GPT-1 Improving Language Understanding by Generative Pre-Training (2018)
Text & Speech Papers
📌Improving Language Understanding by Generative Pre-Training (Radford et al., 2018)
📌 Original Paper: https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
BERT 와 무엇이 다른가 정리
| 항목 | GPT-1 | BERT |
|---|---|---|
| 📚 논문 이름 | Improving Language Understanding by Generative Pre-Training (Radford et al., 2018) | BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (Devlin et al., 2018) |
| 🏗 Transformer 구조 | Decoder-only (GPT-style, left-to-right) | Encoder-only (Fully bidirectional) |
| 🔄 Pre-training 방향 | Left-to-right (Autoregressive) | Bidirectional (Masked Language Model) |
| 🎯 Pre-training 목표 | LM objective (다음 단어 예측) | Masked LM (MLM) + Next Sentence Prediction (NSP) |
| 🛠 Fine-tuning 방식 | 단순한 classification head 추가 후 fine-tuning | 다양한 태스크에 맞게 구조 일부 수정 또는 linear head 추가 |
| 🔍 입력 구조 | 한 문장 단위 (문장 생성 중심) | 문장 쌍도 가능 ([CLS] 문장1 [SEP] 문장2 형태) |
| 🧠 학습 목표 성격 | Generative (생성 기반 언어모델) | Discriminative (이해 기반 언어모델) |
| 🧪 Zero-shot 학습 | 일부 가능 (task 마다 편차 있음 - 추론 기반 태스크에서는 성능 낮음) | 불가능 (BERT는 fine-tuning 필수) |
| ⛳️ 주 용도 | 텍스트 생성, zero/few-shot 가능성 탐색 | 문장 분류, 관계 판단, QA 등 이해 중심 NLP task |
Introduction
📌기존 접근 방식의 한계
-
야생에서 수집한 원시 텍스트(raw text)를 효과적으로 학습하는 능력은 자연어 처리(NLP)에서 매우 중요하다.
-
하지만 라벨이 있는 데이터(labeled data)는 부족하기 때문에, 비라벨 데이터(unlabeled data)를 활용해 지도 학습에 대한 의존도를 줄일 필요가 있다.
이로 인해 unlabeled 데이터를 사전 학습(pretraining)에 활용 하는 접근이 주목받게 되었다.
그러나 기존의 unsupervised pretraining 방식에는 한계가 존재했다:
-
기존 방식은 주로 단어 수준의 통계 정보(word-level statistics)만 학습하며, 문장이나 문맥 수준의 표현력을 충분히 학습하지 못했다.
-
단순히 unlabeled data만으로 학습할 경우, 어떤 목적함수(objective function)가 downstream task에 효과적인지 알기 어렵고, pretrained model을 fine-tuning할 때 task-specific 학습 전략이 명확하지 않아 성능이 불안정했다.
-
또한, 기존 방식은 task마다 모델 구조를 변경하거나 복잡하게 설계해야 하는 경우가 많아, semi-supervised learning 환경에서는 확장성에 어려움이 있었다.
🎯 GPT-1의 해결 방법: 보편적인 사전학습 + 파인튜닝
“다양한 NLP 태스크에 적용 가능한 보편적인 언어 표현(representation)을 미리 학습하고,task-specific한 fine-tuning을 최소한의 구조 변화만으로 수행한다.”
이를 위해 논문은 두 단계의 훈련 절차를 제안한다:
A. Pre-training:
대규모의 unlabeled 텍스트 데이터를 기반으로 language modeling objective (다음 단어 예측)을 통해 일반적인 언어 표현을 학습한다.
B. Fine-tuning:
각 downstream task에 맞게 사전 학습된 모델을 지도 학습 데이터(labeled data)로 미세 조정한다.
이 접근 방식은 모델 구조의 변경 없이 다양한 태스크에 쉽게 적용 가능하며, transfer learning 정확도 크게 높임
GPT1
Architecture
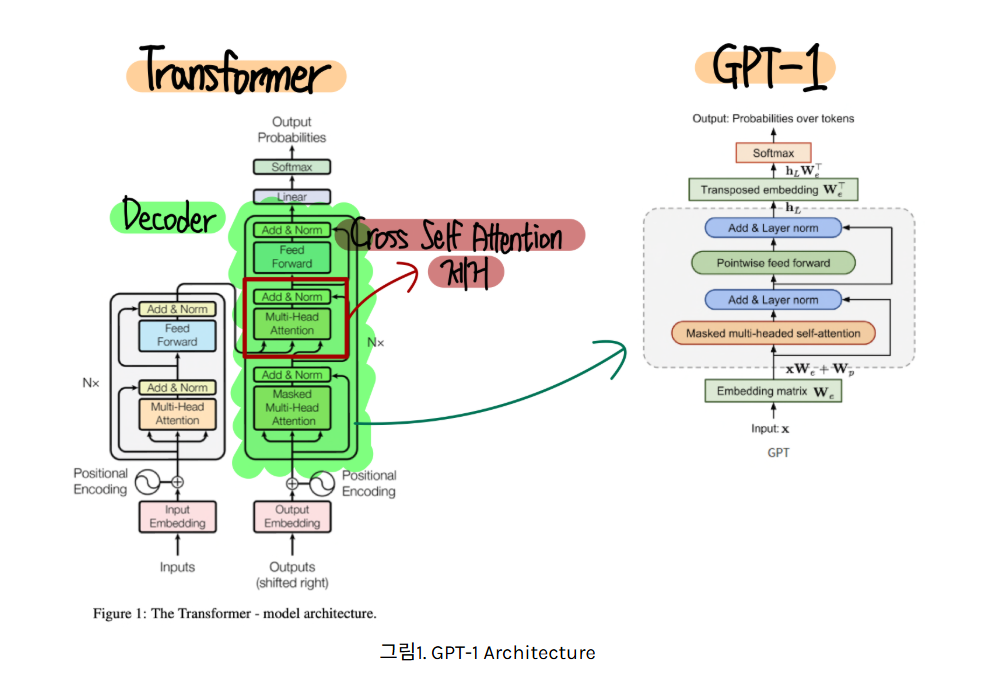
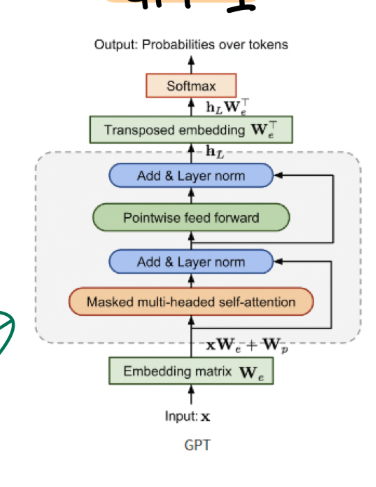
Transformer 의 디코더만 가져와 사용함. 인코더 사용 안하니까 cross self attention 부분은 없어지는 것
디코더만 사용하는 이유:
-
모델의 학습 목표가 “다음 단어 예측” (Autoregressive Language Modeling)이기 때문.
-
간결성으로 연산량이 줄어든다.
Unsupervised Pre-Training
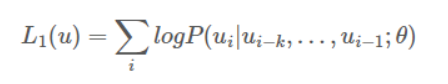

데이터를 문장별로 나눔 -> 각 문장을 입력해주는 구조.
한 문장도 나눠서 넣고 다음 예측하는 방식으로 진행.
Pretraining 의 효과:
1. 언어 구조를 학습
2. 문맥 이해 능력 향상
3. 다양한 언어 패턴 학습
4. transfer learning 시 일반적 언어 이해 능력 높이는데 효과적
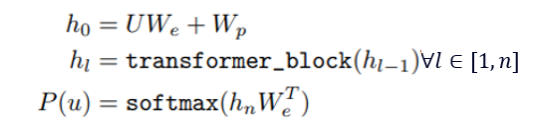
- h0는 "단어 의미 + 위치 정보"
- hl−1: 이전 레이어의 출력
transformer_block: GPT 디코더 블록 (Masked Multi-head Attention + FFN)
총 n개의 Transformer 블록을 통과하며,
각 블록은 문맥 정보를 점점 더 풍부하게 만들어 줌
마스킹된 self-attention을 사용하므로 현재 시점까지의 단어 정보만 반영
- 마지막 Transformer block 출력:
- 임베딩 행렬 전치:
아래 과정으로 최종 출력 형성


Supervised fine-tuning

주어진 정답 데이터셋
C에 대해, 입력 𝑥로부터 정답 𝑦를 최대한 정확히 예측하도록 모델의 파라미터 𝜃를 학습시키는 손실 함수
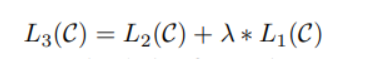
이후 L2 function 에 L1 function 더하는 보조적 역할 사용시 모델 일반화와 학습 속도 향상에 도움이 되었다고 함.
Task Specific Input Transformations
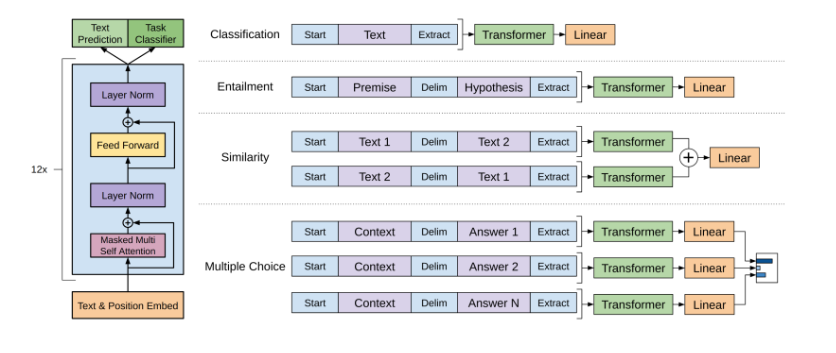
Classification
입력 텍스트 분류 문제 (ex. spam mail detection)
내용 전체를 입력으로 넣고 분류하는 과제
Textual Entailment
한 문장이 다른 문장을 의미적으로 함의하는가
premise (전제) 와 hypothesis (가설) 문장 두개 넣어줌
이때 가운데 deliminator 로 구분해서 처리
Similarity
두 문장이 얼마나 유사한가 판단.
input 으로 두개의 문장을 받고 출력을 0-1 사이에 냄
최종 유사도 값 출력하는 구조
text1 + text2 / text2 + text1
두 결과를 add 한후 선형 레이어에서 활성함수 거쳐서 최종 유사도 출력
Question Answering & Commonsense Reasoning
Context 와 Answer 로 구성되어 있다.
각각의 답마다 서로 다르게 context - answer 쌍 만들어서 transformer 구조로 넣어주고, 이 중 가장 높은 확률을 가진 쌍을 출력하는 구조
Experiments
Natural Language Inference
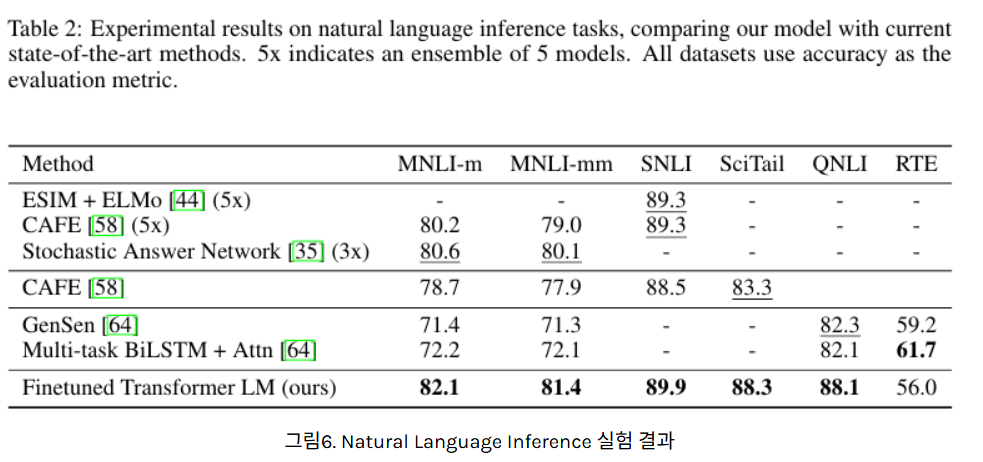
모든 데이터셋에서 기존 방법들보다 성능 우수
Question Answering & Commonsense Reasoning
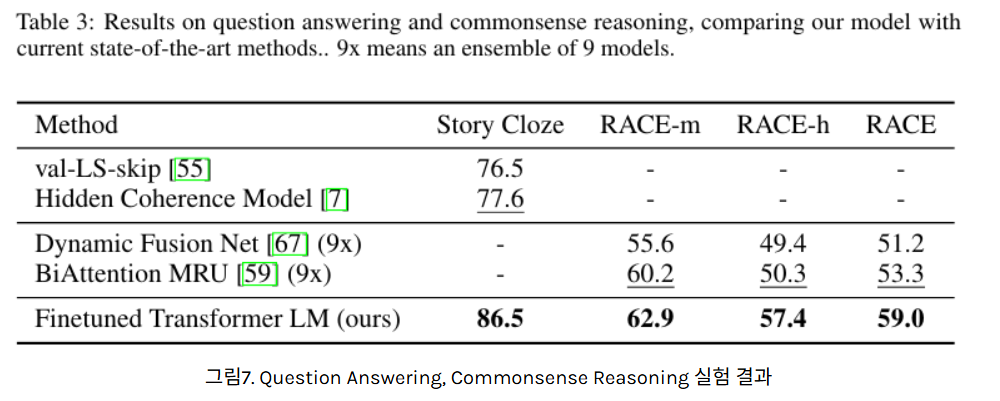
역시 모든 테스크에 대해 성능 우수
Semantic Similarity & Classification
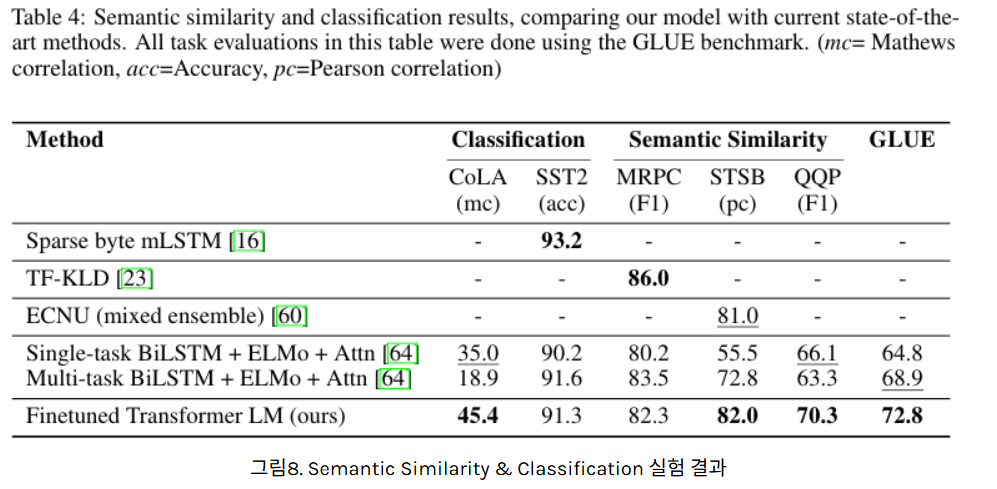
일부 제외 우수한 성능
Analysis
Impact of Number of Layers Transferred & Zero Shot Behaviors
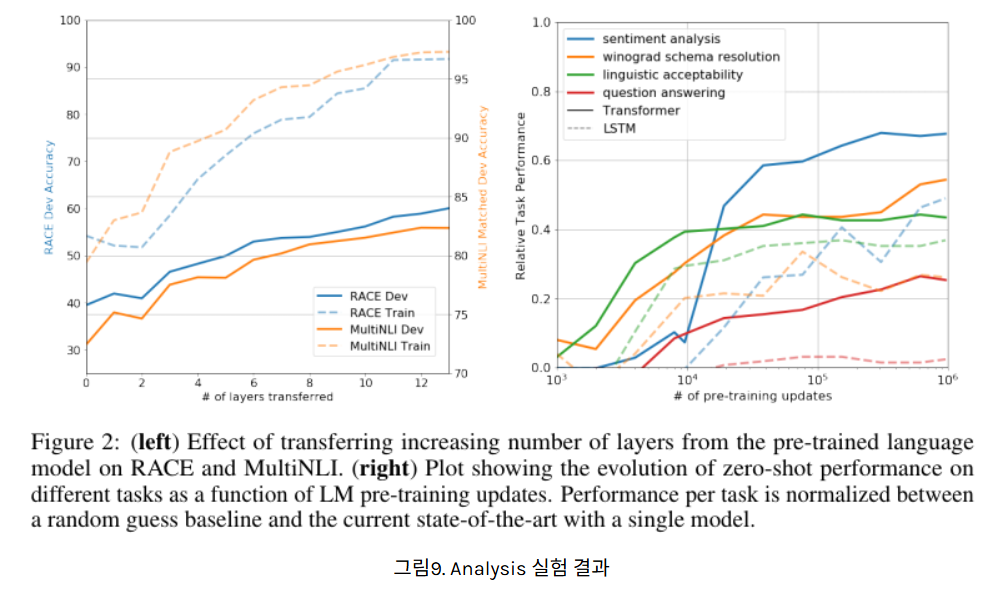
완쪽 그래프는 pre-train 이후 몇개의 레이어를 전이하여 fine-tuning 했고, 이때의 성능 차이를 분석한 그래프이다.
0-12개 기준 레이어 수를 많이 전이(transfer) 해서 fine-tuning 할수록 RACE(질문 응답), MultiNLI(문장관계파단) task 모두 더 좋은 성능
GPT 의 fine-tuning 성능 입증
오른쪽 그래프는 다양한 task 에 대해 사전학습 업데이트 수 증가에 따라 zero-shot (즉 fine-tuning 안하고도 정답 출력 얼마나 내놓을 수 있나) 성능 향상함을 볼 수 있다.
GPT 의 pre-training 성능 입증
정리
✅ 1. Pretraining + Finetuning 패러다임 도입
✅ 2. Transformer Decoder만 사용
✅ 3. Few-shot/Zero-shot Learning의 가능성
✅ 4. 범용 언어모델 (BERT 도 이 부분은 마찬가지, Encoder based 이지만) 제안 -> task 마다 구조 변형 필요 없음
<용어>
✅ Representation: 단어, 문장, 문서 등 언어 단위를 컴퓨터가 이해하고 처리할 수 있도록 만든 수치 벡터(또는 텐서)
