강명호 강사님
붓꽃 군집화 모델
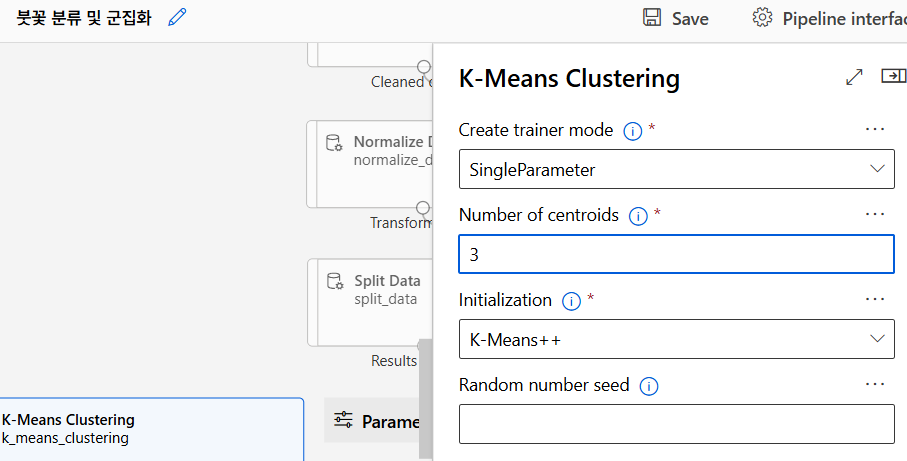
K-means 군집화
- 군집(K)의 개수를 정하고 임의의 중심점을 선택
- 데이터 포인트들을 가까운 중심점에 할당해 군집을 형성
- 새로운 중심점을 계산하고 이를 반복하여 군집의 변동이 없으면 종료
로지스틱 회귀 (Logistic Regression)
- 주어진 데이터를 바탕으로 분류 문제를 해결하는 방법으로 데이터를 범주로 나눈다.
- 이진 분류나 다중 분류에 적합하며 붓꽃 데이터에서는 여러 품종을 예측하는데 사용된다.
실습
데이터 수집
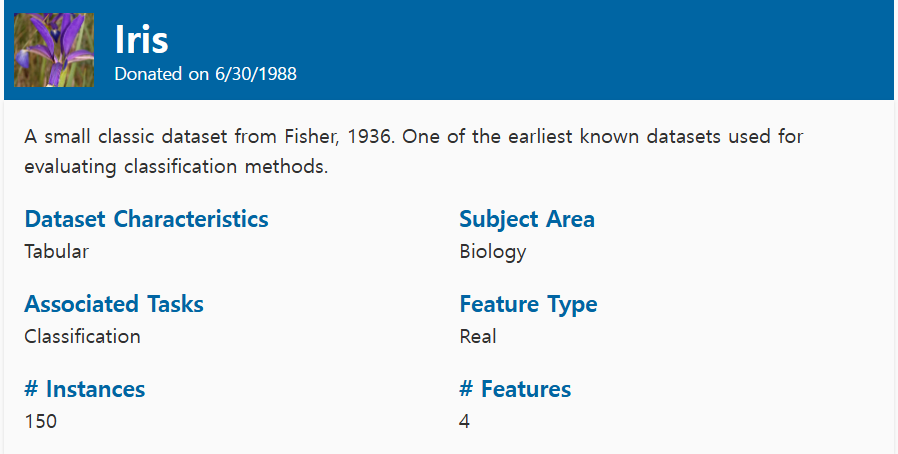
데이터 준비
엑셀에서 헤더 추가
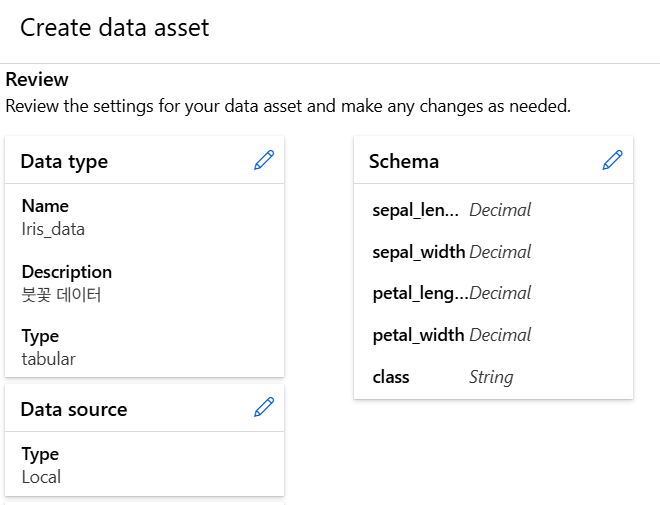
데이터 등록
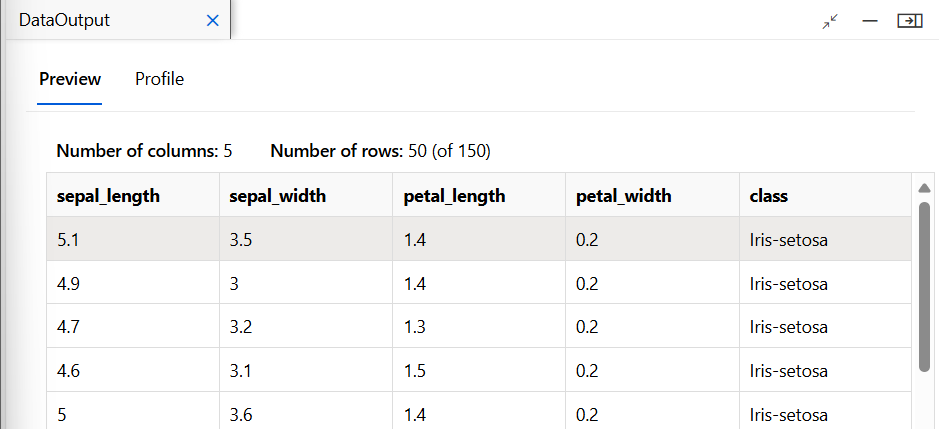
데이터 이해
데이터 전처리
누락값 처리
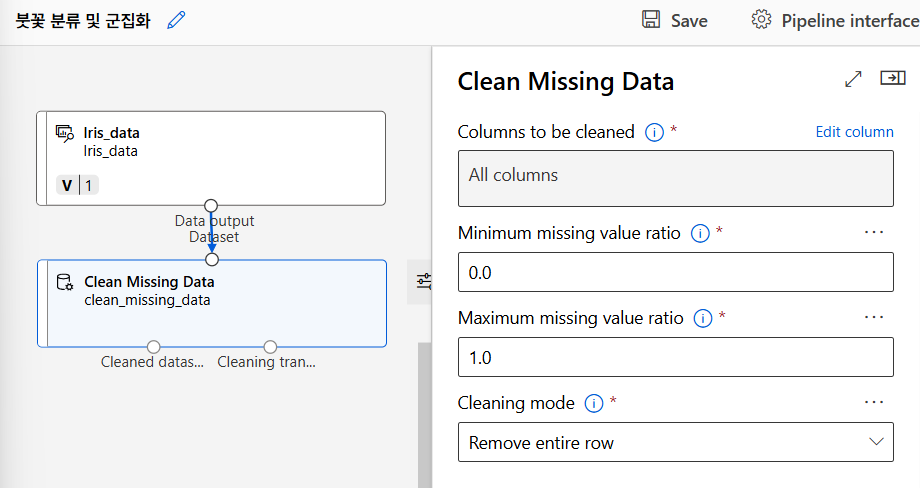
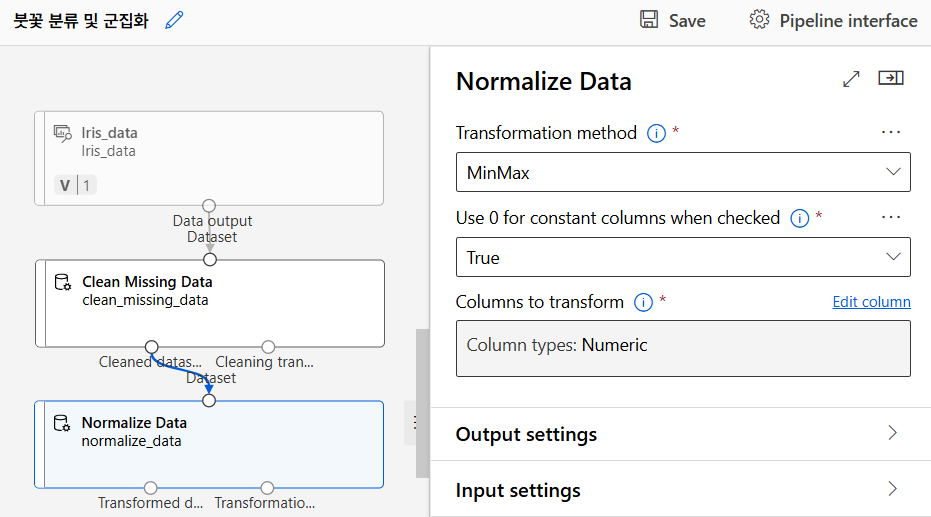
데이터 정규화
모델 학습
데이터 분리
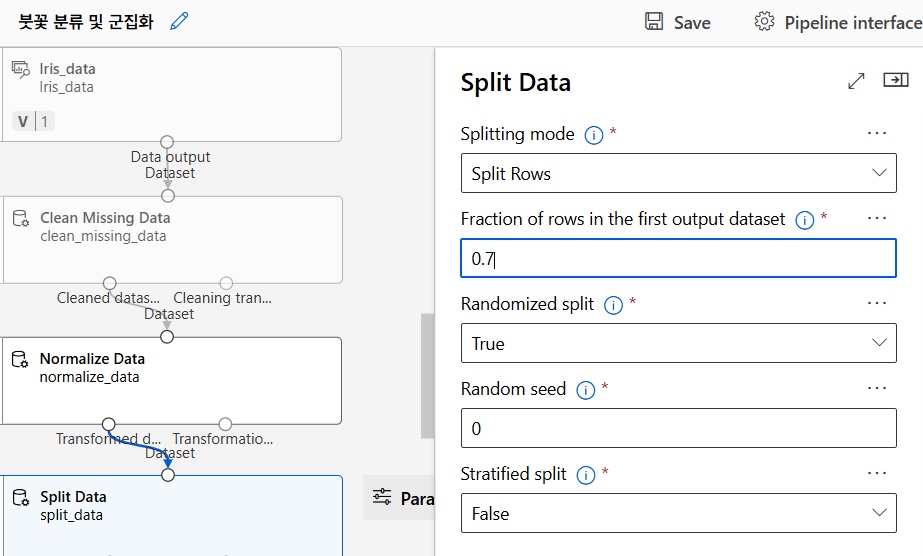
K-means 알고리즘
로지스틱 회귀
train clustering model
train model
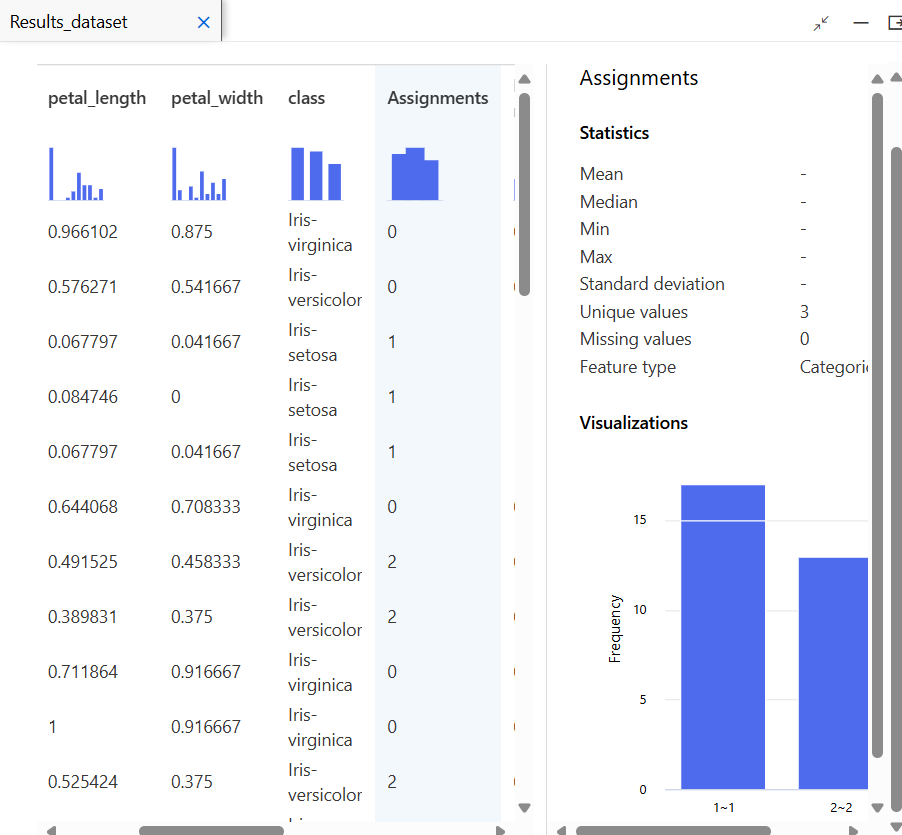
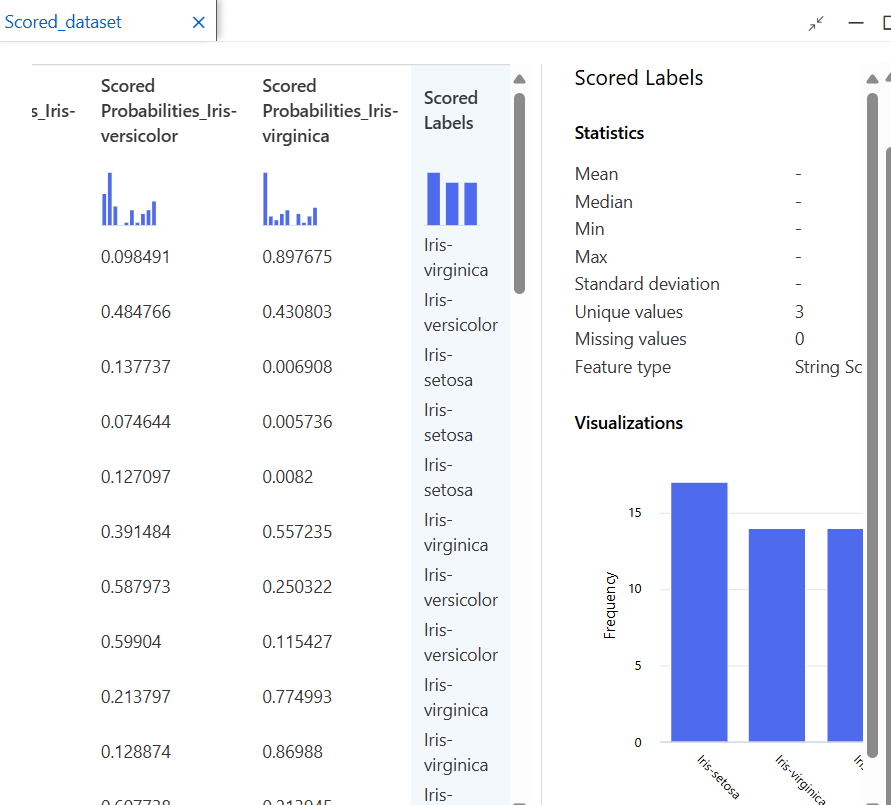
결과 확인
모델 테스트
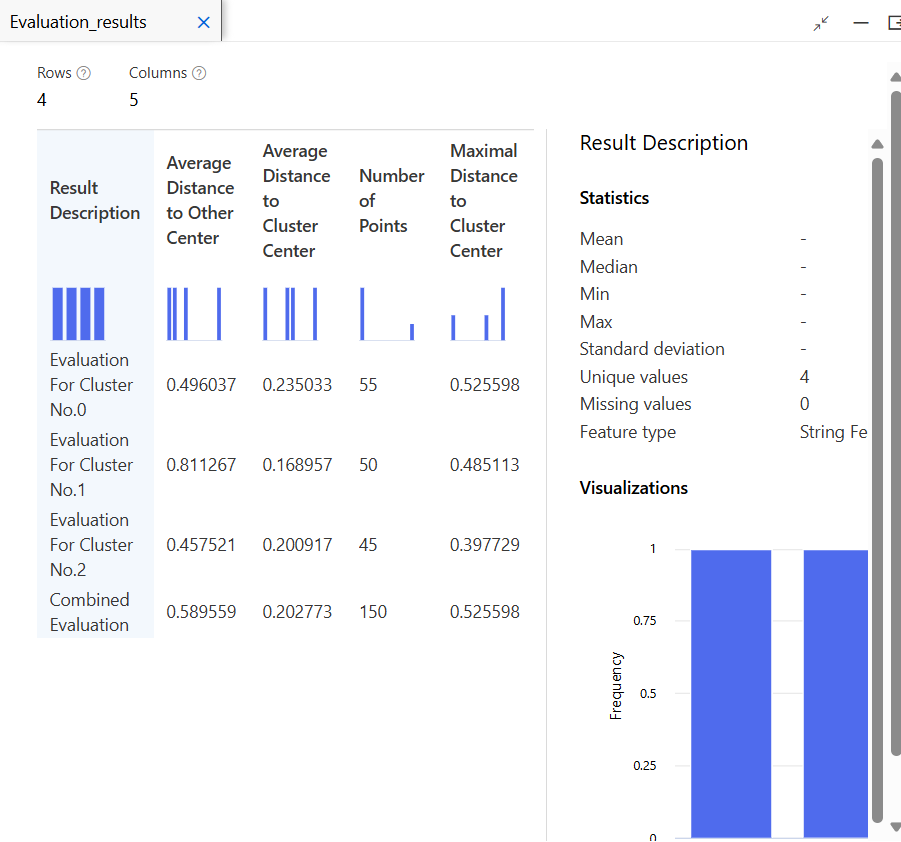
모델 평가
신용 위험 예측 모델
이론
SVM(Support Vector Machine)
SVM은 데이터를 두 개의 그룹(클래스) 으로 나누는 최적의 경계선(초평면) 을 찾는 알고리즘이다. 이를 통해 새로운 데이터가 들어왔을 때 그 데이터가 어느 그룹에 속하는지 예측할 수 있다.
초평면(Hyperplane)
초평면은 데이터를 나누는 경계이다. 2차원에서는 선, 3차원에서는 평면, 그 이상 차원에서는 초평면이라고 부른다. 이 초평면이 두 그룹을 가장 잘 나누도록 최적화된다.
지원 벡터(Support Vector)
지원 벡터는 각 클래스에서 초평면에 가장 가까운 데이터 포인트들이다. 이 지원 벡터들이 초평면을 정의하는데 중요한 역할을 한다.
- 지원 벡터는 초평면을 결정하는데 영향을 주며, 이 데이터들이 SVM에서 가장 중요한 포인트들이다.
마진(Margin)
마진은 두 클래스 간의 거리이다. SVM의 목표는 이 마진을 최대화하여 두 그룹 간의 경계를 명확하게 만드는 것이다.
- 마진이 클수록 모델의 예측 성능이 더 좋아질 가능성이 높다. 마진이 넓다는 것은 두 그룹이 잘 구분된다는 의미이기 때문.
하드 마진 vs. 소프트 마진
- 하드 마진: 모든 데이터를 완벽하게 나누려 할 때 사용한다. 하지만 현실에서는 데이터를 완벽하게 나누기 힘들고, 과적합(overfitting) 문제가 발생할 수 있다.
- 소프트 마진: 일부 데이터는 초평면에 가깝거나 넘어갈 수 있도록 허용하여 실제 데이터의 불완전성을 반영한다. 소프트 마진이 현실적인 데이터에서 더 많이 사용된다.
커널 트릭(Kernel Trick)
SVM은 데이터를 선형적으로 나누기 어려운 경우 커널 트릭을 사용한다. 커널 트릭은 데이터를 고차원 공간으로 변환하여 그 공간에서는 데이터를 선형적으로 나눌 수 있게 도와준다.
- 선형 커널: 데이터가 선형적으로 구분되는 경우에 사용.
- 다항 커널: 비선형 데이터를 다차원으로 확장해 구분.
- RBF(가우시안) 커널: 대부분의 비선형 데이터에 잘 맞음.
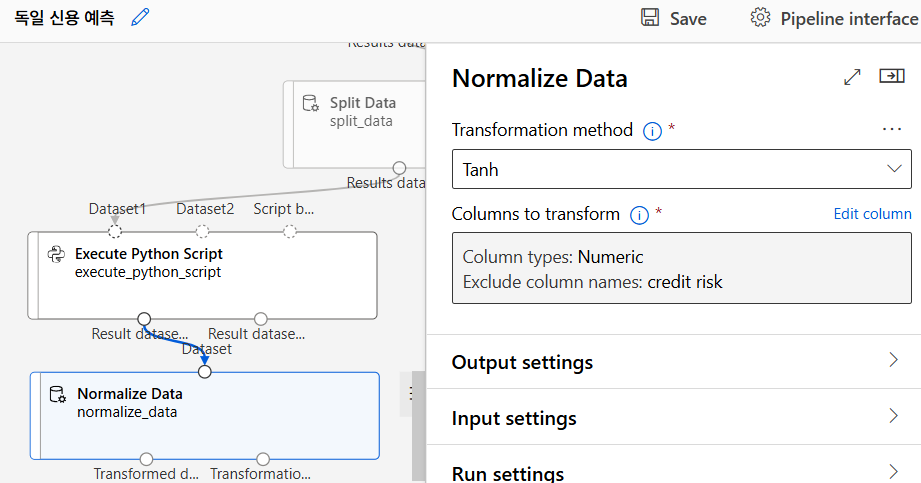
정규화(Normalisation)
SVM은 변수 간의 크기 차이에 민감하기 때문에 데이터를 정규화해 모든 값의 범위를 비슷하게 맞춰야 한다. 정규화하지 않으면 큰 값이 중요한 것으로 간주되어 모델이 왜곡될 수 있다.
Tahn 정규화
Tahn 정규화는 하이퍼볼릭 탄젠트 함수를 이용하여 데이터를 -1에서 1 사이 값으로 변환하는 방식이다. 따라서 양수와 음수 데이터가 모두 있는 경우에도 적합하게 사용할 수 있다.
- 데이터가 중앙값을 기준으로 대칭적이지 않을 때 유용하다. 데이터의 분포를 중앙에 집중되도록 만들어 머신러닝 모델이 더 효율적으로 학습할 수 있다.
- 분포가 비대칭적인 데이터를 다루는데 효과적이다. 데이터가 한쪽으로 치우쳐 있거나 특정 범위에 집중된 경우 Tahn 함수는 그 영향을 줄여준다.
- 이상치(outlier) 의 영향을 상대적으로 적게 받는다. Min-Max 정규화처럼 극단적인 값에 민감하지 않아 이상치로 인해 전체 데이터가 왜곡되는 것을 방지할 수 있다.
실습
데이터 수집 및 이해
UCI 데이터 사용
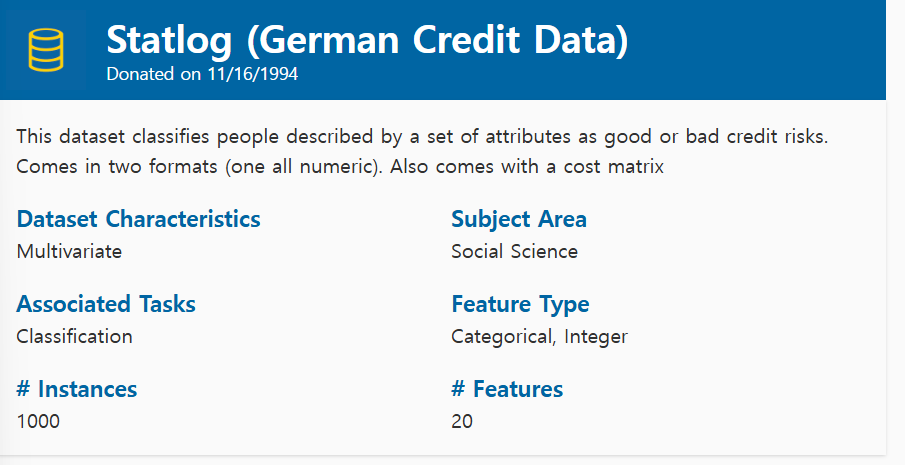
데이터 등록
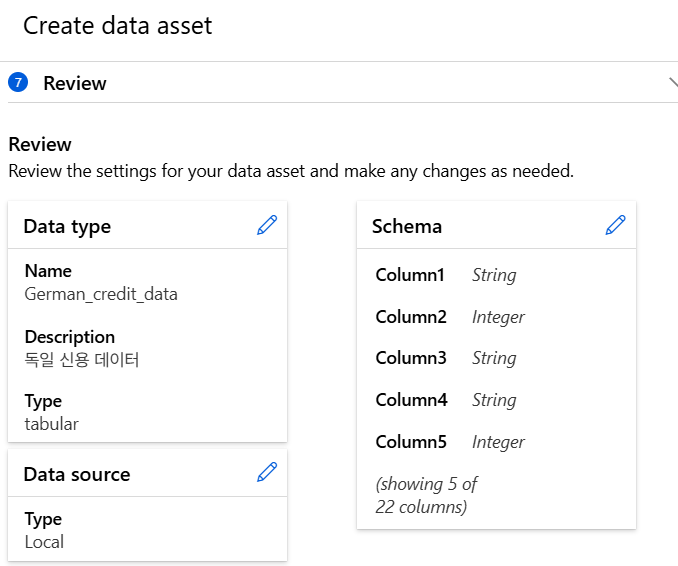
데이터 이해
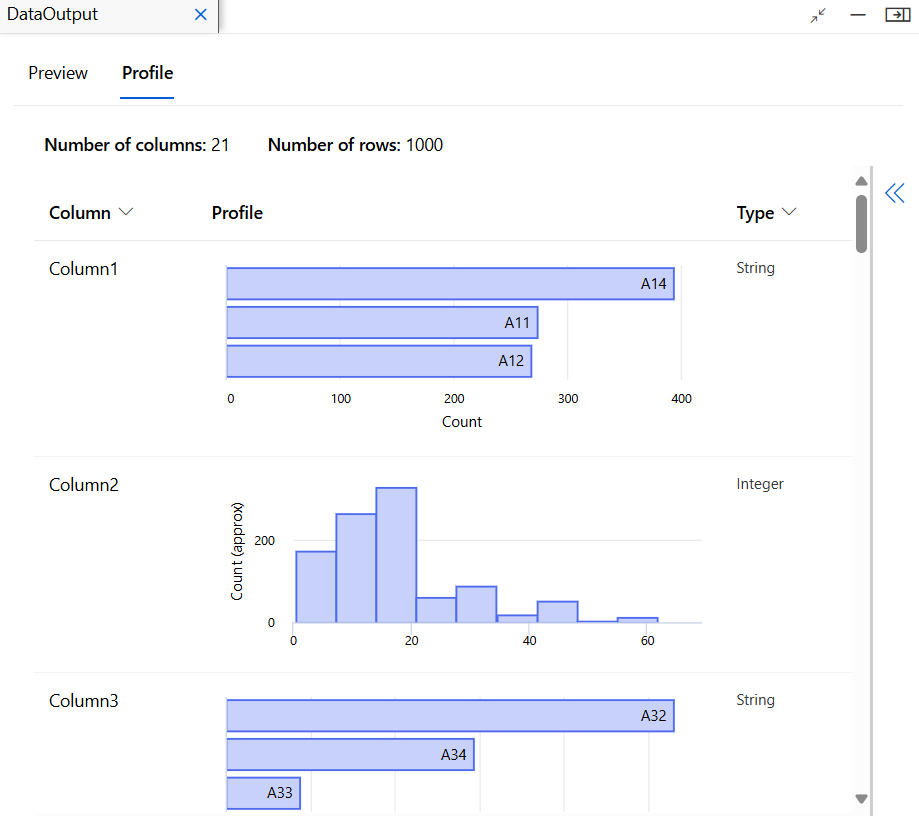
데이터 준비
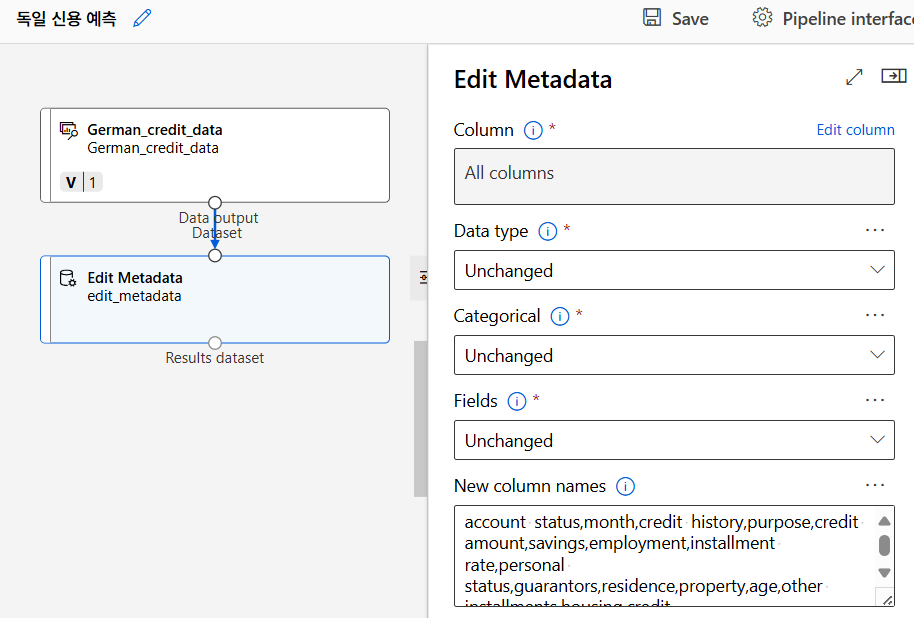
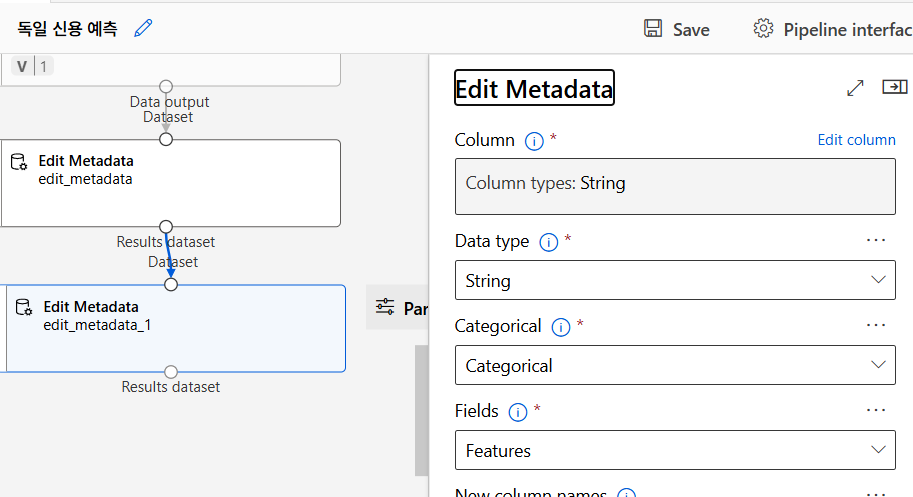
메타데이터 변환 - 컬럼명 부여
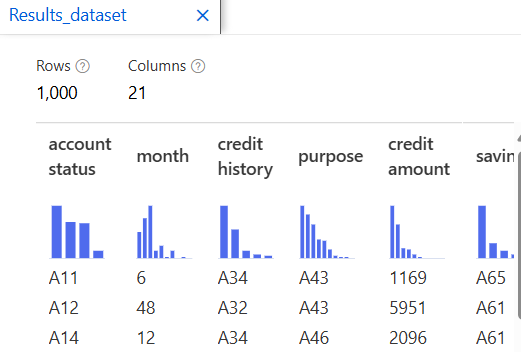
데이터 변환
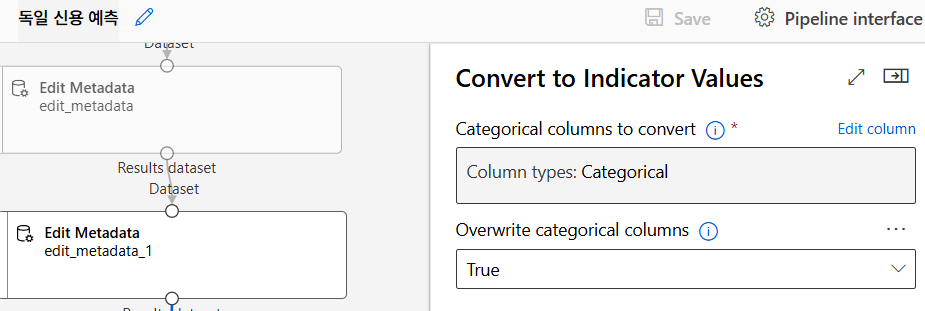
SVM 모델링
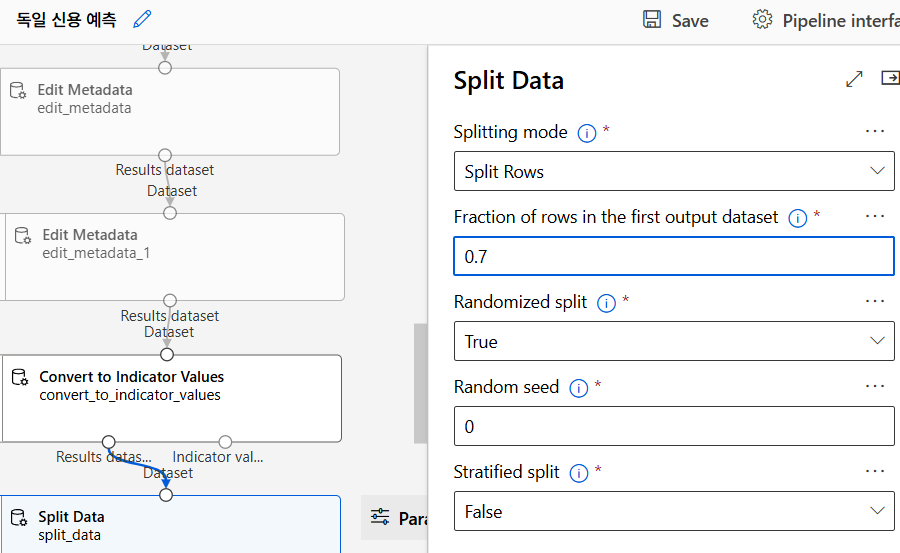
데이터 분리
데이터 복제
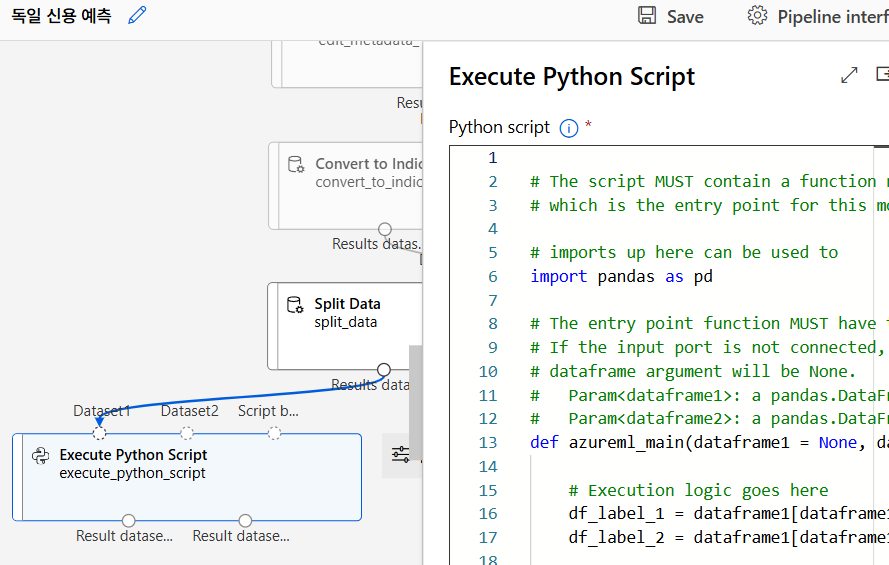
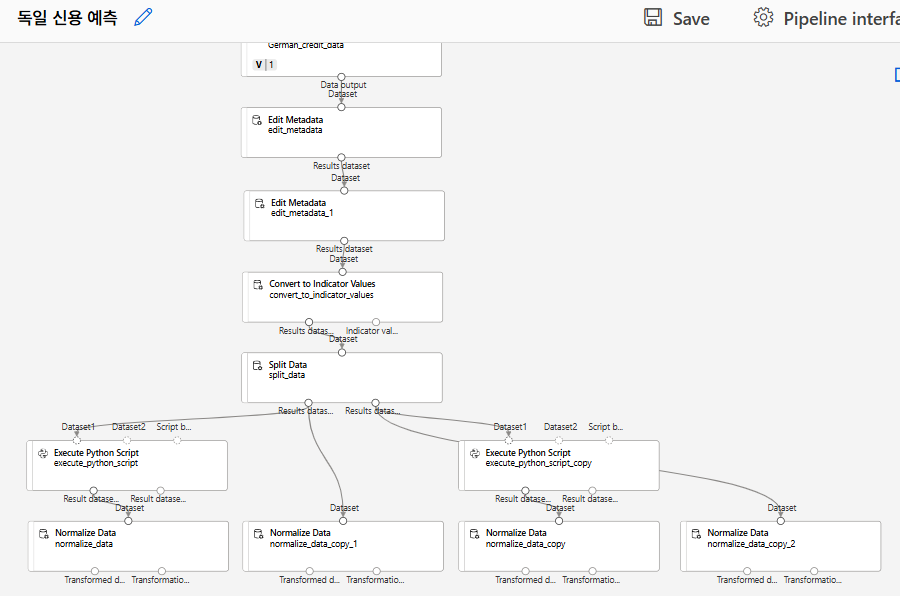
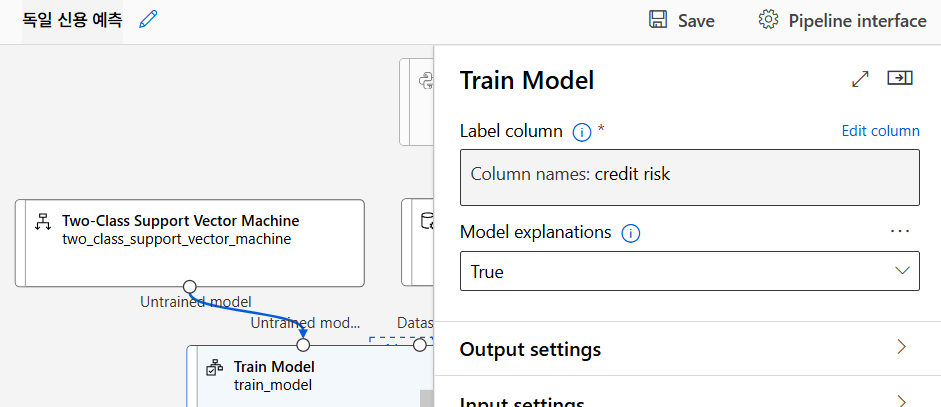
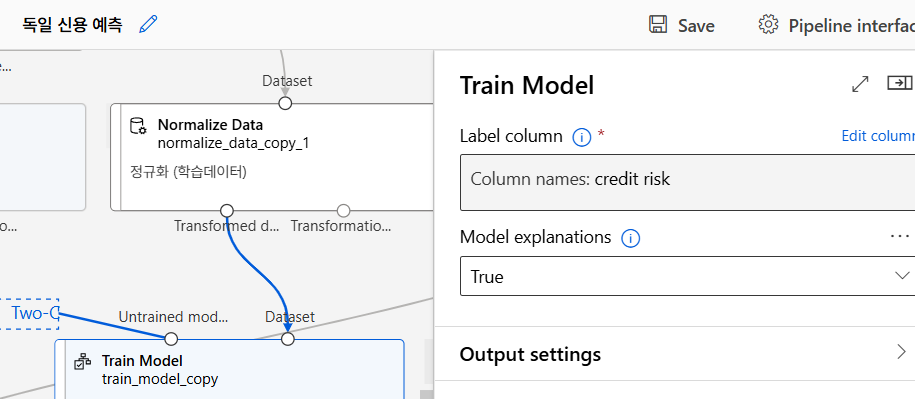
알고리즘 선택 및 모델 학습
ㅎ..
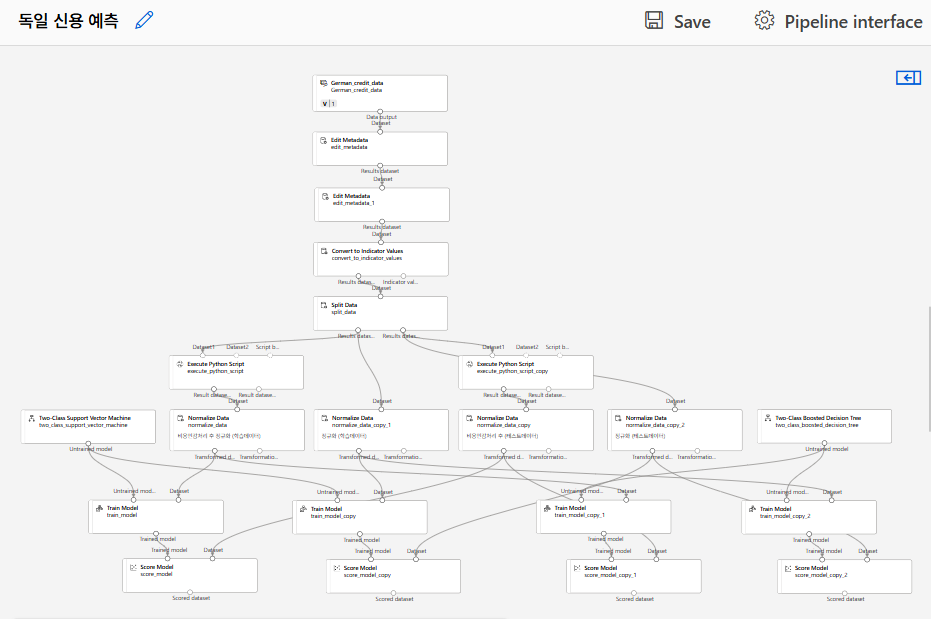
모델 평가
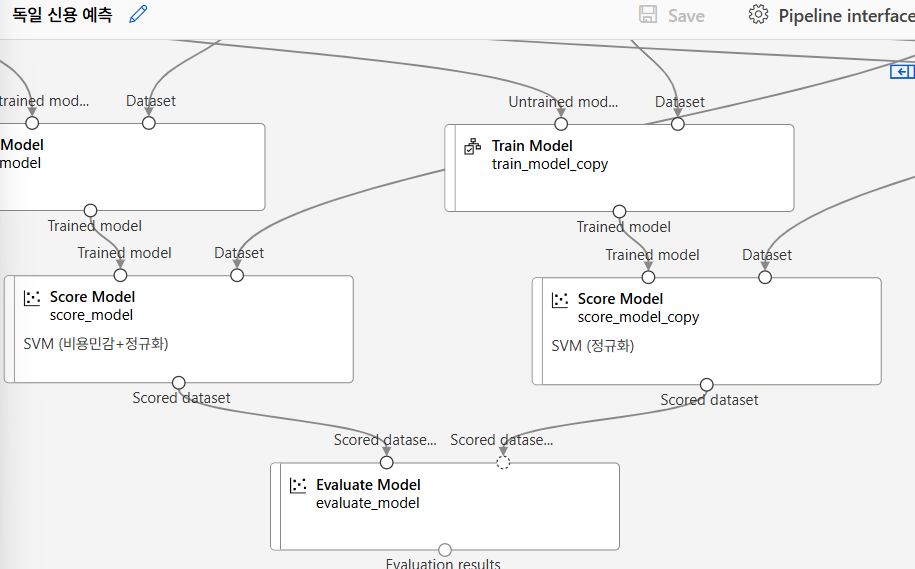
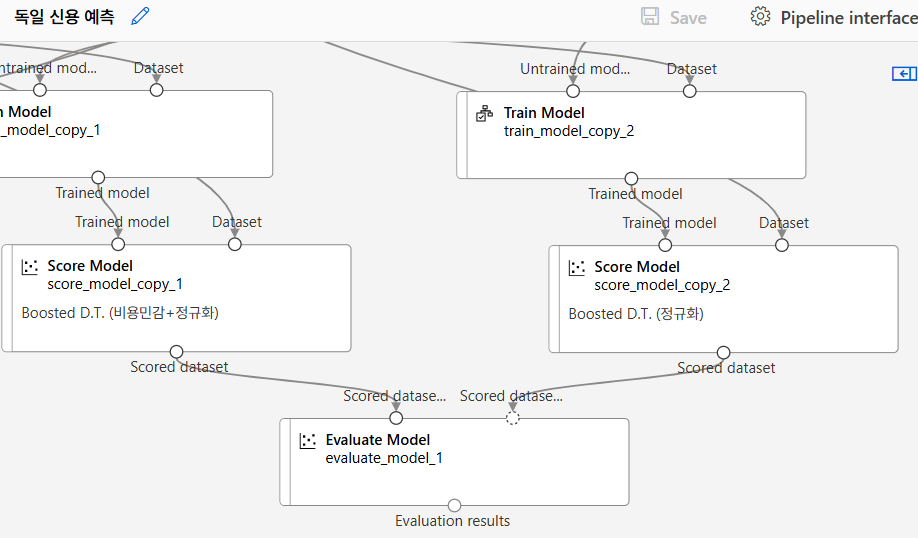
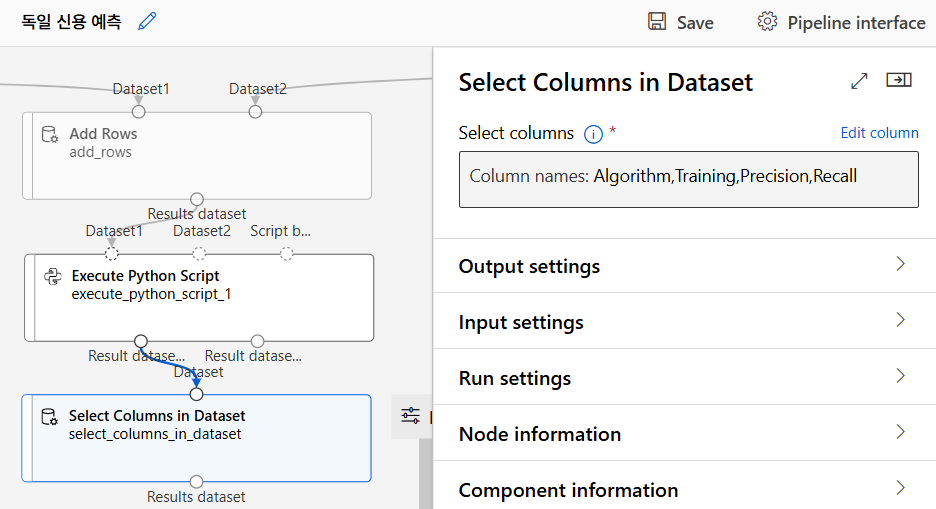
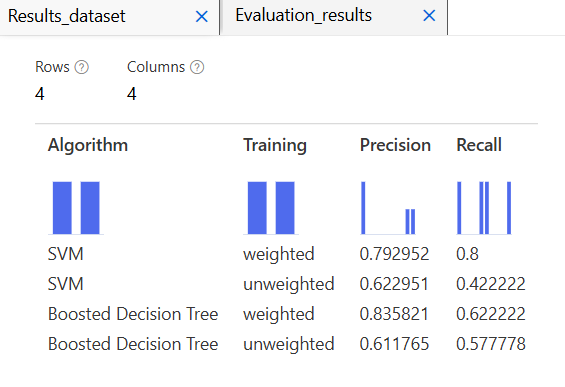
취합
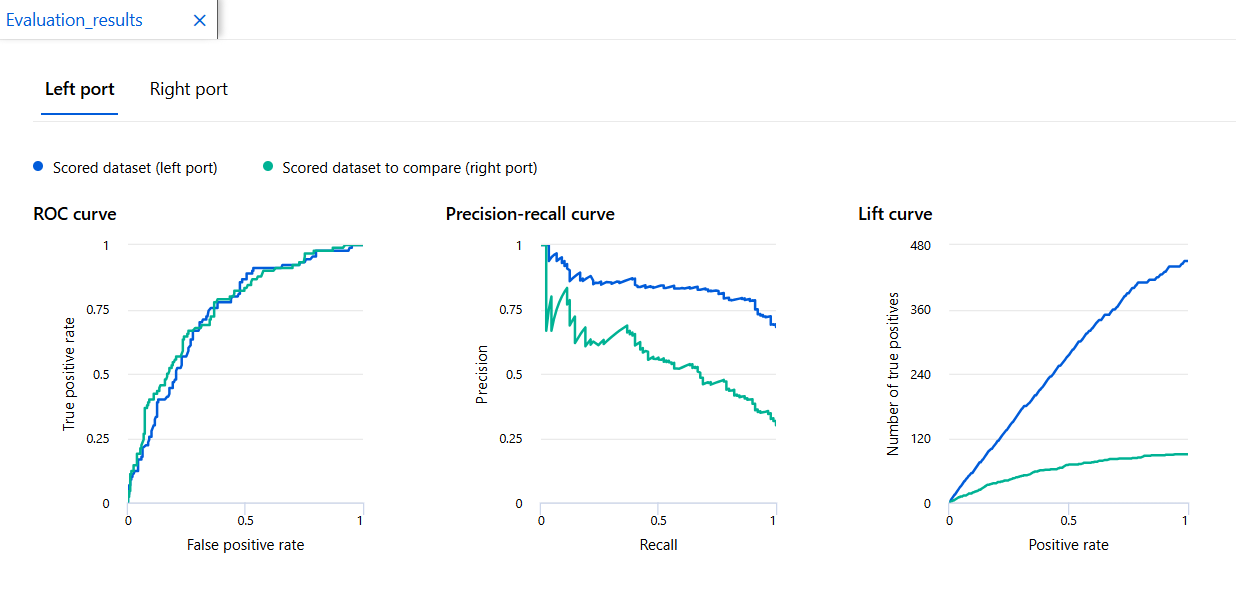
SVM 모델
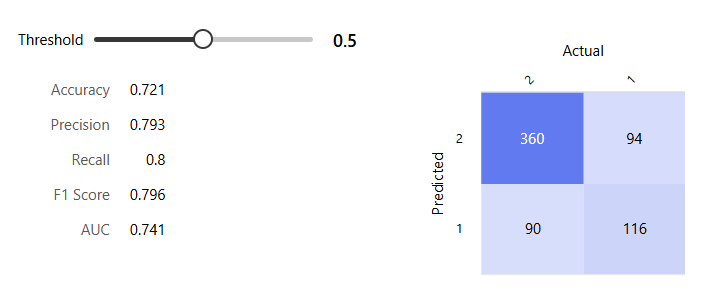
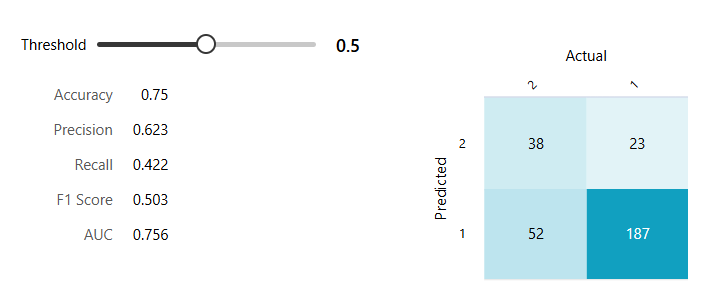
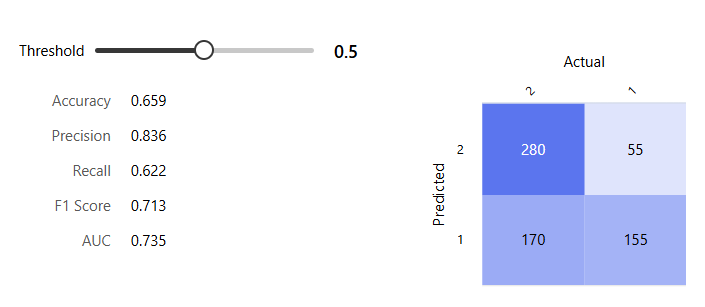
Boosted D.T.
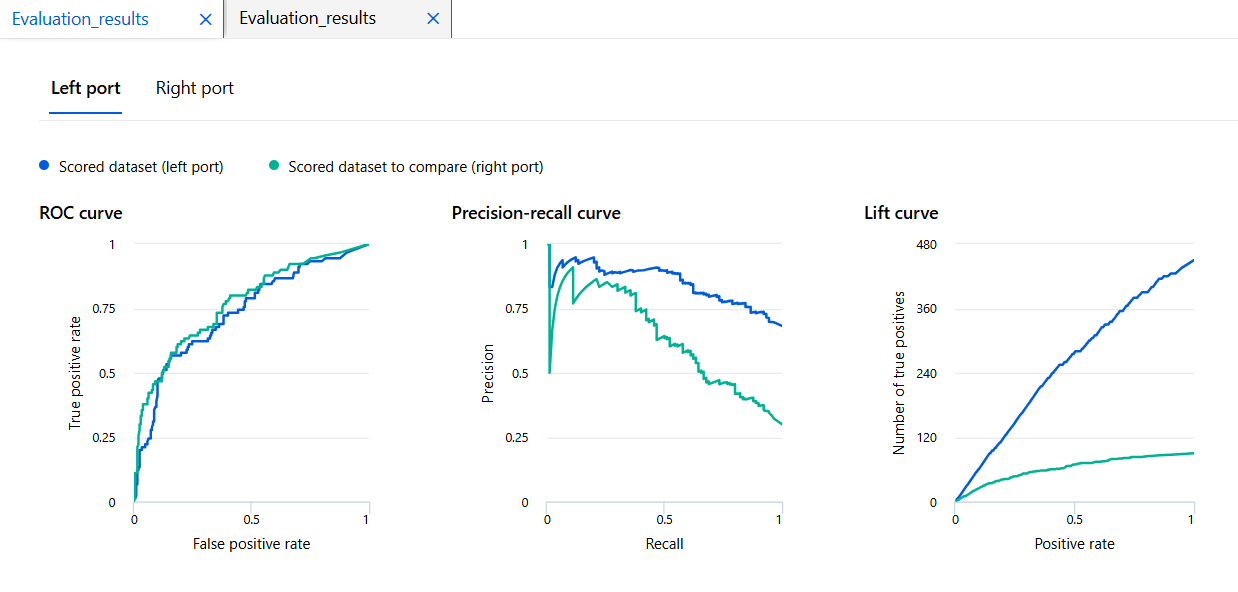
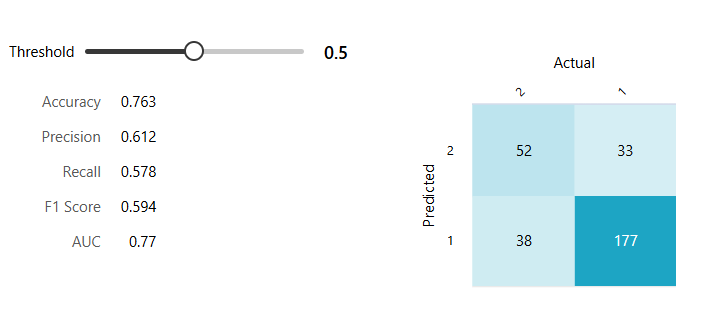
결과
개인 수입 예측 모델
이론
Filter
Filter는 모델을 학습하기 전에 특성을 선택하는 전처리 기법이다. 통계적 방법을 사용하여 특성과 타깃 값 간 관련성을 계산하고, 그 결과에 따라 특성을 선택한다.
- 피어슨 상관분석: 연속형 변수들 사이의 선형 상관관계를 측정하여 관련성이 높은 특성만 선택한다.
- 카이제곱 검정(Chi-Sqaure Test): 범주형 데이터의 특성과 타깃 값 간의 독립성을 검정하는 방법이다. 예측에 큰 영향을 미치는 특성을 선택하기 위해 카이제곱 값을 사용한다.
카이제곱 검정
- 적합도 검정(Goodness of fit test): 하나의 범주형 변수의 관찰된 빈도가 기대값과 일치하는지 확인.
- 독립성 검정(Test of independence): 두 범주형 변수 사이의 독립성을 검증.
- 동질성 검정(TEst of homogeneity): 여러 표본이 동일한 분포를 따르는지 확인.
Wrapper
Wrapper는 모델을 학습하며 특성 선택을 반복하는 방식이다. 다양한 특성 조합을 사용하여 모델을 학습한 후 그 성능을 평가하여 최적의 특성 조합을 선택한다.
- Forward Selection: 아무 특성도 사용하지 않고 시작해서 모델 성능을 향상시키는 특성을 하나씩 추가해 나가는 방식이다.
- Backward Elimination: 모든 특성을 사용하여 시작한 후 성능에 기여하지 않는 특성을 하나씩 제거해나간다.
- 이 방법은 모델 성능을 직접 평가하면서 특성 선택을 하기 때문에 정확도는 높지만 계산 비용이 많이 든다.
Embedded
Embedded는 모델 학습 과정에서 특성 선택을 동시에 수행하는 방법이다. Filter나 Wrapper에 비해 효율적이고 빠르다.
- LASSO (Least Absolute Shrinkage and Selection Operator): 불필요한 특성의 가중치를 0으로 만들어 자동으로 특성 선택을 수행한다.
- Ridge 회귀: 과적합을 방지하기 위해 모든 특성의 가중치를 조금씩 줄이는 방식으로 중요한 특성만 남길 수 있다.
특성 선택의 중요성
특성 선택은 단순히 모델 성능을 높이는 데 그치지 않고 모델의 복잡성을 줄여 해석 가능성을 높이는 데 중요한 역할을 한다. 중요한 특성만을 사용하여 모델을 학습하면 연산 비용이 줄어들고 모델 이해가 쉬워진다.
- Grabage in, garbage out: 쓸모없는 데이터를 사용하면 잘못된 결과가 나오는 것을 방지하기 위해 예측에 중요하지 않은 특성을 제거해야 한다.
- 비슷한 특성 중복 제거: 서로 비슷한 정보만 제공하는 특성들이 여러 개 있으면 그 중 하나만 사용하여 모델의 성능을 향상시킬 수 있다.
실습
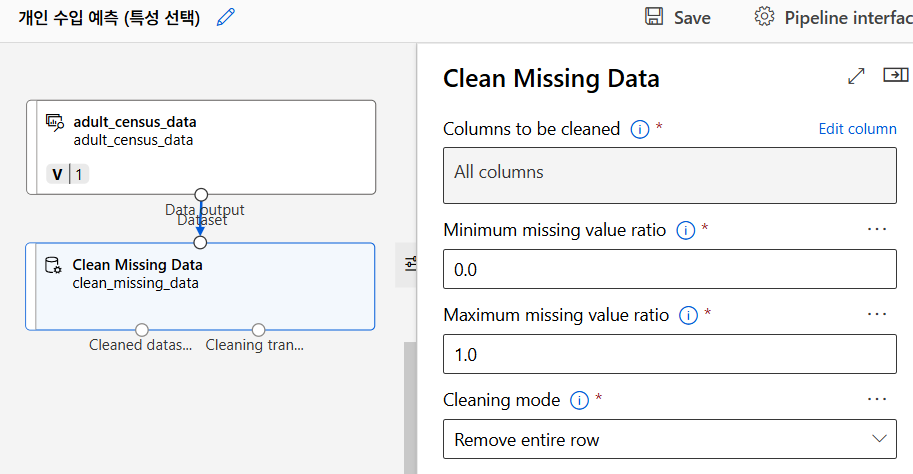
누락값 처리
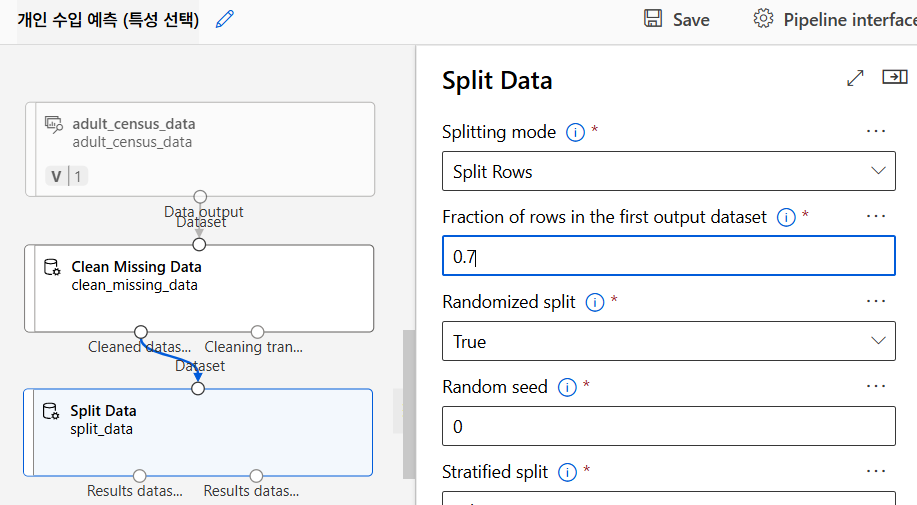
데이터 분리
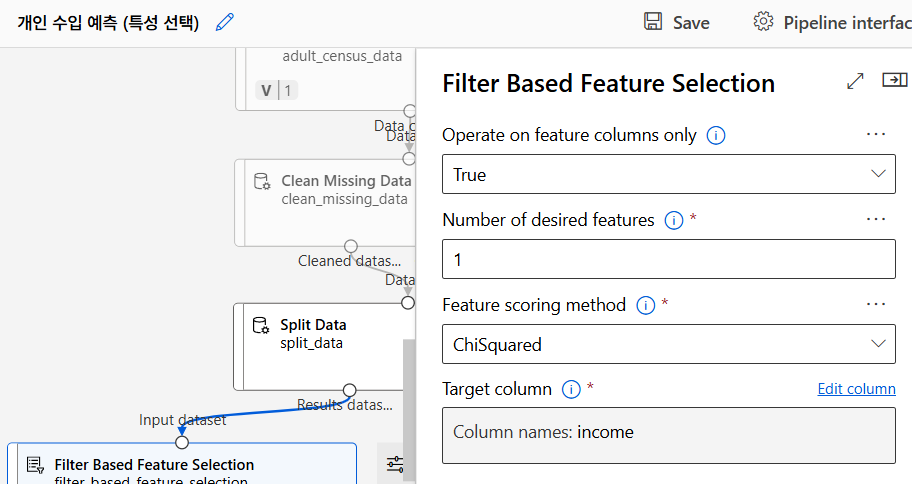
원래는 이전에 데이터 정리 단계가 있어야 하지만 여기서는 특성 선택이 중요한 포인트이므로 생략
Filter-based Feature Selection
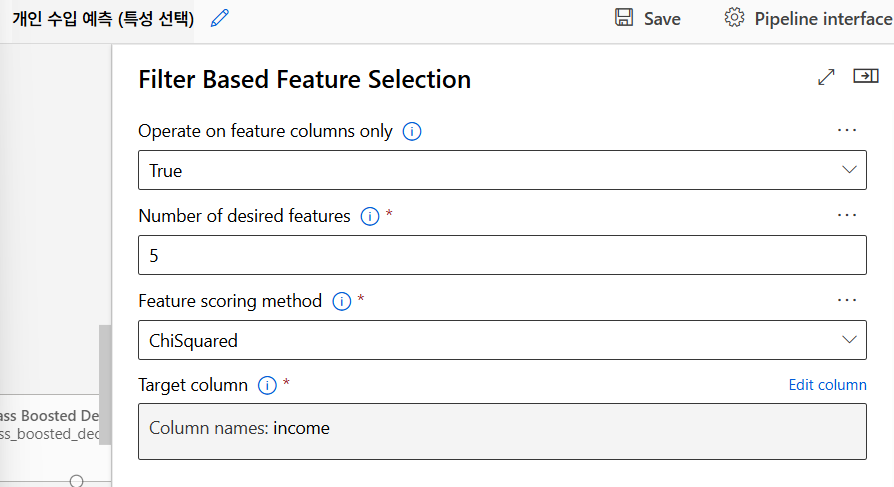
모델링 알고리즘 선택
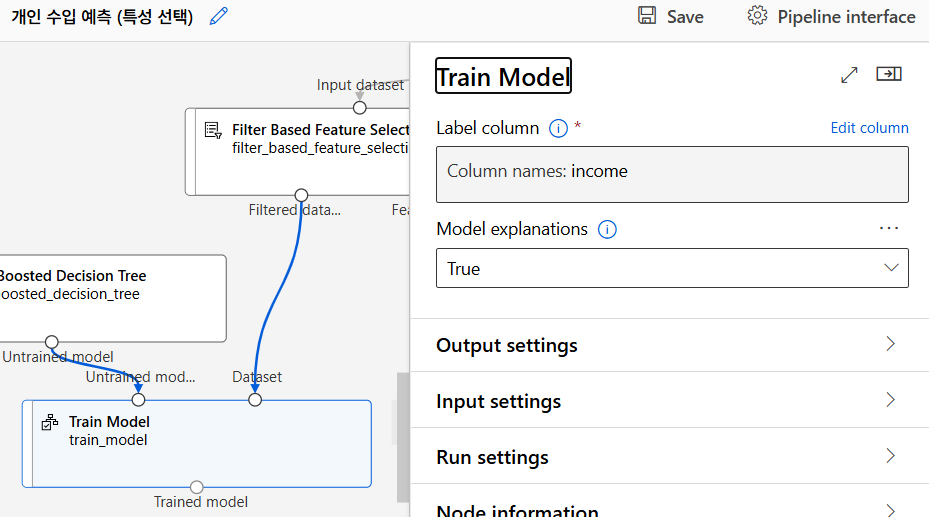
모델 학습
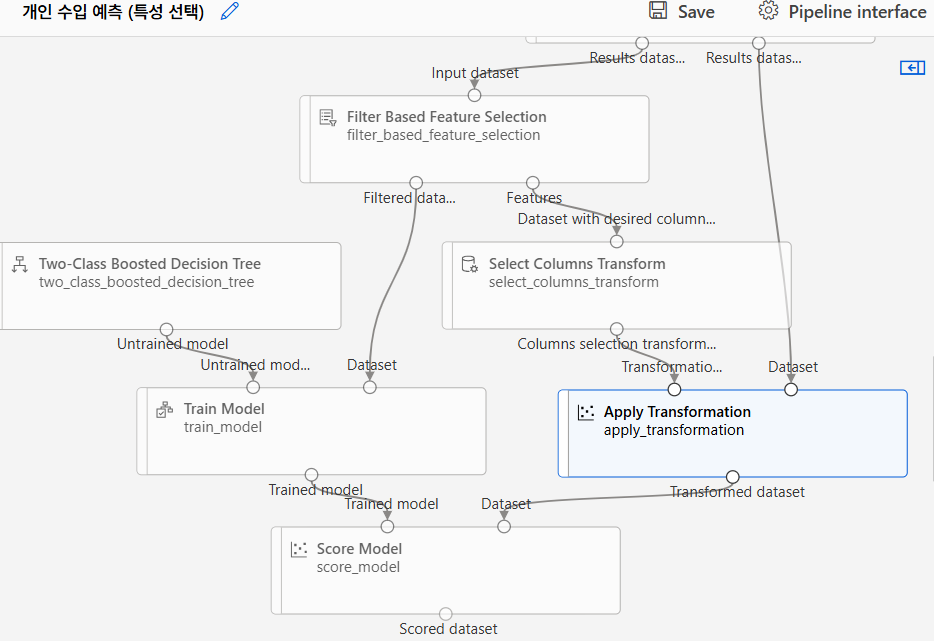
모델 테스트
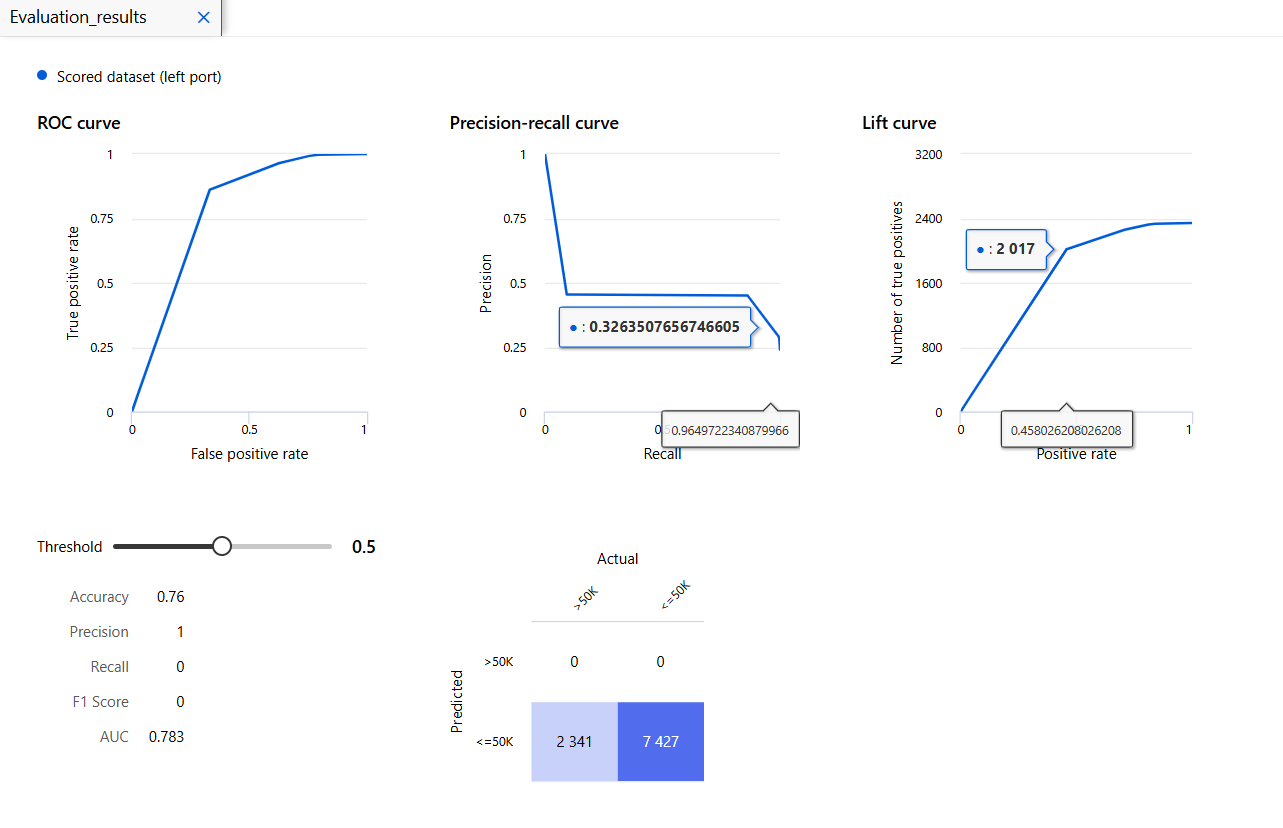
모델 평가
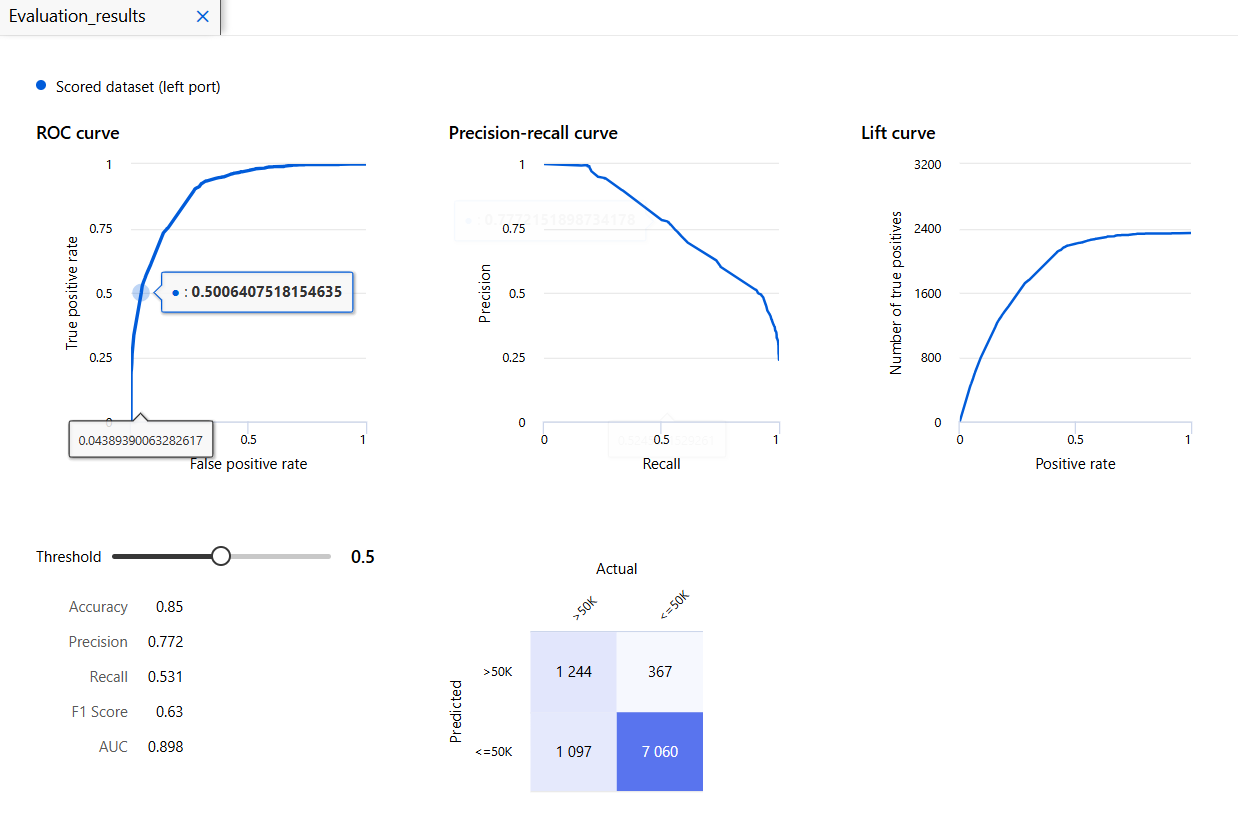
읭 뭔가 이상함;;
다행..
개인 수입 예측 모델 (카이제곱)
개인 수입 예측 모델 (교차검증)
대출 자격 예측 모델
CRM 고객 이탈 예측 모델
Personal Insight
개인 실습이 두개나 있어서 정리할 시간이 필요.
