강명호 강사님
암석식별머신 구현
개발 환경 설정
# 데이터 플로팅 라이브러리
import matplotlib.pyplot as plt
# 숫자 처리 라이브러리
import numpy as np
# 딥러닝을 위한 파이토치 라이브러리
import torch
from torch import nn, optim
# 토치비전 라이브러리
import torchvision
from torchvision import datasets, transforms, models
# 이미지 처리 라이브러리 (PIL, pillow)
from PIL import Image
# 주피터 노트북에서 plot이 보이도록 설정
%matplotlib inline
%config InlineBackend.figure_format = 'retina'- 파이토치 (딥러닝 라이브러리)
-torch: 딥러닝 모델을 구축하고 학습시키는 데 널리 사용되는 라이브러리. GPU를 활용하여 빠른 학습이 가능하고, 신경망 구축과 최적화에 필요한 다양한 기능을 제공한다.torch.nn: 신경망의 각 레이어와 모델 구조를 정의하는 데 필요한 모듈.torch.optim: 모델 학습에 사용되는 최적화 알고리즘 제공.
- 토치비전
-torchvision: 파이토치와 함께 사용되며 컴퓨터 비전(이미지 처리) 작업에 유용한 도구들을 제공.torchvision.datasets: 이미지나 영상 같은 데이터를 쉽게 가져와 사용할 수 있도록 도와준다.torchvision.transforms: 이미지의 크기를 조정하거나 텐서로 변환하는 등 모델 입력에 맞게 전처리할 수 있는 다양한 변환 기능을 제공한다.torchvision.models: 사전 학습된 딥러닝 모델을 제공하여 전이 학습을 쉽게 할 수 있다.
- PIL (이미지 처리 라이브러리)
- PIL(Pillow)은 이미지를 열고, 변환하고, 저장하는 데 유용한 파이썬 라이브러리이다.torchvision.transforms와 함께 사용하여 이미지를 모델이 처리할 수 있는 형태로 변환할 수 있다. - 주피터 노트북에서 그래프 표시 설정
-%matplotlib inline: Jupyter Notebook에서matplotlib그래프가 인라인으로 표시되도록 설정한다.%config InlineBackend.figure_format = 'retina': 그래프의 해상도를 높여 보다 선명하게 보이도록 설정한다.
모델링
기본 변수 설정
# 데이터 디렉토리와 검증 데이터 분할 비율 설정
data_dir = './data'
valid_size = 0.2data_dir: 이미지 파일들이 저장된 디렉토리 경로. 이 위치에서 학습에 사용할 이미지 파일들을 불러온다.valid_size: 데이터셋을 훈련과 검증 데이터로 나눌 때 검증 데이터로 사용할 비율을 지정. 0.2는 전체 데이터의 20%를 검증용으로 사용하겠다는 의미.
# 이미지 데이터 변환 설정
t_transforms = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.Resize(224),
transforms.ToTensor()
])t_transform: torchvision.transforms.Compose를 이용하여 이미지에 적용할 여러 가지 변환을 연속적으로 지정한다. ResNet50 모델이 원하는 형태와 크기로 이미지를 변환하는 과정.
transforms.RandomResizedCrop(224): 이미지를 임의로 자르고 크기를 224*224로 변경하여 다양한 이미지 크기를 학습할 수 있도록 한다.transforms.Resize(224): 이미지 크기를 다시 한 번 224*224로 조정해 모델이 일관된 크기의 입력을 받도록 한다. (앞의RandomResizedCrop에서 크기가 달라질 수 있기 때문에 이 과정을 추가한다.)transforms.ToTensor(): 이미지를 텐서로 변환해 모델이 처리할 수 있도록 한다. 이는이미지의 각 픽셀 값을 [0, 1] 범위로 정규화하여 파이토치 텐서 형태로 변환해 준다.
데이터 로더 함수
# 학습 및 테스트 데이터 생성
train_data = datasets.ImageFolder(data_dir, transform=t_transforms)
test_data = datasets.ImageFolder(data_dir, transform=t_transforms)datasets.ImageFolder: 이미지가 저장된 디렉토리 구조에 따라 데이터셋을 생성한다.data_dir위치에서 폴더 이름을 클래스로 인식하고 각 클래스 폴더에 속한 이미지를 해당 클래스의 이미지로 분류한다.transform=t_transforms: 앞서 설정한 이미지 변환 설정을 적용하여 이미지의 크기, 형식 등을 ResNet50 모델에 적합하게 변환한다.- 이렇게 하면
train_data와test_data가 동일한 이미지 데이터 디렉토리를 사용하므로 실제 학습과 테스트에서는 이 데이터를 별도로 분할할 필요가 있다.
# 데이터 길이 확인 및 인덱스 리스트 생성
num_train = len(train_data)
indices = list(range(num_train))
print(indices)num_train:train_data의 전체 데이터 개수를 담는다.indices: 0부터num_train - 1까지의 정수 리스트 생성. 각 정수는train_data의 이미지에 대한 고유 인덱스를 나타낸다.
# 인덱스 리스트 섞기
np.random.shuffle(indices)
print(indices)np.random.shuffle(indices):indices리스트를 랜덤하게 섞어 데이터가 학습시 순서에 의존하지 않도록 한다. 이는 모델이 데이터를 학습하는 데 있어 편향을 줄여주기 때문에 중요한 단계이다.
# 검증 데이터 분할 인덱스 계산
split = int(np.floor(num_train * valid_size))
print(split)num_train * valid_size: 전체 학습 데이터 중 검증 데이터로 사용할 비율을 계산한다.np.floor: 소수점 이하 값을 버려 정수로 만들고 int로 변환하여split변수에 저장한다.split값은 검증 데이터에 사용할 인덱스의 개수를 나타낸다.
# 학습 데이터 및 테스트 데이터 인덱스 생성
train_idx, test_idx = indices[split:], indices[:split]indices[split:]:split인덱스 이후부터 끝까지의 인덱스를 가져와train_idx리스트에 저장한다. 이는 학습 데이터로 사용할 인덱스들이 된다.indices[:split]: 리스트의 시작부터split인덱스까지의 인덱스를 가져와test_idx리스트에 저장한다. 이는 검증 데이터로 사용할 인덱스들이 된다.
# 샘플링 방식 설정
from torch.utils.data.sampler import SubsetRandomSampler
train_sampler = SubsetRandomSampler(train_idx)
test_sampler = SubsetRandomSampler(test_idx)SubsetRandomSampler: 지정된 인덱스 리스트에서 데이터를 무작위로 샘플링한다.train_sampler:train_idx에 있는 인덱스를 이용해 학습 데이터의 샘플링을 담당한다.test_sampler:test_idx에 있는 인덱스를 이용해 검증 데이터의 샘플링을 담당한다.- 이를 통해
train_idx,test_idx로 구분된 학습 및 검증 데이터가 각각 무작위 순서로 모델에 제공된다.
# 데이터 로더 생성
trainloader = torch.utils.data.DataLoader(train_data, sampler=train_sampler, batch_size=16)
testloader = torch.utils.data.DataLoader(test_data, sampler=test_sampler, batch_size=16)DataLoader: 데이터를 모델에 공급하기 위해 배치 단위로 불러오는 역할을 한다.trainloader,testloader: 각각 학습과 검증 데이터를 무작위 순서로 배치 사이즈만큼 모델에 제공한다.sampler=train_sampler,sampler=test_sampler를 지정하여 학습과 검증 데이터가 각각 지정된 샘플러를 따라 불러와진다.
# 위의 코드들을 묶어서 load_split_train_test() 함수를 만든다. (입력 : 데이터 디렉토리, 분할 비율) (출력 : 학습 데이터 로더, 테스트 데이터 로더)
def load_split_train_test(data_dir, valid_size) :
t_transforms = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.Resize(224),
transforms.ToTensor()
])
train_data = datasets.ImageFolder(data_dir, transform=t_transforms)
test_data = datasets.ImageFolder(data_dir, transform=t_transforms)
num_train = len(train_data)
indices = list(range(num_train))
np.random.shuffle(indices)
split = int(np.floor(num_train * valid_size))
train_idx, test_idx = indices[split:], indices[:split]
from torch.utils.data.sampler import SubsetRandomSampler
train_sampler = SubsetRandomSampler(train_idx)
test_sampler = SubsetRandomSampler(test_idx)
trainloader = torch.utils.data.DataLoader(train_data, sampler=train_sampler, batch_size=16)
testloader = torch.utils.data.DataLoader(test_data, sampler=test_sampler, batch_size=16)
return trainloader, testloader데이터 로딩 함수
# load_split_train_test() 함수 호출
trainloader, testloader = load_split_train_test(data_dir, 0.2)샘플 이미지 로딩 및 확인
# 데이터셋 로드 및 인덱스 리스트 생성
data = datasets.ImageFolder(data_dir, transform=t_transforms)
indices = list(range(len(data)))
np.random.shuffle(indices)
idx = indices[:num]data:data_dir에서 이미지를 불러오는 데이터셋.t_transforms를 사용해 이미지를 전처리한 상태로 로드한다.indices: 전체 데이터의 인덱스를 포함하는 리스트. 0부터데이터 개수 - 1까지의 인덱슬르 생성한다.np.random.shuffle(indices): 인덱스 리스트를 무작위로 섞는다.idx = indices[:num]: 무작위로 섞인 인덱스 리스트에서num개의 인덱스를 선택한다.
# 샘플러 및 데이터 로더 생성
from torch.utils.data.sampler import SubsetRandomSampler
sampler = SubsetRandomSampler(idx)
loader = torch.utils.data.DataLoader(data, sampler=sampler, batch_size=num)SumbsetRandomSampler(idx):idx에 지정된 인덱스만 샘플링하도록 설정.DataLoader(data, sampler=sampler, batch_size=num):num개의 이미지를 한 번에 불러오는 데이터 로더를 생성.sampler=sampler를 사용해 무작위로 선택된num개의 이미지만 로드한다.
# 데이터 로더에서 무작위 이미지 가져오기
dataiter = iter(loader)
images, labels = dataiter.next()dataiter = iter(loader):loader에서 데이터를 하나씩 꺼낼 수 있는 이터레이터를 생성한다.images, labels = dataiter.next(): 이터레이터에서 첫 번째 배치를 꺼내 이미지와 레이블을 반환한다. 이images와labels는 선택된num개의 이미지와 각 이미지의 레이블이다.
# 무작위 이미지와 레이블 가져오기
images, labels = get_random_images(5)get_random_images(5): 무작위로 5개의 이미지와 해당 이미지의 레이블을 가져온다.images는 이미지의 픽셀 배열,labels는 이미지의 클래스 레이블을 담고 있다.
# PIL 형식으로 변환 및 그림 크기 설정
to_pil = transforms.ToPILImage()
fig = plt.figure(figsize=(20, 20))transforms.ToPILImage(): 텐서 형식의 이미지를 PIL 이미지 형식으로 변환해주는 함수. 이후plt.imshow()를 사용하여 이미지를 표시할 수 있게 한다.fig = plt.figure(figsize=(20, 20)): 이미지 출력 창을 생성하고 크기를 (20, 20)으로 설정한다.
# 클래스 리스트 가져오기
classes = trainloader.dataset.classestrainloader.dataset.classes: 데이터셋에 있는 클래스 목록을 리스트로 반환한다.
# 이미지 출력 설정
for ii in range(len(images)):
image = to_pil(images[ii])
sub = fig.add_subplot(1, len(images), ii+1)
index = labels[ii].item()
sub.set_title(classes[index])
plt.axis('off')
plt.imshow(image)for ii in range(len(images)): 5개의 이미지를 각각 순회한다.image = to_pil(images[ii]): 각images배열을 PIL 이미지 형식으로 변환한다.fig.add_subplot(1, len(images), ii+1): 1행에len(images)만큼의 서브 플롯을 생성하여 각 이미지가 나란히 출력되도록 한다.index = labels[ii].items(): 현재 이미지의 레이블 값을 가져온다.sub.set_title(classes[index]): 레이블에 해당하는 클래스 이름을 이미지 상단에 제목으로 표시한다.plt.axis('off'): 축을 표시하지 않도록 설정.plt.imshow(image): 현재 이미지를 서브플롯에 표시.

Compute Device 확인
#컴퓨팅 장치 설정
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')torch.device('cuda' if torch.cuda.is_available() else 'cpu'): 현재 사용할 수 있는 컴퓨팅 장치 설정.torch.cuda.is_available(): CUDA가 설치되어 있고 GPU를 사용할 수 있는지 확인.
- GPU를 사용할 수 있으면'cuda'장치를 선택해device에 저장하고- 그렇지 않으면 CPU를 사용하도록
'cpu'장치를 선택해device에 저장한다.
- 그렇지 않으면 CPU를 사용하도록
ResNet50 모델 지정
# 사전 학습된 ResNet50 모델 로드
model = models.resnet50(pretrained=True)models.resnet50(pretrained=True):torchvision.models에서 제공하는 ResNet50 모델을 불러온다.pretrained=True옵션을 설정하면 ImageNet 데이터셋으로 사전 학습된 가중치를 가져온다. 이를 통해 ResNet50 모델은 이미지 분류를 위해 최적화된 상태로 초기화된다.- 사전 학습된 모델을 사용하면 새로운 데이터셋에 맞게 조금만 추가 학습을 시켜도 좋은 성능을 얻을 수 있어 전이 학습에 유리하다.
Fully Connected Layer 수정
# 모델의 가중치 고정 (freeze)
for param in model.parameters():
param.requires_grad = Falsefor param in model.parameters():: 모델의 모든 가중치를 순회하며 접근.param.requires_grad = False: 모델의 기존 가중치를 학습에서 제외한다. 즉 사전 학습된 가중치는 업데이트되지 않도록 고정(freeze)하여 전이 학습에 필요한 새로운 출력층만 학습하게 한다.
# 출력층(fully connected layer) 수정
model.fc = nn.Sequential(
nn.Linear(2048, 512),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(512, 2),
nn.LogSoftmax(dim=1)
)model.fc: ResNet50의 마지막 완전 연결(fully connected) 레이어. 이 부분을 새롭게 설정해 원하는 클래스 수에 맞게 재구성한다.nn.Linear(2048, 512): 입력 크기 2048을 512개의 뉴런으로 연결한다. (ResNet50의fc출력 크기는 2048이다.)nn.ReLU(): 활성화 함수. ReLU를 사용해 비선형성을 추가한다.nn.Dropout(0.2): 20%의 노드를 무작위로 비활성화하여 과적합을 방지한다.nn.Linear(512, 2): 512개의 뉴런을 2개의 출력으로 연결하여 이진 분류를 수행한다.nn.LogSoftmax(dim=1): 소프트맥스 출력을 로그 확률로 변환하여 손실 함수에 사용할 수 있게 한다.
# 손실 함수 설정
criterion = nn.NLLLoss()criterion = nn.NLLLoss(): 손실 함수를 NLL 손실 함수로 설정한다.nn.NLLLoss():LogSoftmax와 함께 사용되며 로그 확률값을 입력으로 받아 타깃 클래스에 대한 예측 오류를 계산한다.
NLL 손실 함수
Negative Log Likelihood Loss, 음의 로그 우도 손실 함수. 모델이 예측한 클래스 확률과 실제 정답 간의 차이를 계산하는 손실 함수.
- 로그 확률 값을 입력으로 받는다. 그래서 보통 LogSoftmax 함수를 마지막 레이어에 적용하여 클래스별 예측 확률의 로그값을 구한다.
- 모델이 정답으로 예측한 클래스의 로그 확률 값을 음수로 변환한 값. 예측이 정답과 가까울수록 손실 값이 작아지며 정답에서 멀어질수록 손실값이 커진다.
# optimizer 설정
optimizer = optim.Adam(model.fc.parameters(), lr=0.003)optim.Adam(model.fc.parameters(), lr=0.003): Adam 최적화기를 설정한다. 학습할 가중치(model.fc.parameters())는 새로 정의된fc레이어의 가중치들만 포함된다.lr=0.003: 학습률. 최적화가 진행되는 속도를 조절하는 중요한 하이퍼파라미터.
# 모델을 컴퓨팅 장치로 이동
model.to(device)model.to(device): 학습에 사용할 컴퓨팅 장치(device, CPU 또는 GPU)로 모델을 전송하여 학습 속도를 최적화한다.
FCL 학습
# 에폭 및 출력 간격 설정
epochs = 10
print_every = 5epochs: 모델이 전체 데이터셋을 학습하는 횟수를 설정한다.epochs = 10은 데이터셋을 10번 반복하여 학습할 것을 의미한다.print_every: 출력 간격을 설정하여 손실 값을 얼마나 자주 출력할지 결정한다. 여기서는 5로 설정되어 있어 매 5단계마다 손실 값을 출력한다.
# 손실 변수 초기화
running_loss = 0
train_losses, test_losses = [], []running_loss: 학습 중 손실을 누적하여 평균 손실을 계산하기 위해 사용된다. 각 배치 학습의 손실값을 더해가며 출력 간격마다 손실을 계산하고 초기화한다.train_losses,test_losses: 학습 및 검증 손실 값을 기록하는 리스트. 학습이 진행되는 동안 각 에폭의 손실을 저장해 학습 상태를 추적할 수 있게 한다.
# 학습 단계 초기화
steps = 0steps: 학습의 현재 단계를 나타내는 변수로 배치마다steps값을 증가시켜 진행 상황을 나타낸다.print_every와 결합해 설정된 출력 간격마다 학습 상태를 출력할 때 사용한다.
FCL 학습/테스트/평가
# 에폭 반복
for epoch in range(epochs):
epoch += 1epochs: 지정된 에폭 수만큼 반복하며 학습한다.
# 훈련 데이터 반복 학습
for inputs, labels in trainloader:trainloader에서 배치 단위로inputs(이미지 데이터)와labels(정답 레이블)을 가져와 학습을 수행한다.
# 학습 단계 업데이트
steps += 1
print('Training step ', steps)steps: 학습 진행 단계.print_every설정에 따라 특정 단계마다 중간 결과를 출력하는데 사용된다.
# 입력 데이터 이동 및 옵티마이저 초기화
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()- 학습 데이터(
inputs,labels)를 GPU 또는 CPU(device)로 이동시켜 학습에 사용한다. optimizer.zero_grad(): 옵티마이저가 이전 배치의gradients를 초기화하여 새로운 학습에 영향을 주지 않도록 한다.
# 순전파 및 손실 계산
logps = model.forward(inputs)
loss = criterion(logps, labels)logps = model.forward(inputs): 모델에 입력 데이터를 넣어 순전파를 수행하고, 예측된 로그 확률(log probabilities) 를 반환한다.loss = criterion(logps, labels): 예측값(logps)과 실제값(labels) 간의 손실을 계산한다.
# 역전파 및 가중치 업데이트
loss.backward()
optimizer.step()loss.backward(): 역전파를 수행하여 손실에 대한 그래디언트를 계산한다.optimizer.step(): 그래디언트를 기반으로 모델 가중치를 업데이트하여 손실을 줄여 나간다.
# 손실 누적 및 검증 조건
running_loss += loss.item()
if steps % print_every == 0:running_loss에 현재 배치의 손실을 누적하여 일정 단계마다 평균 손실을 출력한다.steps % print_every == 0: 설정한print_every단계마다 검증을 수행하는 조건.
# 모델 검증 및 평가
model.eval()
with torch.no_grad():
for inputs, labels in testloader:model.eval(): 모델을 평가 모드로 전환하여 드롭아웃과 같은 정규화 레이어를 비활성화한다.torch.no_grad(): 검증 과정에서 그래디언트가 계산되지 않아 메모리 사용량과 계산 시간을 줄일 수 있다.
# 검증 손실 및 정확도 계산
test_loss += batch_loss.item()
ps = torch.exp(logps)
top_p, top_class = ps.topk(1, dim=1)
equals = top_class == labels.view(*top_class.shape)
accuracy += torch.mean(equals.type(torch.FloatTensor)).item()test_loss += batch_loss.item(): 배치 손실을 누적하여 검증 데이터 전체의 손실을 계산.torch.exp(logps): 로그 확률을 실제 확률로 변환. /topk: 예측 확률이 가장 높은 클래스(top_class)를 추출.equals = top_class == labels.view(*top_class.shape): 예측한 클래스와 실제 클래스가 일치하는지를 나타내며,accuracy에 평균 정확도를 누적한다.
# 결과 출력 및 변수 초기화
train_losses.append(running_loss/len(trainloader))
test_losses.append(test_loss/len(testloader))
print("Epoch {}/{}: ".format(epoch, epochs),
"Train loss: {:.3f}.. ".format(running_loss/print_every),
"Test loss: {:.3f}.. ".format(test_loss/len(testloader)),
"Test accuracy: {:.3f}\n".format(accuracy/len(testloader)))
running_loss = 0
model.train()
breaktrain_losses,test_losses: 각각 학습 손실과 검증 손실을 저장하여 학습 중 손실 변화를 추적한다.runnin_loss = 0: 손실 누적 변수 초기화. /model.train(): 학습모드로 전환하여 다음 에폭을 준비한다.
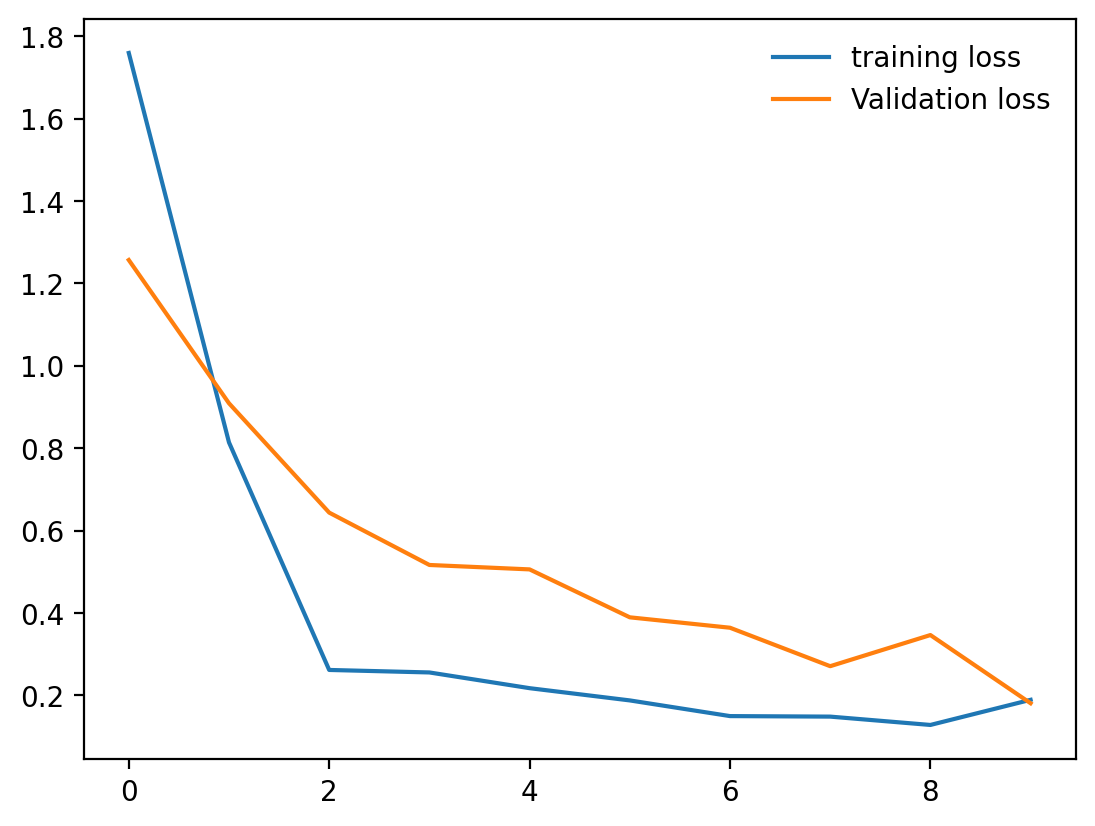
# 손실 그래프 생성
plt.plot(train_losses, label='training loss')
plt.plot(test_losses, label='Validation loss')plt.plot(train_losses, label='training loss'): 학습 손실 리스트를 그래프로 그린다.plt.plot(test_losses, label='Validation loss'): 검증 손실 리스트를 그래프로 그린다.
# 범례 표시 설정
plt.legend(frameon=False)plt.legend(frameon=False): 그래프의 범례를 표시.frameon=False옵션은 범례 주위의 프레임을 제거하여 깔끔하게 표시한다.
학습 테스트 완료된 모델 저장
torch.save(model, 'moonrockmodel.pth')torch.save(model, 'moonrockmodel.pth'):model객체를'moonrockmodel.pth'라는 파일로 저장한다.- 이
.pth파일에는 모델의 구조와 가중치 정보가 포함되어 있어 추후 동일한 모델을 다시 불러와 사용할 수 있다.
예측
학습된 모델 불러오기
# 컴퓨팅 장치 설정
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')- 현재 사용할 수 있는 컴퓨팅 장치를 설정한다. GPU가 사용 가능하면
cuda를 선택하고 그렇지 않으면cpu를 사용한다.
# 저장된 모델 불러오기
model = torch.load('moonrockmodel.pth')torch.load('moonrockmodel.pth'):'moonrockmodel.pth'파일에 저장된 모델을 가져온다.- 이 모델에는 이전에 학습된 가중치 구조와 모델 구조가 포함되어 있어 즉시 예측에 사용할 수 있다.
이미지 예측 함수 작성
# 이미지 텐서 전환
image_tensor = t_transforms(image).float()t_transforms(image): 입력된 이미지를 텐서로 변환하고 필요한 전처리를 적용한다.t_transforms는 앞서 설정한 변환으로 크기 조정 및 텐서화 등의 작업을 포함한다.
# 배치 차원 추가
input = image_tensor.unsqueeze_(0)unsqeeze_(0): 텐서의 첫번째 차원에 새로운 축을 추가하여 배치 차원을 만든다. 모델 입력은[배치 크기, 채널 수, 높이, 너비]형식이어야 하므로 배치 차원이 필요하다.
# 장치로 이동
input = input.to(device)input텐서를 학습에 사용할 장치(device)로 이동하여 GPU(또는 CPU)에서 계산이 가능하도록 한다.
# 모델 예측 수행
output = model(input)model(input): 모델이 예측을 수행하여 각 클래스에 대한 출력을 반환한다.output에는 각 클래스의 확률 점수가 포함되어 있다.
# 예측 클래스 인덱스 추출
index = output.data.numpy().argmax()output.data.numpy():output텐서를 넘파이 배열로 변환하여 계산을 더 쉽게 만든다.argmax(): 가장 큰 값의 인덱스를 반환하며 이는 모델이 가장 높은 확률로 예측한 클래스의 인덱스이다.
이미지 데이터 예측
# 모델 평가 모드 전환
model.eval()model.eval(): 모델을 평가 모드로 전환하여 드롭아웃이나 배치 정규화와 같은 레이어의 동작을 비활성화한다. 이는 테스트 중 일관된 결과를 보장한다.
# PIL 이미지 변환 설정 및 무작위 이미지 로드
to_pil = transforms.ToPILImage()
images, labels = get_random_images(5)
fig = plt.figure(figsize=(20, 20))transforms.ToPILImage(): 텐서 형태의 이미지를 PIL 이미지로 변환.get_random_image(5): 무작위 5개의 이미지와 해당 레이블을 가져온다.plt.figure(figsize=(20, 20)): 이미지 출력 크기를 설정하여 다수의 이미지를 보기 좋게 배치한다.
# 각 이미지에 대해 예측 수행
for ii in range(len(images)):
image = to_pil(images[ii])
index = predict_image(image)for ii in range(len(images)): 가져온 5개의 이미지에 대해 반복 작업 수행.to_pil(image[ii]): 현재 이미지를 PIL 형식으로 변환해predict_image()함수가 처리할 수 있도록 한다.predict_image(image): 변환된 이미지를 입력으로 받아 예측된 클래스의 인덱스(index)를 반환.
# 결과 시각화 설정
sub = fig.add_subplot(1, len(images), ii+1)
res = labels[ii].item() == index
sub.set_title(classes[index] + ':' + str(res))
plt.axis('off')
plt.imshow(image)fig.add_subplot(1, len(images), ii+1): 1행에 5개 서브플롯을 생성하여 각 이미지를 나란히 배치한다.labels[ii].item() == index: 예측 결과(index)와 실제 레이블(labels[ii])이 일치하는지 확인하여res에 저장.sub.set_title(classes[index] + ':' + str(res)): 예측된 클래스 이름과 예측인 올바른지 여부(True or False)를 제목으로 표시한다.plt.axis('off'): 축을 제거하여 깔끔한 이미지를 출력한다.plt.imshow(image): 변환된 PIL 이미지를 서브플롯에 출력.

커스텀비전
클라우드
클라우드 컴퓨팅
인터넷을 통해 서버, 스토리지, 데이터베이스, 네트워크 등 다양한 컴퓨팅 자원을 원할 때 제공하는 방식. 사용자는 필요한 리소스를 원할 때만 사용할 수 있으며 물리적인 리소스 관리 부담을 줄여 애플리케이션과 데이터 관리에 집중할 수 있다.
클라우드 역사
클라우드 컴퓨팅의 기초 기술은 1960년대 시분할 기술부터 발전해 왔으며 본격적으로는 2006년 AWS를 통한 IaaS 제공을 시작으로 발전했다. 이후 Microsoft Azure의 PaaS, AI와 서버리스 기술 등이 도입되며 확장되고 있다.
클라우드 핵심 기술
가상화(virtualisation), 분산 컴퓨팅(distributed computing), 확장 가능한 인프라, 고속 인터넷, 자동화, 표준화 및 API, 보안, 데이터 보호 기술이 클라우드 컴퓨팅을 가능하게 하는 주요 기술로 작용한다.
클라우드 도입의 이점
고가용성, 확장성, 안정성, 예측 가능성, 보안, 관리 효율성 등 여러 이점을 제공한다. 특히 필요에 따라 IT 자원을 효율적으로 확장 및 관리할 수 있다는 점이 강점이다.
클라우드 서비스 모델
IaaS(인프라형 서비스), PaaS(플랫폼형 서비스), SaaS(소프트웨어형 서비스)로 구분된다. 각각의 서비스 모델은 사용자가 관리하는 부분과 제공자가 관리하는 부분이 다르며 온프레미스(직접 관리)와 클라우드 서비스 제공 사이의 관리 책임도 다르다.
공유 책임 모델
클라우드 제공업체와 사용자가 함께 보안을 책임지는 공유 모델이 적용된다.
Azure Custom Vision
Azure에서 제공하는 인공지능 서비스 중 하나로 이미지 분류와 개체 감지 모델을 생성할 수 있는 기능을 제공한다. 이 서비슨느 사용자가 목적에 맞는 모델을 학습하고 배포할 수 있도록 직관적인 인터페이스를 제공하며 클라우드 상에서 유연하게 활용할 수 있다.
Custom Vision 작동 방식
- 이미지 분류(Classification): 입력된 이미지를 특정 레이블로 분류하여 태그를 예측한다.
- 개체 감지(Object Detection): 이미지 내 특정 개체를 감지하여 레이블과 위치(좌표)를 반환한다.
- 적은 양의 데이터로도 시작할 수 있고, 성능 향상을 위해 50개 이상의 이미지 사용이 권장된다.
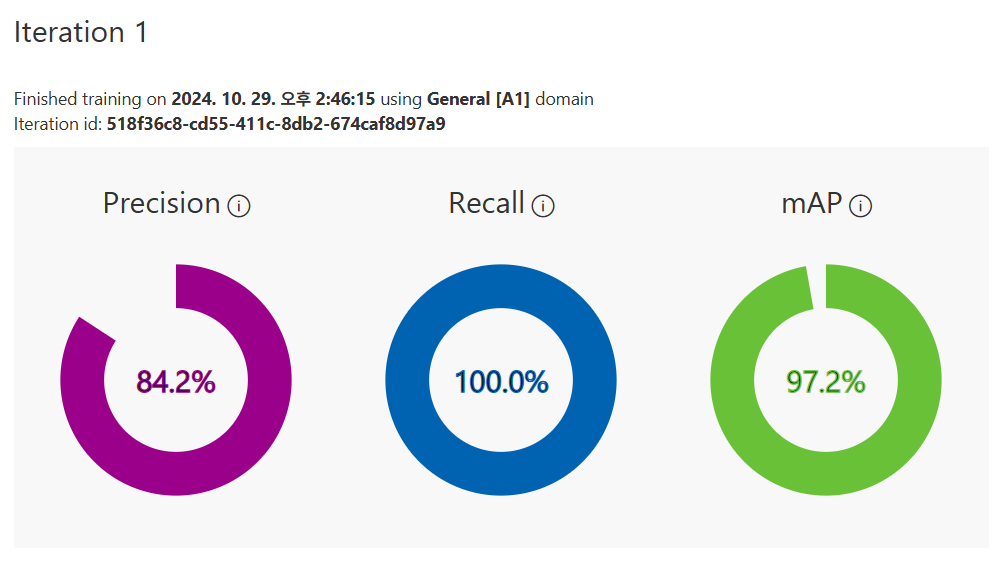
Image 분류 AI 모델 실습
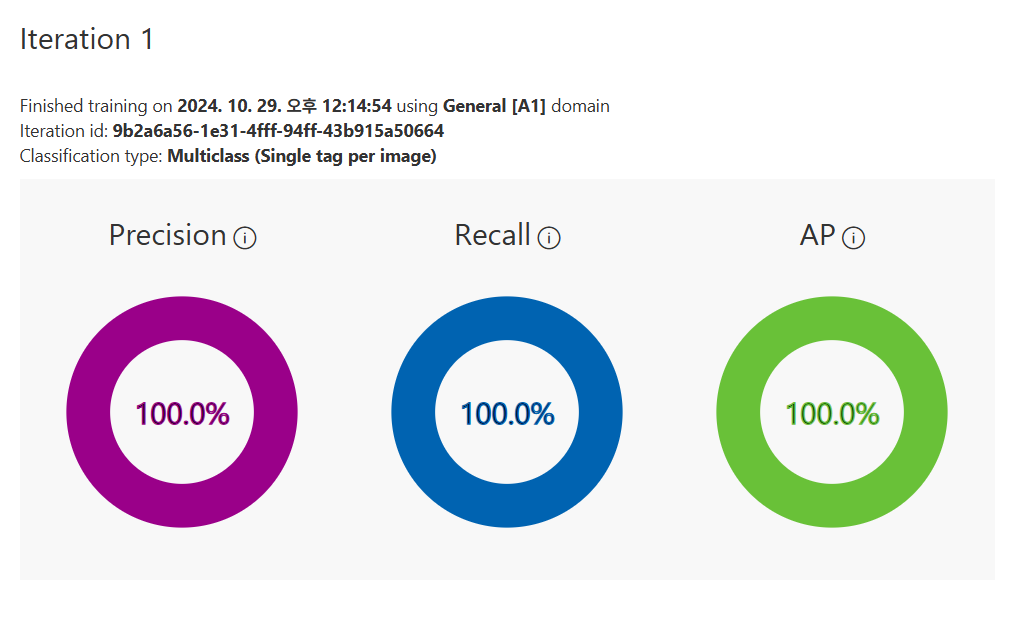
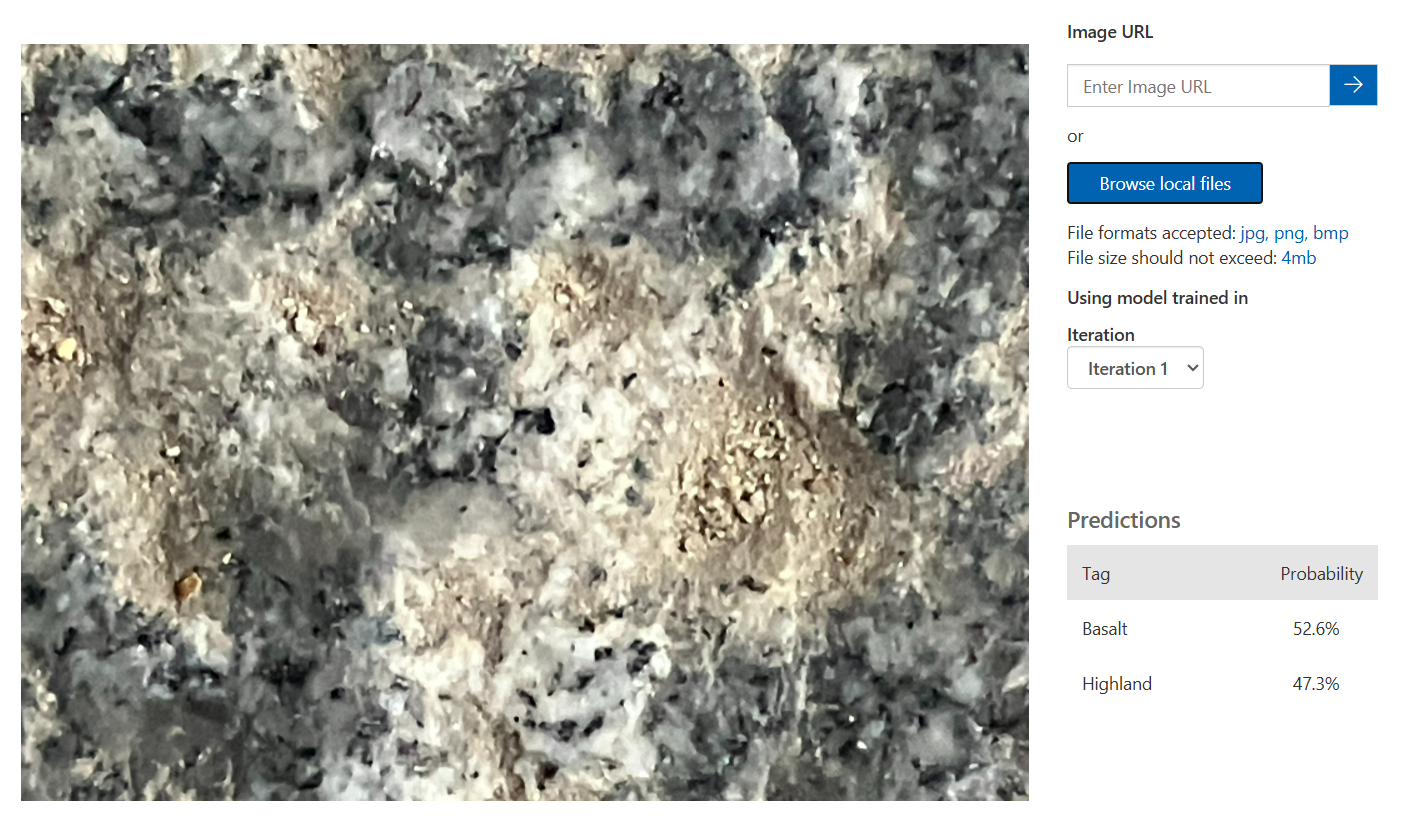
우연히 주일에 찍은 돌사진이 있어서 넣어보았다.
개체 감지 AI 모델 실습
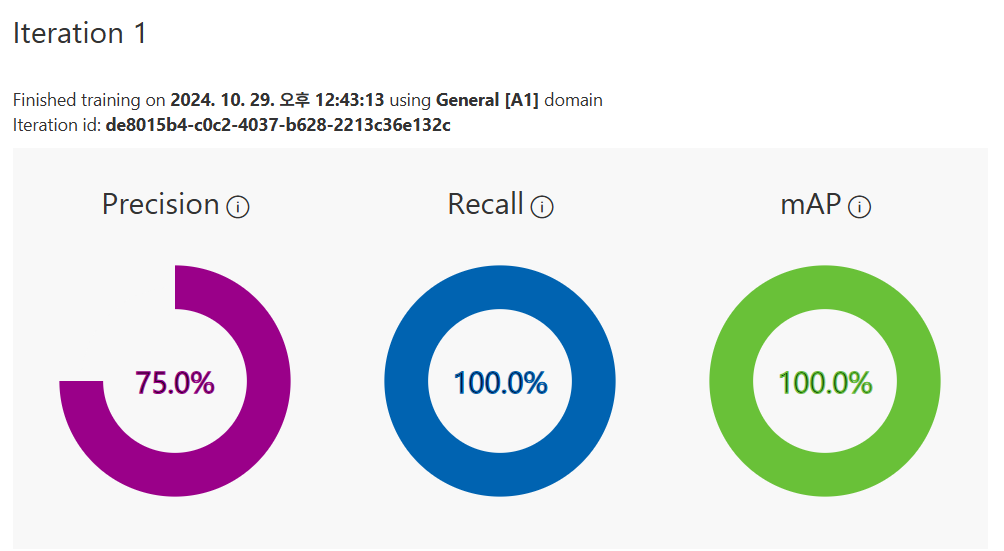
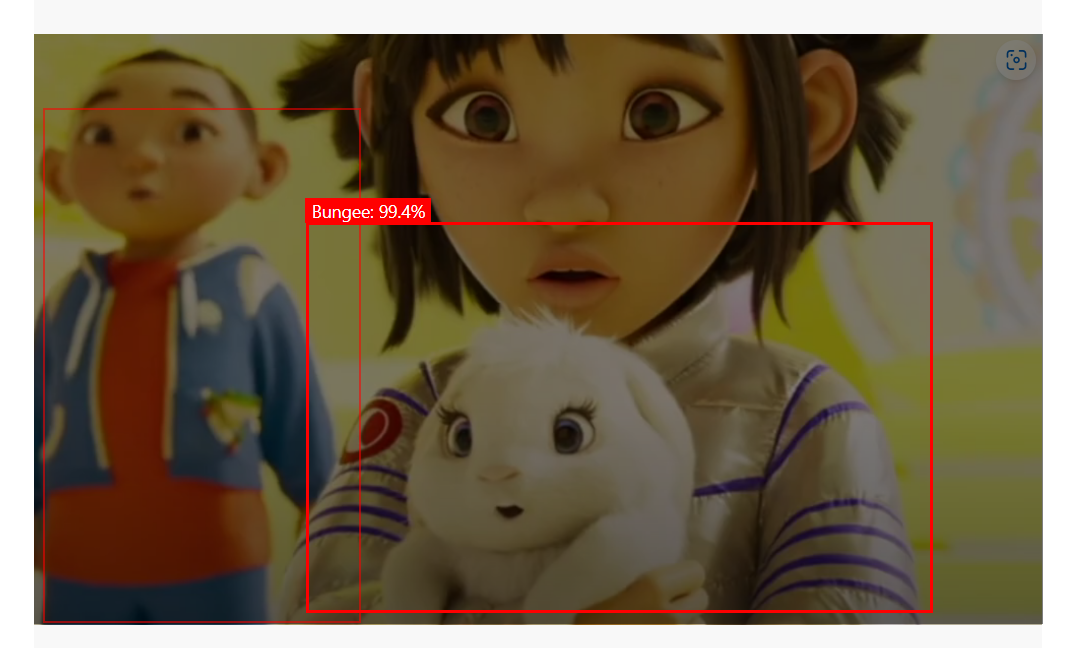

우리 집 멍멍은 Bungee였다는 충격적인 사실
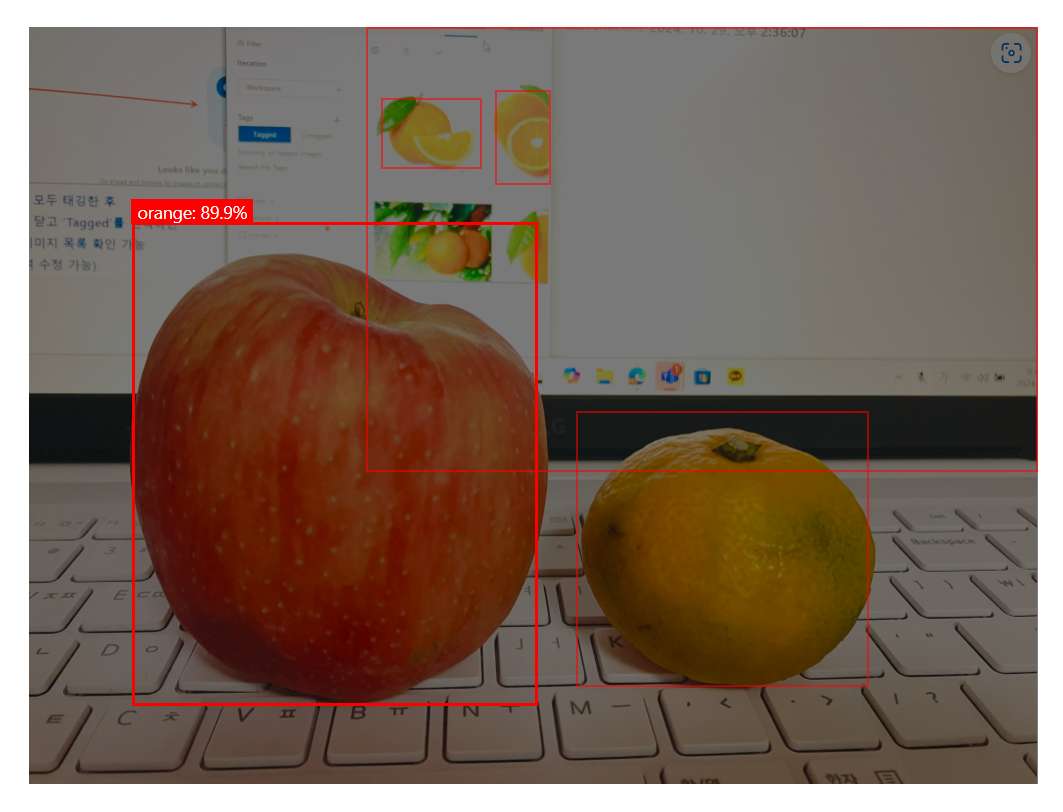
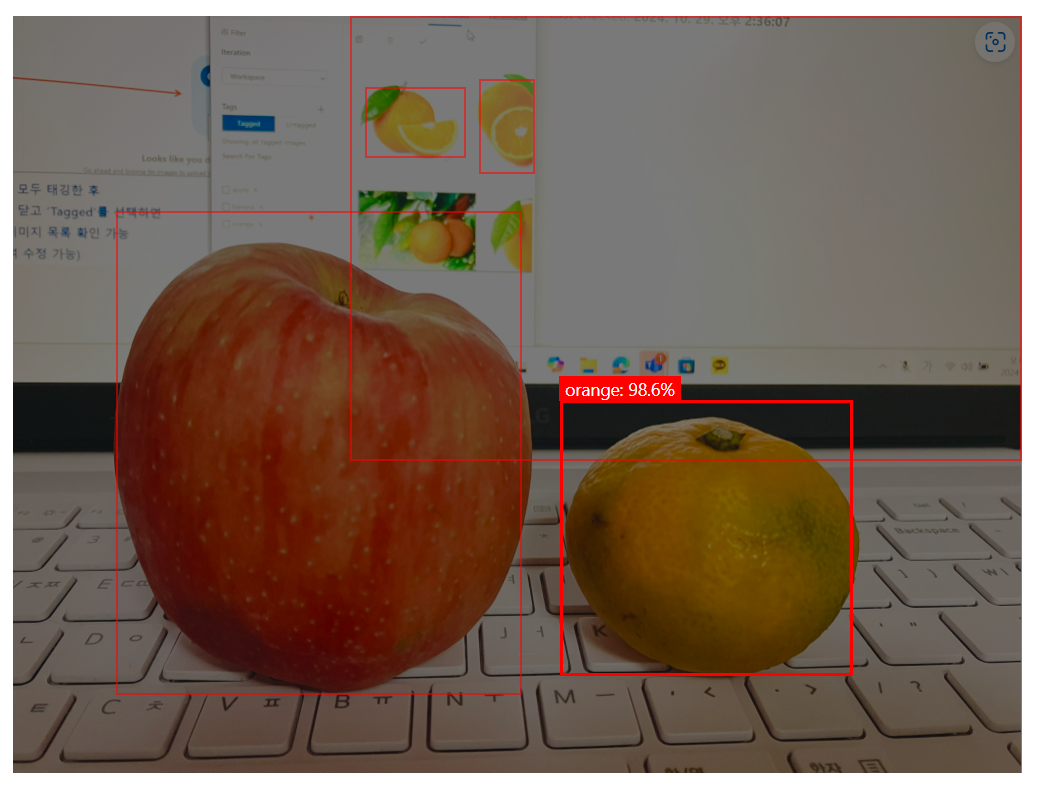
사과랑 오렌지, 바나나 이미지를 학습시키고, 마침 집에 귤과 사과가 있어서 직접 사진을 찍어서 테스트 해봤는데,, 다 틀렸다. 하하
모델 활용 실습
Object Detection
from azure.cognitiveservices.vision.customvision.prediction import CustomVisionPredictionClient
from msrest.authentication import ApiKeyCredentials
from matplotlib import pyplot as plt
from PIL import Image, ImageDraw, ImageFont
import numpy as np
import osfrom azure.cognitiveservices.vision.customvision.prediction import CustomVisionPredictionClient: Azure Custom Vision에서 학습된 모델을 사용해 이미지 예측을 수행하는 클라이언트. 이 클라이언트를 통해 Custom Vision 모델에 예측 요청을 할 수 있다.from msrest.authentication import ApiKeyCredentials: Azure API 호출 시 필요한 인증을 수행하기 위한 모듈. API 키 기반 인증을 설정하여 Custom Vision 서비스의 예측 클라이언트에 접근할 수 있게 한다.from PIL import Image, ImageDraw, ImageFont
-PIL: Python Imaging Libarary.Image는 이미지 열기와 변환,ImageDraw는 이미지 위에 그래픽을 그리기 위해 사용하며,ImageFont는 텍스트 표시를 위한 폰트 스타일링에 사용된다.import os: 파일 시스템 작업을 수행하며 이미지 파일을 읽거나 저장 위치를 설정할 때 사용된다.
prediction_endpoint = "~"
prediction_key = "~"
project_id = "~"
model_name = "Iteration1"prediction_endpoint: Azure Custom Vision 서비스의 엔드포인트 URL. Azure 포털 커스텀 비전 서비스 내 프로젝트에서 확인할 수 있고, 이 URL로 요청을 보내게 된다.prediction_key: Custom Vision 서비스 예측 API에 접근하기 위한 인증 키. Custom Vision 리소스 생성 시에 부여되고, 예측 요청을 할 때 필수적으로 사용된다.project_id: Custom Vision 프로젝트의 고유 식별자. 각 프로젝트마다 부여되는 ID로 예측을 요청할 때 어떤 프로젝트의 모델을 사용할지 지정하는 역할을 한다.model_name: 예측에 사용할 모델의 이름(버전). Custom Vision에서는 프로젝트 모델을 여러번 학습할 수 있고 각 학습 모델은 별도의 이름으로 저장된다.
credentials = ApiKeyCredentials(in_headers={"Prediction-key": prediction_key})
predictor = CustomVisionPredictionClient(endpoint=prediction_endpoint, credentials=credentials)credentials = ApiKeyCredentials():ApiKeyCredentials를 사용해 Custom Vision API에 대한 인증을 설정한다. 이 인증 객체는prediction_key를 이용해 헤더를 구성하여 API에 접근 권한을 부여한다.predictor = CustomVisionPredictionClient()
-CustomVisionPredictionClient객체를 생성하여 예측 기능을 수행할 수 있는predictor인스턴스를 초기화한다.- 이 인스턴스는
prediction_endpoint와credentials를 사용하여 생성되고, 이후predictor객체를 통해 Azure Custom Vision 모델에 이미지를 보내고 예측 결과를 받아올 수 있다.
- 이 인스턴스는
image_file = "~.png"
print('Detecting objects in ', image_file)
image=Image.open(image_file)
h, w, ch = np.array(image).shape
print(h)
print(w)
print(ch)image_file: 예측에 사용할 이미지 파일의 경로를 지정한다.image = Image.open(image_file):PIL.Image.open()을 사용해 이미지 파일을 열고image변수에 저장한다.h, w, ch = np.array(image).shape:numpy.array()를 이용해image를 배열로 변환하여 이미지의 크기 및 채널 정보를 가져온다.h,w,ch는 각각 이미지의 높이, 너비, 채널 수를 나타낸다.일반적으로 컬러 이미지의 경우ch는 3(RGB)라고 한다.
# 이미지 파일 열기 및 예측 요청
with open(image_file, mode="rb") as image_data:
results = predictor.detect_image(project_id, model_name, image_data)open(image_file, mode="rb"): 이미지 파일을 바이너리 읽기 모드(rb) 로 연다. 이진 데이터를 Azure Custom Vision API에 전달하기 위함.predictor.detect_image(): Custom Vision API 예측 기능을 사용하여 지정된project_id와model_name에 대해 이미지 데이터를 분석한다.results에는 예측 결과가 저장된다.
# 그림과 축 설정
fig = plt.figure(figsize=(8,8))
plt.axis('off')fig = plt.figure(figsize=(8, 8)): 8*8 크기의 그림을 생성.plt.axis('off'): 축을 제거하여 이미지만 표시되도록 한다.
# 이미지 그리기 준비
draw = ImageDraw.Draw(image)
lineWidth = int(w/100)
color = 'magenta'draw = ImageDraw.Draw(image): 이미지 객체에 그림을 그릴 수 있는ImageDraw객체를 생성한다.lineWidth: 바운딩 박스 테두리의 두께를 설정하여 이미지 너비의 1%를 기준으로 한다.color: 바운딩 박스의 색상으로 설정된다.
# 예측 결과에 따른 바운딩 박스와 텍스트 추가
for prediction in results.predictions:
if (prediction.probability*100) > 50:
left = prediction.bounding_box.left * w
top = prediction.bounding_box.top * h
width = prediction.bounding_box.width * w
height = prediction.bounding_box.height * h
points = ((left,top), (left+width,top), (left+width,top+height), (left,top+height), (left,top))
draw.line(points, fill=color, width=lineWidth)
plt.annotate(prediction.tag_name + ' {0:.2f}%'.format(prediction.probability * 100), (left, top), color=color)- 예측 확률이 50% 이상인 예측만 표시하기 위해
if조건문이 사용된다. left,top,width,height: 바운딩 박스의 위치와 크기를 픽셀 좌표로 변환.points: 바운딩 박스의 각 꼭짓점 좌표를 포함하는 튜플.draw.line(points, fill=color, width=lineWidth)는 이 좌표에 따라 직사각형을 그린다.plt.annotate: 바운딩 박스 위에 예측된 객체의 이름과 확률을 텍스트로 추가한다.
# 결과 이미지 표시 및 저장
plt.imshow(image)
outputfile = 'output.jpg'
fig.savefig(outputfile)
print('Results saved in', outputfile)plt.imshow(image): 바운딩 박스와 태그가 추가된 이미지를 표시한다.fig.savefig(outputfile): 최종 이미지를output.jpg파일로 저장한다.

Image Classification
Object Detection에 내용이 거의 다 포함되어 있어서 패스
OpenCV
OpenCV 개요
OpenCV (Open Source Computer Vision)
컴퓨터 비전과 머신러닝을 위한 이미지 처리 라이브러리로 인텔에서 개발되어 현재는 컴퓨터 비전 작업의 표준 라이브러리로 자리잡았다.
지원 언어
Python, C++, Java 등을 지원하고, 실시간 이미지 및 동영상 분석 기능을 제공한다.
주요 기능
- 이미지 처리
- 개체 검출
- 동영상 분석
- 증강 현실
활용 사례
- 얼굴 인식
- 산업 자동화
- 자율 주행
실습 준비
OpenCV 설치
import sys
!{sys.executable} -m pip install opencv-python이미지 불러오기, 저장, 표시 및 확인
OpenCV 불러오기 및 이미지 로딩
import cv2
import numpy as np
from matplotlib import pyplot as pltcv2: OpenCV 라이브러리. 이미지 및 비디오 분석을 위한 다양한 함수를 제공한다.
image = cv2.imread('Puppy.jpg')cv2.imread(): 'Puppy.jpg' 이미지 파일을 읽어와image변수에 저장한다.
if image is None :
print("Error : 이미지 읽기 실패")cv2.imread()가 이미지 파일을 찾지 못하거나 불러오는 데 실패하면image변수는 None 값을 갖게 된다.
이미지 표시
plt.imshow(image)
plt.show()plt.imshow(): 이미지를 화면에 표시.plt.show(): 화면에 표시된 이미지를 실제로 출력하여 볼 수 있게 한다.
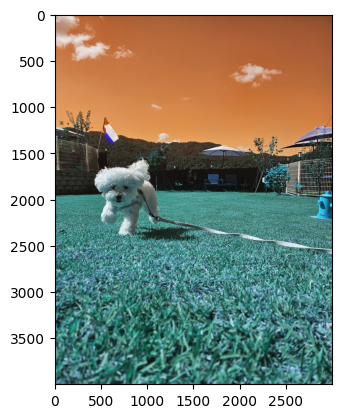
OpenCV로 불러온 이미지는 기본적으로 BGR 형식이라 올바른 색상으로 표시하려면 RGB 형식으로 변환해야 한다.
컬러맵 변환
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.show()cv2.cvtColor(image,cv2.COLOR_BGR2RGB): OpenCV로 불러온 이미지를 BGR 형식에서 RGB 형식으로 변환하여 올바른 색상으로 표시한다.

gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY): 원본 이미지를 그레이스케일로 변환하여gray_image에 저장.
이미지 저장
cv2.imwrite('dog_saved.jpg', image)cv2.imwrite(): 이미지를 파일로 저장하는 함수.
-'dog_saved.jpg': 저장할 파일의 이름과 형식을 지정.image: 저장할 이미지 데이터. OpenCV에서 불러오거나 처리한 이미지 배열이 들어간다.
이미지 표시 함수 구현
def show_image(image, title='noname'):
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # BGR을 RGB로 변환
plt.imshow(image_rgb)
plt.title(title)
plt.axis('off') # 축 제거
plt.show()def show_image(image, title='noname'):show_image라는 이름의 함수를 정의하며 두 개의 인자를 받는다.
-image: 표시할 이미지 배열.title: 이미지 위에 표시할 제목. 기본값은 noname.
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB): OpenCV에서 불러온 BGR 형식의 이미지를 RGB 형식으로 변환항image_rgb변수에 저장.plt.imshow(image_rgb): 변환된 RGB 이미지를 화면에 표시.plt.title(title): 이미지를 표시할 때 제목 설정.plt.axis('off'): 이미지 주변의 축과 눈금을 제거하여 깔끔하게 표시.pl.show(): 이미지를 화면에 출력.
이미지 변환
크기 조정
resized_image = cv2.resize(image, (224, 224))
show_image(resized_image, "Resized Image")cv2.resize(image, (224, 224)):image를(224, 224)크기로 변경하여resized_image변수에 저장한다.

회전
rotated_image = cv2.rotate(image, cv2.ROTATE_90_CLOCKWISE)
show_image(rotated_image, "Rotated Image")cv2.rotate(image, cv2.ROTATE_90_CLOCKWISE):image를 시계 방향으로 90도 회전하여rotated_image에 저장한다.
-cv2.ROTATE_90_CLOCKWISE: 이미지 회전을 시계 방향으로 90도 설정하는 옵션.

뒤집기
flipped_image = cv2.flip(image, 1)
show_image(flipped_image, "Flipped Image")cv2.flip(image, 1):image를 좌우로 뒤집어flipped_image에 저장한다. 1을 지정하면 이미지가 좌우로 대칭(수평) 반전되며, 0을 사용하면 상하(수직) 반전, -1은 좌우 및 상하 모두 반전을 의미한다.


크롭
x, y, w, h = 2000, 2000, 1000, 1000
cropped_image = image[y:y+h, x:x+w]
show_image(cropped_image, "Cropped Image")x, y, w, h = 2000, 2000, 1000, 1000: 자르기 영역 정의.
-x,y: 잘라낼 영역의 왼쪽 상단 좌표 (가로 x=2000, 세로 y=2000)w,h: 잘라낼 영역의 너비와 높이 (각각 1000 픽셀)
cropped_image = image[y:y+h, x:x+w]: 지정된 좌표와 크기에 따라 원본image에서 잘라낸 부분을cropped_image에 저장.
- 이미지의 특정 부분을[y:y+h, x:x+w]형식으로 슬라이싱하여 얻는다.

import random
H, W = image.shape[:2]
crop_size = 1000 # 크롭할 영역 크기
x = random.randint(0, W - crop_size) # 크롭 시작 좌표 (임의의 위치)
y = random.randint(0, H - crop_size)
cropped_image = image[y:y+crop_size, x:x+crop_size]
show_image(cropped_image, "Cropped Image")H, W = image.shape[:2]: 원본 이미지의 높이(H)와 너비(W)를 추출하여 자르기 위치를 결정하는 데 사용한다.crop_size = 1000: 잘라낼 영역의 크기를 1000*1000으로 설정한다.x = random.randint(0, W - crop_size),y = random.randint(0, H - crop_size)
-x,y: 자르기 시작 위치의 좌표. 이미지 내 임의의 위치를 선택한다.random.randint()함수를 사용하여 0부터W - crop_size와H - crop_size사이의 값 중 무작위로 선택한다. 이를 통해 잘라낼 영역이 이미지 경게를 넘어가지 않게 한다.
cropped_image = image[y:y+crop_size, x:x+crop_size]: 선택된 좌표에서crop_size만큼의 크기로 이미지에서 잘라낸 부분을cropped_image에 저장한다.

def random_crop_and_resize(image, crop_size, resize_size):
H, W = image.shape[:2]
x = random.randint(0, W - crop_size) # 크롭 시작 좌표 (임의의 위치)
y = random.randint(0, H - crop_size)
cropped_image = image[y:y+crop_size, x:x+crop_size]
resized_image = cv2.resize(cropped_image, (resize_size, resize_size))
return resized_imageH,W: 입력 이미지의 높이, 너비.x,y: 각각 이미지 너비와 높이를 기반으로 임의의 시작 좌표를 선택.cropped_image:(x, y)에서 시작하여crop_size만큼의 영역을 잘라낸 이미지.resized_image:crop_size로 잘라낸 이미지를resize_size로 다시 조정한 결과물.

밝기 및 대비
alpha = 0.5; beta = 0 # 4. 대비 감소 (alpha = 0.5)
adjusted_image = cv2.convertScaleAbs(image, alpha=alpha, beta=beta)
show_image(adjusted_image, f'Adjusted Image ({alpha}, {beta})')adjusted_imagealpha = 0.5: 대비를 절반으로 줄임.alpha값이 1보다 작으면 대비가 감소하고, 1보다 크면 대비가 증가한다.beta = 0: 밝기를 추가로 조정하지 않도록 설정. 이 값이 양수면 밝기가 증가하고 음수면 밝기가 감소한다.
cv2.convertScaleAbs(image, alpha=alpha, beta=beta): OpenCV 함수를 사용하여image의 각 픽셀 값을alpha * pixel_value + beta로 변환한다. 절댓값이 적용된다.

히스토그램
# 히스토그램 시각화를 위한 함수
def plot_histogram(img, title):
plt.figure()
plt.title(title)
plt.hist(img.ravel(), 256, [0, 256])
plt.xlabel("Pixel Intensity")
plt.ylabel("Frequency")
plt.show()plt.figure(): 새로운 그래프 창을 연다.img.ravel(): 이미지를 1차원 배열로 변환하여 각 픽셀의 밝기 값이 전체 범위로 표현되도록 한다.
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
plot_histogram(gray_image, "Original Image Histogram")cv2.cvtColor(image, cv2.COLOR_BGR2GRAY):image를cv2.COLOR_BGR2GRAY플래그를 사용해 그레이 스케일로 변환한다.
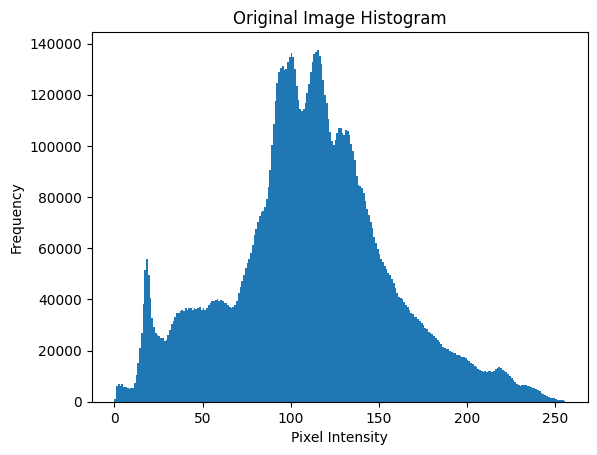
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
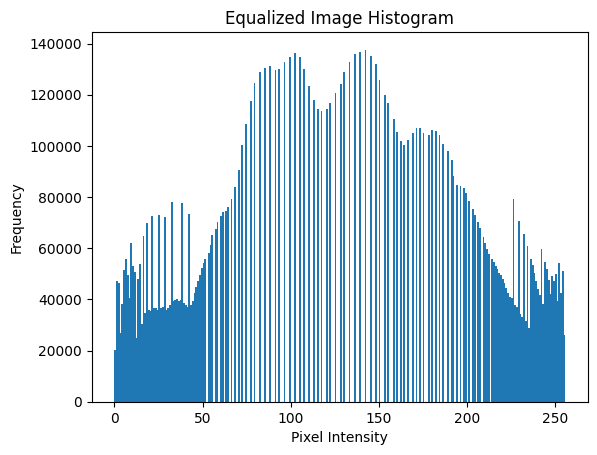
equalized_image = cv2.equalizeHist(gray_image)
plot_histogram(equalized_image, "Equalized Image Histogram")
show_image(equalized_image, "Histogram Equalized Image")cv2.equalizeHist(gray_image):gray_image히스토그램을 평활화하여 대비가 개선된 이미지를 생성한다.

# YUV 색 공간으로 변환
yuv_img = cv2.cvtColor(image, cv2.COLOR_BGR2YUV)
# 밝기 채널에 히스토그램 평활화 적용
yuv_img[:, :, 0] = cv2.equalizeHist(yuv_img[:, :, 0])
# RGB 색 공간으로 다시 변환
equalized_img = cv2.cvtColor(yuv_img, cv2.COLOR_YUV2BGR)
# 결과 이미지 저장 또는 표시
show_image(equalized_img, 'Equalized Image')cv2.cvtColor(image, cv2.COLOR_BGR2YUV): BGR 이미지를 YUV 색 공간으로 변환.
-Y: 밝기 /U,V: 색상 정보yuv_img[:, :, 0] = cv2.equalizeHist(yuv_img[:, :, 0]):Y채널(밝기)에 히스토그램 평활화를 적용.cv2.cvtColor(yuv_img, cv2.COLOR_YUV2BGR): YUV 이미지를 BGR로 다시 변환하여 원래 색상과 평활화된 밝기가 결합된 결과 이미지를 생성.

yuv = cv2.cvtColor(image, cv2.COLOR_BGR2YUV)
clahe = cv2.createCLAHE(clipLimit=1.0, tileGridSize=(8, 8))
yuv[:, :, 0] = clahe.apply(yuv[:, :, 0])
clahe_image = cv2.cvtColor(yuv, cv2.COLOR_YUV2BGR) # BGR 색 공간으로 다시 변환
show_image(clahe_image, 'Equalized Image (CLAHE)')cv2.createCLAHE(clipLimit=1.0, tileGridSize=(8, 8)): CLAHE 객체를 생성.여기서 계속 CLANE로 입력해서 오류가 났었다.
-clipLimit=1.0: CLAHE의 대비 제한 값으로 값이 높으면 더 강한 대비가 적용되며 낮으면 대비 증가가 제한된다.tileGridSize=(8, 8): 이미지를(8, 8)타일로 나누어 각 타일 내에서 히스토그램을 평활화하여 국소적인 대비 조정을 수행한다.
yuv[:, :, 0] = clahe.apply(yuv[:, :, 0]): Y 채널에 CLAHE를 적용하여 조명 조건이 일정하지 않은 이미지의 대비를 균일하게 조정한다.

이진화
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
_, binary_image = cv2.threshold(gray_image, 150, 255, cv2.THRESH_BINARY)
show_image(binary_image, 'Binary Image')cv2.cvtColor(image, cv2.COLOR_BGR2GRAY): 입력된 컬러 이미지를 그레이스케일로 변환.cv2.threshold(gray_image, 150, 255, cv2.THRESH_BINARY): 그레이스케일 이미지gray_image의 각 픽셀 값을 임계값(150)과 비교하여 이진화한다.
-150: 임계값. 픽셀 값이 150보다 크면 255(흰색), 150 이하이면 0(검정)으로 설정된다.
-255: 픽셀 값이 임계값보다 높을 때 설정할 최대 밝기 값.
-cv2.THRESH_BINARY: 이진화 모드로 지정된 임계값에 따라 픽셀 값을 두 가지 값으로 나눈다.

gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
_, binary_image = cv2.threshold(gray_image, 150, 255, cv2.THRESH_BINARY_INV)
show_image(binary_image, 'Binary Image(INV)')_, bianry_image = cv2.threshold(gray_image, 150, 255, cv2.THRESH_BINARY_INV) - 그레이스케일 이미지에 이진 임계값을 적용. -THRESH_BINARY_INV`: 이진화 반전.

gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
_, binary_image = cv2.threshold(gray_image, 150, 255, cv2.THRESH_TRUNC)
show_image(binary_image, 'Binary Image(TRUNC)')cv2.THRESH_TRUNC: 주어진 임계값보다 큰 값은 임계값으로 잘리고, 나머지 값은 그대로 유지.

gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
_, binary_image = cv2.threshold(gray_image, 127, 255, cv2.THRESH_TOZERO)
show_image(binary_image, 'Binary Image(TOZERO)')THRESH_TOZERO: 주어진 임계값보다 작은 픽셀 값을 0으로 바꾸고, 큰 픽셀 값은 그대로 유지하는 방식.

이진화 임계값 찾기
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
_, otsu_image = cv2.threshold(gray_image, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
show_image(otsu_image, "Otsu's Thresholding")_, otsu_image = cv2.threshold(gray_image, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
-0: Otsu 알고리즘이 최적의 임계값을 자동으로 계산하도록 지시.
-cv2.THRESH_BINARY + cv2.THRESH_OTSU: 이진화 방법을 지정. Otsu 방법은 이미지의 히스토그램을 분석하여 최적의 임계값을 찾는다. 이 방법은 명암 대비가 뚜렷할 때 효과적이다.

적응형 이진화
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
adaptive_mean = cv2.adaptiveThreshold(gray_image, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 151, 2)
show_image(adaptive_mean, "Adaptive Mean Thresholding")cv2.adaptiveThreshold: 적응형 임계값 처리를 수행한다. 이미지의 작은 영역에 대해 임계값을 다르게 적용하여 이진화한다.
-cv2.ADAPTIVE_THRESH_MEAN_C: 적응형 방법으로 각 픽셀의 임계값을 그 주위의 평균을 사용하여 결정한다.C는 계산된 평균에서 빼는 상수.
-151: 주변 픽셀의 크기를 지정. 이 값은 블록 크기로 홀수여야 한다.
-2: C의 값으로 계산된 평균에서 빼는 상수. 이 값이 크면 결과 이미지에서 더 많은 픽셀들이 흰색으로 설정된다.

gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
adaptive_gaussian = cv2.adaptiveThreshold(gray_image, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 151, 2)
show_image(adaptive_gaussian, "Adaptive Gaussian Thresholding")cv2.ADAPTIVE_THRESH_GAUSSIAN_C: 가우시안 방식으로 주변 영역의 가중 평균을 사용하여 임계값을 계산. 더 부드럽고 자연스러운 결과를 제공한다.

블러링
blurred_image = cv2.GaussianBlur(image, (5, 5), 0) # 가우시안 블러 (필터크기, sigmaX)
show_image(blurred_image, "Blurred Image")cv.GaussianBlur: 입력 이미지를 가우시안 필터를 사용하여 블러 처리한다.
-(5, 5): 필터 크기. 가우시안 커널의 너비와 높이를 정의한다. 반드시 홀수여야 하고, 커널의 크기가 클수록 더 많은 블러 효과가 적용된다.
-0:sigmaX값으로 가우시안 커널의 표준 편차를 의미한다.0으로 설정하면 OpenCV가 자동으로 계산한다. 이 값이 크면 블러 효과가 더 부드럽게 적용된다.

모션 블러
import numpy as np
# 모션 블러 커널 생성 (크기가 클수록 블러 효과가 더 강해짐)
kernel_size = 120 # 모션 블러 커널 크기
kernel = np.zeros((kernel_size, kernel_size))kernel_size: 모션 블러의 강도를 결정하는 커널의 크기 설정. 크기가 클수록 블러 효과가 더 강해진다.np.zeros((kernel_size, kernel_size)): 주어진 크기로 0으로 초기화된 커널을 생성.
# 대각선 방향으로 1을 채워서 모션 블러 커널 생성
np.fill_diagonal(kernel, 1)
kernel = kernel / kernel_size # 블러 강도 조절np.fill_diagonal(kernel, 1): 커널의 대각선에 1을 채워서 대각선 방향으로 모션 블러를 나타내는 커널 생성.kernel = kernel / kernel_size: 커널의 모든 요소를 커널 크기로 나누어 블러 강도 조절. 이것으로 전체 픽셀 값의 합이 1이 되어 이미지의 밝기를 유지한다.
motion_blurred_image = cv2.filter2D(image, -1, kernel)
show_image(motion_blurred_image, "Motion Blurred Image")cv2.filter2D: 주어진 커널을 사용하여 이미지를 필터링.-1은 출력 이미지의 깊이를 입력 이미지와 동일하게 설정한다.

노이즈 추가
# 가우시안 노이즈 생성
mean = 0
stddev = 25 # 표준편차를 조정해 노이즈의 강도를 변경
gaussian_noise = np.random.normal(mean, stddev, image.shape).astype(np.float32)mean: 가우시안 분포의 평균을 설정.stddev: 표준편차를 설정하여 노이즈의 강도를 조정한다. 값이 클수록 노이즈가 더 강해진다.np.random.normal(mean, stddev, image.shape): 주어진 평균과 표준편차에 따라 이미지와 동일한 모양의 가우시안 노이즈를 생성..astype(np.float32): 생성된 노이즈를float32형으로 변환하여 이미지에 추가할 수 있게 한다.
# 이미지에 노이즈 추가
G_noisy_image = cv2.add(image.astype(np.float32), gaussian_noise)
G_noisy_image = np.clip(G_noisy_image, 0, 255).astype(np.uint8)
show_image(G_noisy_image, 'Noisy Image (Gaussian)')cv2.add(image.astype(np.float32), gaussian_noise): 원래 이미지에 가우시안 노이즈를 추가한다.image는float32형으로 변환되어야 한다.np.clip(G_noisy_image, 0, 255): 결과 이미지의 픽셀 값이 0에서 255 범위를 벗어나지 않도록 제한. 이것으로 이미지가 유효한 범위 내에 유지된다.astype(np.uint8): 최종 이미지를uint8형으로 변환하여 OpenCV에서 올바르게 표시할 수 있도록 한다.

H, W, C = image.shape
speckle_noise = image + image * np.random.randn(H, W, C) * 1.5
speckle_noise = np.clip(speckle_noise, 0, 255).astype(np.uint8)
show_image(speckle_noise, 'Noisy Image (Speckle)')H,W,C: 각각 이미지의 높이, 너비, 채널 수.speckle_noise = image + image * np.random.randn(H, W, C) * 1.5
-np.random.randn(H, W, C): 정규 분포(평균 0, 표준편차 1)를 따르는 무작위 값을 생성하여(H, W, C)크기의 배열을 만든다.image * np.random.randn(H, W, C): 각 픽셀에 대해 스케일링된 무작위 노이즈를 생성.1.5: 노이즈의 강도를 조절하는 상수. 이 값이 클수록 노이즈의 영향이 더 강해진다.image + ...: 원래 이미지에 스케일링 된 노이즈를 추가하여 스펙클 노이즈가 포함된 이미지를 만든다.
np.clip(speckle_noise, 0, 255): 결과 이미지의 픽셀 값이 0에서 255 범위를 벗어나지 않도록 제한.

prob = 0.25 # 25% 확률로 노이즈 추가
SP_noisy_image = np.copy(image)prob: 이미지의 픽셀 중에서 노이즈를 추가할 확률을 설정.SP_noisy_image: 원본 이미지의 복사본. 여기에 노이즈를 추가한다.
# 소금(흰색) 노이즈 추가
num_salt = np.ceil(prob * image.size * 0.5).astype(int) # 50%를 소금 노이즈로 사용
coords = [np.random.randint(0, i - 1, num_salt) for i in image.shape]
SP_noisy_image[coords[0], coords[1], :] = 255num_salt: 총 노이즈 픽셀 수의 50%를 소금 노이즈로 사용.coords: 각 차원(높이, 너비, 채널)에 대해 소금 노이즈의 위치를 랜덤으로 선택.SP_noisy_image[coords[0], coords[1], :] = 255: 선택된 위치에 소금 노이즈를 추가. 소금 노이즈는 픽셀 값이 255로 설정된다.
# 후추(검은색) 노이즈 추가
num_pepper = np.ceil(prob * image.size * 0.5).astype(int) # 50%를 후추 노이즈로 사용
coords = [np.random.randint(0, i - 1, num_pepper) for i in image.shape]
SP_noisy_image[coords[0], coords[1], :] = 0
show_image(SP_noisy_image, 'Noisy Image (Salt&Pepper)')num_pepper: 총 노이즈 픽셀 수의 50%를 후추 노이즈로 사용.

median_blur = cv2.medianBlur(SP_noisy_image, 5)
show_image(median_blur, 'Median Blur(Salt&Pepper)')cv2.medianBlur: 이미지를 블러링. 두 번째 인자5는 블러링에 사용되는 커널의 크기를 지정한다. 커널 크기는 홀수여야 한다.- 미디언 블러는 이미지의 각 픽셀을 해당픽셀 주변 픽셀 값의 중간값으로 대체한다. 이 과정에서 소금후추 노이즈가 효과적으로 제거된다.

엣지 검출
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
edges = cv2.Canny(gray_image, threshold1=20, threshold2=50)
show_image(edges, "Edge Detection")cv2.Canny: 회색조 이미지에서 엣지를 검출.threshold1,threshold2: 엣지 검출 과정에서 사용하는 두 개의 임계값.
-threshold1: 낮은 임계값. 엣지로 간주되기 위한 최소 강도.
-threshold2: 높은 임계값. 강도가 이 값을 초과하는 픽셀을 확실한 엣지로 간주된다.

Stable Diffusion에서 만났던 Canny를 이렇게 만나니 반가웠다.
import numpy as np
sobel_x = cv2.Sobel(image, cv2.CV_64F, 1, 0, ksize=3) # X 방향 경계
sobel_y = cv2.Sobel(image, cv2.CV_64F, 0, 1, ksize=3) # Y 방향 경계
sobel_x = cv2.convertScaleAbs(sobel_x)
sobel_y = cv2.convertScaleAbs(sobel_y)
sobel_combined = cv2.magnitude(sobel_x.astype(np.float32), sobel_y.astype(np.float32))
sobel_combined = cv2.convertScaleAbs(sobel_combined)
show_image(sobel_x, "Sobel - X Direction")
show_image(sobel_y, "Sobel - Y Direction")
show_image(sobel_combined, "Sobel - Combined")sobel_x = cv2.Sobel(image, cv2.CV_64F, 1, 0, ksize=3)
-cv2.Sobel: X 방향의 경계를 검출.cv2.CV_64F: 출력이미지의 데이터 타입을 64비트 부동 소수점으로 설정.1, 0: X 방향의 미분을 나타낸다. Y 방향 미분은 0.ksize=3: Sobel 커널의 크기를 3으로 설정. 이 값은 엣지를 감지하는 데 영향을 준다.
cv2.convertScaleAbs: 입력 이미지의 값을 절대값으로 변환하고 이를 8비트 이미지로 변환한다.cv2.magnitude: X 방향과 Y 방향에서 얻은 경계 강도의 크기를 계산하여 결합한다.



gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
equalized_image = cv2.equalizeHist(gray_image)
emboss_kernel = np.array([[-1, -1, 0],
[-1, 0, 1],
[0, 1, 1]])
embossed = cv2.filter2D(equalized_image, -1, emboss_kernel) + 128
show_image(embossed, "Embossed Image")emboss_kernel: 엠보싱 효과를 적용하기 위한 커널을 정의. 이 커널은 엠보싱 필터의 형태로 주변 픽셀들과의 차이를 강조하여 경계와 윤곽을 부각시킨다.+ 128: 이미지의 픽셀 값을 밝게 만들어 엠보싱 효과를 더욱 부각시킨다.

Zero-Centering
mean_values = np.mean(image, axis=(0, 1))np.mean: 이미지의 각 채널(B, G, R)의 평균 값을 계산.axis=(0, 1)은 이미지의 높이와 너비를 따라 평균을 계산하도록 지정한다.mean_values는 각 채널의 평균색 값을 포함하는 배열이 된다.
# zero-centering: 각 채널에서 평균값 빼기
zero_centered_image = image - mean_values- 원본 이미지에서 계산된 평균 값을 빼서 제로 centered 이미지를 생성한다.
- 이미지의 색상 분포가 평균적으로 0에 근접하게 된다.
# 결과 확인을 위한 스케일링 (이미지 출력 시 양수로 변환)
zero_centered_image = cv2.normalize(zero_centered_image, None, 0, 255, cv2.NORM_MINMAX).astype(np.uint8)
show_image(zero_centered_image, "Zero Centered Image")cv2.normalize: 제로 centered 된 이미지를 0에서 255 범위로 정규화한다. 이를 통해 이미지의 픽셀 값은 양수가 된다.NORM_MINMAX: 최솟값, 최댓값을 사용하여 픽셀 값을 정규화.


배경 제거
mask = np.zeros(image.shape[:2], np.uint8)
bgd_model = np.zeros((1, 65), np.float64)
fgd_model = np.zeros((1, 65), np.float64)mask: 이미지의 각 픽셀에 대한 초기 마스크를 생성.mask는 이미지의 높이와 너비를 갖는 2D 배열로 초기 값은 모두 0이다.bgd_model,fgd_model: 각각 배경 및 전경 모델을 초기화한다.
# ROI 설정 (배경/전경 구분할 초기 사각형 설정)
rect = (50, 50, image.shape[1] - 50, image.shape[0] - 50) # (x, y, width, height)rect: 전경과배경을 구분하는 초기 사각형 설정.
# GrabCut 적용
cv2.grabCut(image, mask, rect, bgd_model, fgd_model, 5, cv2.GC_INIT_WITH_RECT)cv2.grabCut: GrabCut 알고리즘 적용. 이미지, 초기 마스크, ROI, 배경 및 전경 모델, 반복 횟수, 초기화 방법을 인자로 받는다.5: 알고리즘이 수행할 반복 횟수.cv2.GC_INIT_WITH_RECT: 사각형을 기반으로 초기화하겠다는 의미.
# 전경 및 배경 마스크 생성
mask2 = np.where((mask == 2) | (mask == 0), 0, 1).astype("uint8")
foreground = image * mask2[:, :, np.newaxis]
show_image(foreground, "Background Removed")mask2: GrabCut 결과로 생성된mask에서 픽셀 값이 0 또는 2인 경우(배경 또는 불확실한 영역)에 대해 0으로 설정하고 나머지(전경)에 대해 1로 설정한다.foreground: 원본 이미지에mask2를 적용하여 전경만 남긴 이미지를 생성한다.mask2를 3차원으로 확장하여 각 색상 채널에 적용할 수 있도록 한다.

잘 된 것 같지는 않은,,
이 뒤에 얼굴 검출 실습이 있었는데 뭔가 순식간에 호다닥 지나가서 놓쳤다. ㅏㅏ하하
