논문 출처: https://arxiv.org/abs/1511.05952
Background
DQN의 목표는 신경망이 최적 Q함수에 근사하는 것이다. 하지만 최적 Q함수
을 표현하는 방법이 없기 때문에 벨만 방정식을 이용해 Target-Q(최적 Q함수)를 표현하고 Q-network는 TD-target과의 차이가 0에 수렴하도록 학습한다.

즉 우리는 TD-target과 Q-network에 거의 차이가 없는 "이론적으로는 최적 에 수렴한" 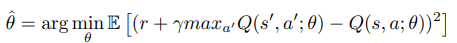
parameter 를 찾아야 한다. parameter 를 찾기 위해 DQN은 수집한 데이터를 Replay Buffer에 보관한 후 Random Sampling으로 Batch를 구성한 후 TD-error의 MSE로 Gradient-Descent로 parameter updating 한다.
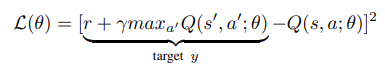
하지만 Correlation을 완화해도 제대로 학습이 이루어지지 않는 경우가 많은데 그것은 대부분 데이터가 학습에 별 쓸모가 없기 때문이다.
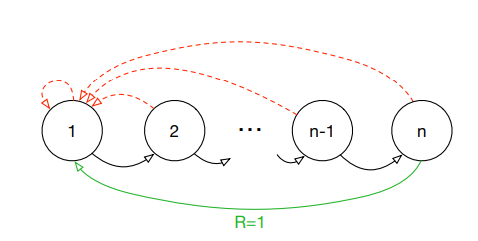
예를 들어 1에서 n으로 가는 MDP문제가 있다고 가정하자 여기서 agent가 n-1에서 n으로 간다면 보상 1을 받을 것이다. 하지만 그 전에는 어떤 행동을 해서 어떤 state로 가든 보상을 받을 수 없는데 만약 Replay Buffer에서 Data를 뽑는다고 가정할 때, 대부분은 TD-error 가 0인 쓸모가 없는 데이터다. 그래서 학습에 도움이 되는 논문의 용어로 Suprising(TD-error가 큰)한 데이터에 우선순위를 매겨 더 중요하게 학습하는 방법이 고안되었고 이것을 Prioritized Experience Replay이라고 한다.
Prioritizing with TD-Error
만약 Reward가 Terminal일 때만 주어진다면 대부분의 Transition은 쓰레기다. 그러므로 효율적인 학습을 위해서는 Transition에 우선순위를 매기는 것이 중요한데 TD-Error가 높을수록 그리고 최근에 수집한 데이터일수록 우선순위를 높게 배정한다.
TD-Error가 높은 데이터에 우선순위를 주는 이유는 DQN의 목표는 TD-target과 Q-network가 거의 차이가 없도록 하는 것이 목표인데 TD-Error가 높다는 말은 제대로 근사가 되지 않았다는 뜻이므로 그 데이터에 더 집중하여 Network를 Updating하는 것은 직관적이고 합리적인 판단이다.
또한 최근에 수집한 데이터에 높은 우선순위를 배정하는 이유는 최근 데이터에 대한 정보가 별로 없기 때문에 Exploration을 가하기 위함이다.
Priority를 설정하고 가장 높은 데이터를 기반으로 학습을 진행한다면 Priority가 낮은 데이터에 대해서 제대로 학습이 이루어지지 않을 가능성이 있다. 그래서 이 논문은 Priority에 기반하여 확률을 차등적으로 분배하는 방법인 Stochastic Prioritization 방식을 제시한다.
Stochastic Prioritization
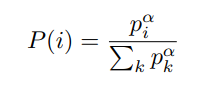
위 식을 Proportional Prioritization이라고 하는데 우선순위를 기반으로 확률을 차등적으로 부여하였다. 이것을 통해 우선순위가 높은 Sample이 선택될 확률을 높이면서 우선 순위가 낮은 Sample이 선택되지 않을 가능성을 제거하였다. 는 우선순위에 민감도를 나타내고 가 클수록 우선순위를 중요하게 여긴다. 이면 Random-Variable은 Uniform-Distribution이다.
각 데이터에 대하여 Proportional Prioritization을 정의하는데 를 정의하는 방법은 두 가지가 있다.
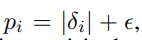
는 TD-Error 고 은 뽑힌 Sample의 TD-Error가 다 0일 수 있기 때문에 분모가 0이 되는 것을 막기 위해 a small positive constant를 설정하였다.
두 번째로는
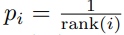 가 있다.
가 있다.
Stochastic Prioritization 을 이용해 TD-Error가 더 큰 Data에 집중해 Network가 학습할 수 있게 하였으며 또한 TD-Error가 낮은 데이터가 무시되지 않도록 조정하였다.
Annealing the Bias
하지만 차등적인 확률을 배정하는 것은 DQN의 Random Sampling에 문제를 야기한다. DQN은 Replay Buffer에서 Random Sampling(Uniform Distribution)을 통해 Batch를 구성하는 방식으로 Correlation을 완화시켰는데 Stochastic Prioritization 방식은 Correlation이 완화된다고 보장할 수 없다. 왜냐하면 샘플이 Uniform Distribution이 아니기 때문이다.
이를 해결하기 위해 Importance-sampling이라는 트릭을 사용하였다.
라는 방식으로 도수에 대해서는 uniform Distribution이 아니지만 도수에 대해서는 Uniform Distribution이 되도록 설정하였다. 를 Importance-Sampling weights라고 한다. 이 논문에서는 weights를 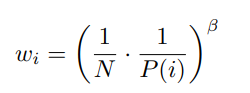
로 정의 하였다. 가 1이 된다면 Uniform-Distribution 효과가 나타난다.
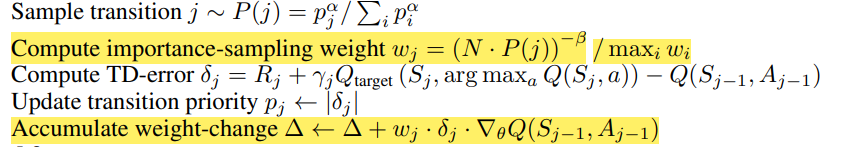
PseudoCode를 보면 마지막 Accumulate weight-change 부분에서 각 sample 별로 Importance-Sampling weights를 곱하는 것을 확인할 수 있다.
PseudoCode

Conclusion
이 논문에서는 Replay Buffer에서 Data를 더 효율적으로 선별하여 학습 시킬 수 있는 방법을 제시하였다.
Reference
- Tom Schaul et al.(2016)PRIORITIZED EXPERIENCE REPLAY
.ICLR
