BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (2019)
Text & Speech Papers
📌 틈틈히 정리하는걸로...아마 꽤나 몰아서 올릴것 같지만...얼마 전에 리뷰 끝낸 BERT 논문부터.
📌 Original Paper : https://arxiv.org/abs/1810.04805
Abstract
BERT (Bidirectional Encoder Representations from Transformers) 는 말 그대로 Transformer 구조의 인코더 구조를 사용한 모델이다. Unlabeled data 로부터 pre-train을 진행 후 특정 downstream task (라벨 있는 데이터) 에 fine-tuning 한 모델이다.
사전학습 + 파인튜닝 방식을 NLP 분야에서 자리잡게 만든 대표적인 방법론으로, pre-trained 된 BERT 모델이 한 output layer 만 추가하면 NLP 의 다양한 구체적 task (Question Answering, Language Inference 등) 을 수행할 수 있다고 함.
이 방법은 논문 나올 때 당시 NLP 다양한 주요 11개의 task 에 대하여 SOTA 달성했다고 설명한다.
Introduction & Related Work
BERT 등장 이전 방법론들을 살펴보면, 이전에는 특정 task 에 대해 pre-trained 된 language representation 을 적용하는 방법이 크게 Feature based approach 와 Fine-tuning approach 가 있었다.
Feature Based Approach
단어 수준의 고정된 벡터 표현을 얻은 후 → 해당 벡터를 task specific 한 모델에 적용하여 학습시키는 방법이다. 대표적인 예시가 ELMo 모델.
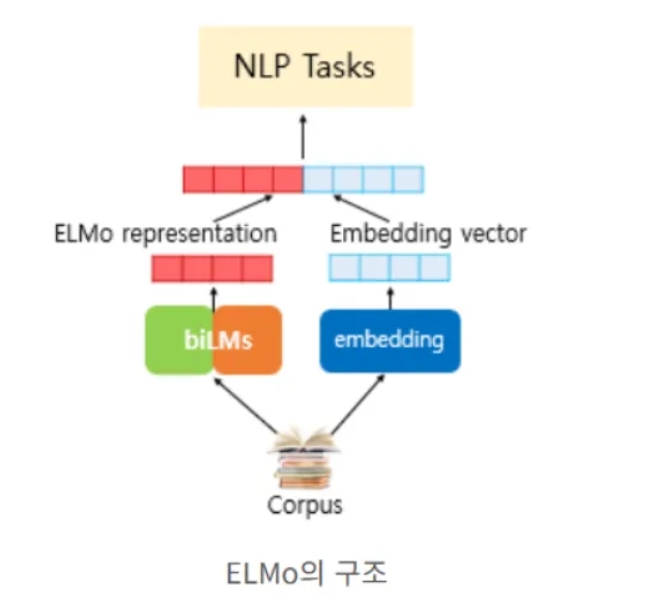
- 입력 문장 → 각 단어의 임베딩 생성
- 임베딩을 모델에 넣고:
- Forward LSTM: 왼→오른쪽 문맥
- Backward LSTM: 오른→왼쪽 문맥
- 각 층의 forward hidden state와 backward hidden state를 concat
- 여러 층의 concat된 결과를 가중합(weighted sum) 해서 최종 ELMo vector 생성
Fine-tuning Approach
하나의 pre-trained 모델을 통째로 불러와서, downstream task에서 전체 모델을 함께 학습시키는 방법
대표적인 예시가 (논문 나온 당시 기준) GPT1
"Left-to-Right" 언어 모델 구조를 가지고 있으며, 앞에 나온 단어 보고 현재 단어 예측하는 방식을 따른다.
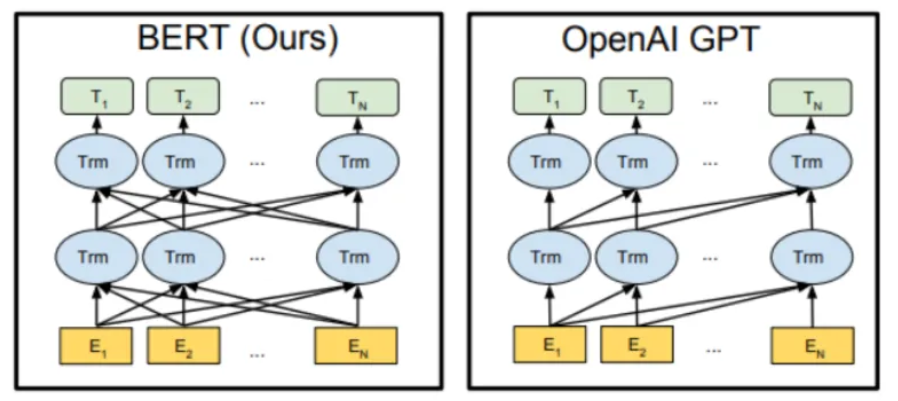
하지만 기존의 두 방식 모두 사전학습 과정에서 이전 데이터들만 사용하는 unidirectional launguage models (단방향 모델)이다.
이러한 방식은 pre-trained representation 효과를 감소시키고ㅡ 특히 Fine-tuning approach 에서 이런 단점이 두드러짐.
- GPT: Left-to-right만 보는 단방향 모델
- ELMo: 양방향 BiLSTM이지만 forward, backward를 독립적으로 학습 (Joint context 아님)
- 이로 인해:
- 특정 단어의 양쪽 문맥을 동시에 반영하기 어려움
- Fine-tuning 시에도 표현력에 한계
그렇게 해서 이런 단점 보완 → BERT
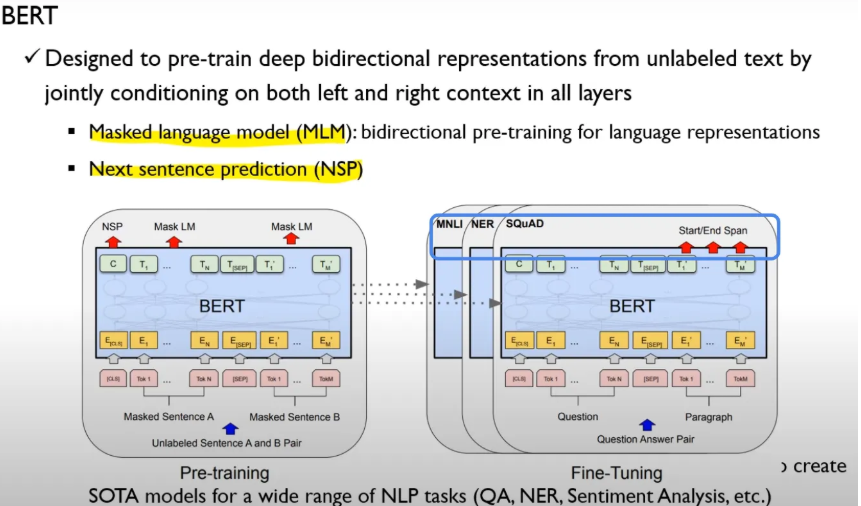
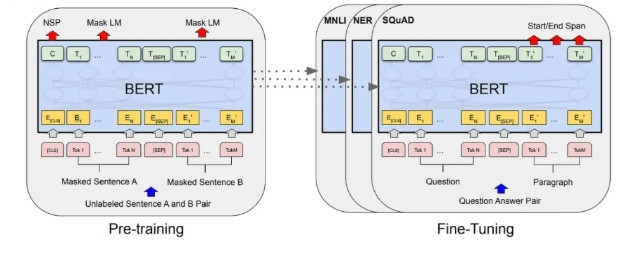
Pre-training + Fine-Tuning 방법으로 구성되어 있으며, Pre-training 은 Masked Language Model + Next Sentence Prediction 과정으로 이루어져 있음 → 이후 task specific 하게 넘어가 fine-tuning 해주는 구조.
BERT

모델 아카텍처
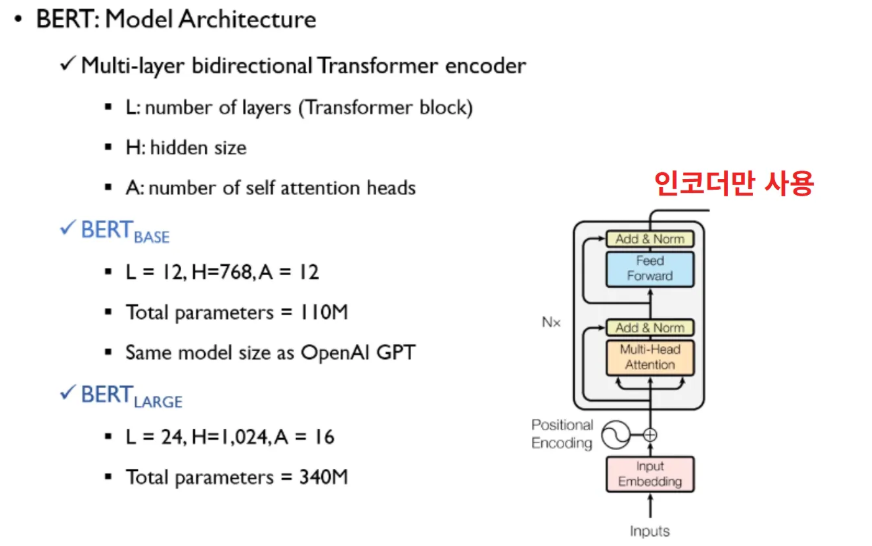
- BERT 는 Transformer 의 인코더 블록만 사용한다.
- L: 레이어 개수 (Transformer block 몇개 사용했나)
- H: 히든 사이즈
- A: 멀티 헤드 어텐션 몇개인지
BERT Base : 레이어 개수 12개 히든 사이즈 768차원, 어텐션 헤드 12개
전체 파라미터 1억 1000만개
GPT 크기와 유사하게 만들어 연구 진행
Tokens
아래 그림은 Pre-Train 과정의 MLM + NSP 과정 두개 같이 표현한 그림
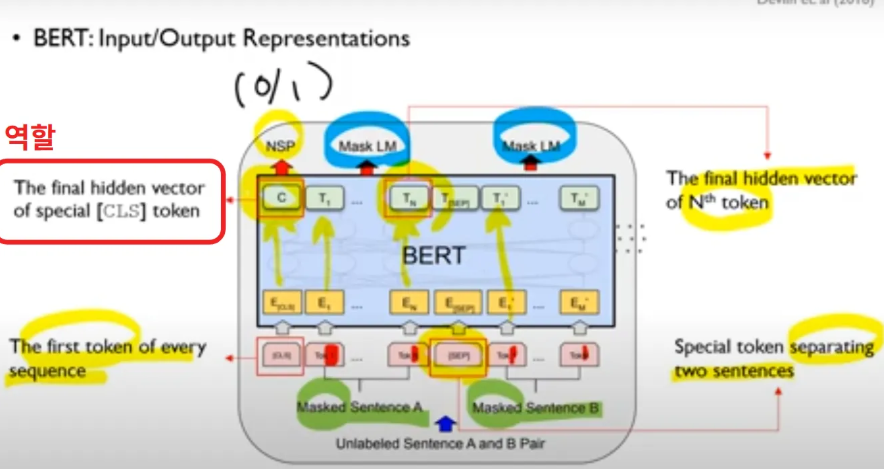
- Input : Masking 이 된 문장 2개 A, B
- CLS - 문장 시작을 알려주는 토큰
- SEP: 두 문장 구분시켜주는 token
- Tn → 각 위치 대응하는 토큰 (final hidden vector)
- C(NSP) - classification task 위해 사용 → CLS 토큰의 마지막 hidden state 출력하고, NSP (Next Sentence Prediction) 시 사용 or fine-tuning 때 특정 task 에 대해 사용
Representations
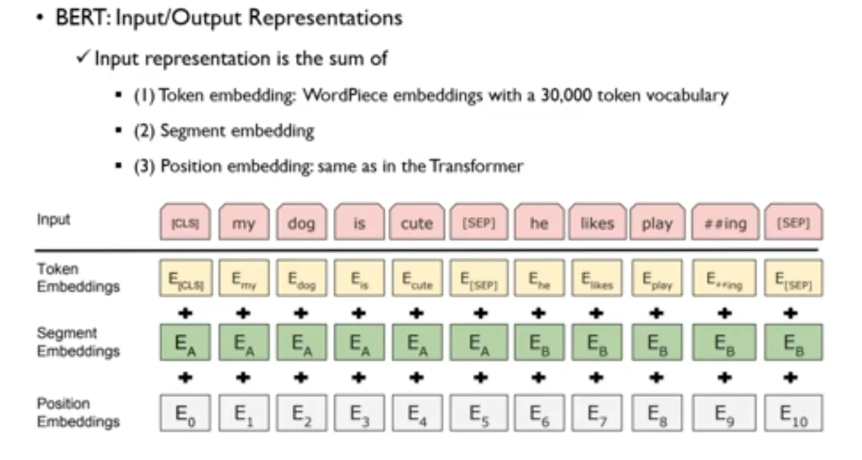
Token Embedding : WordPiece tokenizer로 분리된 subword 단위 토큰 각각에 대해 고유한 임베딩
ex. playing 이면 play 와 ing 로 나눈 형태의 임베딩
Segment Embedding : BERT는 두 문장 (sentence A, sentence B) 을 동시에 입력으로 받기 때문에, 각 토큰이 어떤 문장에 속해 있는지를 나타내는 임베딩
Position Embedding : Transformer는 순서를 고려하지 않기 때문에, 각 토큰의 위치 정보를 알려주는 순서 기반 임베딩
Pre-Training BERT: Masked LM
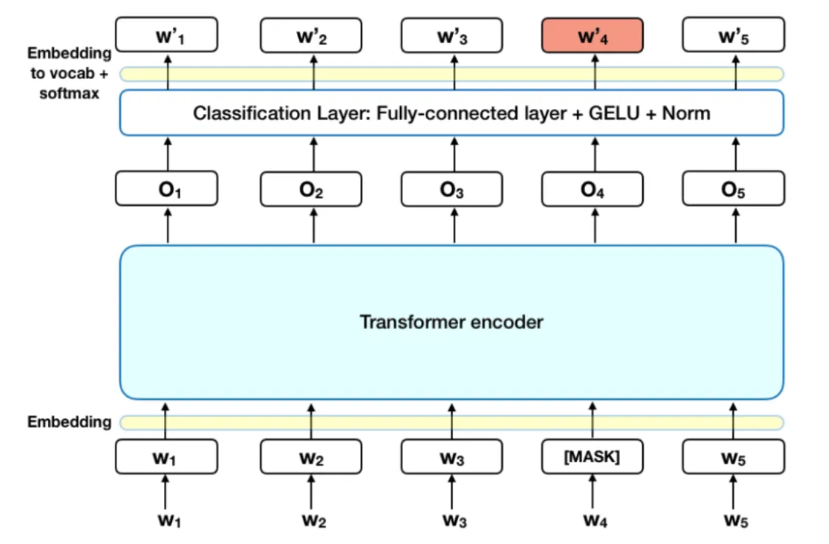
ex) w4 단어가 마스팅 됨 → 인코더 → 한개의 classification layer 지나서 w4’ 가 w4 가 되도록 학습시키는 과정이 masked language model 과정이다.
이처럼 양방향으로 학습을 시키되, 가려진 단어를 예측하도록 학습시키는 과정이 masked language model 의 목적.
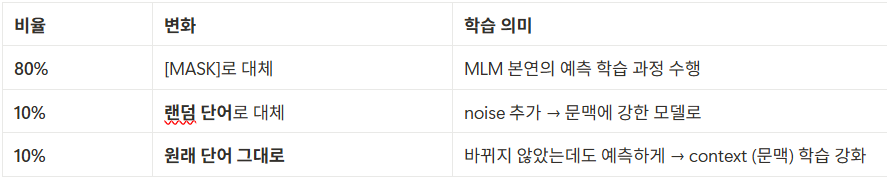
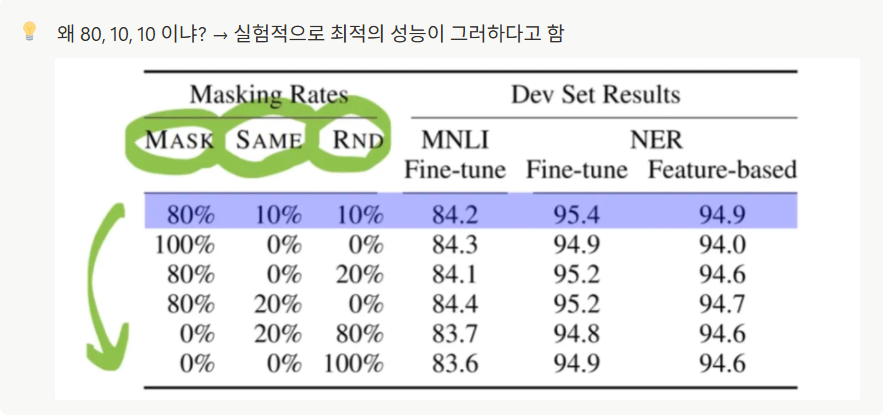
틀린 정보도 주고, 정답도 보여주면서 mask 된 단어 맞추는 과정에서 context 학습을 강화시킴
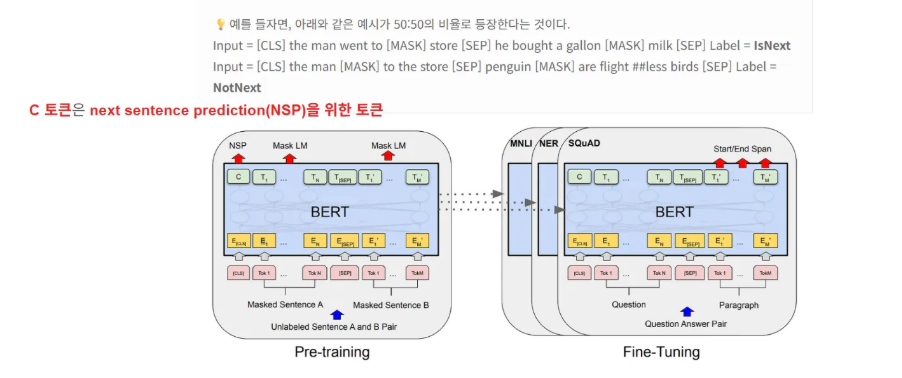
Pre-Training BERT : Next Sentence Prediction (NSP)
많은 NLP의 downstream task(QA, NLI 등)는 두 문장 사이의 관계를 이해하는것이 핵심
BERT의 pre-training 과정에서는 NSP(Next Sentence Prediction)이라는 태스크를 통해 두 문장 A와 B가 주어졌을 때, 50%는 실제 연속 문장 쌍(IsNext), 50%는 무작위 문장 쌍(NotNext)으로 구성하여 학습시킨다.
입력의 첫 토큰인 [CLS]의 최종 hidden state를 NSP classifier에 통과시켜, B 문장이 A의 다음 문장인지 아닌지를 이진 분류로 예측하게 한다.
→ 이를 통해 모델은 문장 간 문맥 관계를 학습할 수 있다.
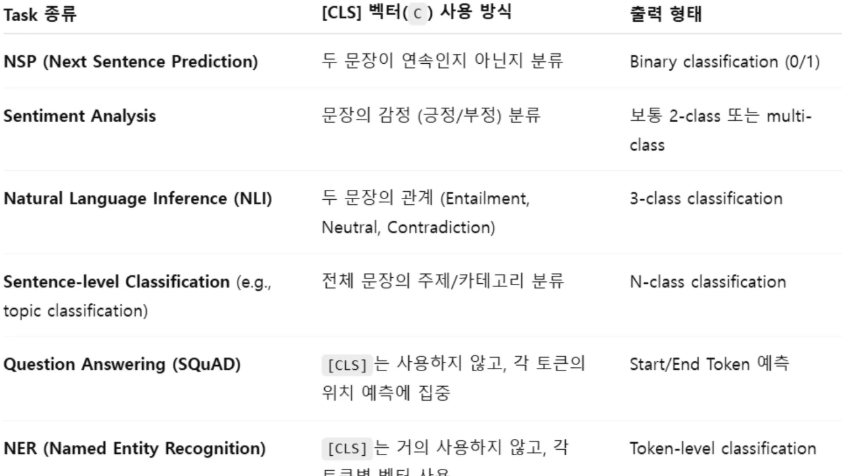
Fine-tuning BERT
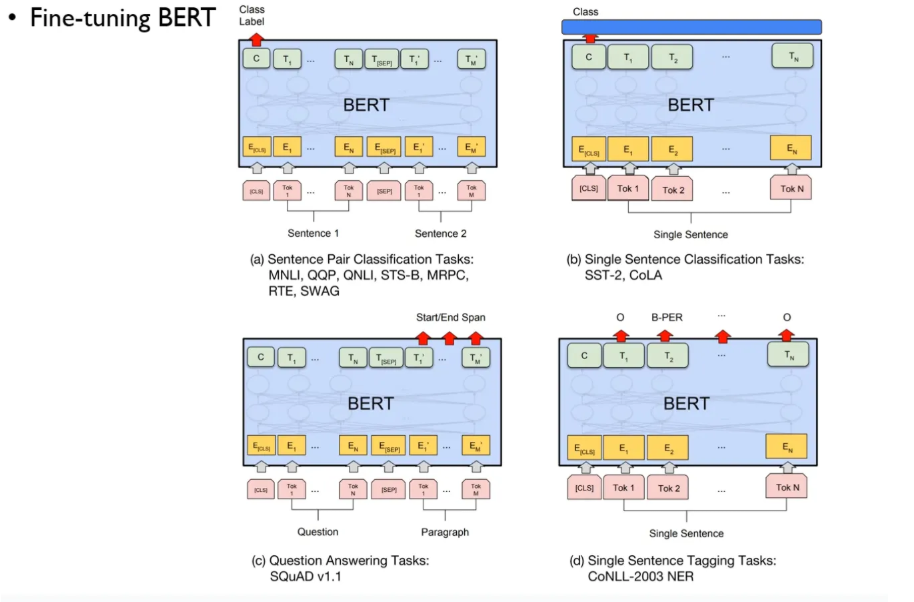
a. 두 문장이 같은 의미인지, 모순인지, 이어지는지 등 두 문장 간 관계 판단
b. 감정, 문법성 등 문장 하나에 대한 속성 분류
c. 질문에 대한 정답이 문단의 어디에 있는지 찾기 (Q&A)
d. 문장 속 단어마다 사람/장소/기관 등 표시하기 (NER, 이름 인식 등)
Experiment
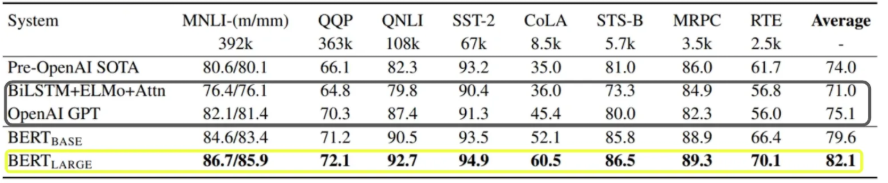
실험 결과를 보면 앞서 말한 이전 방법론들보다 BERT base 와 비교해도 유의미한 성능 향상이 있었고, BERT large 와 비교하면 확 튀는 큰 성능 차이가 모든 task에서 보임을 알 수 있다.
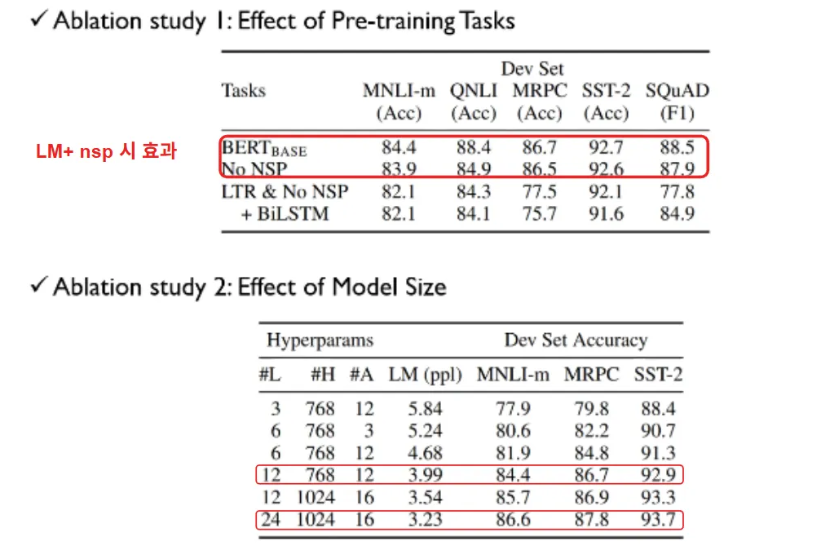
- LM + NSP 둘 다 적용한 BERT 와 no NSP (only masking) 비교시 두개 이상의 문장을 이해야 하는 Q&A task 인 SQuAD 는 성능 향상이 분명이 있었다.
- BERT Large, 즉 모델의 구조가 커지면 성능이 좋아지더라
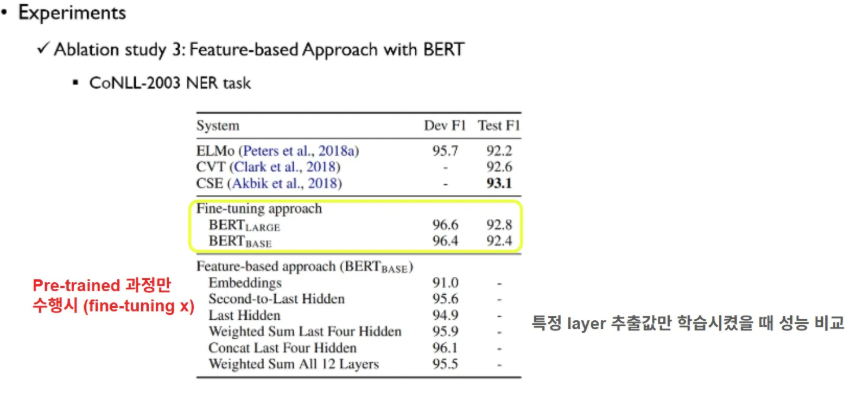
위에는 전체 BERT 학습된거, 밑에는 fine tuning 적용 안하고 pre-training까지만 수행하고 고정(freeze) 한 채, 특정 레이어의 출력만 꺼내어 학습시켜 성능 비교한 것 → pre-training 도 꽤 성능 좋다 의미함
📌 논문 의의
Pre-training + Fine-tuning 패러다임의 표준화
- 기존에는 NLP task마다 별도 구조 설계와 학습 방식이 필요했으나, BERT는 하나의 사전학습 모델을 다양한 task에 일관되게 fine-tuning하는 접근 제시
- Masked Language Model (MLM) 기반의 양방향 문맥 학습으로 다양한 언어 이해 task에서 더 강력한 표현력 확보
- 단순한 task-specific layer만 추가하면, 문장 분류, 개체명 인식, 질의응답 등 다양한 task에 쉽게 적용 가능
- NLP에서 Transfer Learning의 실용적 표준을 정립하고, 이후 언어 모델 설계의 기본 틀로 자리잡음 (ex. RoBERTa, ALBERT, T5 등)
