AI Tech Day 9 (RNN, Transformer)

1. 오늘 일정
- 수학 스터디 공부 (8시 ~ 9시 반)
- 강의 학습 (9시 반 ~ 12시, 3시 반 ~ 4시 반)
- 깃허브 특강 (1시 ~ 3시 반)
- 피어세션(4시 반 ~ 6시)
2. 학습 내용
DL Basic
7강: RNN
Sequential Model
1) Naive sequencee model
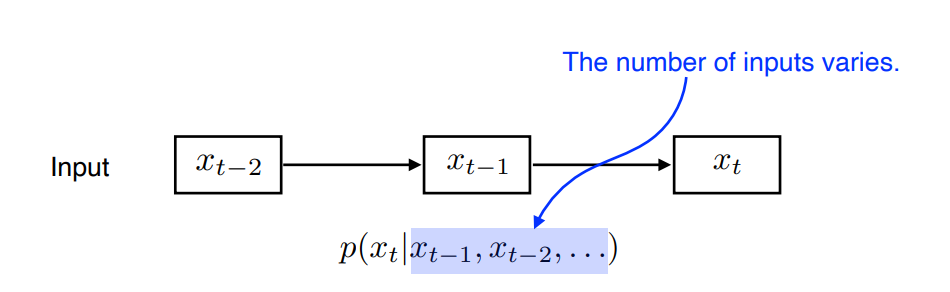
- 몇개의 단어가 입력으로 올지 모른다. 따라서 입력의 크기에 상관없이 동작해야 한다.
2) Autoregressive model
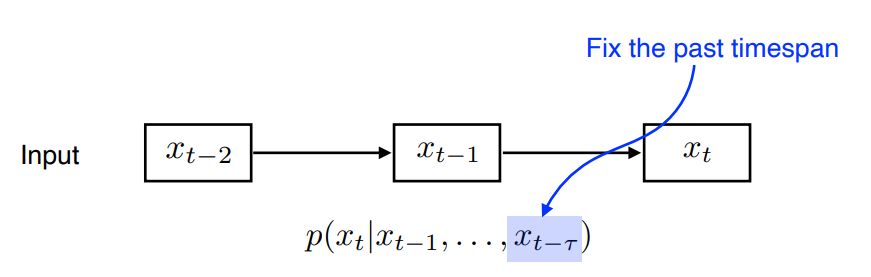
- 과거를 몇개 볼지 기간을 Fix.
3) Markov model
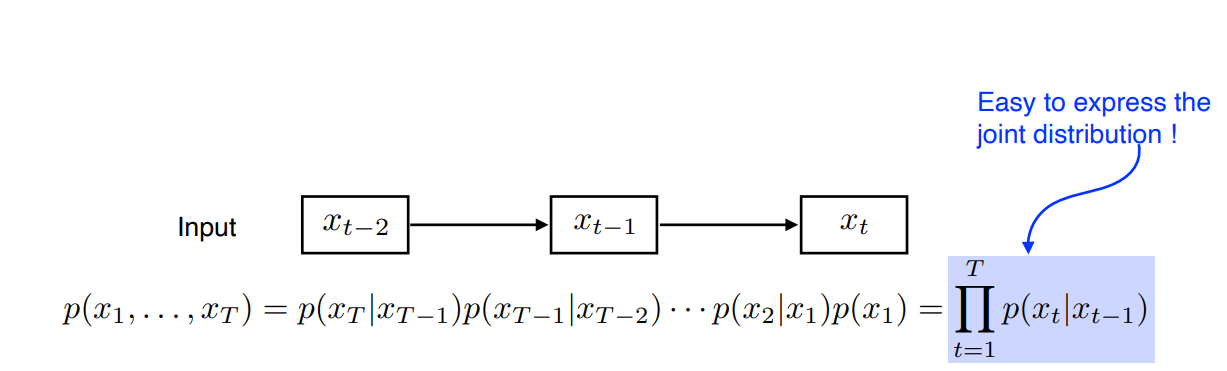
- 현재는 바로 전과거에 dependent하다고 가정한 모델
4) Latent autoregressive model
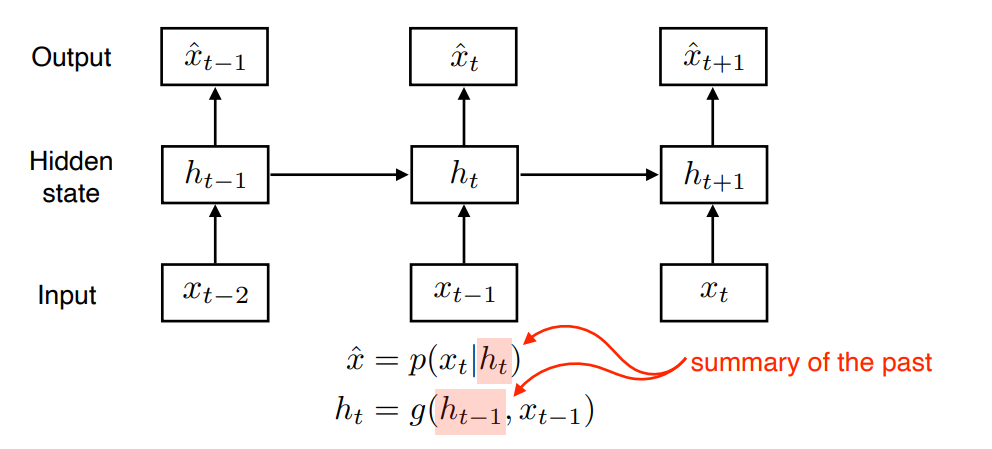
- 중간에 과거가 요약된 hidden state를 넣어 hidden state에만 dependent하도록 만든 모델
RNN (Recurrent Neural Network)
- 자기 자신으로 돌아오도록 만든 모델
- parameter를 share하게 된다
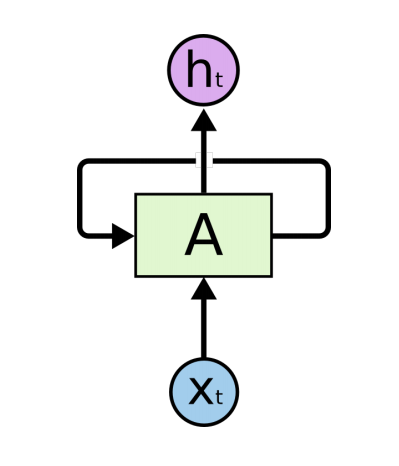
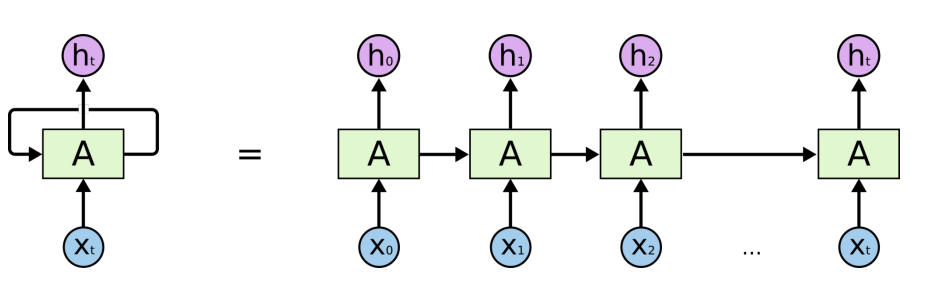
- 다음과 같이 시간순으로 풀 수가 있다.
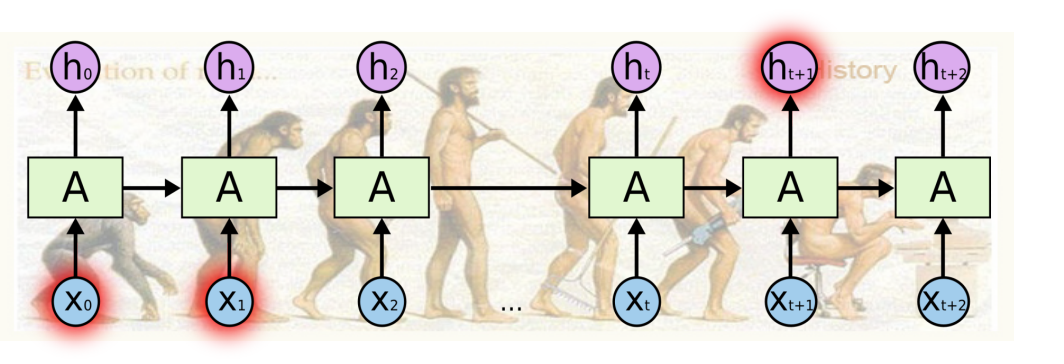
- 멀리 있는 정보는 고려하기 힘든 단점이 있다.
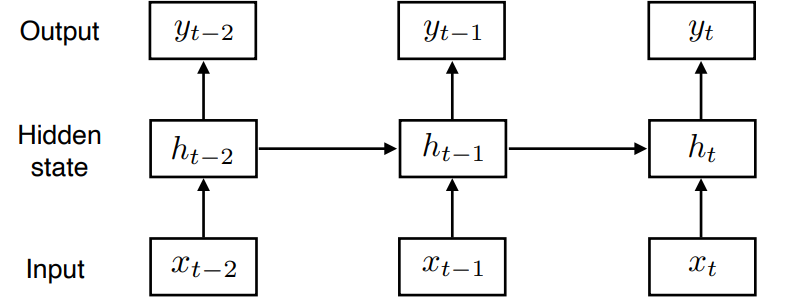
- 식으로 전개하면 다음과 같이 나타낼 수 있다.
- 시그모이드를 사용한다면 Vanishing gradeint, Relu를 사용한다면 exploding gradient문제가 생길 수 있는 단점이 있다.
LSTM (Long Short Term Memory)
- RNN의 long term dependency문제를 해결하기 위해 등장한 모델이다.
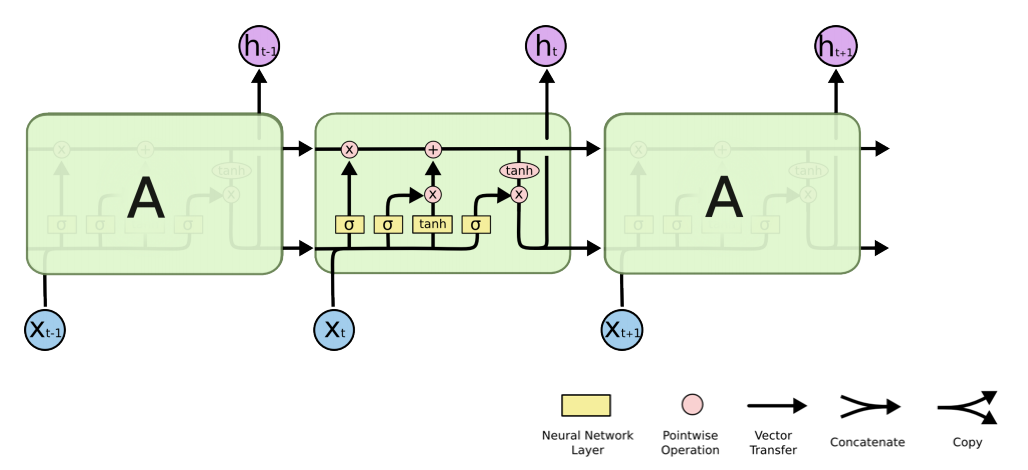
- 가장 기본적인 idea는 t-1전까지 정보를 요약하여 Previous cell state를 계속 전해주는 것.
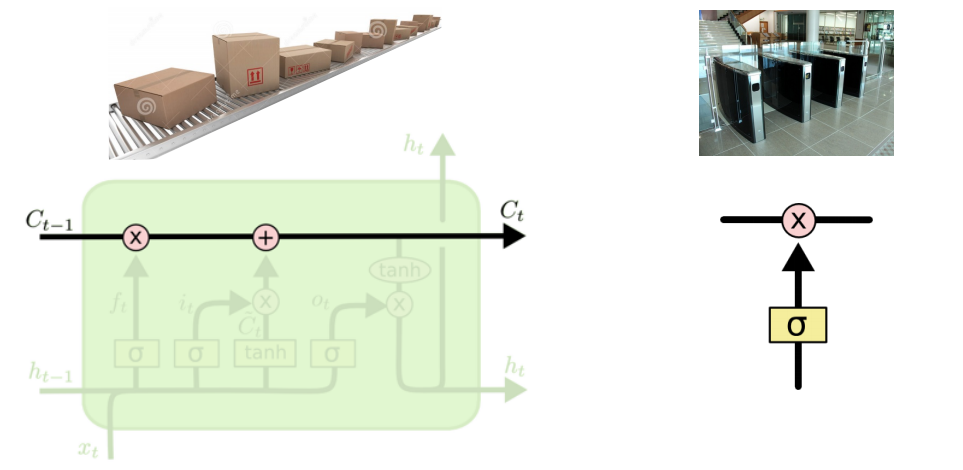
구조를 간단히 살펴보면,
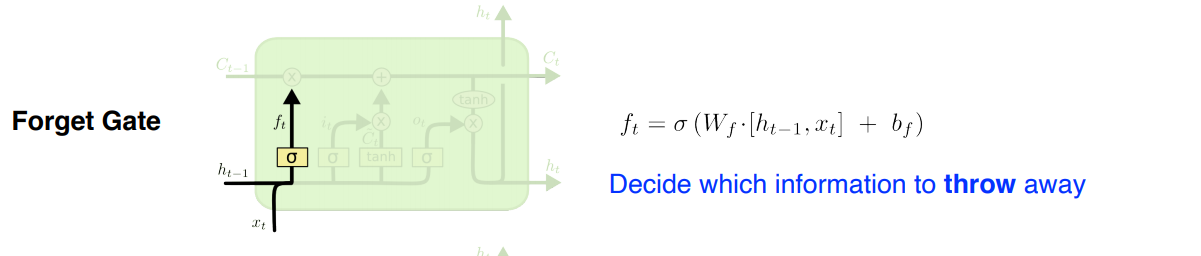
- Forget Gate: 어떤 정보를 버릴지 결정

- Input Gate: 어떤 정보를 올릴지 결정
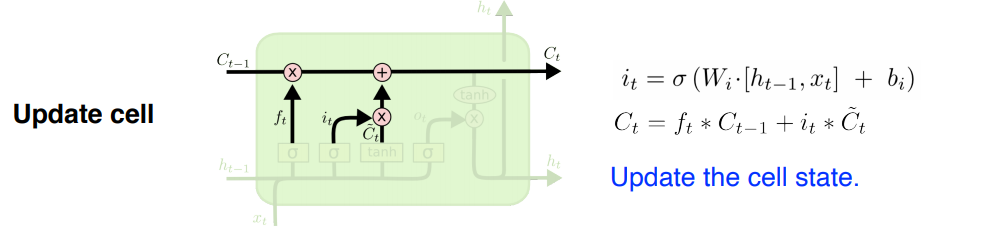
- Update cell: Forget+Input으로 버릴건 버리고 올릴건 올려서 상태를 업데이트
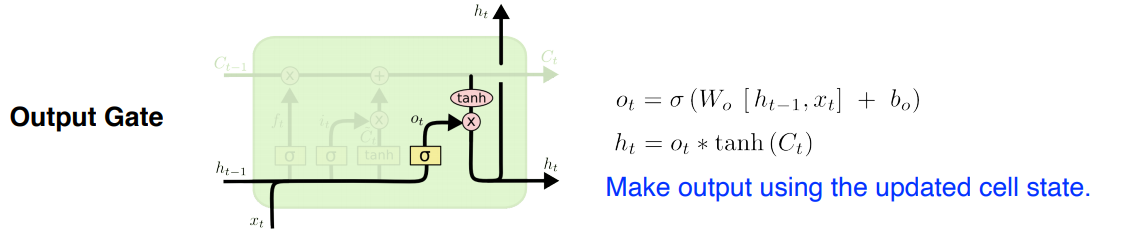
- Output Gate: 어떤 값을 내보낼지 결정
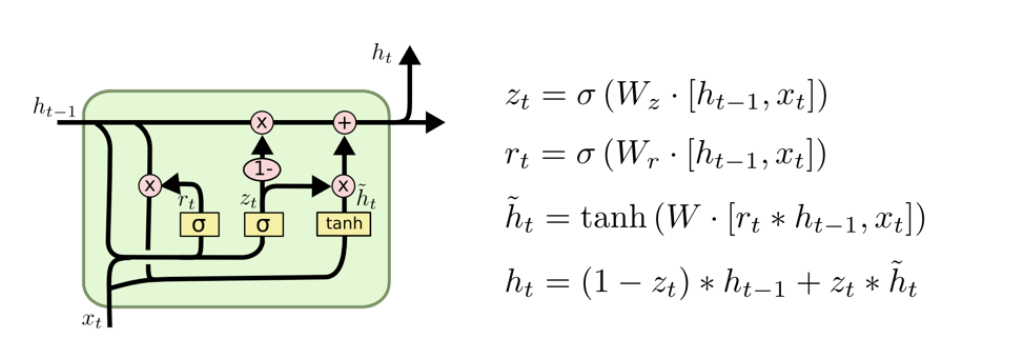
GRU(Gated Recurrent Unit)
- LSTM과 유사하지만, Output gate를 없애고 더 적은 파라미터로 동일한 아웃풋을 낼 수 있도록 고안한 모델
8강: transformer
Sequential Model을 다루면서 가장 어려운 문제는 무엇일까?
- 자연어라고 했을 때 말끝을 흐리거나 중간을 생략하거나 밀리거나 하는 문제들
Transformer
Transformer는 전적으로 attention에 기반한 첫번째 시퀀스 transduction 모델이다.

Transformer의 구성은 다음과 같다.
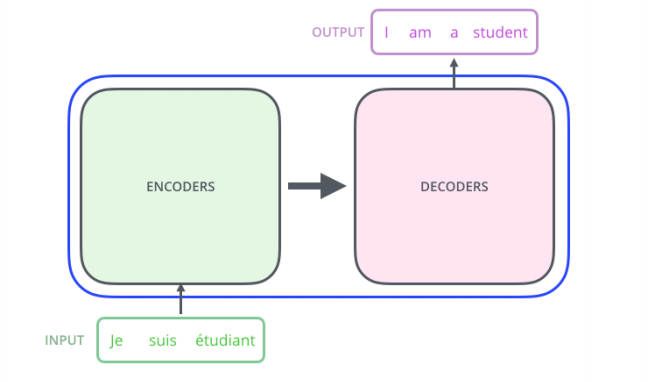
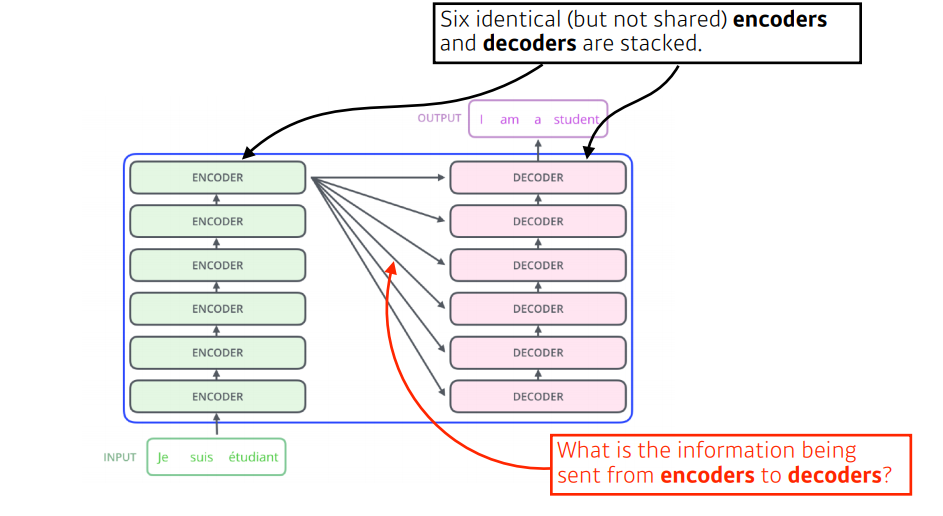
- RNN과 가장 큰 차이점은 RNN은 단어의 순서대로 처리하는데 반해, Transformer는 n개의 단어를 한번에 처리한다는 점이다.
특히 인코더와 디코더에 있는 Self-Attention은 transformer의 가장 기초가 된다.
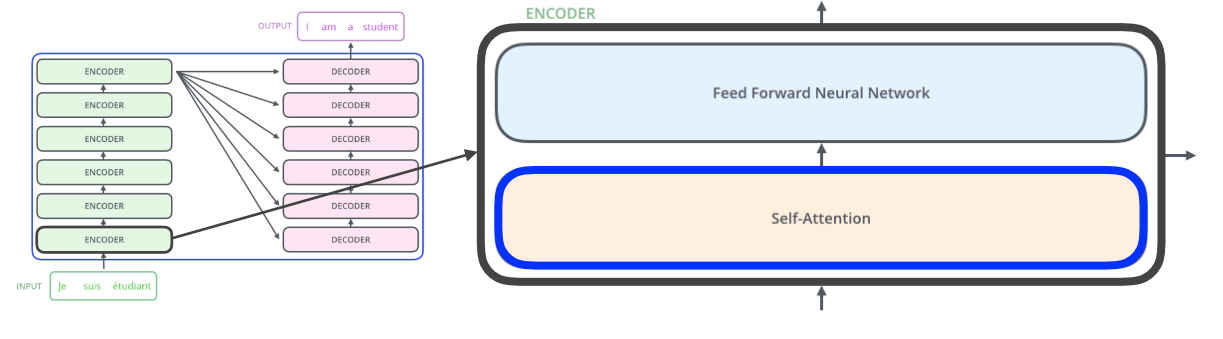
다음은 Transformer의 진행 과정이다.

우선, 우리는 각각의 단어를 embedding 벡터로 표현한다.
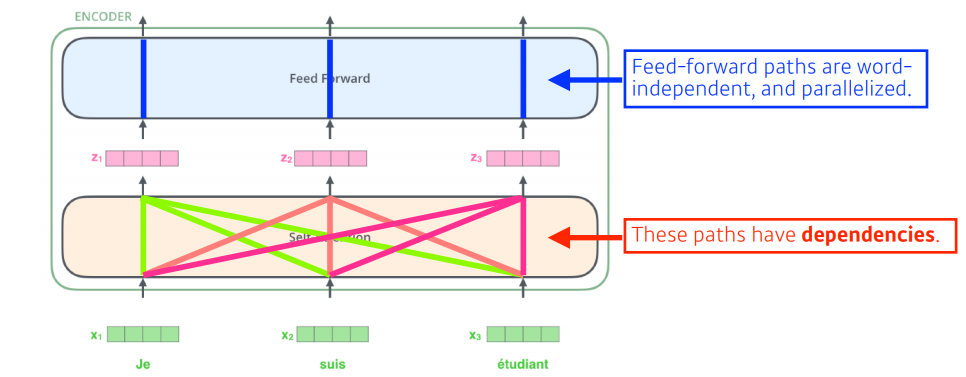
다음으로, 트랜스포머는 Self-Attention을 통해 각각의 단어들을 feature 벡터로 인코딩한다. 이 과정에서 각 벡터들은 모든 단어를 같이 고려한다. (dependency)
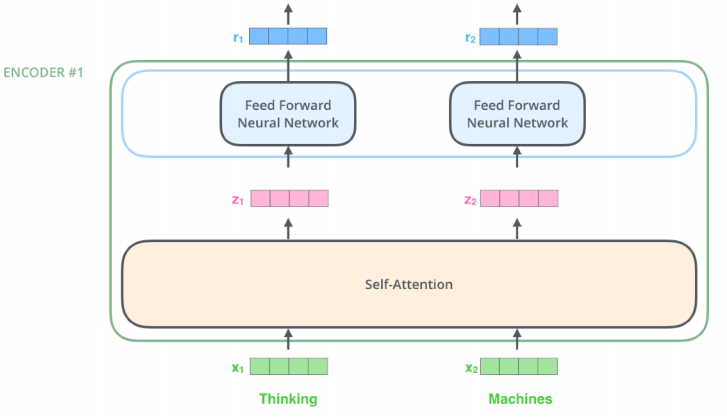
- Thinking과 Machines이라는 단어를 인코딩한다면 위와 같다.

- 위와 같이 모든 단어를 고려하여 it의 경우 animal의 dependency가 높게 학습을 진행한다.
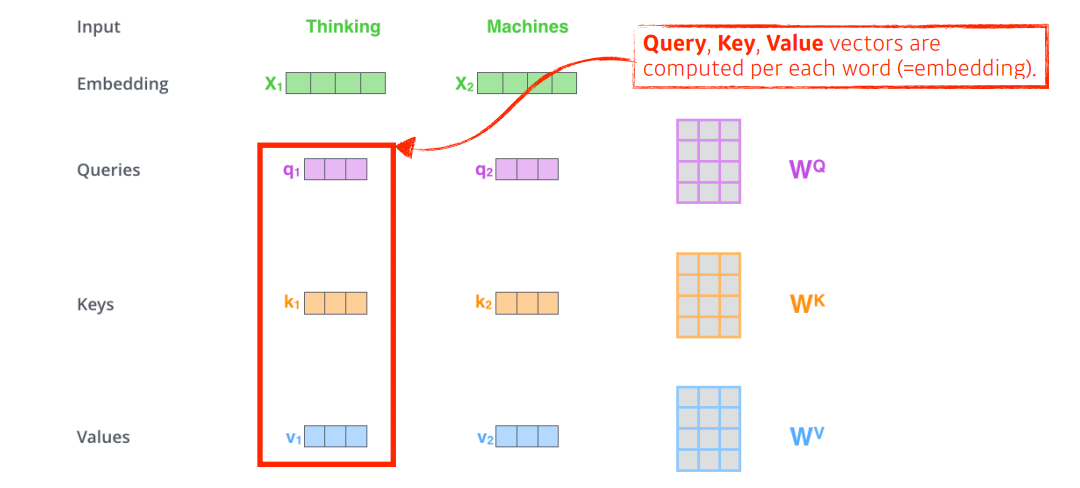
각각의 단어마다 Query, Key, Value벡터를 계산한다.
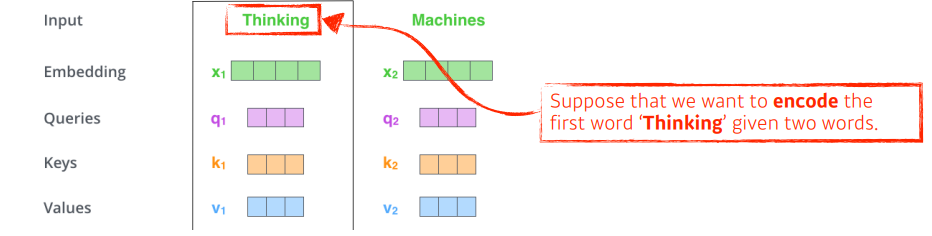
'Thinking'과 'Machines'라는 단어가 주어져있고 'Thinking'을 살펴보자.
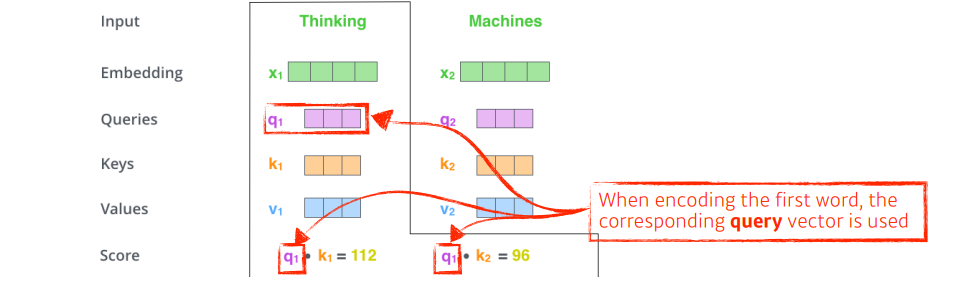
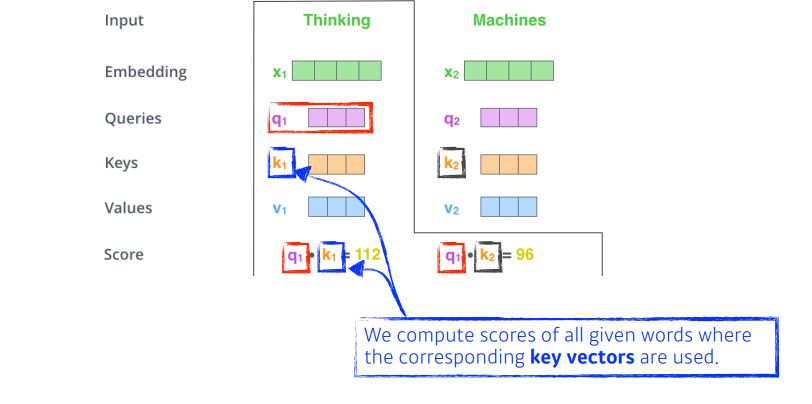
'Thinking'의 쿼리벡터와 각 단어의 key벡터를 이용하여 각각 score를 구한다.
(어떤 단어와 interaction이 있는지(유사도)를 확인하는 과정)
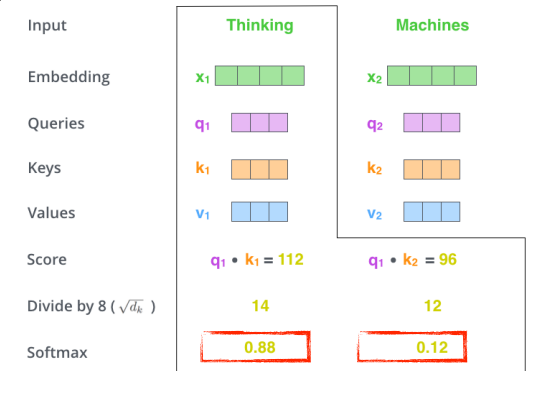
다음으로 key벡터의 크기를 활용하여 softmax연산을 해준다. (값이 크지 않도록 정규화)
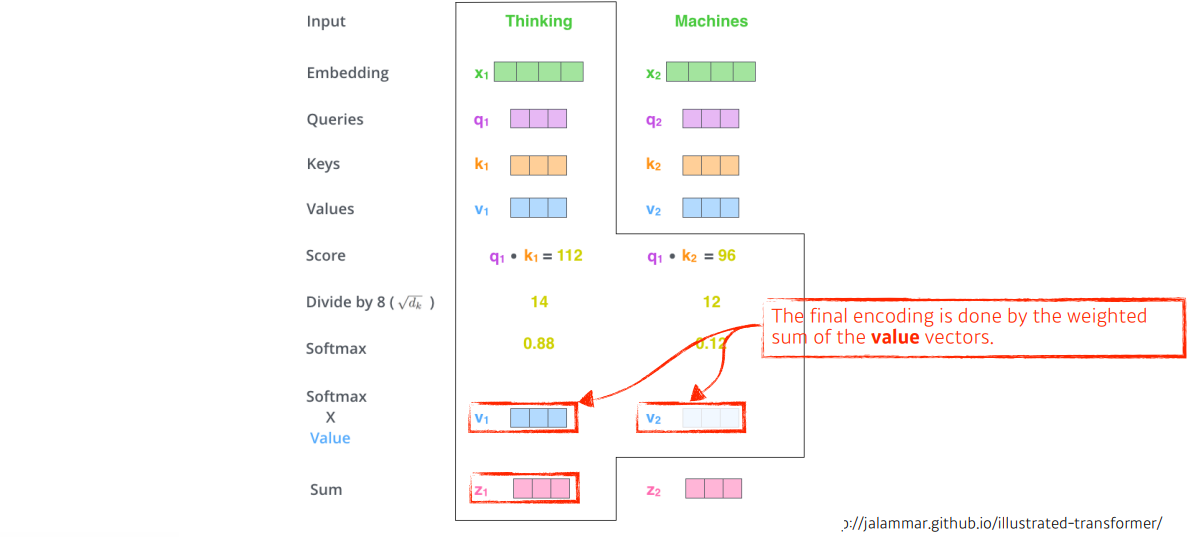
그 후, 최종으로 value 벡터의 weighted sum을 구한다.
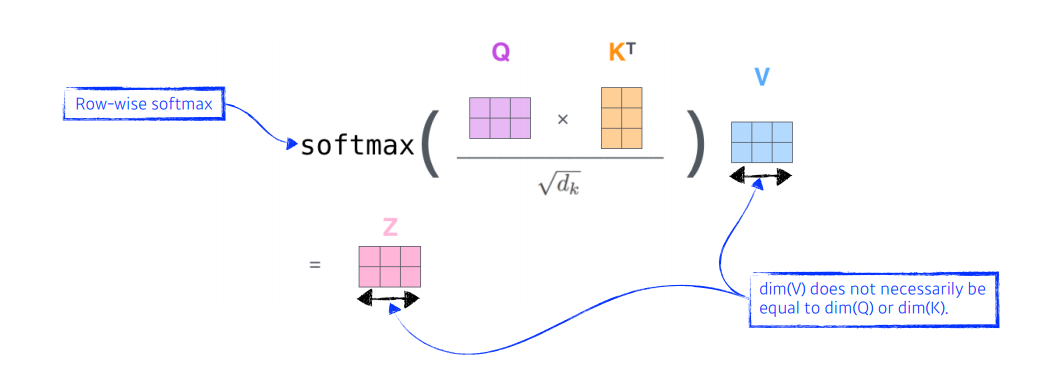
참고로, 위와 같이 Query와 Key는 내적을 해야되기 때문에 차원이 같아야 하지만, Value는 달라도 된다. 그리고 최종 차원은 Value의 차원이 된다.
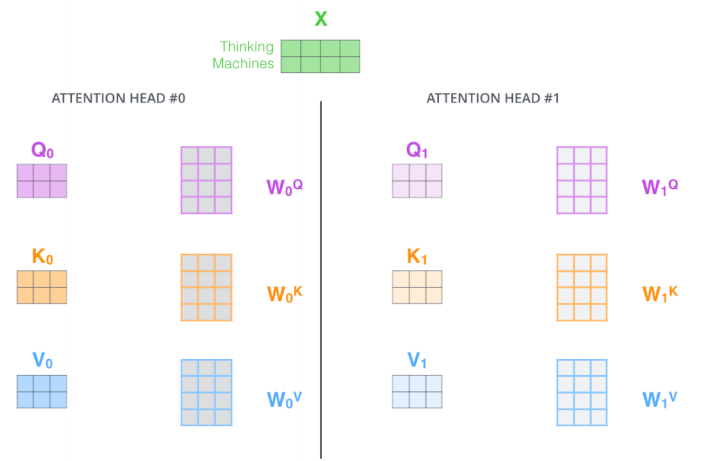
위는 Multi-headed attention(MHA)이다. 이를 하게되면 특정한 하나의 위치에만 크게 집중하는 것이 아니라, 그 집중을 분산시킬 수 있어서 두번째, 세번째 중요한 위치 등을 효과적으로 학습할 수 있다.
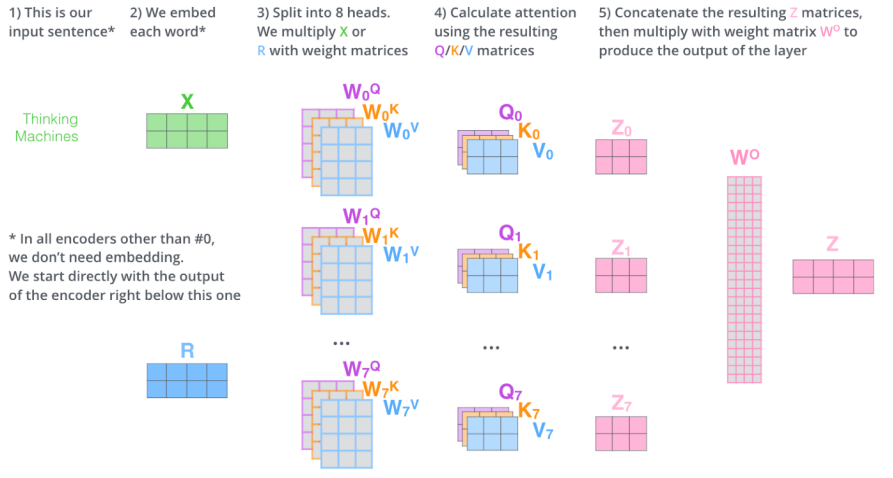
위는 이때까지 설명을 요약한 그림이다.
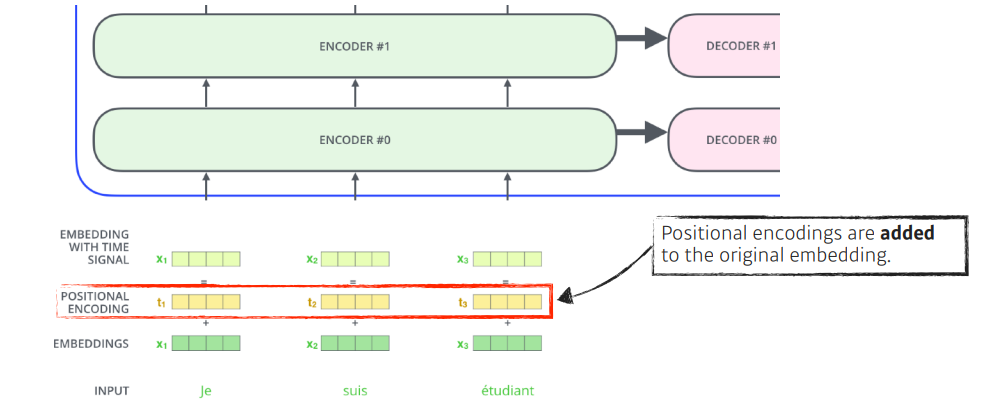
poisitional encoding은 왜 필요한 것일까?
트랜스포머에서 인풋에 independent하게 인코딩되기 때문에 sequntial을 위해 넣어준다.
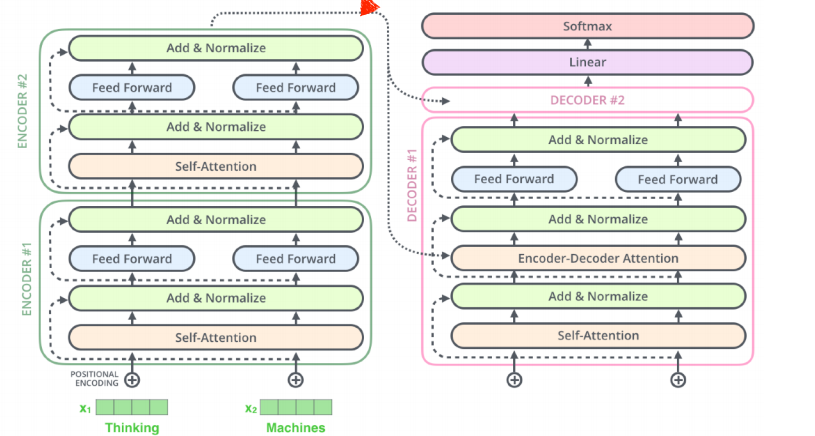
이제 decoder를 살펴보자.
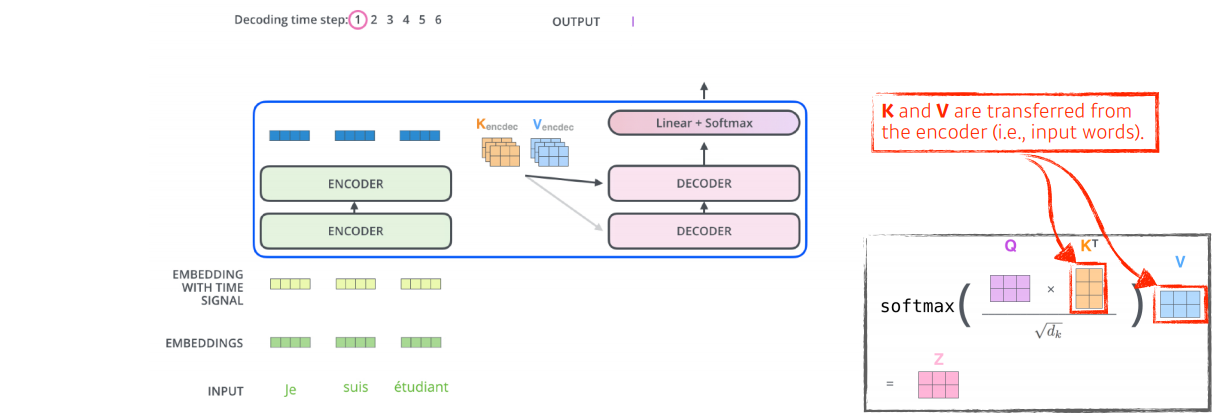
인코더에서 디코더로 key 벡터와 value 벡터를 보내게 된다.
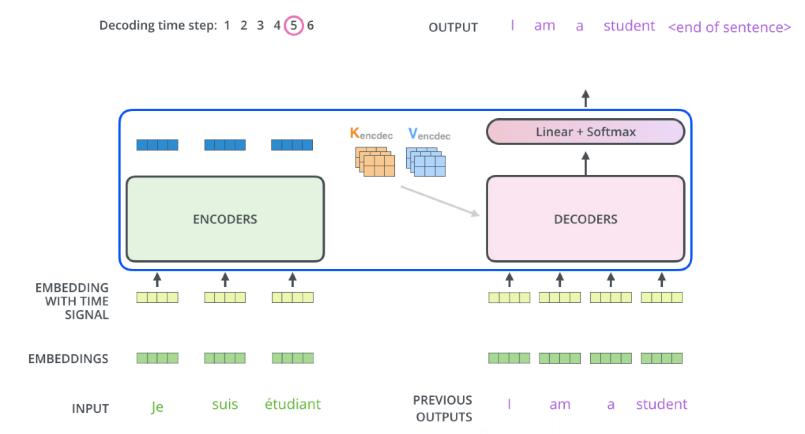
output sequence는 autoregressive 방식으로 생성이 된다.
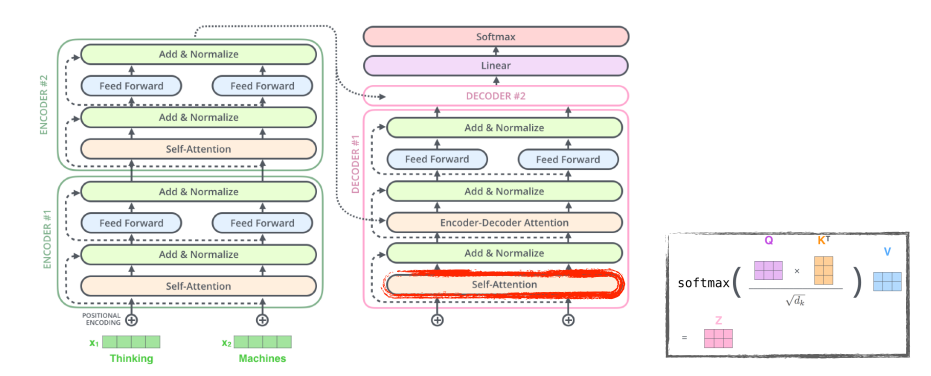
그리고 decoder의 self-attention layer에서는 오직 earlier만 허락한다. (이전만 dependent, 뒤는 independent)
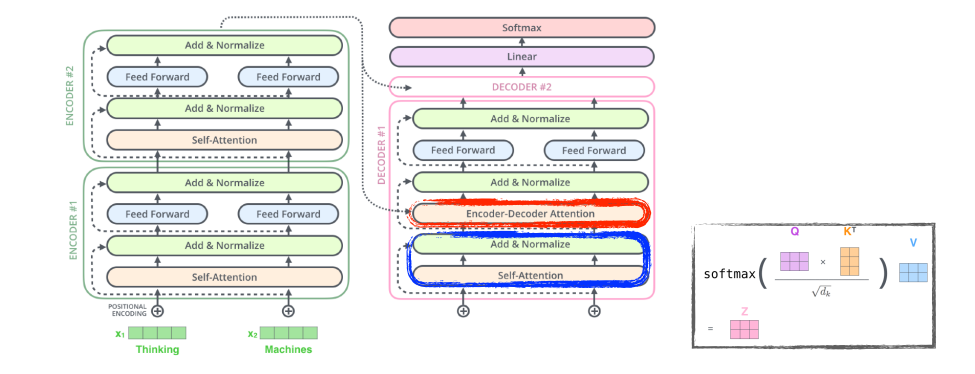
encoder=decoder attention layer에서는 multi-headed self-attention처럼 동작하지만 아래 레이어에서 Query 행렬을 생성하고 key와 value를 인코더 스택에서 가져온다.
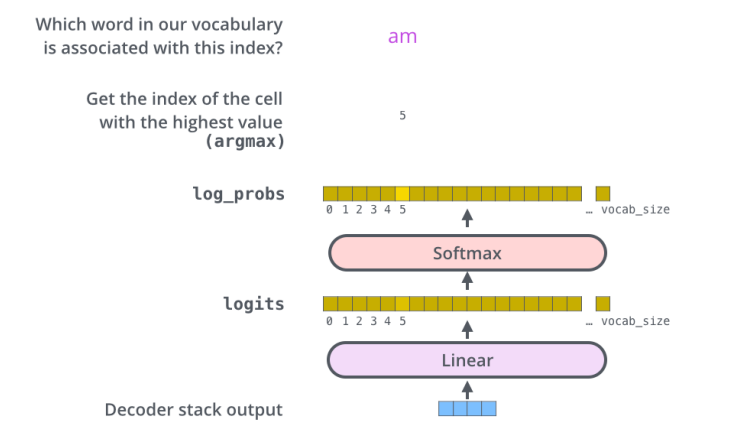
마지막 layer에서는 디코더의 출력 스택을 단어에 대한 분포로 변환한다.
3. 피어세션 정리
특이사항 없음
4. 과제 수행 과정
강의와 동일
5. 회고
- transfomer같은 경우에는 주말에 논문 리뷰나 논문을 직접 읽어봐야 할 듯 하다.
- 뭔가 이해가 되는듯 안되는듯 되는듯 안되는듯..
6. 내일 할일
- GAN 학습
- 시각화
- 멘토링
- 수학 스터디
