스무번째 수업 | 프로야구 선수능력 측정 모델 | 개인 수입 예측 모델 | 분류모델 | 랜덤포레스트 | 자동차 가격 예측 모델 | 선형회귀 | 펭귄 데이터 군집화 모델
Microsoft Korea 5th AI School
강명호 강사님
프로야구 선수능력 측정 모델
주성분 분석
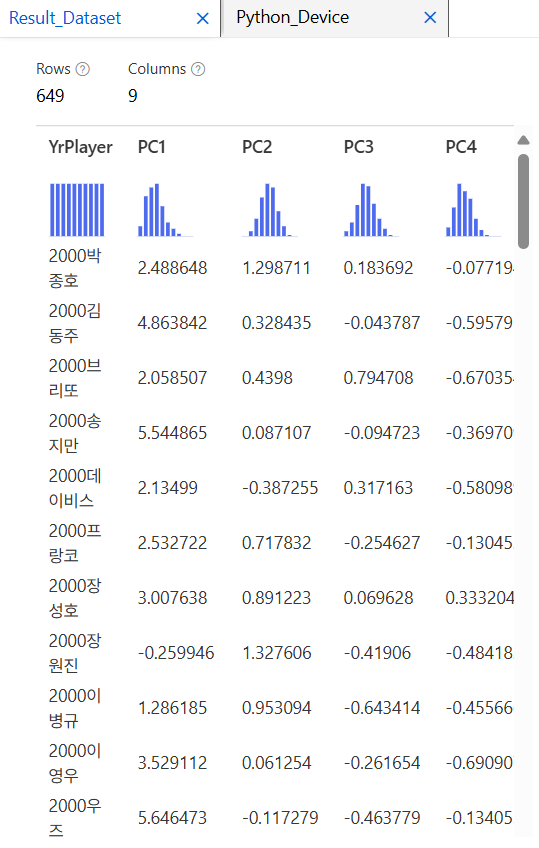
K-means 군집화
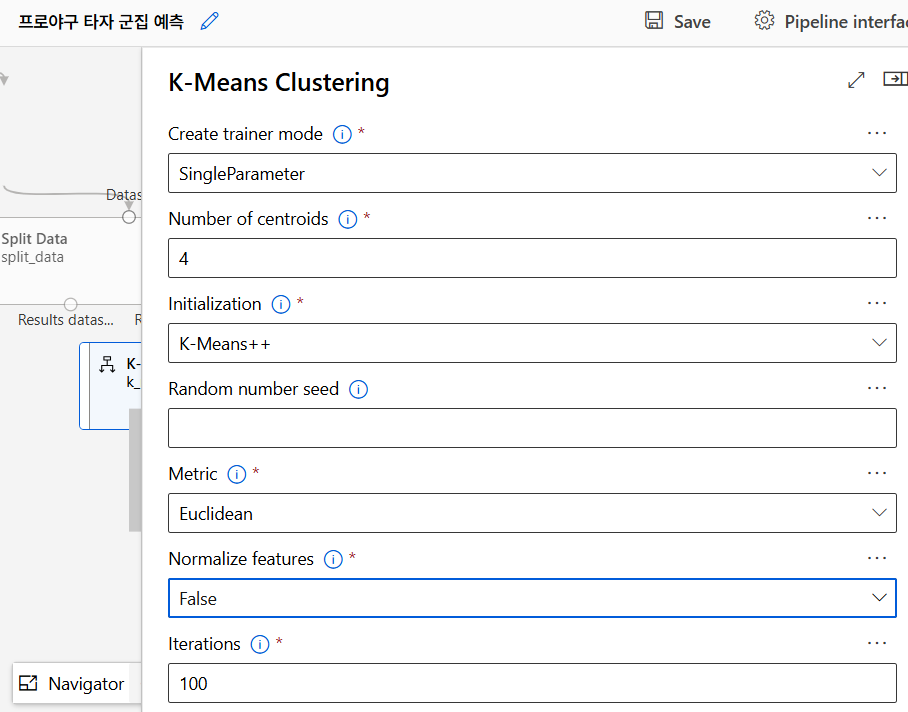
K-means 군집화 알고리즘으로 선수들을 여러 그룹으로 나눈다. 각 군집마다 유사한 선수들이 모여 있고, 중심점(centroid)은 군집의 중심을 나타낸다. 초기 중심점은 무자위로 설정되고, 반복적으로 업데이트된다.
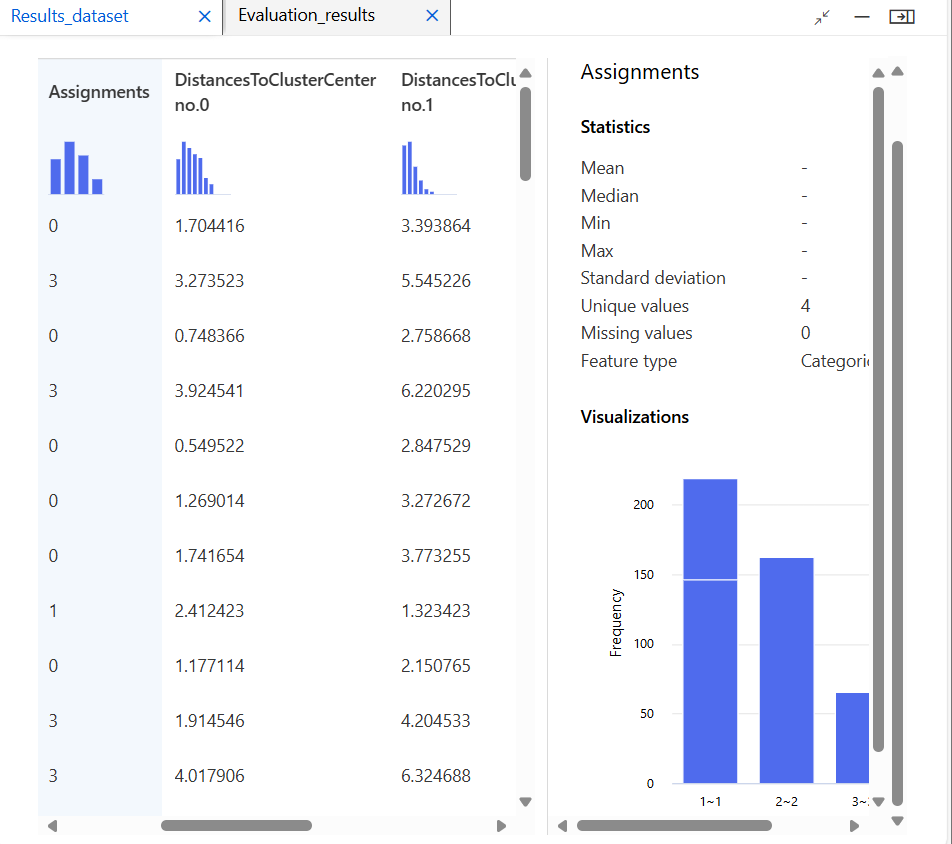
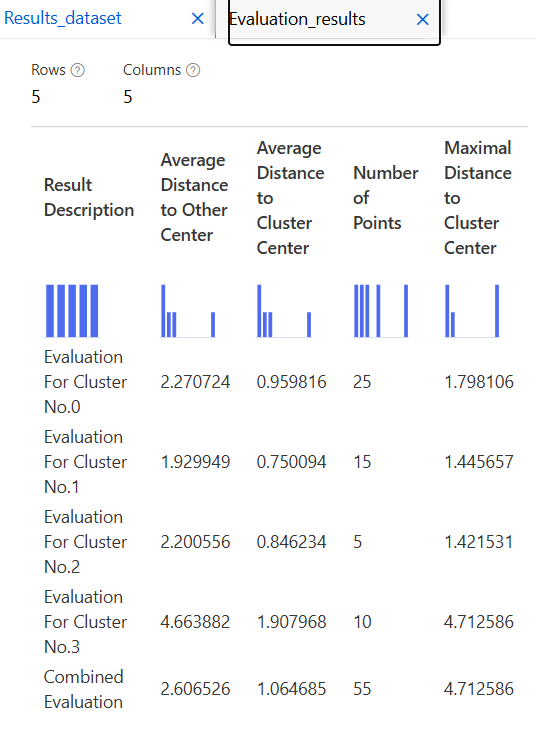
모델 평가
개인 수입 예측 모델
데이터 수집 및 준비
Kaggle에서 Adult Census Income 데이터 검색 후, 데이터 다운로드
데이터 이해 및 탐색
데이터 업로드
데이터 처리
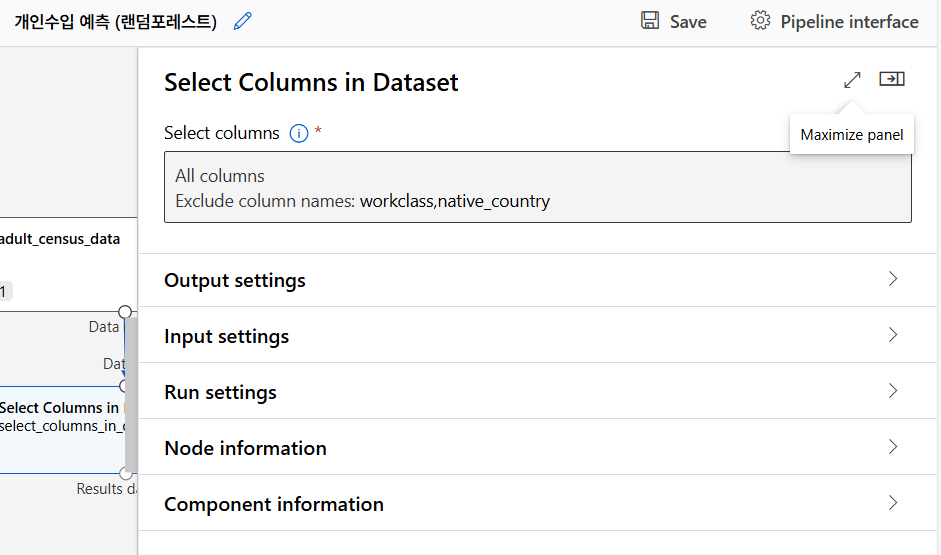
불필요한 컬럼 제거
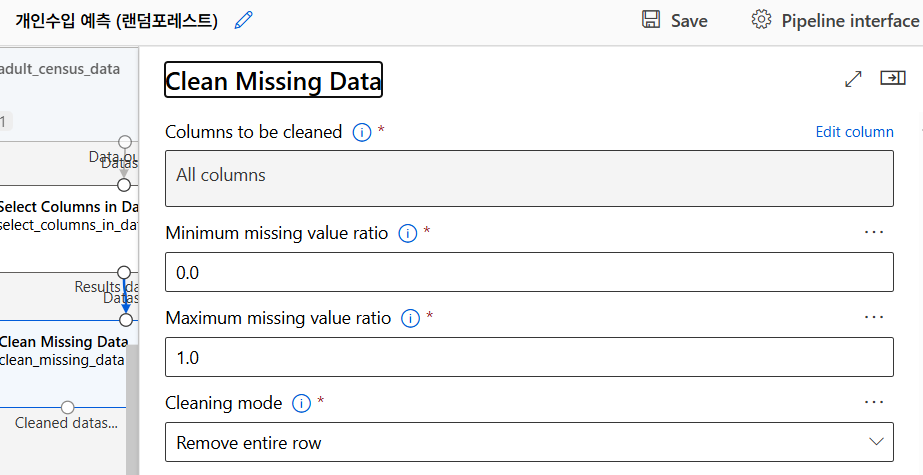
누락된 데이터 처리
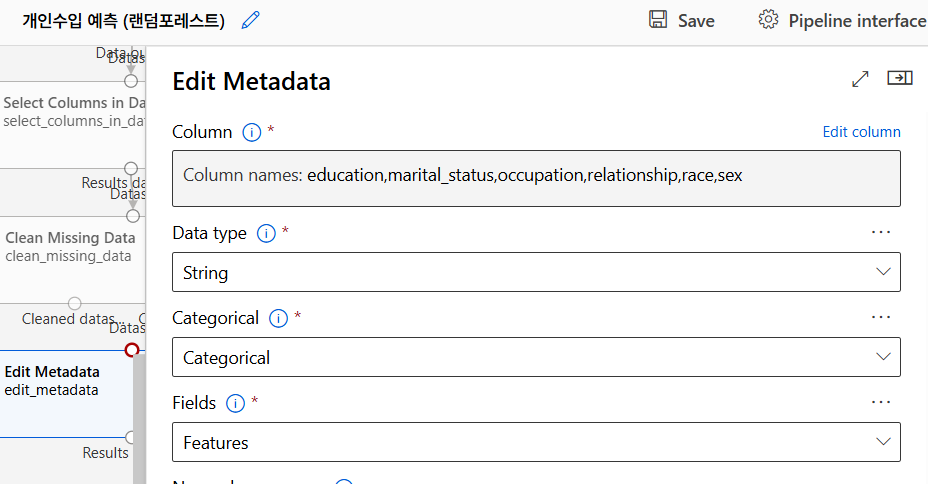
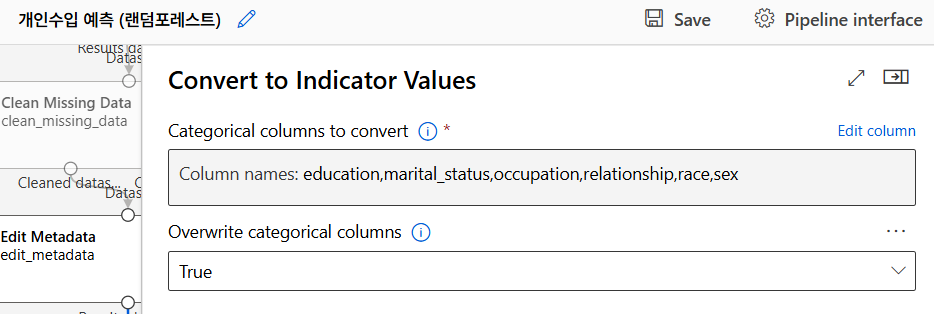
범주형 데이터는 숫자형 데이터로 변환하여 머신러닝 모델에서 사용할 수 있도록 함.
데이터 분리
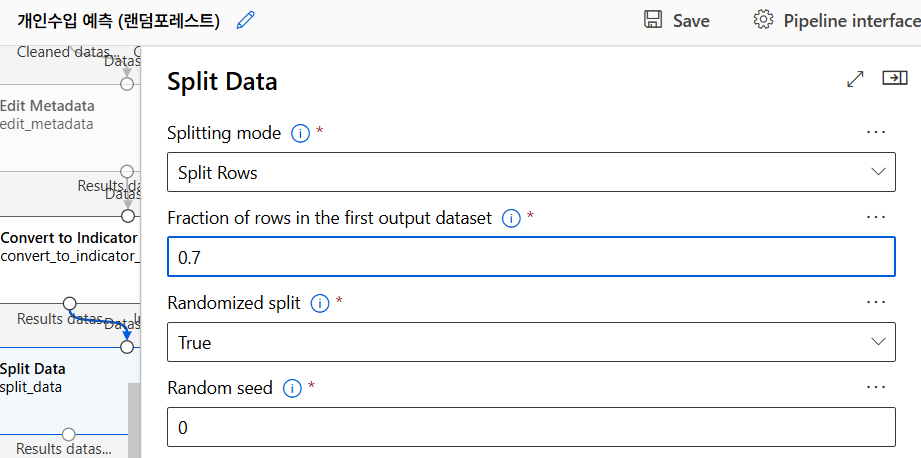
학습용 70, 테스트용 30
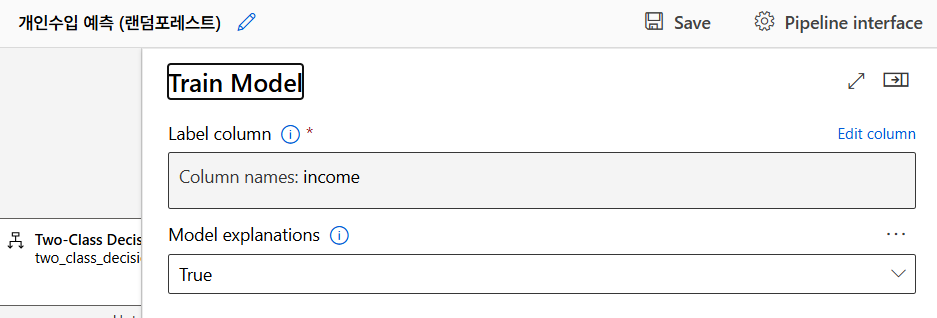
모델 훈련 (Random Forest)
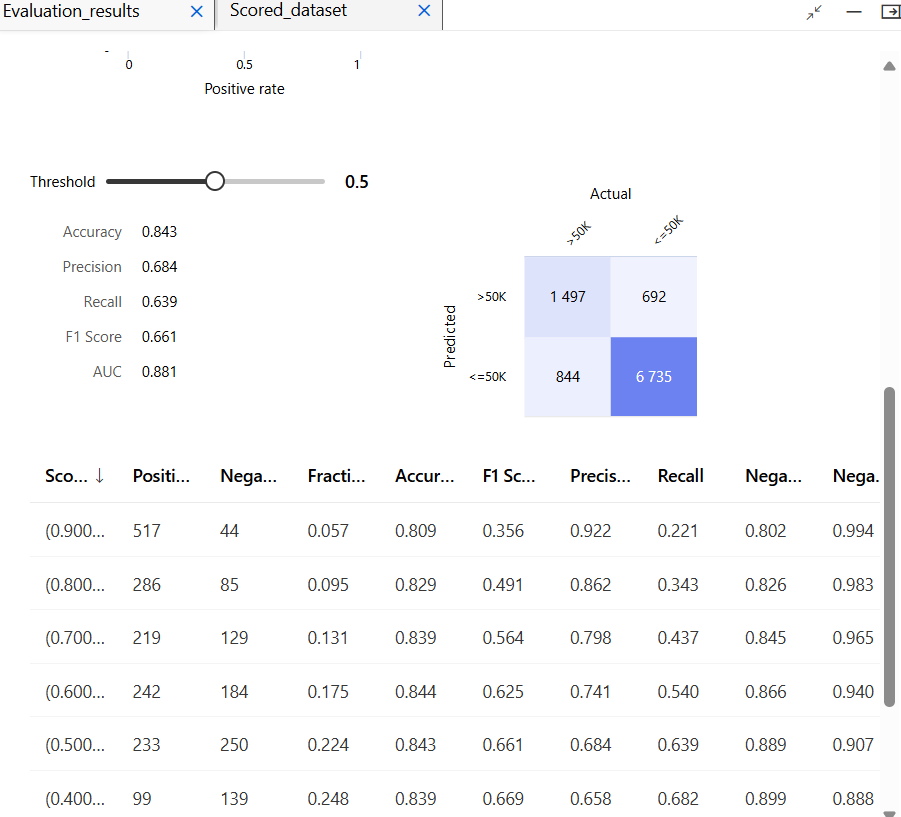
모델 테스트
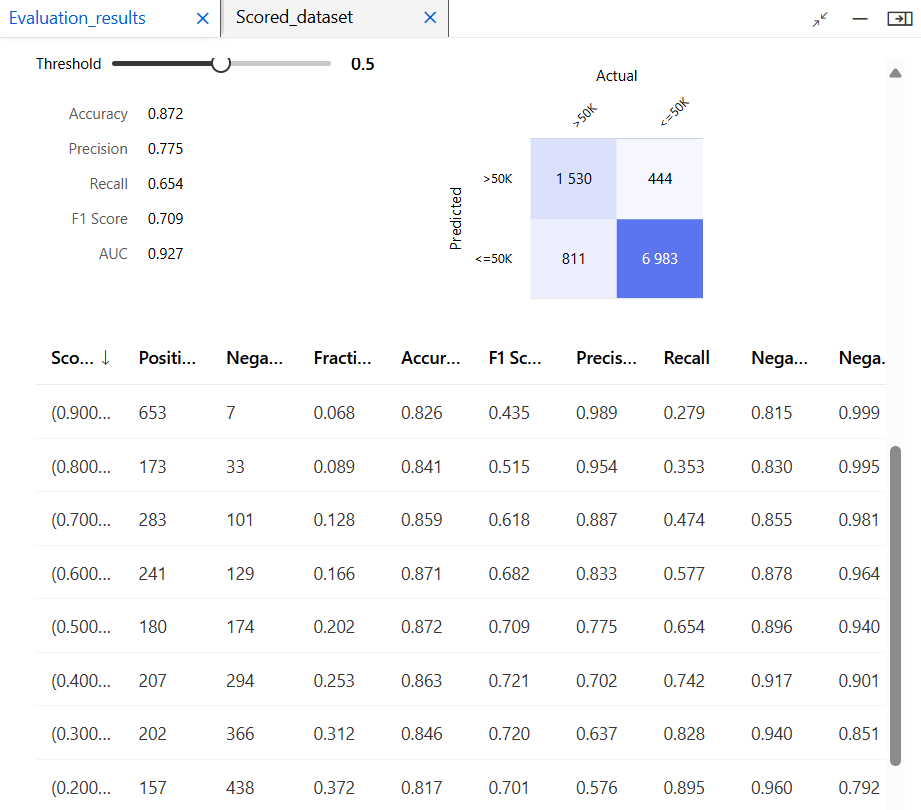
모델 평가
자동차 가격 예측 모델
회귀 알고리즘
회귀란 주어진 데이터를 이용해 종속 변수를 예측하는 과정이다. 선형 회귀는 데이터를 가장 잘 설명하는 직선을 찾는 모델이다.
단순 선형 회귀
단순 선형 회귀는 하나의 독립 변수로 종속 변수를 예측하는 것이다. 예측된 직선이 데이터에 얼마나 잘 맞는지 보여준다.
오차
오차는 모델이 예측한 값과 실제 값 사이의 차이이다. 이 오차가 얼마나 작은지를 통해 모델의 성능을 평가한다.
MAE & MSE
MAE는 오차의 절대값을 평균한 값이고, MSE는 오차의 제곱을 평균한 값이다. 둘 다 오차가 작을수록 모델이 더 정확함을 의미한다.
다중 선형 회귀
다중 선형 회귀는 여러 독립 변수를 사용해 종속 변수를 예측한다.
자동차 가격은 연식, 마일리지, 연료 종류 등 여러 요소에 의해 결정된다.
데이터 수집 및 전처리
더 자세하게 과정을 보여주고 싶지만 혹여 강의자료 유출이 될까 하여 중간중간 생략(귀찮은 거 아님. 아무튼 아님)
모델 학습 및 평가
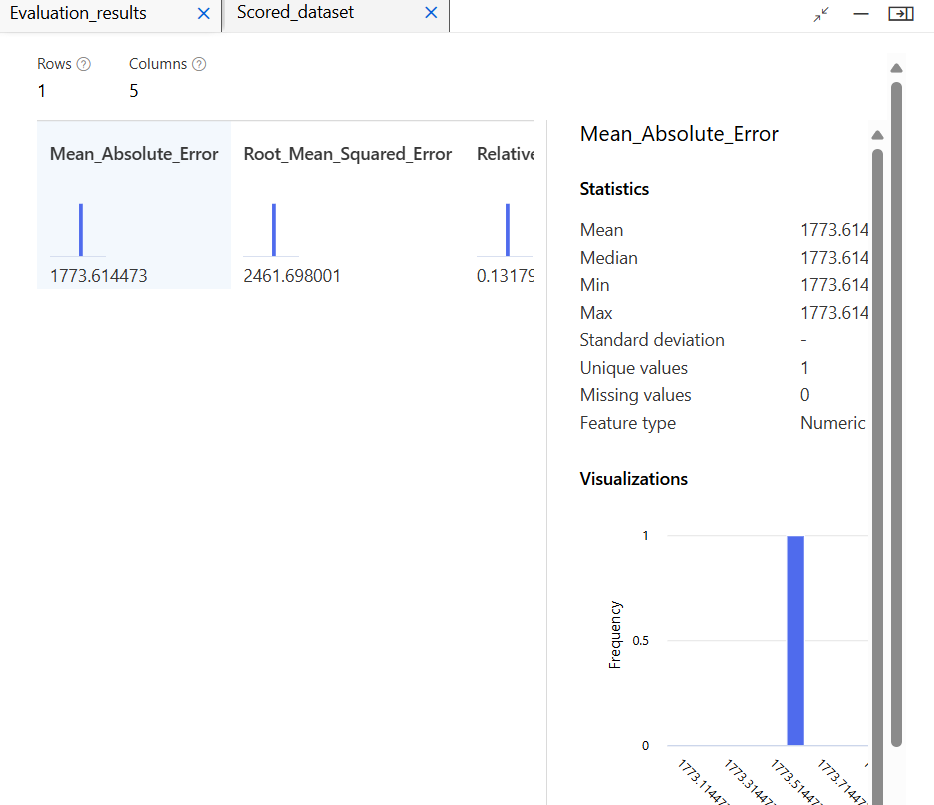
평가 지표
추가 실습
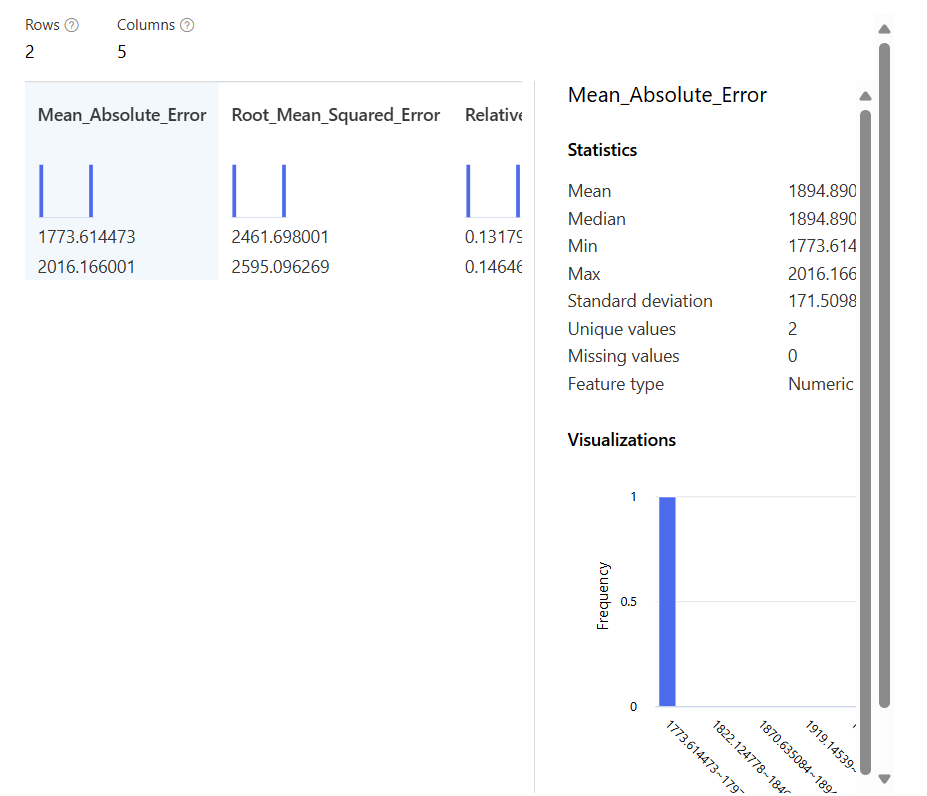
Linear Regression에서 하나는 Ordinary Least Squares로, 하나는 Online Gradient Descent로 진행
펭귄 데이터 군집화 모델
군집화(Clustering)
데이터를 비슷한 특징끼리 묶는 과정
K-means 알고리즘
가장 흔한 군집화 방법 중 하나로 데이터를 미리 정한 숫자만큼 그룹으로 나누는 방법
- 처음에 임의의 중심점을 설정한 후 각 펭귄 데이터를 가장 가까운 중심점에 할당한다.
- 그 후 각 군집의 중심을 다시 계산, 중심점이 변하지 않을 때까지 이 과정을 반복한다.
데이터 수집 및 준비
UCI Machine Learning Repository에서 실습 데이터 다운로드
데이터 전처리
특성 선택
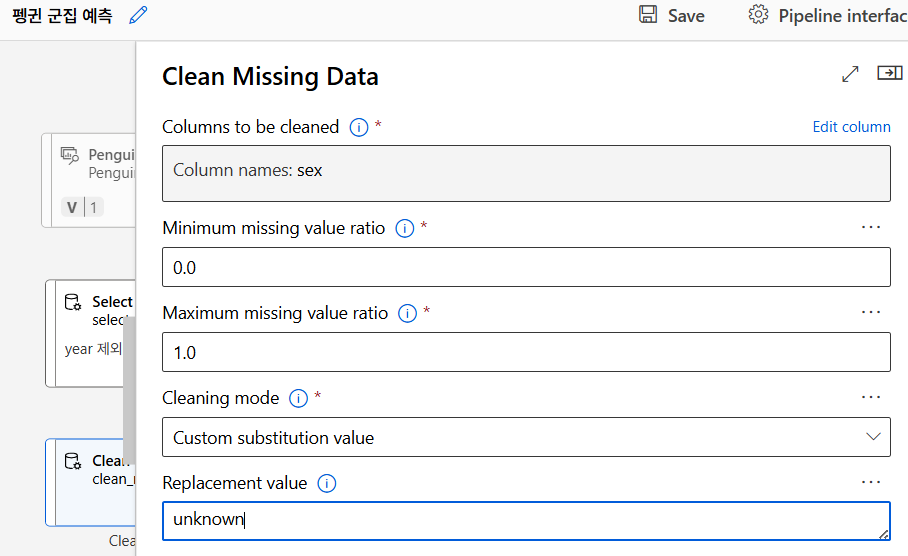
누락값 처리
데이터 변환
모델링
K-means 알고리즘
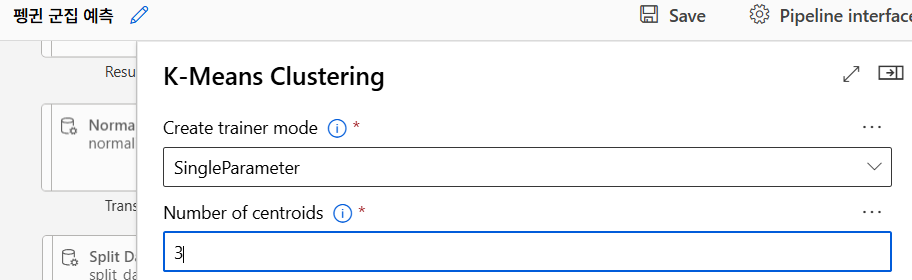
모델 훈련
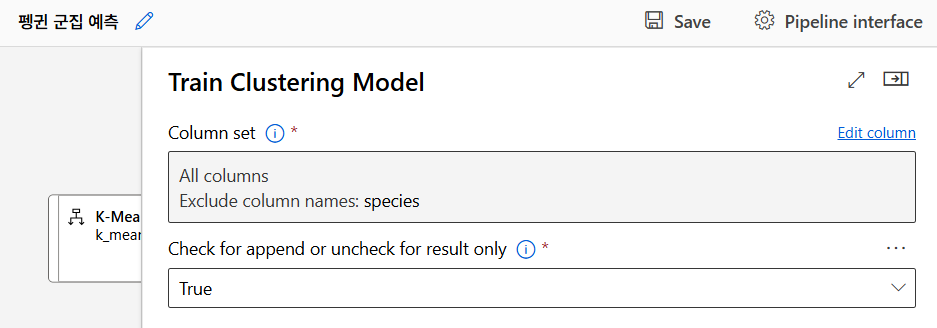
모델 테스트
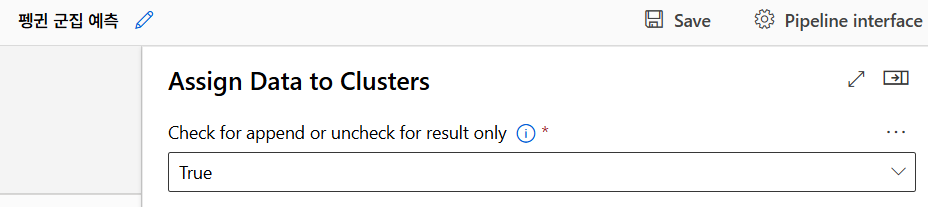
모델 평가
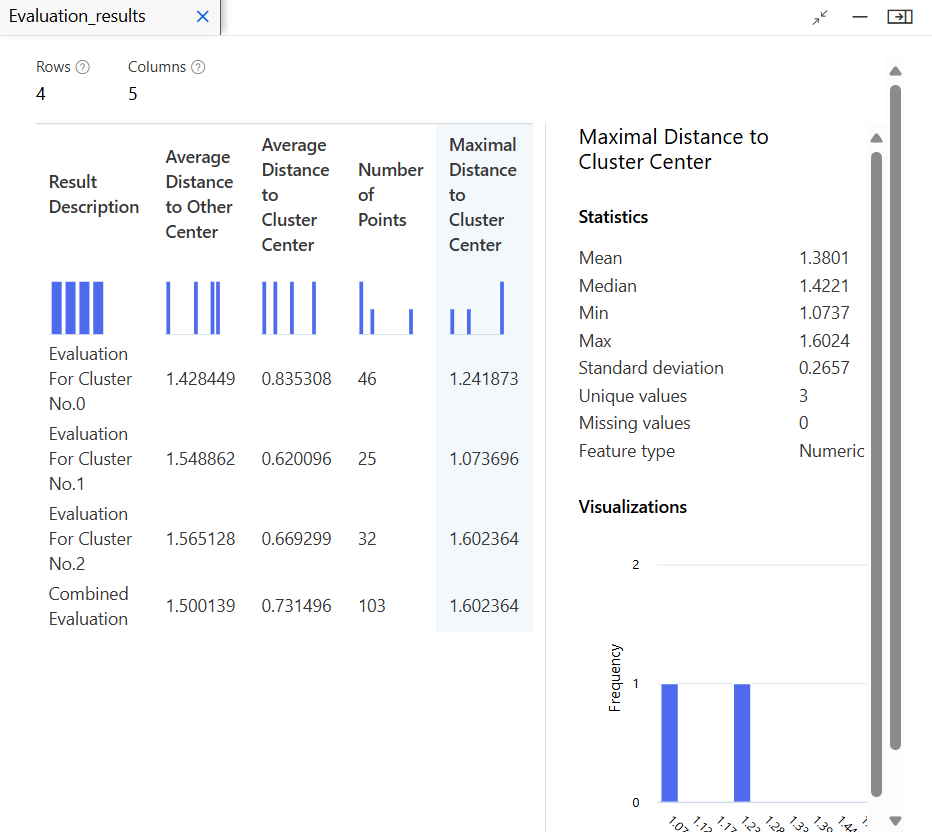
결과 확인 및 유추 파이프라인 생성
결과 확인
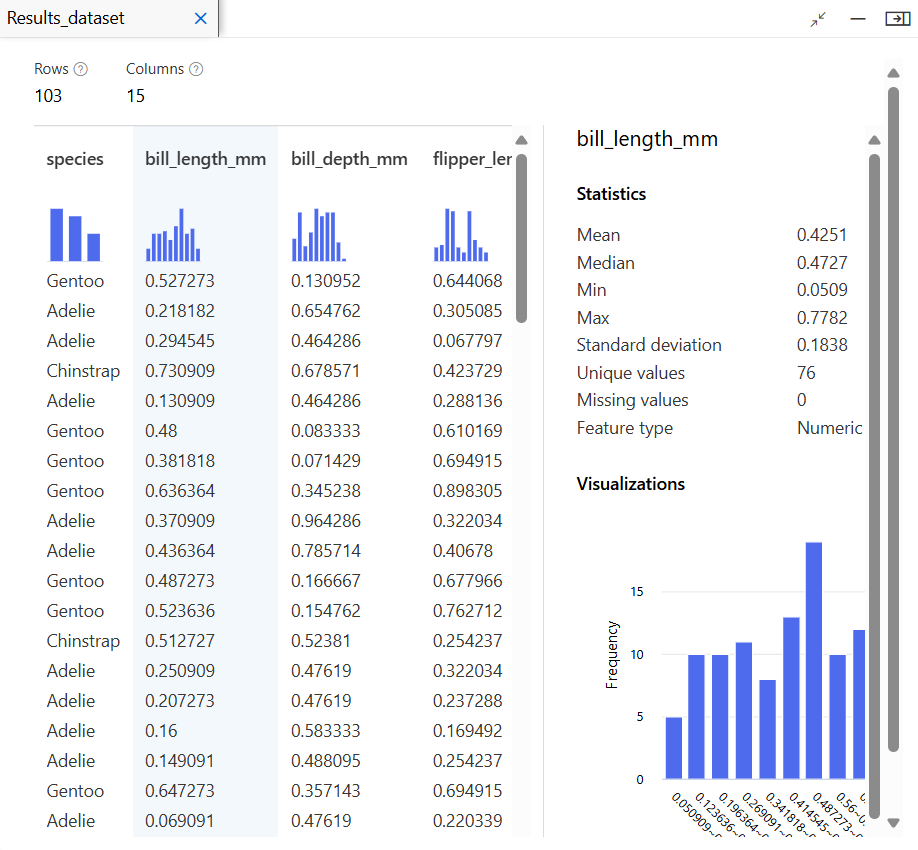
유추 파이프라인 생성
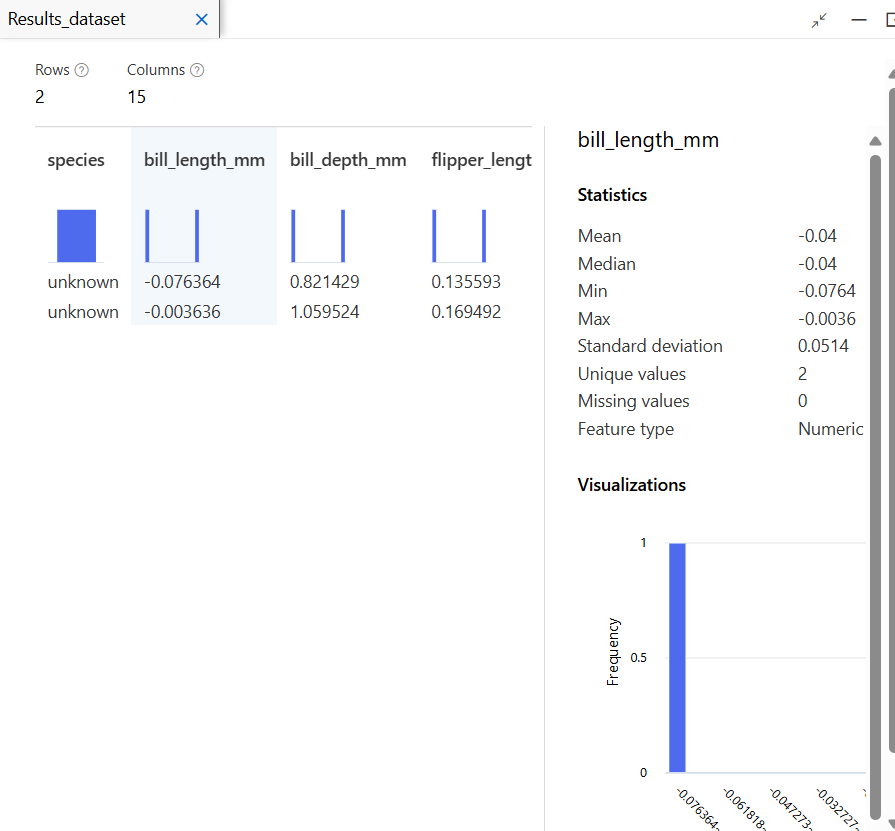
개인 수입 예측 모델 (Boosting)
알고리즘
앙상블 기법은 하나의 모델로 예측하기보다 여러 모델을 결합하여 예측 정확도를 높이는 방법이다. 각각의 모델이 약점이 있더라도 여러 모델이 협력하면 더 나은 성과를 낼 수 있다.
Bagging (Bootstrap Aggregating)
- Bagging은 여러 모델을 병렬적으로 학습시키는 방법이다. 각 모델은 독립적으로 학습을 진행하고, 나중에 그 예측 결과를 결합하여 최종 예측값을 낸다.
- 데이터를 여러 개의 샘플로 무작위로 나눠서 각 모델이 다른 데이터를 학습한다. 이를 통해 각각의 모델이 다른 특성을 학습할 수 있다.
- 각 모델은 서로 다른 데이터를 학습하므로, 모델 간의 상호작용이나 종속성이 줄어들어 과적합(overfitting) 문제를 방지할 수 있다.
Boosting
- Boosting은 순차적으로 모델을 학습시키는 방식이다. 첫 번째 모델이 예측을 끝내면 그 모델이 예측에 실패한 데이터에 더 집중해서 다음 모델이 그 부분을 더 잘 학습하도록 하는 방식이다.
- 이전 모델이 틀린 부분을 계속 보완하면서 점점 더 정확한 모델을 만들어나간다. 이 과정이 여러 번 반복되어 strong learner 가 만들어지는 것.
- Boosting의 핵심 개념은 이전 모델의 약점을 다음 모델이 보완한다는 점이다. 이를 통해 모델의 성능을 꾸준히 향상시킬 수 있다.
AdaBoost (Adaptive Boosting)
AdaBoost는 Boosting 알고리즘 중 가장 기본적인 형태이다. 이 알고리즘은 이전 모델의 실수를 강조하며 그 실수를 더 잘 학습할 수 있도록 모델을 개선해나가는 방식이다.
동작 방식
- 초기 가중치 부여: 모든 데이터는 같은 가중치로 시작된다.
- 첫 번째 모델 학습: 첫번째 weak learner를 학습시킨다. 이때 모델은 각 데이터를 학습하면서 가중치가 있는 데이터를 통해 예측을 수행한다.
- 오류 분석: 첫번째 모델이 학습을 마치면 예측이 잘못된 데이터에 대한 오류(error) 를 게산한다. 틀린 예측을 한 데이터의 가중치를 더 높게 설정함으로써 다음 모델이 이 데이터를 더 잘학습하도록 만든다.
- 두번째 모델 학습: 가중치가 조정된 데이터를 가지고 두번째 모델을 학습한다. 이 모델 역시 가중치를 기반으로 데이터를 학습, 예측이 틀린 데이터에 더 많은 가중치가 부여된다.
- 과정 반복: 과정을 여러 번 반복하면서 각 모델은 이전 모델이 틀린 부분을 보완해가며 성능이 점점 좋아지게 된다.
장단점
- 장점: 단순한 모델을 여러 개 결합하여 성능을 끌어올리는 방식이므로 매우 효율적이고 성능이 좋다.
- 단점: 노이즈(잡음)에 민감하다. 잘못된 데이터나 특이점(outlier)이 있을 경우 그것에 지나치게 집중할 수 있다.
Gradient Boosting Machine (GBM)
GBM은 Boosting 알고리즘의 일종으로 잔차(residual) 를 이용해서 모델을 개선한다. 잔차는 실제 값과 예측 값의 차이를 말하며, 이 잔차를 줄이는 방식으로 모델 성능을 향상시킨다.
동작 방식
- 첫번째 모델 학습: 첫번째 weak learner를 학습시킨다.
- 잔차 계산: 첫번째 모델이 예측한 결과와 실제 데이터 간의 차이를 계산한다.
- 잔차 예측: 두번쨰 모델은 잔차를 예측한다.
- 반복: 과정을 여러 번 반복한다. 각 단계에서 새로 추가된 모델은 이전 모델들이 예측하지 못한 잔차를 예측하며 점점 더 정확한 모델을 만들어간다.
- 학습률(learning rate) 적용: GBM은 잔차를 줄이는 과정이 너무 급격하지 않도록 학습률을 적용한다.
학습률: 각 모델이 잔차를 얼마나 크게 수정할지 결정하는 값학습률을 작게 설정하면 각 단계에서 조금씩 개선해 가는 방식으로 과적합을 방지할 수 있다.
장단점
- 장점: 복잡한 데이터에서도 높은 성능을 발휘한다. 각 단계에서 잔차를 줄여 나가므로 예측 성능이 점점 더 좋아진다.
- 단점: 속도가 느리다. 많은 모델을 순차적으로 학습시키기 때문에 데이터가 많거나 모델의 깊이가 깊을수록 시간이 오래 걸릴 수 있다. 또 학습률을 너무 높게 설정하면 과적합이 발생할 수 있다.
GBM과 AdaBoost의 차이점
- 잔차 기반 학습: AdaBoost는 오류에 집중해 다음 모델이 그 오류를 고치는 방식이지만, GBM은 잔차를 줄이는 것에 초점을 맞춘다.
- 가중치 부여 방식: AdaBoost는 데이터마다 가중치를 다르게 부여하고 이를 기반으로 학습하지만, GBM은 이전 모델의 잔차를 학습하는 방식이다.
데이터 전처리
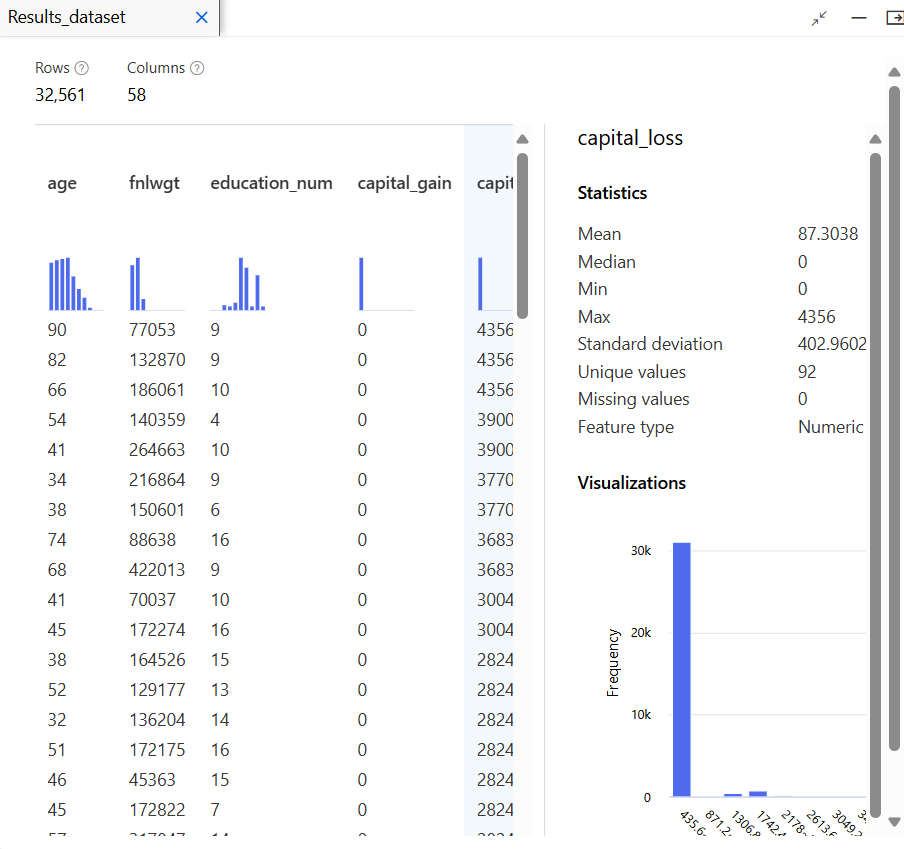
모델 학습
학습 데이터 70, 테스트 데이터 30
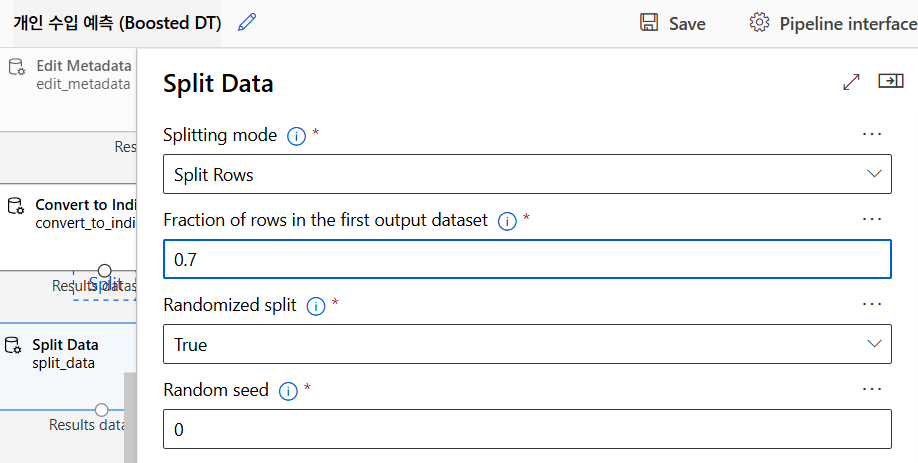
Two-Class Boosted Decision Tree
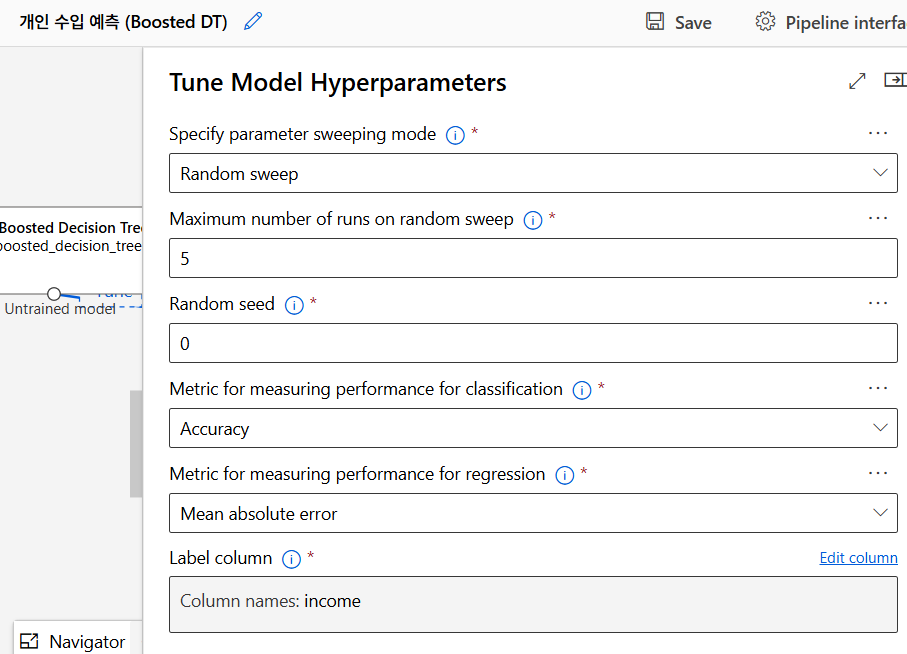
모델 평가
자동차 가격 예측 모델 (트리기반 알고리즘)
MS Azure Machine Learning에서 제공하는 회귀 알고리즘
Poission Regression
- 푸아송 회귀는 푸아송 분포를 사용하는 회귀 알고리즘이다. 푸아송 분포는 일정한 시간 안에 어떤 사건이 몇 번 일어날지 예측하는 데 사용된다.
- 이산 확률 분포를 사용하므로 예측 결과는 보통 양의 정수 값으로 나온다.
Linear Regression
- 선형 회귀는 독립변수와 종속변수 사이에 직선 관계가 있다고 가정한다.
- 단순 선형 회귀는 하나의 독립변수를 다중 선형 회귀는 여러개의 독립변수를 사용해 예측한다.
Bayesian Linear Regression
- 베이즈 선형 회귀는 선형 회귀에 베이즈 이론을 결합한 알고리즘이다. (베이즈 이론: 사건의 확률이 이전에 일어난 사건에 의해 영향을 받을 수 있다.)
- 데이터를 이전에 발생한 사건과 연결지어 그 확률에 기반해 더 빠르고 정확한 모델링이 가능하다.
- 데이터 간의 연관성이 뚜렷할 때 효과적이다.
Neural Network Regression
- 신경망 회귀는 인공신경망을 사용한 회귀 알고리즘이다. 인공신경망은 사람의 뇌처럼 작동하며 복잡한 데이터에서 패턴을 찾아내는 데 유리하다.
- 복잡한 비선형 데이터에 적합하며 선형 회귀로 해결하기 어려운 문제를 해결할 수 있다.
- 훈련에 시간이 많이 걸리고 많은 데이터가 필요하다.
Decision Forest Regression
- 의사 결정 나무 회귀는 의사결정나무(Decision Tree) 기반 회귀 알고리즘이다. (의사결정나무: 데이터를 구간으로 나누어 각 구간에 대해 예측을 수행한다.)
- 의사결정나무 회귀는 복잡한 데이터 구조에서도 유연하게 대응할 수 있다.
Boosted Decision Tree Regression
- 부스팅은 여러 개의 결정 나무를 사용해 순차적으로 학습하는 방법이다. 각 나무는 이전 나무가 예측한 오류를 개선하면서 학습한다.
- 각 단계에서 오류를 보완해 나가므로 성능이 좋다.
- 정확도가 높아지지만 그만큼 메모리를 많이 사용하고 학습에 시간이 걸린다.
Fast Forest Quantile Regression
- 빠른 포레스트 분위 회귀는 의사결정나무를 이용해 특정 데이터 분포의 분위수(quantile) 를 예측하는 알고리즘이다.
- 가격이나 기후 데이터처럼 분포를 기반으로 하는 데이터를 예측할 때 유용하다.
회귀나무 (Regression Tree)
CART 알고리즘 (Classification And Regression Tree)
분류와 회귀 문제 모두에 사용할 수 있는 나무 구조 기반 알고리즘.
- 분류: 데이터를 여러 카테고리로 나누는 것
- 회귀: 숫자 값을 예측하는 것
- 회귀 문제에 사용될 때는 분류에서 쓰는 불순도(Gini Index) 대신 예측값과 실제값 간의 차이(오차)를 기반으로 학습한다.
의사결정나무 회귀
데이터의 구간을 여러개로 나누고 각 구간에 대해 고정된 값을 예측하는 방식이다.
- 데이터의 비선형성을 처리하는 데 유리하며 여러 변수를 고려하여 예측할 수 있다.
- 루트 노드는 전체 데이터를 포함하고 내부 노드는 데이터를 나누는 기준이 되는 지점이다. 리프 노드는 더 이상 나눌 수 없는 마지막 노드로 여기서 예측값이 결정된다.
분할 기준 & 손실함수
데이터를 나눌 때는 손실 함수를 사용한다. (손실함수: 예측값과 실제값 사이의 차이를 계산하여 이를 최소화하는 방향으로 데이터를 나눈다.)
- MSE가 일반적으로 많이 사용된다.
예측값과 실제값 사이의 차이의 제곱을 더한 값 - RSS도 사용되는데 이는 데이터 구간 내의 데이터와 그 구간의 평균 사이의 차이의 제곱을 더한 값이다.
모델 훈련 및 평가
데이터 분리
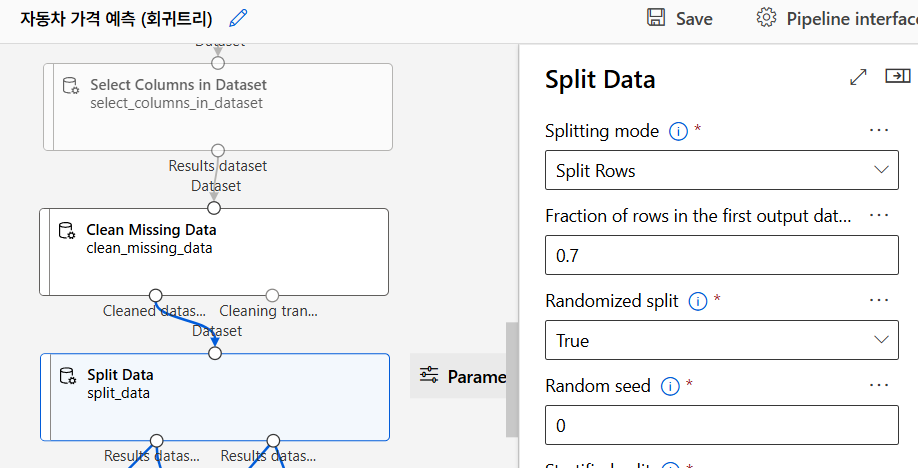
모델링 알고리즘 선택
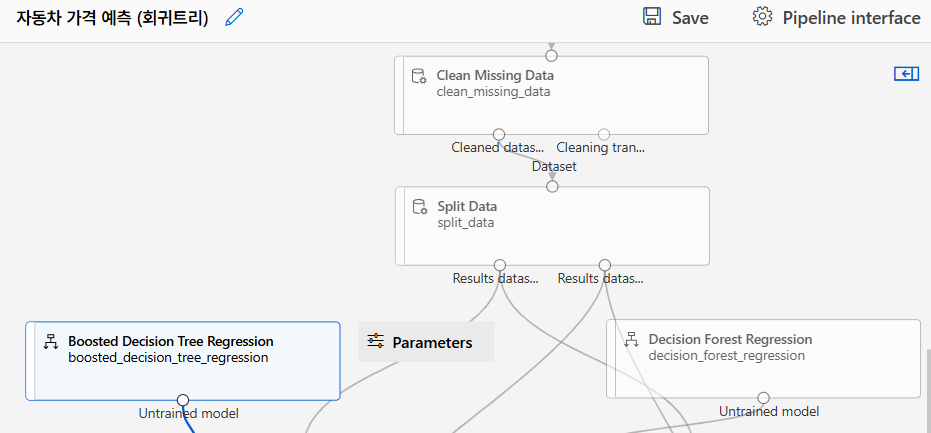
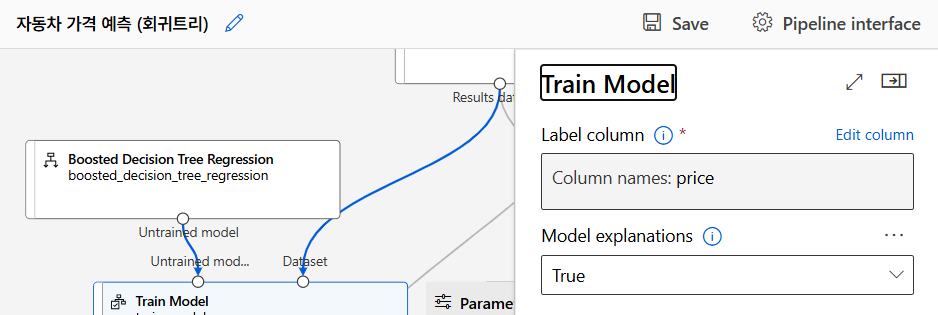
모델 훈련
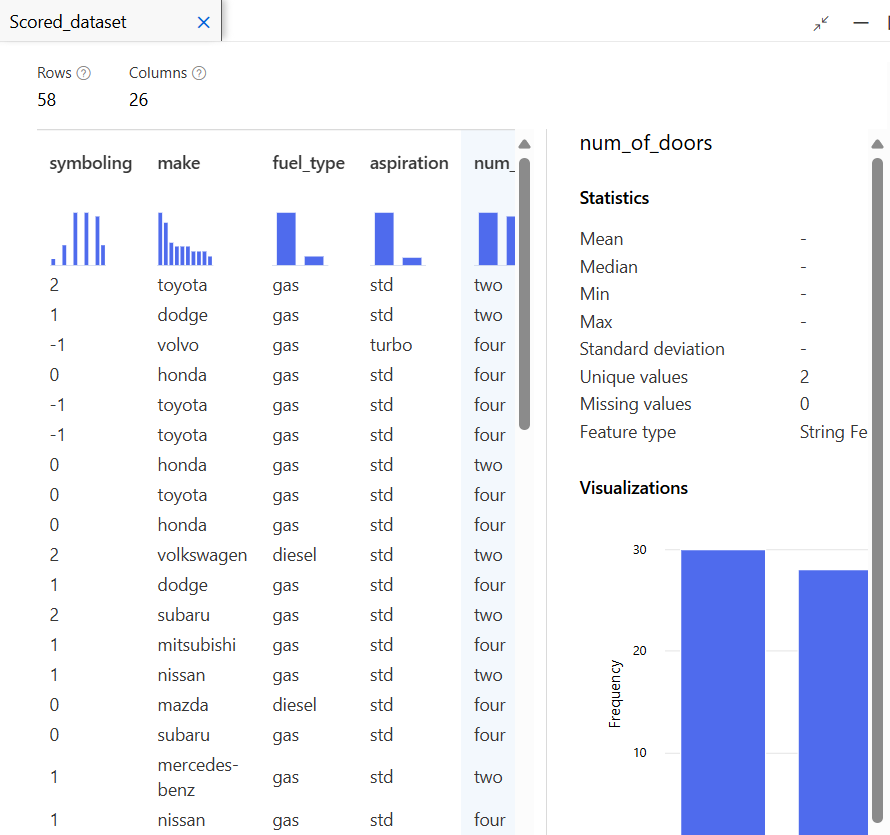
모델 테스트
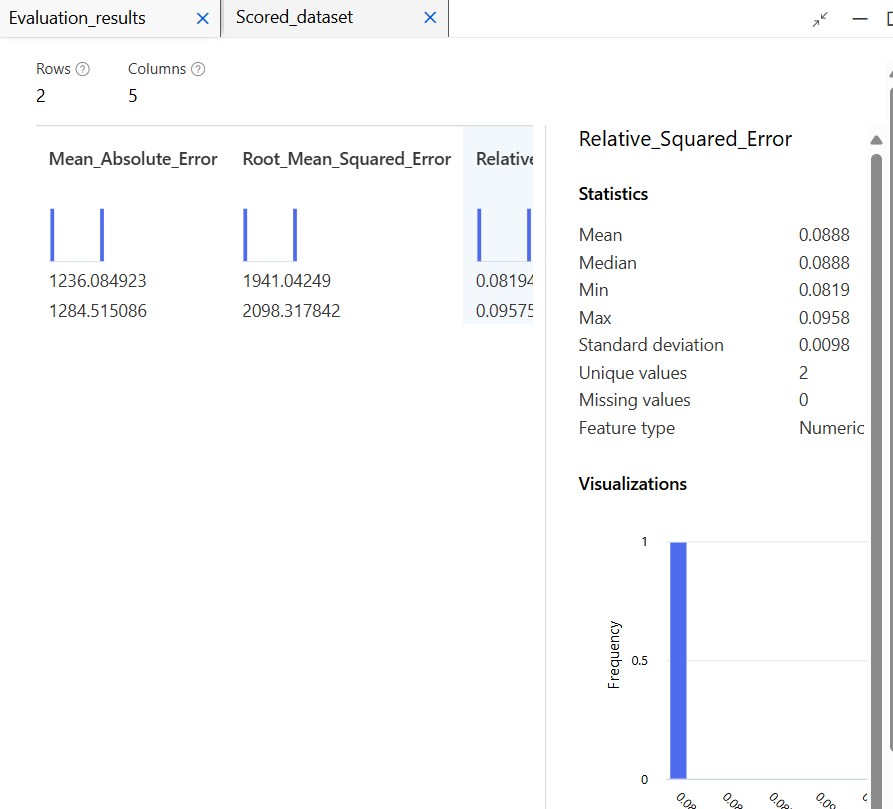
모델 평가
추가 실습

Personal Insight
이후에 버섯 분류 모델 개인 실습을 진행하였으나.. 오류 폭탄을 맛보고 오늘은 이만 머리를 식히기로 하였다. 나쁜 버섯 🍄
