AI Tech Day 8 (CNN, github)

1. 오늘 일정
1) pytorch 공부 (7시 ~ 9시)
pytorch 기초 깃허브 코드
2) CNN 강의 학습 (AM 9시 ~ 12시,PM 3시반 ~ 4시반)
3) git 특강 (PM 1시 ~ 3시반)
4) 피어세션 (4시반 ~ 6시)
2. 학습 내용
DL Basic
4강: CNN
Convolution
이산형
연속형
2D image convolution
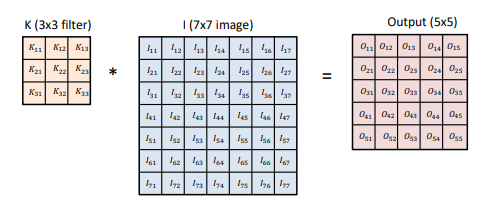
- 입력데이터의 채널 수 = 커널의 채널 수
Stride & Padding
- Stride는 합성곱 연산시 커널을 움직이는 간격을 말한다
- Padding은 합성곱 연산시 생기는 가장자리의 정보손실을 막기 위해 임의의 값을 채우는 방법이다. 주로 0을 채운다.
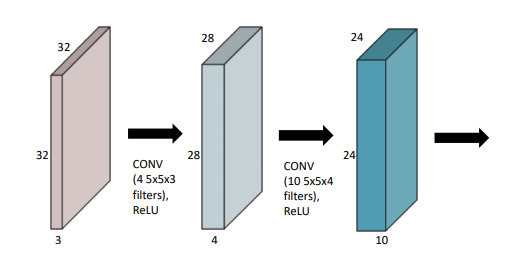
파라미터 계산해보기
- 파라미터 수 = 커널 크기 커널 크기 인풋 채널 수 * 아웃풋 채널 수가 된다.
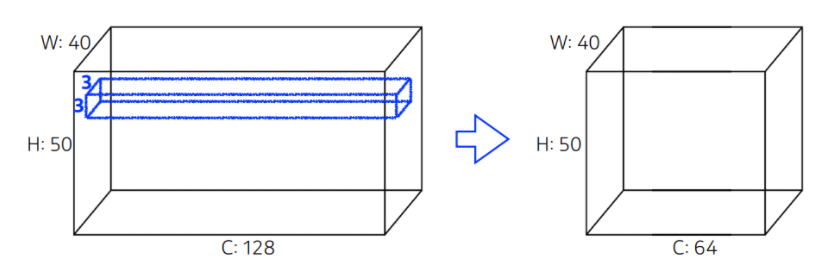
- 따라서 위의 파라미터 수는
5강: Modern CNN
AlexNet
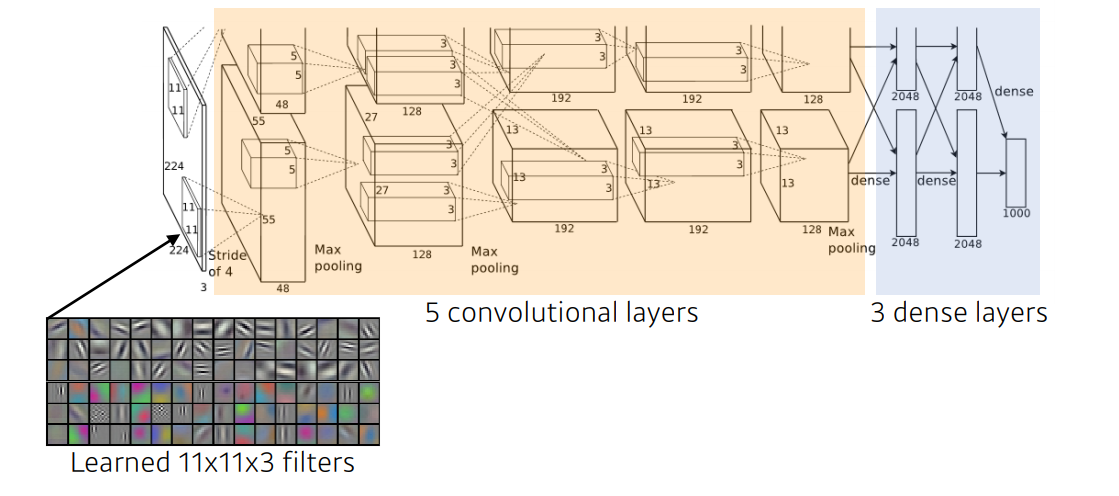
- AlexNet은 2012년 ILSVRC에서 최초로 DL을 이용하여 수상한 모델이다
- RELU를 활성화 함수로 사용하여 sigmoid / tanh가 가지는 gradient vanishing 문제를 해결했다
- 이미지 사이즈에 비해 GPU VRAM이 부족하여 2개의 GPU를 이용하여 합치는 방법을 사용했다
- Local response normalization: 같은 위치의 픽셀에 대해 정규화 적용
- Overlapping pooling: 일반적으로 중복되지 않은 영역을 pooling하지만, AlexNet에서는 Overlapping pooling을 이용했다
- Data augmentation: overfitting 방지(RGB 채널값 변화 등)
- Dropout: overfitting 방지(일부 뉴런의 가중치를 0으로 만들어준다)
- 결론적으로 지금의 기준이되는 많은 방법을 사용하였다.
VGGNet
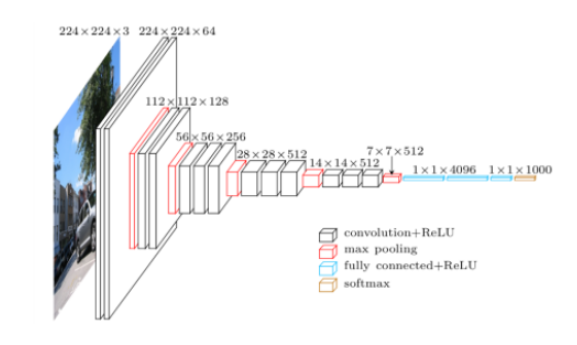
- 3x3 convolution filter만을 사용하여 depth를 증가시킴
- 커널 사이즈가 커지면 receptive field가 커지고, 그만큼 많은 영역의 정보를 파악할 수 있다.
- 반면 학습해야하는 parameter수가 커지는 문제점이 발생
- 따라서 receptive field를 유지하면서 파라미터 수를 줄일 수 있는 방법(3x3 convolution filter)을 사용하였다.
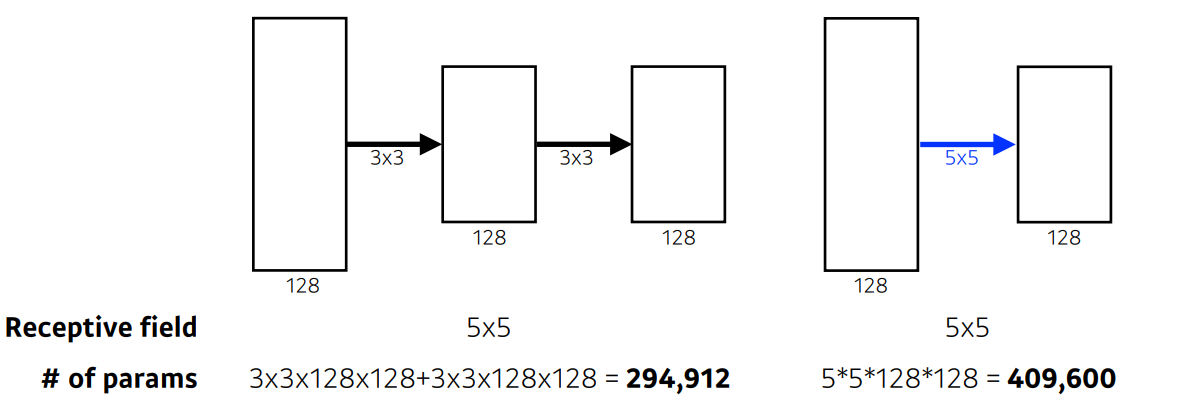
- 같은 receptive filed지만, 파라미터 수가 훨씬 줄어든 것을 알 수 있다.
- Dropout(p=0.5), VGG16, VGG19
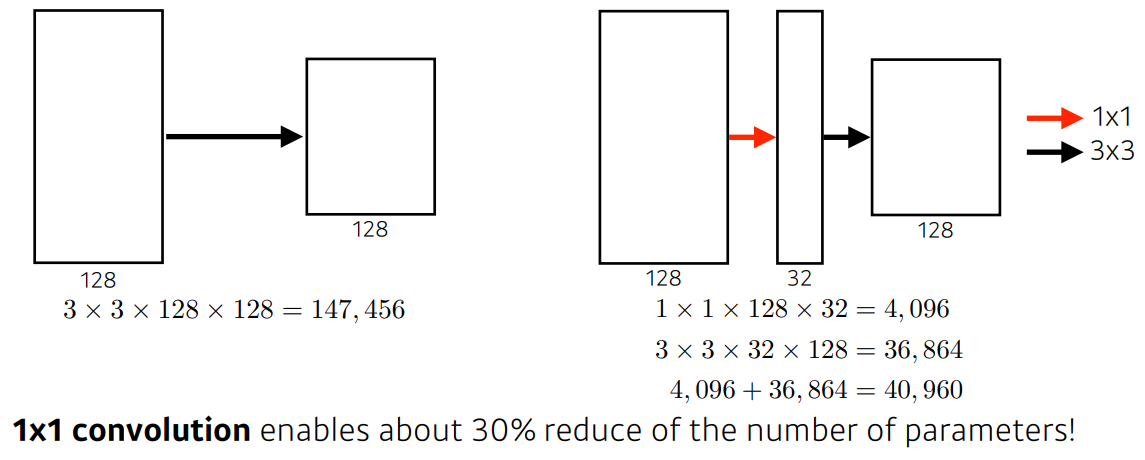
GoogLeNet
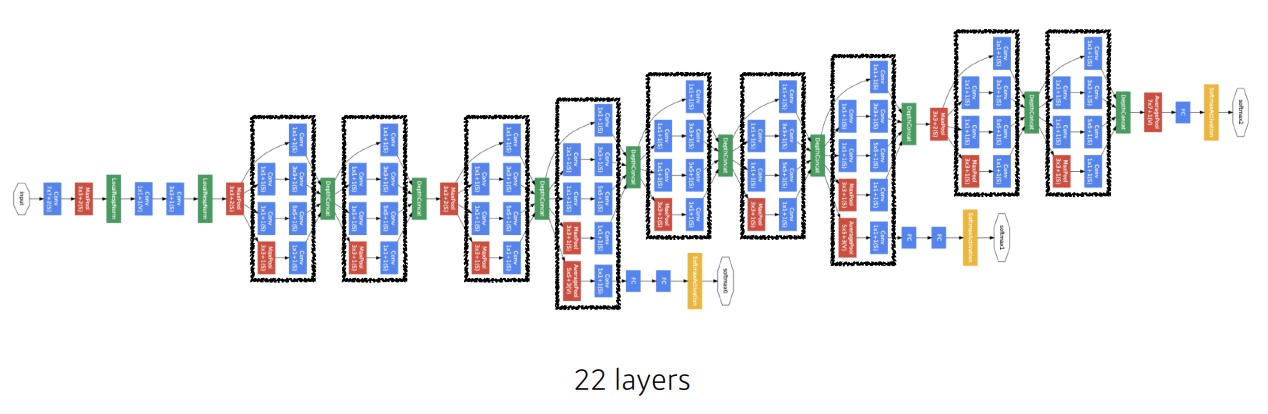
- Inception Block 사용
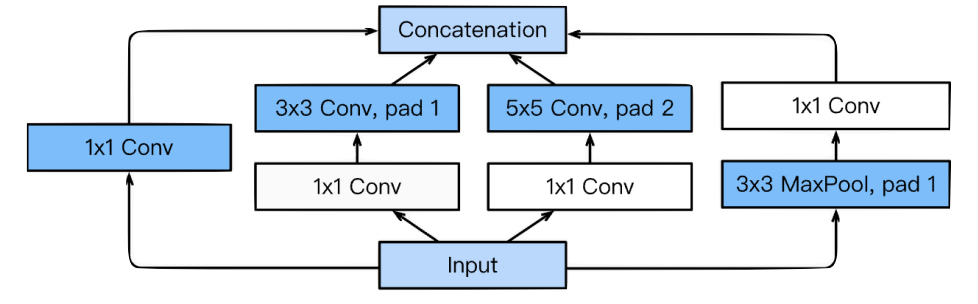
- Inception Block 사용을 통해 파라미터 수를 줄일 수 있게 된다.
- 1x1 convolution이 각 필터에 적용되었기 때문이다.
- 1x1 convolution을 적용하면 같은 receptive field에 파라미터 수를 급격하게 줄일 수 있다.
ResNet
-
ResNet은 다음과 같은 깊이가 깊어졌을 때, 생기는 학습이 안되는 문제를 해결한 모델이다.
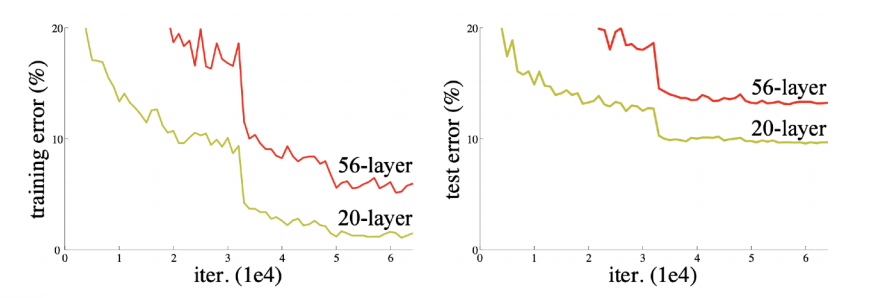
20-layer와56-layer로 테스트 해본 결과gradient vanishing/exploding문제로56-layer가 더 나쁜 성능을 보였고, 무조건 깊게 만드는 것보다 다른 방법을 생각하도록 만들었다.
-
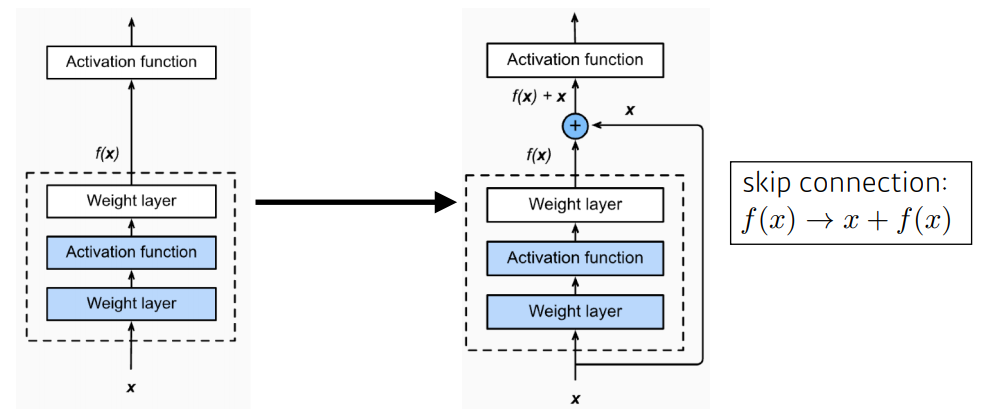
Residual block
- Input x를 더함으로써 Skip Connection을 통해 각각의 Layer들이 작은 정보들을 추가적으로 학습하도록 한다.
- 즉, 기존에 학습했던 정보를 연결하여 추가적으로 학습해야 할 정보만을 Mapping(학습)하게 된다.
-
Batch normalization after convolutions
-
Bottleneck architecture
- 학습 시간을 줄이기 위해 1x1 convolution을 이용한
bottle neck design이 적용되었다.
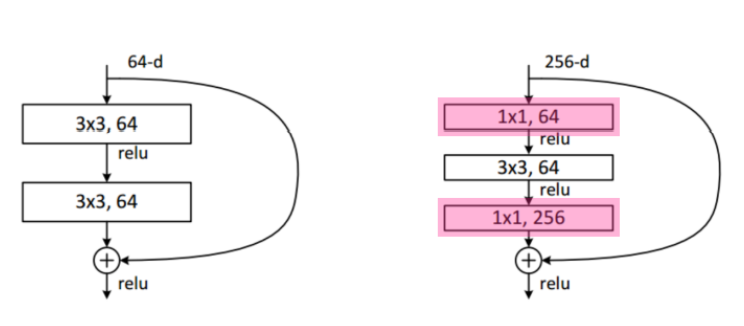
- 학습 시간을 줄이기 위해 1x1 convolution을 이용한
DenseNet
- addition하기보다 concatenation을 사용하여 채널 수가 증가하고 정보 흐름이 향상되는 효과가 있다.
- 채널이 커지고 파라미터의 수가 급격하게 증가해서 transition block을 통해 차원의 수를 줄인다.

요약
- AlexNet은 ReLU, Data augmentation, Dropout 등 지금 cnn의 기준이 되는 많은 방법을 사용하였다.
- VGGNet은 반복된 3x3 필터 사용으로 같은 receptive field를 가져가면서 파라미터 수를 줄였다.
- GoogLeNet은 1x1 convolution의 도입으로 파라미터 수를 급격하게 줄였다.
- ResNet: Block단위로 Parameter를 전달하기 전에 이전의 값을 더하는 Residual Block을 형성하여 기존의 깊이가 깊어지면 생기는 Vanishing Gradient 등의 여러 문제를 해결하였다.
- DenseNet: addition보다 concatenation을 사용하여 채널 수를 증가시키고 이를 통해 성능을 향상시켰다.
6강: Computer Vision Applications
Semantic Segmentation
Semantic Segmentation은 다음처럼 이미지에 있는 모든 픽셀에 대해 예측을 하게 된다.
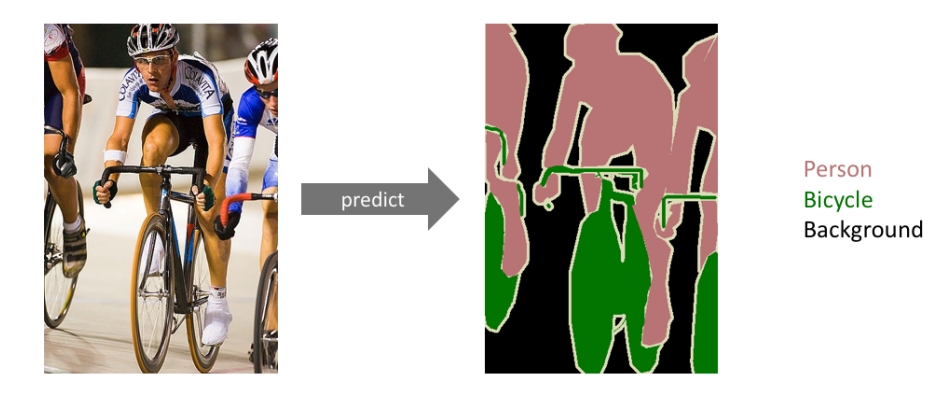
특히 자율주행에 주로 활용된다.
Fully Convolutional Network(FCN)
- 기존의 cnn 모델 뒤쪽에 있는 FC(Fully Connected) layer를 convolution layer로 대체한 것이다.
- FC layer의 경우 입력의 모든 차원을 출력의 모든 차원과 연결되있으므로 입력을 더 크게 만들면 더 많은 가중치가 필요하게 된다. 따라서 고정된 입력 크기를 가질 수 밖에 없다.
- 또한, 각 이미지별로 Flatten과정을 거치기 때문에 이미지의 공간적 정보가 소실된다.
- convolutional layer는 각 채널의 이미지 위치마다 flatten하여 얻는 벡터들을 fully-connected 하게 되므로 공간적 정보가 소실되는 문제를 해결할 수 있다.
- 그래서 convolutional layer는 입력사이즈에 independent하기 때문에 입력 사이즈의 제한을 받지 않고, 공간 정보를 보존할 수 있게 되는 이점이 있다.

Deconvolution
- Convolutionalization을 통해 얻은 heatmap은 하나의 클래스를 대표하는 대략적인 정보이다. 하지만 우리의 목적은 dense prediction이기 때문에 이를 dense map으로 복원하는 deconvolution이 필요하다.
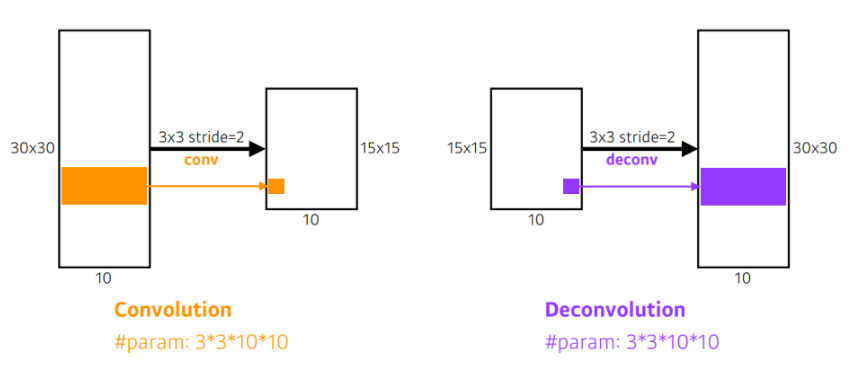
Detection
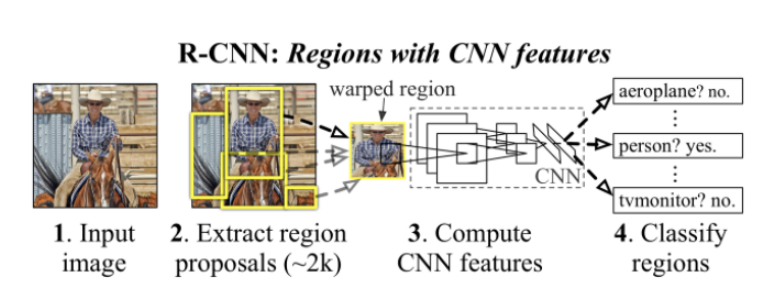
R-CNN
- R-CNN은 이미안에 있는 object의 bounding box를 detection하고 classification을 해주는 모델이다. 다음의 과정을 거친다.
- 인풋 이미지를 받는다.
- Selective Search를 이용하여 약 2000개의 region proposal을 추출한다.
- AlexNet을 활용하여 각 proposal의 feature를 계산한다.
- SVM을 활용하여 object를 분류한다.
SPPNet
- R-CNN은 약 2000개의 region proposal을 각각 CNN에 넣기 때문에 2000번의 CNN 연산이 소요된다는 문제점이 있다.
- SPPNet은 입력 이미지에 대해 CNN 연산을 먼저 적용한 후 feature map에 기반한 region proposal 과정을 거치기 때문에, 1번의 CNN 연산 과정을 거친다.
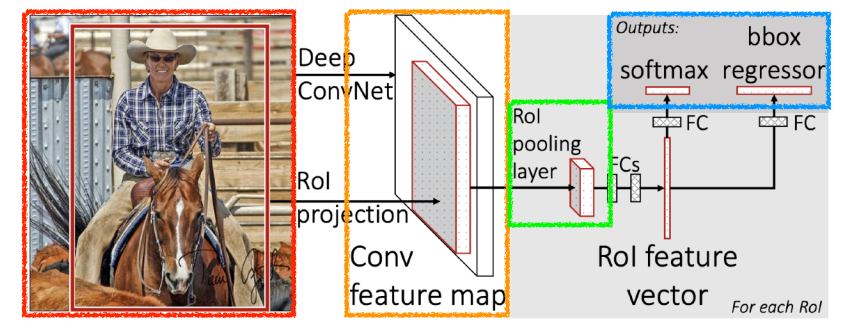
Fast R-CNN
- Fast R-CNN으 ㅣ수행과정은 다음과 같다.
- R-CNN에서와 마찬가지로 Selective Search를 통해 RoI를 찾는다.
- 전체 이미지를 CNN에 통과시켜 feature map을 추출한다.
- RoI를 feature map크기에 맞춰서 projection시키고 RoI Pooling을 진행하여 고정된 크기의 feature vector를 얻는다.
- feature vector는 FC layer를 통과한 뒤, 두 브랜치로 나뉘게 된다.
- 하나는 softmax를 통과하여 RoI에 대해 object classification을 한다.
- 하나는 bounding box regression을 통해 box의 위치를 조정한다.
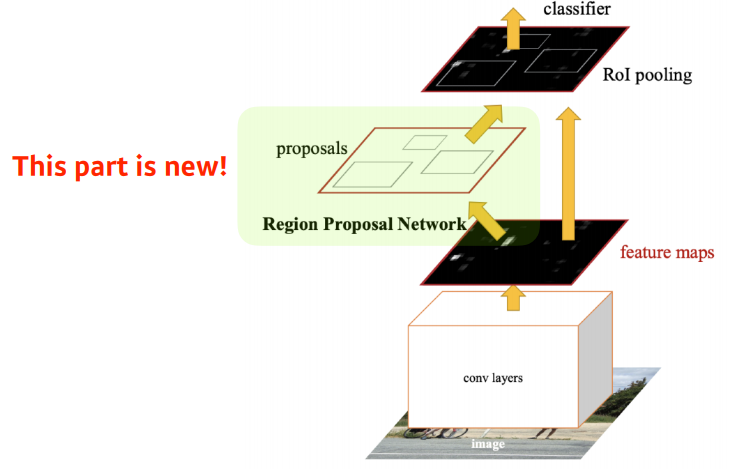
Faster R-CNN
- Fast R-CNN의 확장 모델으로 region proposal 과정 또한 학습시키는 RPN(Region Proposal Network)를 제안하였다.
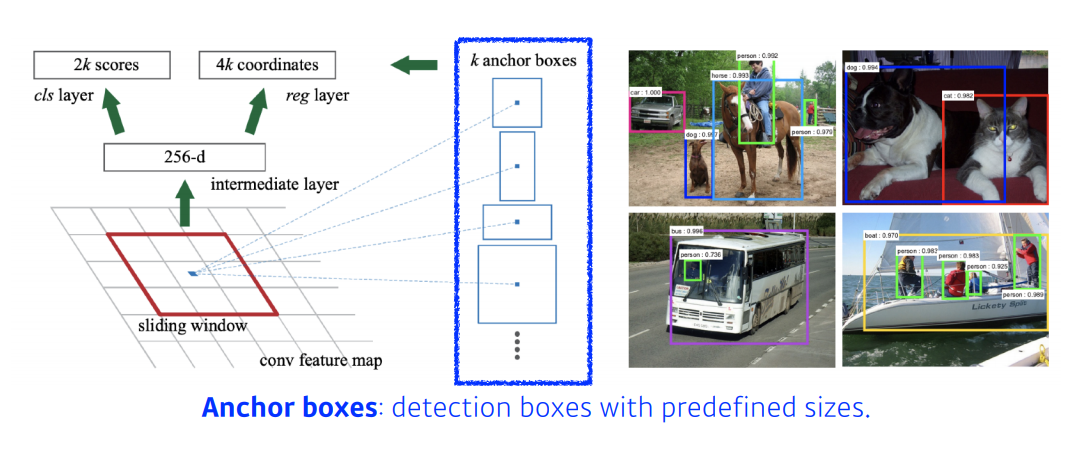
- RPN이란 CNN의 출력 feature map위에
NxNwindow를 입력으로 받고 pre-defined sizes를 바탕으로 각 sliding window의 위치마다reference boxk개를 출력하도록 설계하여 region proposal을 업데이트할 수 있도록 만든 것이다.
YOLO
- 높은 fps 성능을 구현하기 위해서 만들어진 모델이다.
- YOLO는 localization과 classification을 동시에 진행하면서 fps를 높였다.
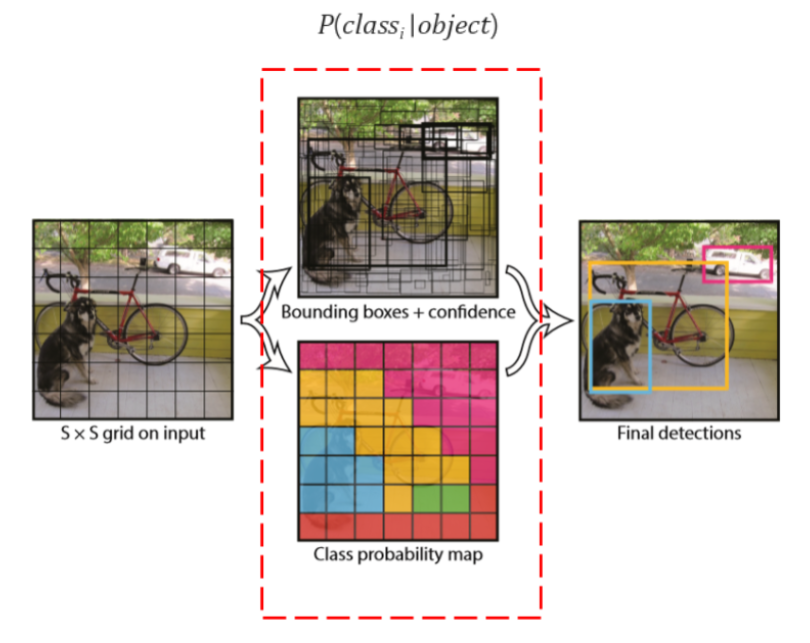
- 다음은 YOLO의 진행 과정이다.
- 이미지에
SxSgrid를 생성한다.- 각 grid 셀마다 각각 Classification과 Localization을 적용한다.
3. 피어세션 정리
- FCN은 왜 Semantic Segmentation에 효과가 있는가?
- 각 채널의 이미지 위치마다 Flatten하여 얻는 벡터들을 FC하게 되므로 공간적 정보가 소실되는 문제를 해결해준다.
- 여러가지 책 추천
4. 과제수행 과정
- 강의와 동일
5. 회고
- 파이토치강의를 아침에 들으면서 조금 친해질 수 있어서 좋았다.
- 깃허브 특강들으면서 협업하는데 어떻게 해야하는지 조금 알게 되었다.
- 시각화 강의는 언제 다듣지?
- 선택 과제는?
- 수학 스터디 공부하고 자야겠다.
6. 내일 할일
- 멘토링때 물어볼 질문 정리
- 수학 스터디때 할 발표 준비
- 강의 듣기
- 가능하면 시각화까지

AI가 세상을 바꾼다. 열심히 AI를 배워서 선한 영향력을 펼치는 개발자가 되고싶다. 인생은 Gradient Descent와 같지.