
📌 CNN
📖 Convolutional Neural Network
1950년 대 수행했던 고양이의 뇌파 실험에 영감을 얻은 Yann Lecun 교수에 의해 1998년 이미지 인식을 획기적으로 개선할 수 있는 CNN이 제안되었다.
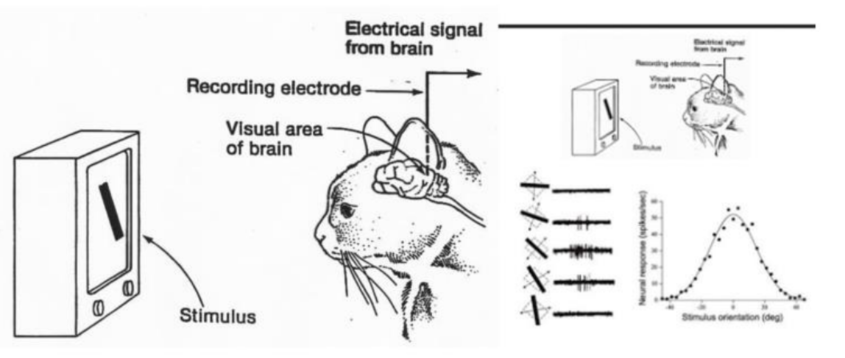
고양이의 눈으로 보는 사물의 형태에 따라 뇌의 특정영역(특정뉴런)만 활성화 된다는 실험 결과를 기반으로 제안 되었다.
- 2010 ~ 2013년도 CNN의 획기적인 발전과 다수의 논문이 출시 되었다.
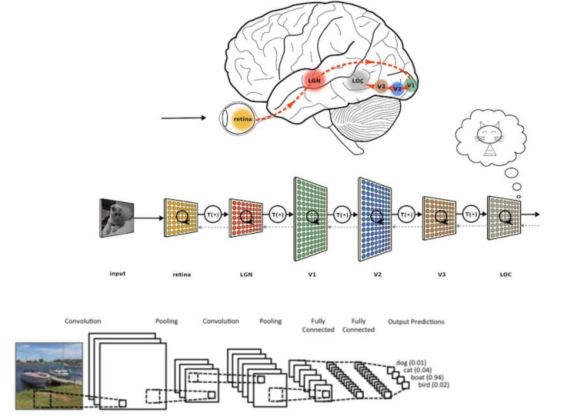
-
특정추출부의 초반 층들은 데이터의 심플한 특징들을 잡아낸다.
Ex) 1단계 : 세모, 동그라미, 네모, ..등 -
특성추출부의 층들이 깊어지면서 조금 더 디테일한 특징들을 잡아낸다.
Ex) 2단계 : 코, 입, 귀, 눈, ..등 -
이러한 특징들이 모여서 최종적으로 고양이라고 판단하게 된다.
Ex) 3단계 : 고양이, ..등
📖 CNN 특징 추출
CNN(합성곱)은 입력된 이미지에서 특징을 추출하기 위해 필터의 개념을 도입했다.
이미지 전체영역(전체픽셀)에 대해 서로 동일한 연관성(중요도)으로 처리하는 대신 특정 범위에 한정해 처리한다면 훨씬 효과적일 것이라는 아이디어 에서 착안 했다.
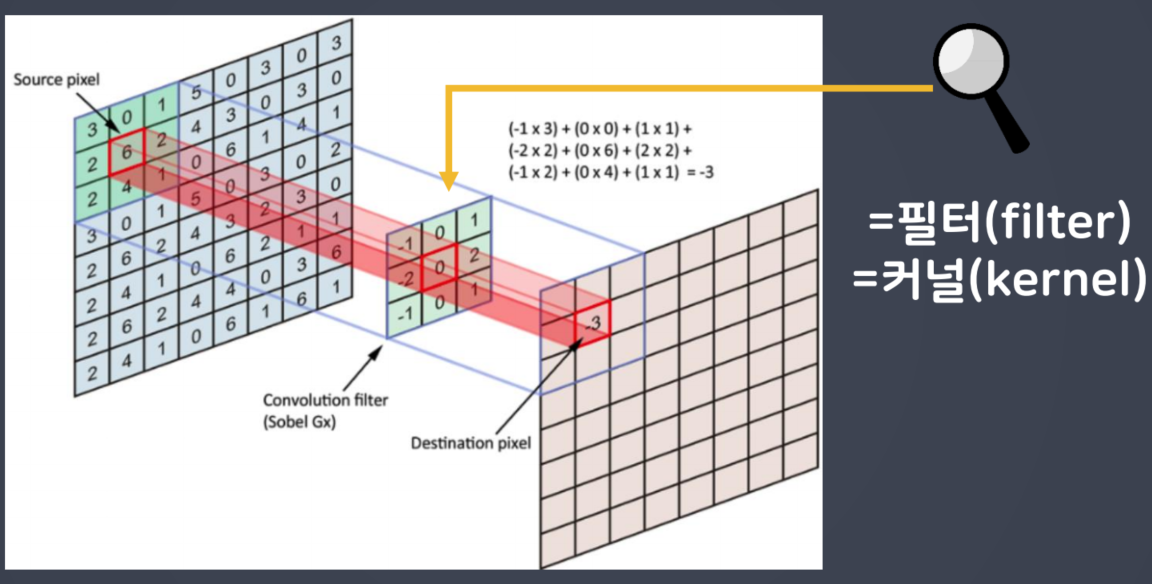
📖 이미지 데이터에서 색상의 개념
합성곱 계층에서 이미지의 색상 정보를 채널이라고 부른다.
흑백으로 코딩 된 경우 (ex 손글씨 이미지) 흑백의 글이 스케일 (0:검은색, 255:흰색)만 나타내면 되므로 채널은 1이 된다.
입력신호가 RGB 신호로 코딩된 경우, 채널은 세가지 색을 각각 나타내는 3이 된다.
(데이터의 색상 정보를 유지 할 수 있음)

📌 패딩(Padding)
📖 패딩의 특징
필터의 크기로 인해 가장자리 부분의 데이터가 부족해서 입력과 출력의 이미지 크기가 달라지게 되는데 이를 보완하기 위해서 입력데이터의 가장자리 부분에 0을 미리 채워 넣는 것을 패딩(Padding) 이라고 한다.
패딩을 사용하면 입력과 출력의 크기를 갘게 맞춰줄 수 있다.
동시에 층이 깊어지면서 이미지의 크기가 줄어드는 것을 방지 할 수 있다.
Cinv2D 계층에서는 padding 명령을 사용해 패딩을 지정 할 수 있다.
same을 지정하면 출력과 입력이 같아지게 적절한 수의 패딩을 자동으로 입력valid로 설정하면 패딩을 사용하지 말라는 뜻
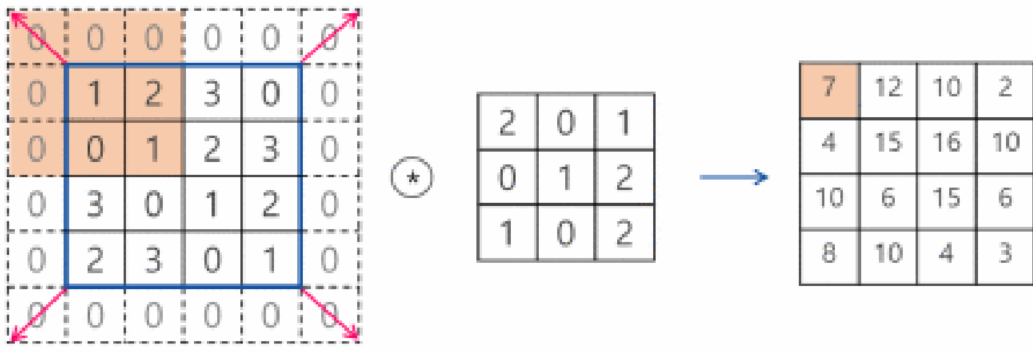
📖 축소 샘플링
합성곱을 수행한 결과 신호를 다음 계층으로 전달할 때, 모든 정보를 전달하지 않고 일부만 샘플링 하여 넘겨주는 작업을 축소샘플링(subsampling)이라고 한다.
축소 샘플링을 하는 이유는 좀 더 가치있는 정보만을 다음 단계로 넘겨주기 위함이며, 딥러닝에서 원하는 결과를 얻기 위해서는 가치 있는 정보를 줄여가야 하며, 결국 핵심 정보만 다음 계층으로 전달하는 장치가 필요하다.
축소 샘플링에는 크게 스트라이드(stride)와 풀링(pooling) 두 가지 기법이 있다.
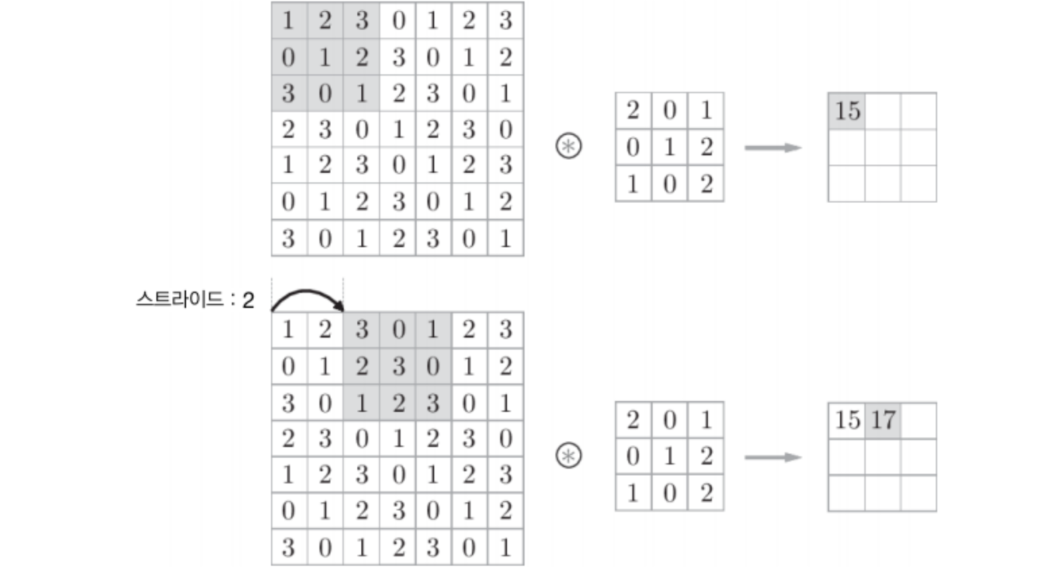
📋 스트라이드(Stride)
스트라이드는 합성곱 연산을 수행할 때 필터를 한 픽셀씩 옆으로 이동하면서 출력을 얻는게 아니라, 2 픽셀씩 또는 3 픽셀씩 건더 뛰면서 합성곱 연산을 수행하는 방법이다.
이를 스트라이드 2 또는 스트라이드 3이라고 하는데, 이렇게 하면 출력 데이터(특성맵)의 크기를 1/4 또는 1/9로 줄일 수 있다.
📋 풀링(Pooling)
플링이란 CNN에서 합성곱 수행 결과를 다음 계층으로 모두 넘기지 않고, 일정 범위 내 (가로, 세로)에서 가장 큰 값을 하나만 선택하여 넘기는 방법을 사용한다.
이렇게 지역내 최대 값만 선택하는 풀링을 최대풀링(max pooling)이라고 한다.
최대 풀링을 하면 작은 지역공간의 대표정보만 남기고 나머지 신호들을 제거하는 효과를 얻을 수 있다.
- 지역내 평균 값을 선택하는
평균풀링(Average pooling)도 있음!
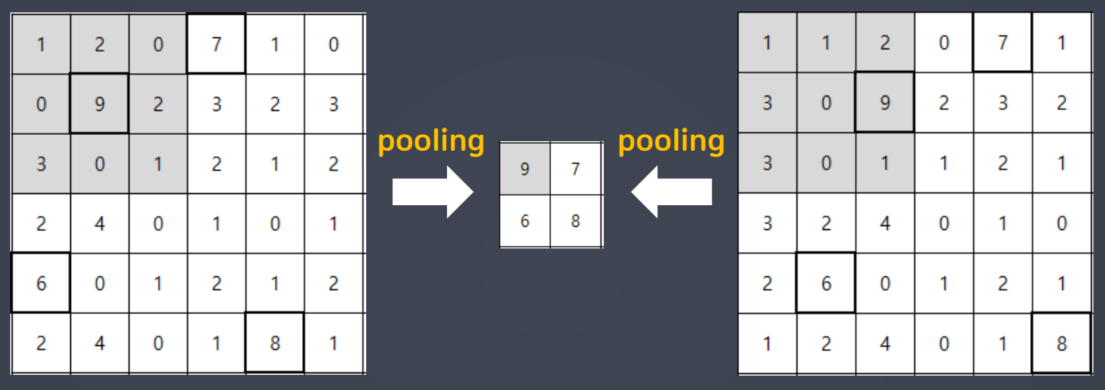
풀링은 위에 보이는 것과 같이 입력의 변화에 영향을 적게 받는다.
📌 CNN - keras
📖 Conv2D
Conv2D(filters = 32,
kernel_size = (5,5),
padding='valid',
input_shape=(28, 28, 1),
activation='relu',
strides = (2, 2))- filters : Convolution 필터의 수
- Kernel_size : Convolution 필터 사이즈 (행, 열)
- padding : 데이터 경계 처리 방법을 정의
- 'valid' : 유효한 영역만 출력. 따라서 출력 이미지 사이즈는 입력 사이즈보다 작음
- 'same' : 출력 이미지 사이즈와 입력 이미지 사이즈가 동일
- input_shape : 샘플 수를 제외한 입력 형태를 정의
- 모델에서 첫 레이어일 때만 정의 (가로픽셀, 세로픽셀, 채널 수)
- 흑백 영상인 경우에는 채널이 1이고, 컬러(RGB)영상인 경우에는 채널을 3으로 설정
- activation : 활성화 함수 설정
- relu, sigmoid, softmax, linear - stride : stride 크기 지정 (행, 열)
📖 과대적합 피하는 방법
-
학습조기중단(early stopping)
- 과대적합이 되기 전까지 모델을 학습
-
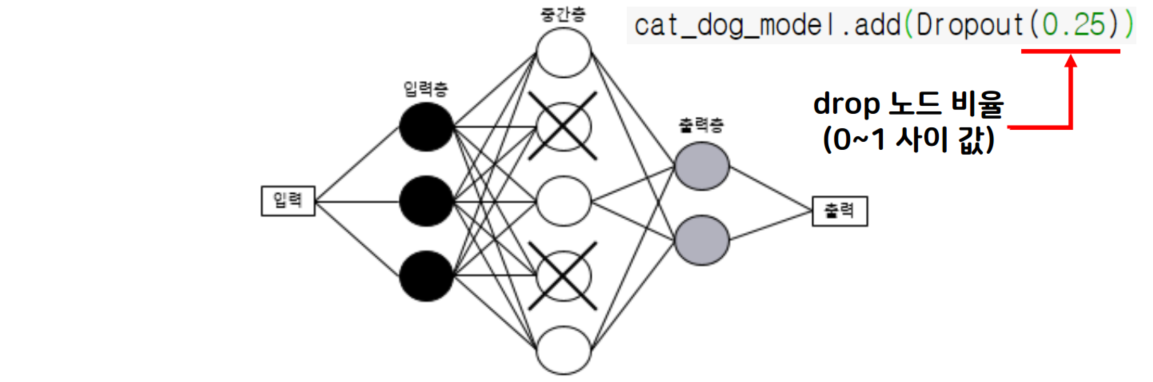
드롭아웃(dropout)
- 신셩망 중간층 뉴런 일부를 비 활성화시켜 과대 적합을 방지
- 드롭아웃은 일정한 비율만큼 랜덤으로 중간층의 뉴런을 비활성화 시켜, 과도하게 학습되는 현상을 방지
- 드롭아웃은 학습(역전파)을 하는 동안에만 적용되고, 학습이 종료된 후 예측을 하는 단계에서는 모든 유닛을 사용하여 예측함
-
데이터 증강(data augmentation) - 이미지 증식
- 원본과 유사한 데이터를 생성하여 폭넓은 학습에 도움
- 과대적합이 일어나는 이유 중 하나는 훈련데이터가 부족하기 때문
- 훈련 데이터가 충붆 많다면 과대 적합을 줄일 수 있음
- 데이터 확장이란 훈련 데이터를 유사하고 다양하게 변형하여 새로운 훈련 데이터처럼 추가적으로 사용함으로써 마치 룬련 데이터 수가 늘어난 효과를 얻는 것

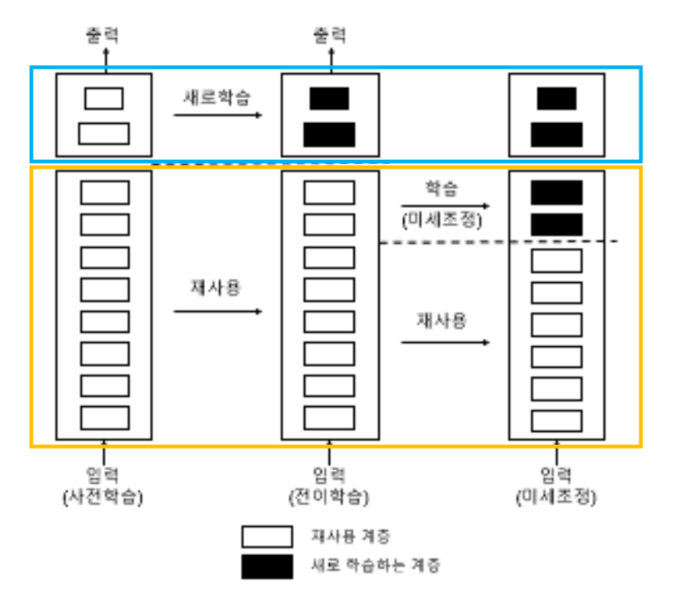
📌 전이학습(Transfer Learnin)
📖 전이학습 개념
전이학습이란 다른 데이터 셋으로 이미 학습한 모델을 유사한 다른 데이터를 인식하는데 사용하는 기법이다. 이 방법은 특히 새로 훈련시킬 데이터가 충분히 확보되지 못한 경우에 높은 학습 효율을 높여주었다.
전이학습 모델을 적절히 이용하는 방법은 특성 추출(feature extraction) 방식과 미세 조정(fine-tuning) 방식이 있다.
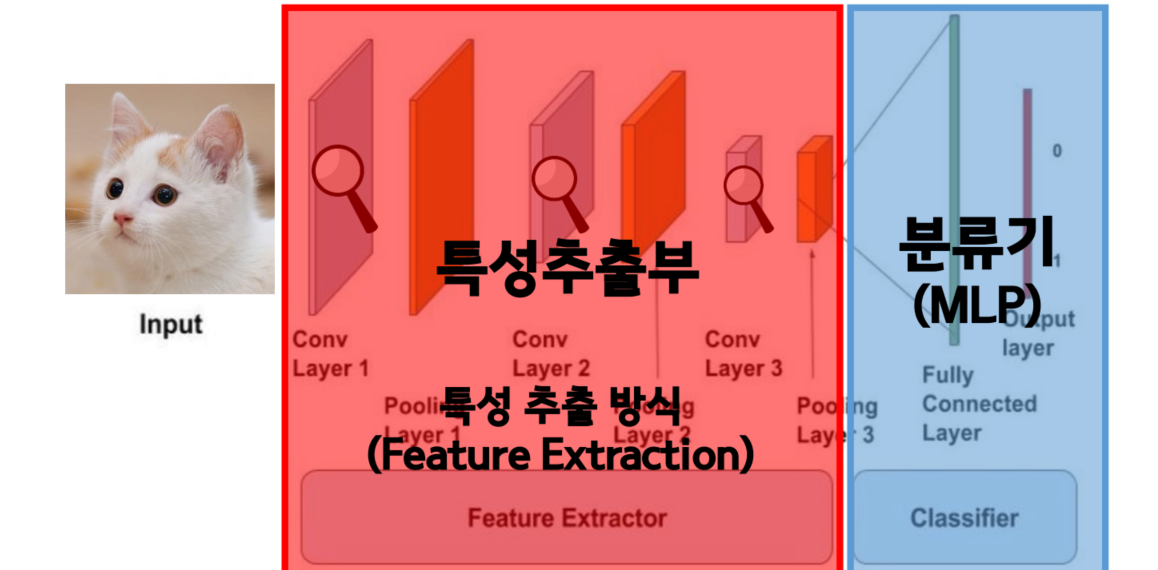
📋 특성추출방식
CNN 층에서 특성추출부만 가져와서 사용하는 방식
-
특성 추출부 부분만 사용하는 이유는 분류기
(MLP)의 경우 우리가 해결하고자 하는 문제에 맞게 새로 설정해줘야 하기 때문이다. -
단, 새롭게 분류할 클래스의 종류가 사전 학습에 사용된 데이터와 특징이 매우 다르면, 특성추출부 전체를 재사용해서는 안되고 앞 단의 일부 계층만을 재사용해야 함 (심플한 특징들만 추출해내기 위해)
📋 미세조정방식
'사전 학습된 모델의 가중치'를 목적에 맞게 전체 또는 일부를 재학습시키는 방식
-
특성추출부의 층들 중 하단부 몇 개의 계층은 전결합층 분류기
(MLP)와 함께 새로 학습시킴 -
처음부터 특성추출부 계층들과 분류기
(MLP)를 같이 훈련시키면 새롭게 만든 분류기에서 발생하는 큰 에러 값으로 인해, 특성추출부에서 사전 학습된 가중치가 많이 손실 될 수 있음 -
처음에는 분류기
(MLP)의 파라미터가 랜덤하게 초기화 되어 있으므로 컨볼루션 베이스 중 앞 단 계층들을 고정(동결)하고 뒷 단의 일부 계층만 학습이 가능하게 설정한 수,MLP와 같이 학습시켜 파라미터(w,b) 들을 적당하게 잡아 준다.
📌 마무리
📖 느낀점
딥러닝을 배우면서 인공지능에 대한 공부를 하고, 계속 공부하다보면 '알파고' 같은 것을 내가 만들 수 있지 않을까? 하는 생각이 들었지만 공부를 하면 할 수록 너무 큰 꿈을 가지고 있었다는 것을 느끼게 되었다.
어려운 것은 사실이나 아직 뭔가 엄청 어렵다 라는 느낌은 덜받았다.
코드도 비슷한것이 많고, 여러 코드를 쓰는것이 아니라 반복되는 작업이 많기 때문인지 여러번 반복해서 공부하다보면 따라갈 수도 있다고 생각을 했다.
