AI Tech Day 7 (Optimization)

1. 오늘 일정
1) 학습
2) 도메인 특강
3) 피어 세션
4) 시각화 마스터 클래스
2. 학습 내용
DL Basic
3강: Optimization
Important Copcepts in Optimization
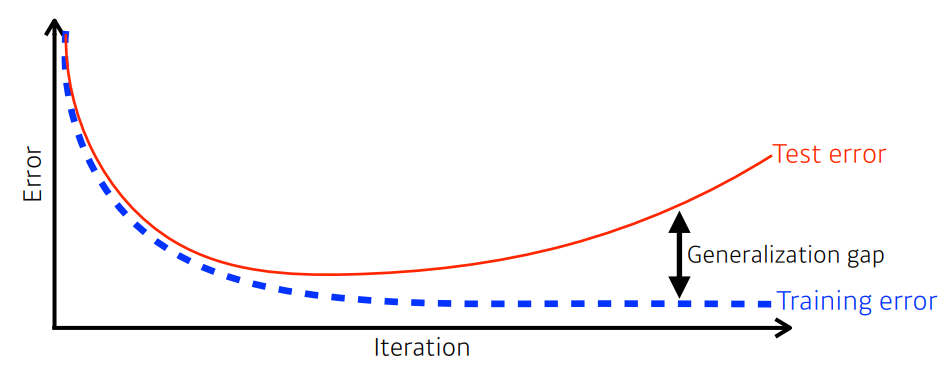
Generalization
- Training error와 Test error의 차이
- Generalization 성능을 높이는 것이 목적이다
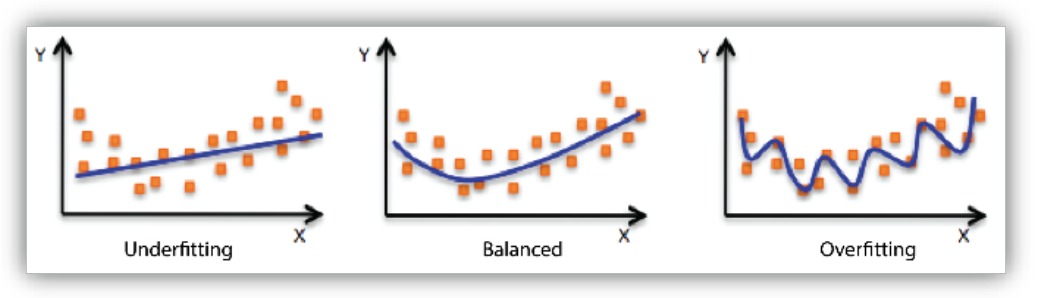
Underfitting vs Overfitting
- Underfitting: too bias하게 train되어, 제대로 학습되지 않은 모델
- Overfitting: high variance하게 train되어, 새로운 데이터에 대해서는 예측하지 못하는 모델
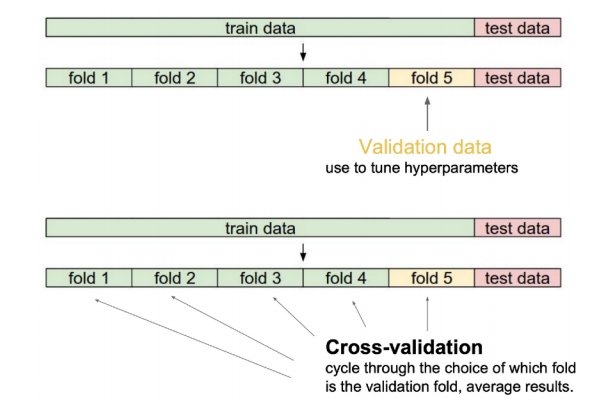
Cross-validation
- K-fold validation이라고 도 함
- 훈련 데이터세트를 Fold라고 하는 단위로 k개로 나누어 따로 학습을 진행하고 성능을 평가한다. 이후 평균을 측정한다
- 결과를 통해 lr, loss function등의 하이퍼파라미터 조정에 사용될 수 있다
Bias and Variance
- 편향: 잘못된 가정을 했을 때 발생하는 오차 -> 언더피팅
- 분산: 트레이닝 셋에 내재된 작은 변동 때문에 발생하는 오차 -> 오버피팅

Bootstrapping
- 가설 검증(test)하거나 메트릭(metric)계산 전에 random sampling을 적용하는 방법
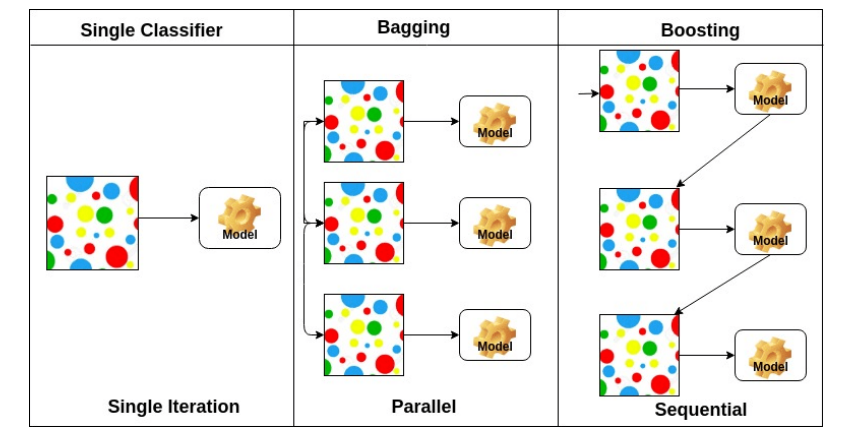
Bagging vs Boosting
- Bagging: Bootstrapping으로 다수의 모델이 학습된다.
- 샘플을 여러 번 뽑아(Boostrap) 각 모델을 학습시켜 결과물을 집계(Aggregration)하는 방법
- Boosting: 가중치를 활용하여 weak learner를 strong learner로 만드는 방법
Gradient Descent Method
- Stochastic gradient descent: single sample로부터 계산
- Mini-batch gradent descent: subset of data로부터 계산
- Batch gradient descent: whole data로부터 계산
Batch-size의 중요성
- large batch일수록 sharp하게 수렴하는 경향이 있고 small batch일수록 flat하게 수렴하는 경향이 있음 (On Large-batch Training for Deep Learning: Generalization Gap and Sharp Minima, 2017)
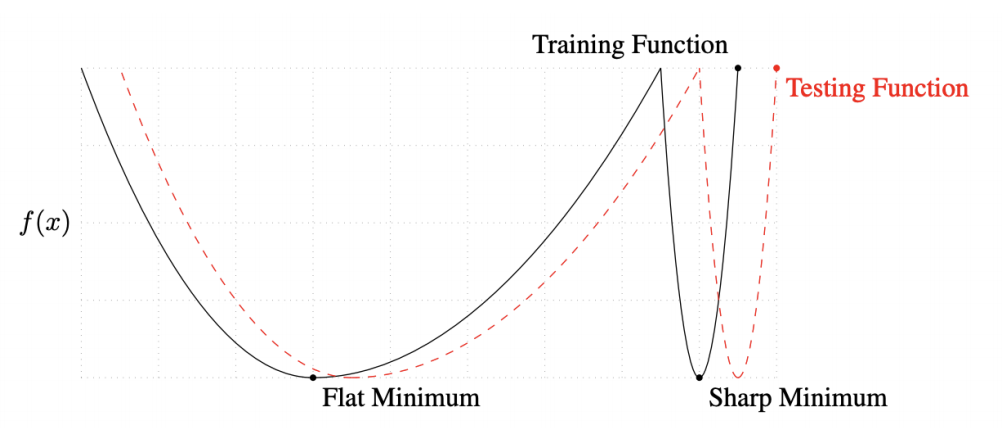
- 따라서 flat한 경우가 genelization performance가 높을 확률이 높고 small batch가 더 좋은 경향을 보인다
Gradient Descent Methods
Gradient Descent
- = Learning rate, = Gradient
- 를 적절하게 설정하는게 어렵다.
Momentum
- 이전 gradient 방향 정보를 활용 진동현상을 줄여주면서 빠르게 이동
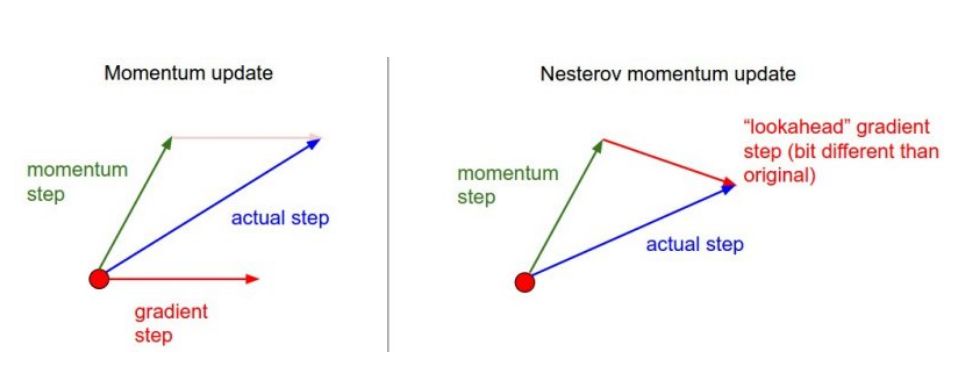
Nesterov Accelerated Gradient
- Nesterov는 momentum을 갔다고 가정하고 그레디언트 계산
Adagrad
= Sum of gradient squares, = for numerical stability
- 가 상당히 커지면 학습이 멈춘다는 단점
Adadelta
- Adadelta는 Adagrad의 extension으로 분모가 과도하게 커지는걸 막기 위해 가중평균을 취해준다.
= EMA of gradient squares, = sepsize- Adadelta에서는 학습률이 없다
RMSprop
Adam
- Adam은 모멘텀과 adaptive learging rate를 합친것이다
Regularization
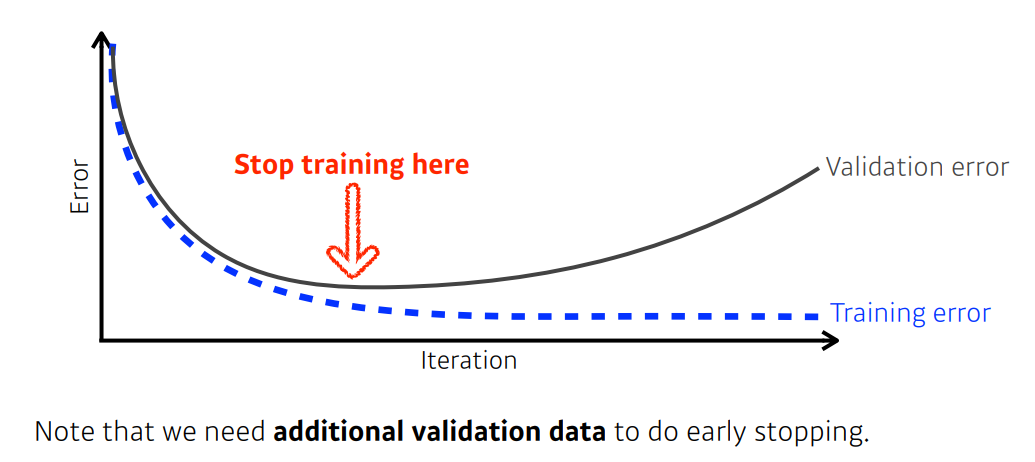
Early stopping
Parameter Norm Penalty
- 파라미터가 너무 커지지 않게 조정
Data Augmentation
- 데이터는 많을수록 좋다.
- 하지만, 대부분의 경우에 training data는 미리 주어져 있다.
- 따라서 우리는 data augmentation을 사용한다.
Noise Robustness
- input과 weight에 랜덤한 noise를 추가

Label Smoothing
- decision bound를 부드럽게 만들어준다

Dropout
- 랜덤으로 몇몇 가중치를 0으로 만들어준다
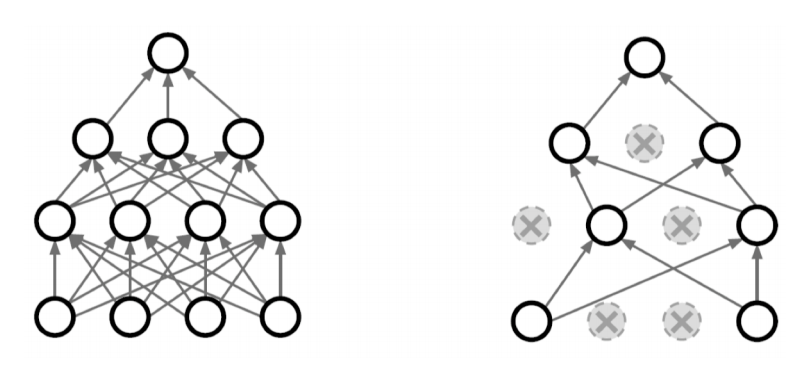
Batch Normalization
- 레이어의 statitics를 정규화한다.
Data Viz
2-1강: Bar Plot
Bar plot이란?
- 직사각형 막대를 사용하여 데이터의 값을 표현하는 차트/그래프
- 막대 그래프, bar chart, bar graph 등의 이름으로 사용됨
- 범주에 다른 수치 값을 비교하기에 적합한 방법
막대의 방향에 따른 분류 (.bar() / .barh())
- 수직 (vertical): x축에 범주, y축에 값을 표기 (default)
- 수평 (horizontal): y축에 범주, x축에 값을 표기. (범주가 많을 때 적합)
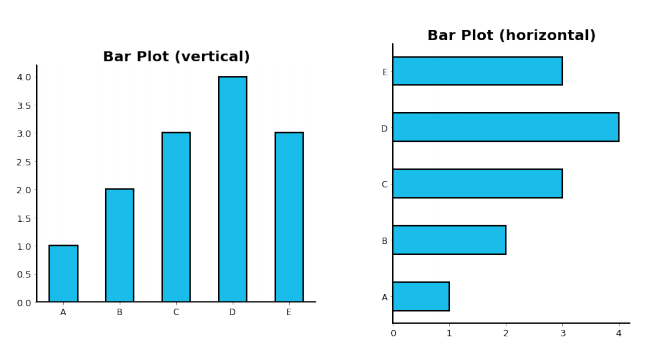
다양한 Bar Plot
Multiple Bar Plot
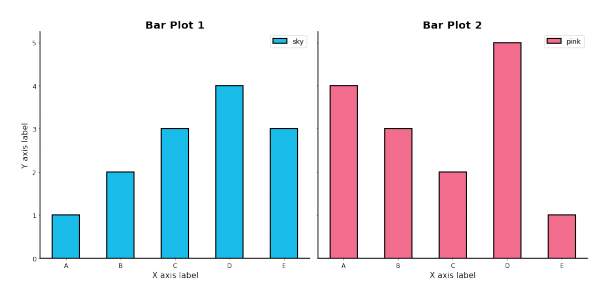
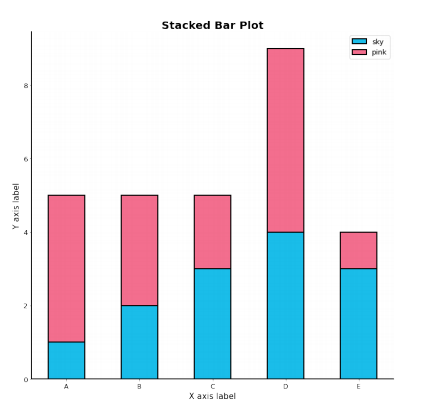
Stacked Bar Plot
- 2개 이상의 그룹을 쌓아서 표현하는 bar plot
- 맨 밑의 bar의 분포는 파악하기 쉽지만
- 그 외의 분포들은 파악하기 어려움
- .bar()에서는 bottom파라미터를 사용
- .barh()에서는 left파라미터를 사용
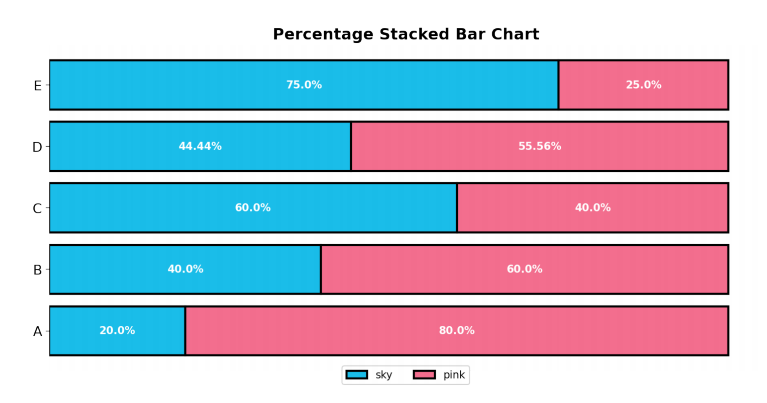
- 응용하여 전체에서 비율을 나타내는 Percentage Stacked Bar Chart가 있음
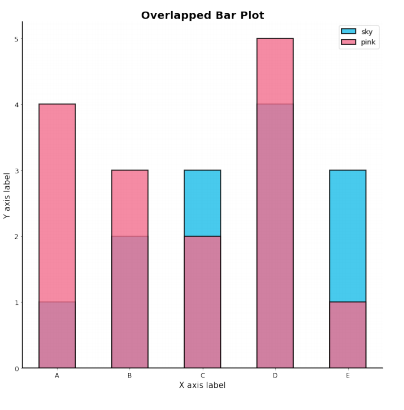
Overlapped Bar Plot
- 2개 그룹만 비교한다면 겹쳐서 만드는 것도 하나의 선택지
- 같은 축을 사용하니 비교가 쉬움
- 투명도를 조정(alpha)
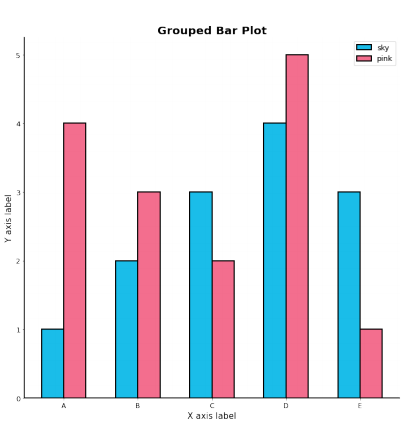
Grouped Bar Plot
- 그룹별 범주에 따른 bar를 이웃되게 배치하는 방법
정확한 Bar Plot
Principle of Proportion Ink
- 실제 값과 그에 표현되는 그래픽으로 표현되는 잉크 양은 비례해야 함
- 반드시 x축의 시작은 zero(0)
데이터 정렬하기
- 더 정확한 정보를 전달하기 위해서는 정렬이 필수
pandas에서는 sort_values(), sort_index()를 사용- 데이터의 종류에 따라 다음 기준으로
- 시계열 | 시간순
- 수치형 | 크기순
- 순서형 | 범주의 순서대로
- 명목형 | 범주의 값 따라 정렬
적절한 공간 활용
- 여백과 공간만 조정해도 가독성이 높아진다
- Matplotlib techniques
- X/Y axis Limit (.set_xlim(), .set_ylim())
- Spines (.spines[spine].set_visible())
- Gap (width)
- Legend (.legend())
- Margins (.margins())
복잡함과 단순함
- 필요 없는 복잡함은 NO! (비교가 어려움)
- 축과 디테일 등의 복잡함
- Grid (.grid())
- Ticklabels (.set_ticklabels())
- Text 추가 (.text(), .attnotate())
etc
- 오차 막대를 추가하여 Uncertainty 정보를 추가 가능(errorbar)
- Bar 사이 Gap이 0이라면 -> 히스토그램(Histogram)
- .hist()를 사용하여 가능
- 연속된 느낌을 줄 수 있음
- 다양한 Text 정보 활용하기
- 제목 (.set_title())
- 라벨 (.set_xlabel(), .set_ylabel())
3. 피어 세션 정리
- optimizer에 대한 요약
- cross-validation으로 어떻게 하이퍼 파라미터를 튜닝하는가?
4. 과제 수행 과정
- 강의 내 포함
5. 회고
- 시각화는 주말에 실제 데이터로 연습해보면 좋을 듯
- 파이토치는 간단하게 강의를 듣자 내일이나 여유로울 때
6. 내일 할 일
- 깃허브 특강
- cnn 강의 & 과제
- 시각화 남은거 or 파이토치 공부

AI가 세상을 바꾼다. 열심히 AI를 배워서 선한 영향력을 펼치는 개발자가 되고싶다. 인생은 Gradient Descent와 같지.