
오늘은
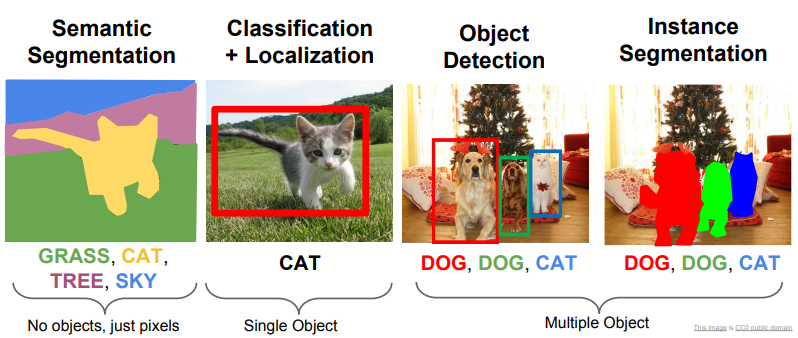
Segmentation(이미지 분리)
Localization(위치 찾기)
Detection(탐지)
에 관한 내용입니다.
Semantic Segmentation

컴퓨터는 각 픽셀을 레이블로 구분합니다.
그래서 픽셀만 신경을 써서 오른쪽 그림처럼 소 두마리를 구별 못하는 문제가 있습니다.
이런 문제 해결을 위해
Sliding Window
Fully Convolutional
위 두가지 방식이 나왔습니다.
2017년 기준이다.

Sliding Window방식은 이미지를 구역별로 잘라내서 CNN을 거치게 하는 방식입니다.
하지만 이 방식은 전체 이미지에 대한 것이 아니라 일일이 구역별로 잘라낸 것을 적용하는 것이라서 계산할 것이 너무 많습니다(별로 좋지 못한 방식)
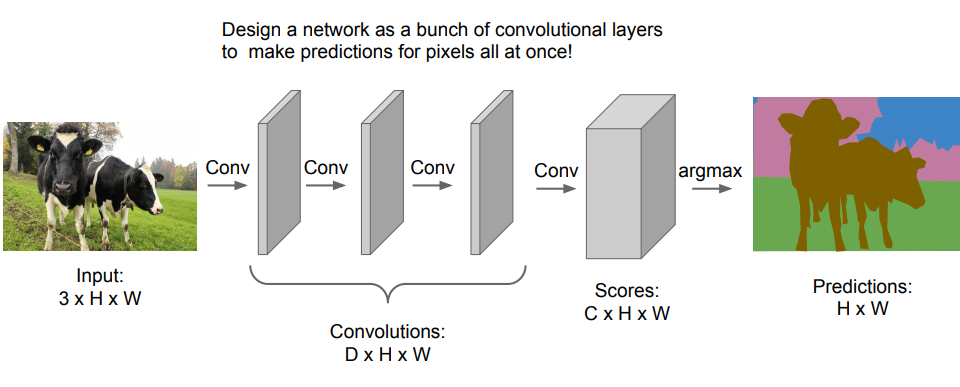
Fully Convolutional Network 방식입니다.
위에 Sliding Window 방식처럼, 독립적인 조각 분류 느낌이 아닌, CNN망을 여러겹 쌓은 느낌입니다.
하지만 이 방식도 결국에는 너무 많은 메모리를 차지하는 문제 때문에, 잘 사용하지 않는 방식입니다.
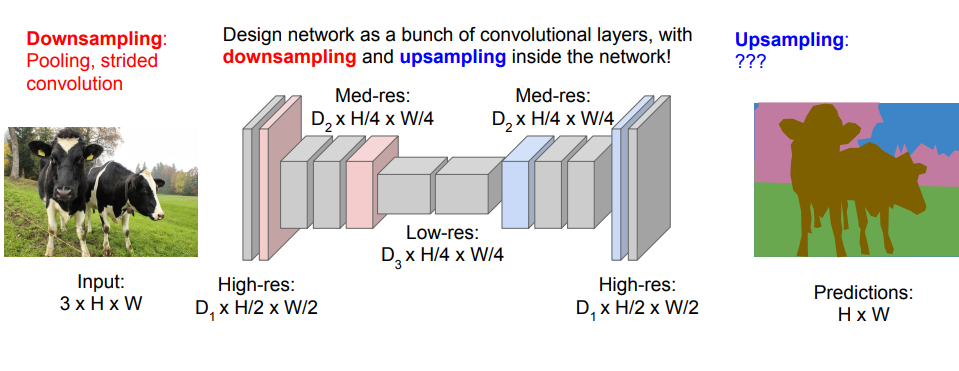
위의 Fully Convolutional Network방식을 보완한 'Down Sampling, Up Sampling'방식 입니다.
처음 'Down Sampling'으로 축소를 하게 되고, 'Up Sampling'으로 고해상도 이미지를 출력하게 됩니다.
또 'Up Sampling'방식으로는 두가지 방식으로 나누어 지는데, 'Nearest Neighbor'(같은 수 복제) 방식, 'Bed of Nails'(0값 채워넣기) 방식 으로 나뉘게 됩니다.
이제 위의 Fully Convolutional Network방식을 살펴보도록 하겠습니다.
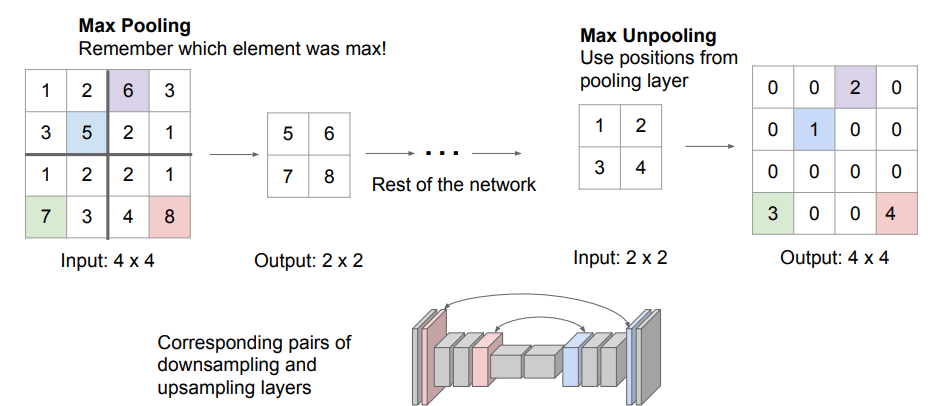
그림을 보면, 처음 '다운 샘플링'으로 Max Pooling방식을 사용했고, '업 샘플링'으로 'Bed of Nails'방식이 적용되었음을 알 수 있습니다.
Classification + Localization
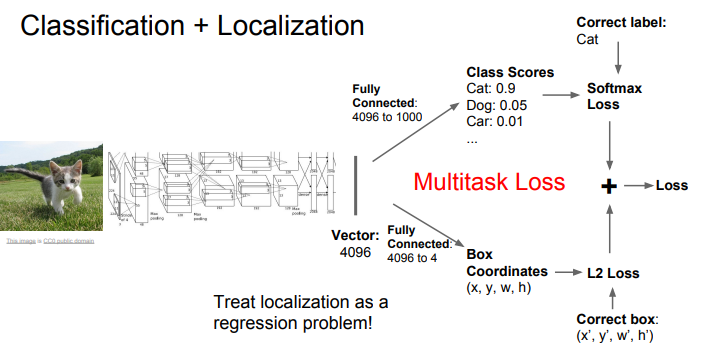
처음으로 이미지를 신경망(AlexNet)에 넣게 됩니다.
그렇게 이미지가 요약(축소)됩니다.
각각을 FC로 연결하고, 하나는 점수를 내게 되고, 하나는 좌표(Box Coordinates)값을 뱉게 됩니다.
그렇게 나온 Loss 값을 더하면, 이것이 최종 Loss값이 되게 됩니다.
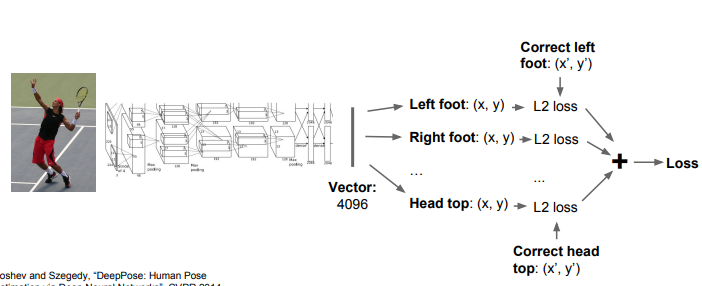
다음은 스켈레톤을 예시로 들었습니다.
탐지한 부분 각각의 좌표를 L2 loss를 거치고, 그걸 다 sum한 값이 최종 loss값이 됩니다.
스켈레톤은 있는 모델로 그냥 찍고, 감탄만 했었는데, 내부에 이런 작용이 일어나는게 참 놀라웠다.
Object Detection
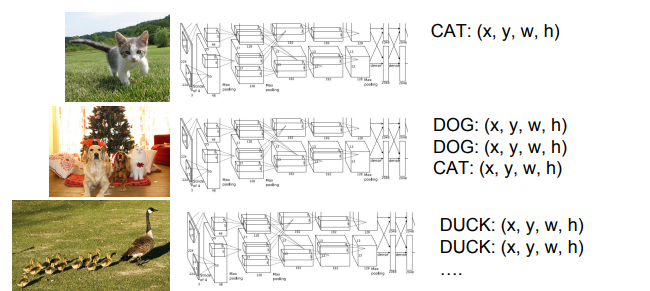
물체 탐지는 각 물체마다 (x,y,w,h)값 4개를 예측해야 합니다.
그래서 이를 Regression 문제로 풀면 안됩니다.
일부분 회귀로 구성되는 경우도 있는데, 전체를 그냥 회귀로 풀면 안된다는 이야기 같다.
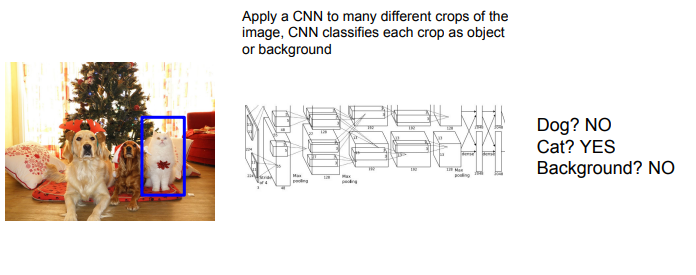
그래서 이렇게 여러 조각으로 나누고, CNN에 적용하는 방식을 씁니다.
하지만 이것도 요새는 계산할게 너무 많아져서 잘 사용하지 않는다고 합니다.

그래서 이 계산량 때문에, 나온 방식이 '영역제안(Region Proposals)' 입니다.
Selective Search라는 방식을 써서, cpu에서 2초동안 2000개의 영역을 뱉는 엄청난 방식입니다.
아무래도 과잉탐색, 스케일과 같은 문제 때문에 노이즈가 쫌 껴 있을수도 있는데, 그래도 최종적으로 좋은 출력을 냅니다.
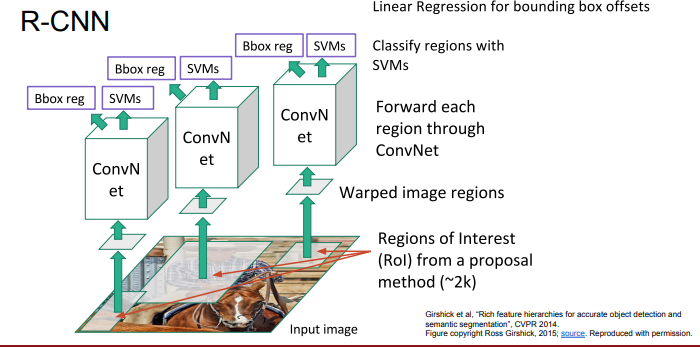
다음으로 R-CNN입니다.
각 영역마다 구역 나눠서 CNN계층을 통과하게 됩니다.
하지만 이 방식은 각 경계를 너무 많이 나누게 되는 경우도 생겨서 계산량이 상당합니다.
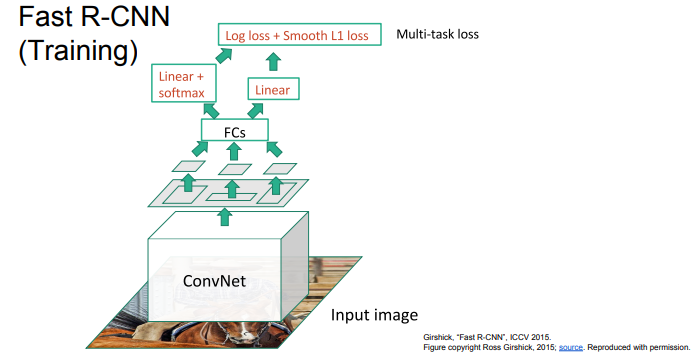
그래서 나온게 Faster R-CNN 입니다.
처음에 영역 구분을 안하고, 전체 이미지를 한번에 CNN계층을 통과시킵니다.
그렇게 나온 출력물을 FC계층을 거치고, 각 손실값을 계산하는 형태입니다.
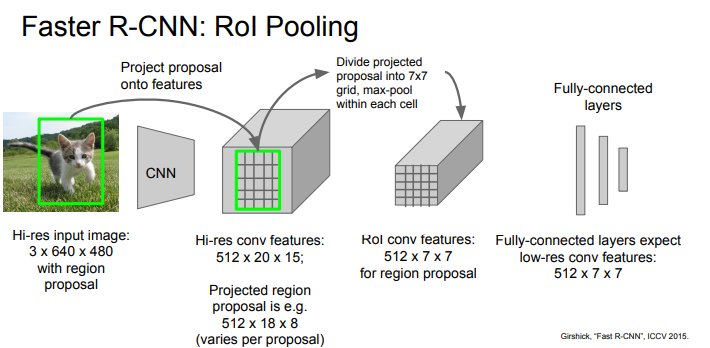
그 다음 Faster R-CNN인데, Max Pooling을 거친 방식입니다.
Faster R-CNN과 똑같은 방식에 풀링으로 차원 축소를 한 것입니다.
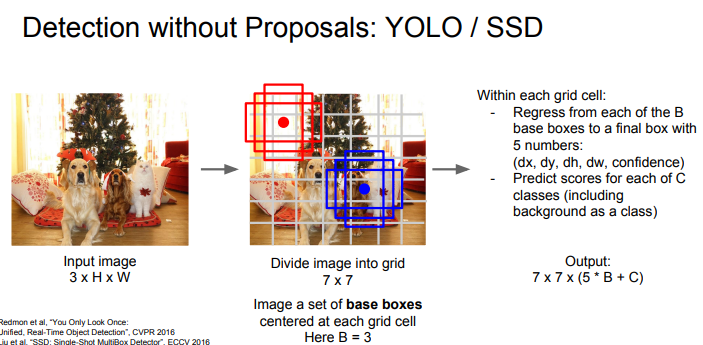
YOLO/SSD 방식입니다.
그리드 라는 영역으로 이미지를 나누게 됩니다.
여기서 그리드 셀은 탐지 물체 뿐만이 아닌, 배경까지도 하나의 클래스로 포함해서 예측하게 되는 형태입니다.
Instance Segmentation
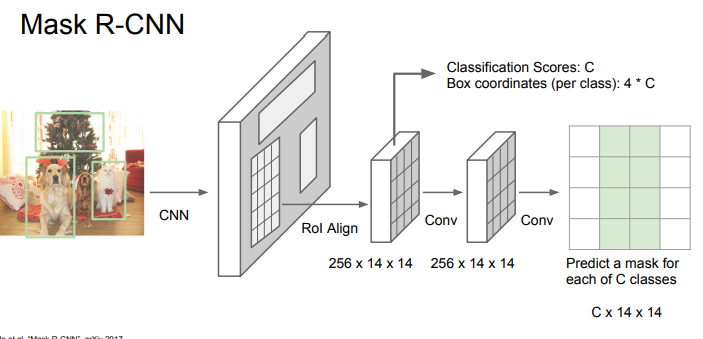
여기서 설명한 것은 Mask R-CNN방식 입니다.
단순 분류, 예측이 아닌, 영역 각각을 분리하는 형태입니다.
앞에서는 어떤 영역을 찍어내는 느낌이었는데, 여기서는 이름에서 알 수 있듯이 어떤 마스크?를 찍어내는 것을 생각하면 편하다. (탐지 물체 전체 밀도? 느낌)
감사합니당 ~ 🦾
참고자료
https://www.youtube.com/playlist?list=PL3FW7Lu3i5JvHM8ljYj-zLfQRF3EO8sYv
http://cs231n.stanford.edu/2017/syllabus
