

하루 한 줄 요약
동료와 공유하는 것의 중요성을 다시금 느낀 하루.
오늘 공부한 내용
- 배열, 문자열
- 반복문, 재귀함수
- 정렬(버블, 선택, 삽입)
- 소수 판별
새로 배우게 된 내용
배열, 문자열
어쩌면 아무 의미 없겠지만, 문자열보다 배열이 앞에 있기에 배열부터 살펴보았다.
여러개의 데이터를 저장할 수 있는 공간이다.
index라는 고유의 주소값을 통해서 각 값에 접근할 수 있다.
-
Index는 왜 0 부터 시작할까?
팀 스터디 하다가 팀원분께서 문득 질문하셨는데, 찾아보니 메모리 계산의 편리성 때문이라고 한다.
a + i * size(a :시작 주소 , i : i 번째 요소, size : 각 요소가 차지하는 메모리 크기)
이때 i를 0부터 사용하면 추가적 계산 없이 바로 배열의 시작주소를 쓸 수 있기 때문이다.
역시나 다 의미가 있던 것... -
배열에서의 파이썬과 C의 명확한 차이
공부하면서 파이썬같은 경우 List 자료형을 활용해서 크기도 자유롭게 늘렸다가 줄일수도 있다.
또한 len(), max, min, sort() 등 다양한 메서드를 지원하는 반면,
C언어 같은 경우 고정된 크기의 메모리 블록을 연속적으로 할당한다.
또한 길이도 직접 배열 크기를 요소 크기로 나누어 주어야 하는 차이를 알 수 있었다.
sizeof(arr) / sizeof(arr[0])
- NUL, NULL, 0, \0 의 차이?
일단 널문자를 쓰는 이유는 메모리상 문자열은 이진 데이터로 저장되는데,
이 문자열의 시작과 끝을 구분하기 위함이다.
결론은 저 4가지는 같은 의미이다.
아스키에서 0000 0000 으로 매핑되어이있기 때문에 의미는 같다.
다만 CSAPP에서 배웠던 Context에 따라
문자열 종료 문자인지, 정수 0인지, 널포인터 인지 다르게 해석되는 것!
반복문, 재귀함수
-
반복문에서의 C와 파이썬의 명확한 차이
일단 do/while은 파이썬엔 없고 while True:와 break으로 흉내 낼수는 있다.
C는 컴파일 언어라서 소스 코드 전체를 읽어서 기계어로 바꾸기 때문에 반복문을 최적화해서 실행 속도를 높일 수 있다.
반면 파이썬은 인터프리터 언어라서 한줄씩 기계어로 변환되기에 C 보다 상대적으로 속도가 느리다.
(가끔 백준 문제 보면 다른 언어들은 1초 주는데 파이썬은 2초 줄때가 있는데 이런거 때문이 아닐까...?) -
재귀와 반복문은 어떤 차이를 갖고 있나?
사실 재귀나 반복문이나 똑같은 작업을 계속 한다는 것은 똑같다.
그러나 우리가 재귀를 배우는 이유는 자신을 호출하면서,
큰 문제를 작은 문제로 나누어 해결하는 방식에 적합하기에 배우는 것 같다. -
재귀를 더 빠르게! Memoization
쉽게 설명하자면 했던 계산은 안하고 저장된 곳에서 빠르게 꺼내오는 것!
from timeit import Timer
def fibonacci(n):
if n == 0: return 0
if n == 1: return 1
return fibonacci(n - 1) + fibonacci(n - 2)
# 메모이제이션 적용
dic = {0: 0, 1: 1}
def fibonacci_memo(n):
if n in dic:
return dic[n]
dic[n] = fibonacci_memo(n - 1) + fibonacci_memo(n - 2)
return dic[n]
t1 = Timer("fibonacci(30)", "from __main__ import fibonacci")
t2 = Timer("fibonacci_memo(30)", "from __main__ import fibonacci_memo")
print("단순 재귀 * 20번", t1.timeit(number=20), "seconds")
print("재귀 + 메모이제이션 * 20번", t2.timeit(number=20), "seconds")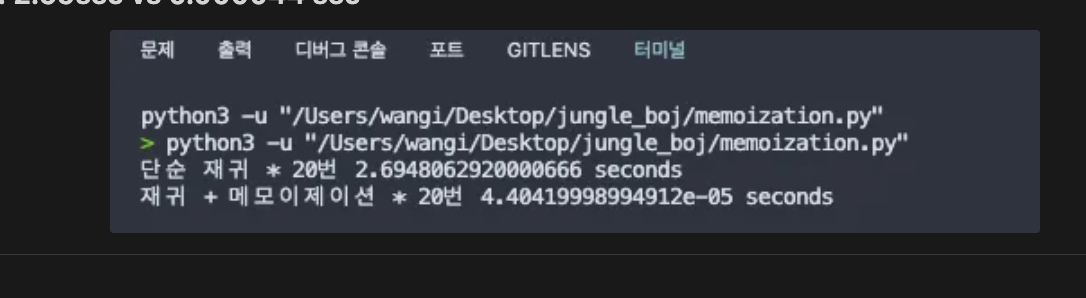
속도차이가 어마무시 해서 놀랐다.
정렬(버블, 선택, 삽입)
정처기 필기 준비하면서 시간복잡도만 디립다 외웠고,
그게 왜 그런 시간 복잡도를 가지는지 이번 기회를 통해 알게 되었다.
결국 리스트를 한바퀴 돌면서 두 원소를 비교하고 정렬하는데,
2중 루프가 필요하기에 버블정렬은 O(N^2) 였고,
이진탐색은 단계마다 탐색 범위가 절반씩 좁아지는 것이기에 O(log2 N) 이 보장되는 것이었다.
백준 - 소수 판별(2588)
문자열 슬라이싱 관련 문제로 팀 스터디때 백준 문제 풀이를 공유했는데
너무나 간결하게 단 4줄로 풀었던 팀원의 설명에 뒷통수를 씨게 맞았던 기분
그와중에 문자열로 입력받고 숫자로 바꾸고 다시 문자열로 입력받고 앉아 있었다...

a = int(input())
b = input()
print(a*int(b[2]))
print(a*int(b[1]))
print(a*int(b[0]))
print(a*int(b))
#####################
import sys
input = sys.stdin.readline
first = int(input().rstrip())
second = int(input().rstrip())
second_digit = []
for i in str(second):
second_digit.append(int(i))
# 3 -> (1)과 (2)의 1의 자리
print(first * second_digit[-1])
# 4 -> (1)과 (2)의 10 의 자리
print(first * second_digit[-2])
# 5 -> (1)과 (2)의 100의 자리
print(first * second_digit[-3])
# 6 -> (1) * (2)의 곱셈 연산 값
print(first * second)공부하면서 어려웠던 점
- 오늘은 스무스하게 잘 공부했던 것 같다.
- 팀 스터디때 단순 개념 정리에 제공받은 백준 문제를 연결해서 설명했다면 더 명확한 이해가 되었을 것 같다.
