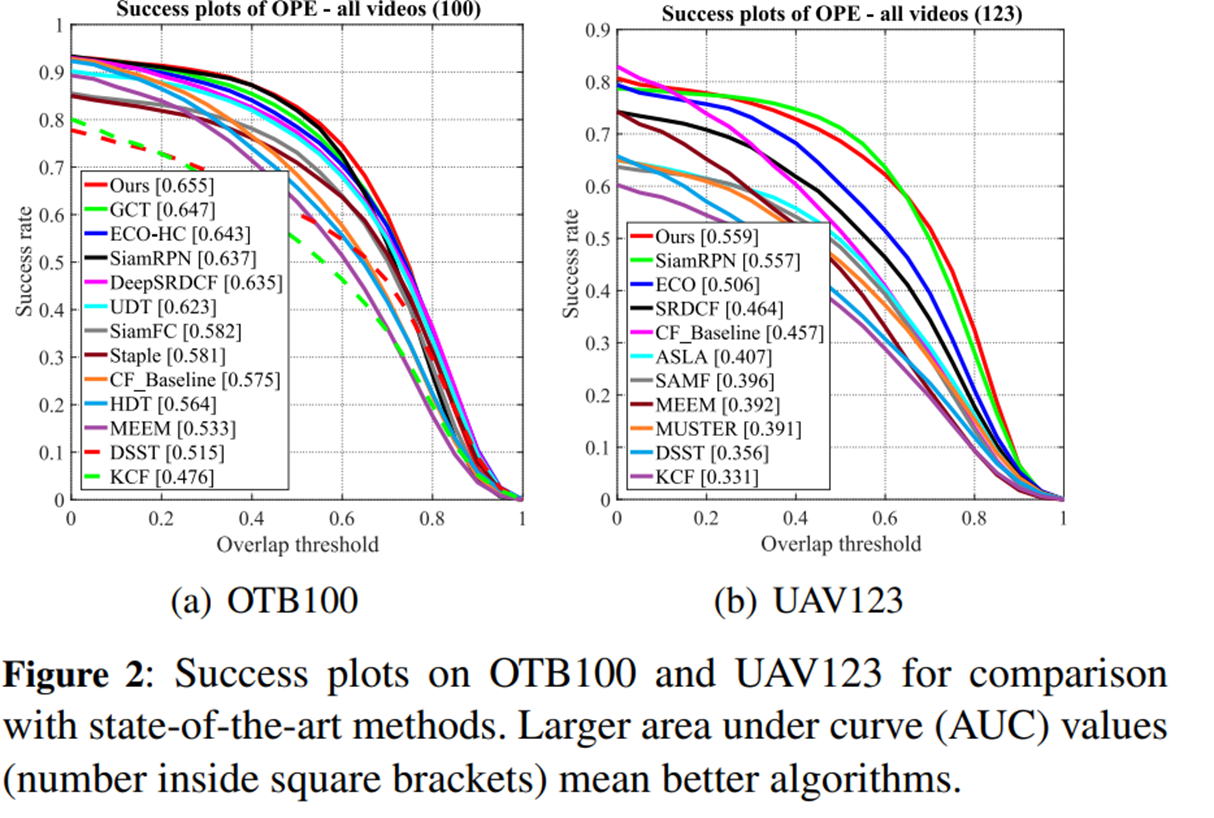
Test- VOT
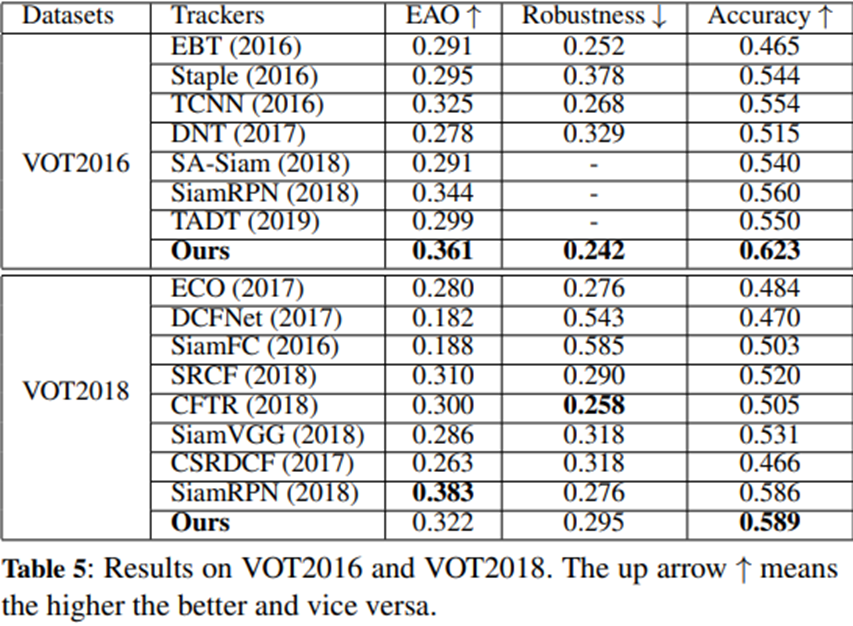
Conclusion
Action Space가 복잡할 수록 Monte Carlo 방식으로 최적 가치함수에 수렴하기 위해서는 Data-Diversity가 풍부해야 한다. 그러므로 Exploration은 매우 중요하다. Visual Tracking은 매우 복잡한 문제로 Exploration이 매우 중요하나 최근까지 연구에 사용된 알고리즘들은(DQN,DDPG,A2C)는 Exploration 을 Agent에게 직접 강요하지 않아 Local Optimal을 효율적으로 해결하지 못했다. 그러나 이 연구는 SAC를 사용함으로써 이 문제를 상당히 완화시켰고 SAC를 이용한 Visual Tracking이 가능하다는 것을 최초로 실험을 통해 밝혔다.

헬스 ,강화학습,3D Vision,Robotics를 좋아하는 엔지니어 입니다.