
이번 포스팅은 RNN 내용입니다.
순환 신경망(Recurrent Neural Networks)은 시퀀스 데이터(문장, 음성, 시계열)를 처리하는데 사용되는 신경망입니다.
그럼 바로 본론으로 들어가겠습니다.
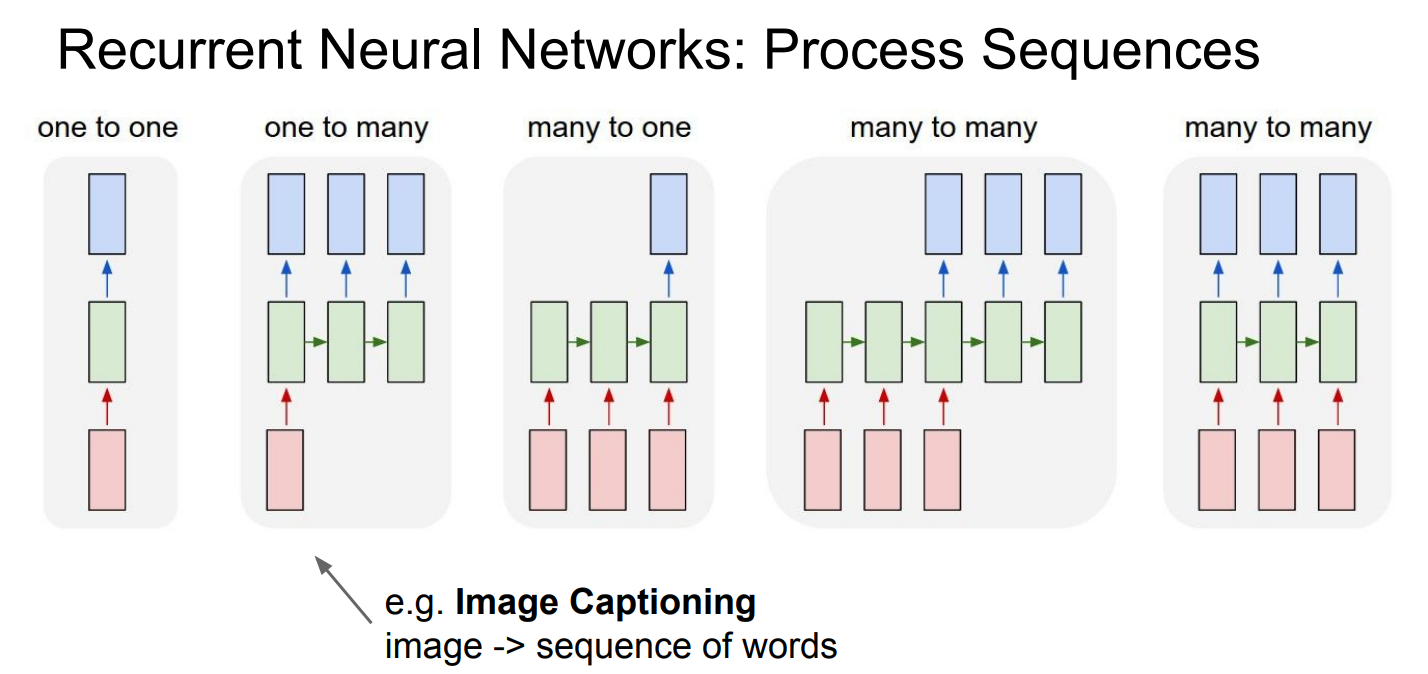
RNN의 작업 과정 모식도 입니다.
첫번째 one to one은 1:1 구조로 이루어지며, Vanila Neural Networks(가장 기초 신경망)입니다.
두번째 one to many는 1:N구조로 이루어지고, Image Captioning(Image -> sequence of words)에 사용되고,
세번째 many to one, N:1 구조는 Sentiment Classification(감성분류), 즉 Sequence of words -> sentiment에 사용됩니다.
네번째 many to many, N:M구조는 Machine Translation(번역)에 사용되고,
다섯번째 many to many, M:M구조는 Video classification on frame level(비디오를 프레임 단위로 분류 후 각 프레임을 개별적 분류)에 사용된다고 합니다.
이처럼 영상에서도 적용된다는 것이 참 신기했다.
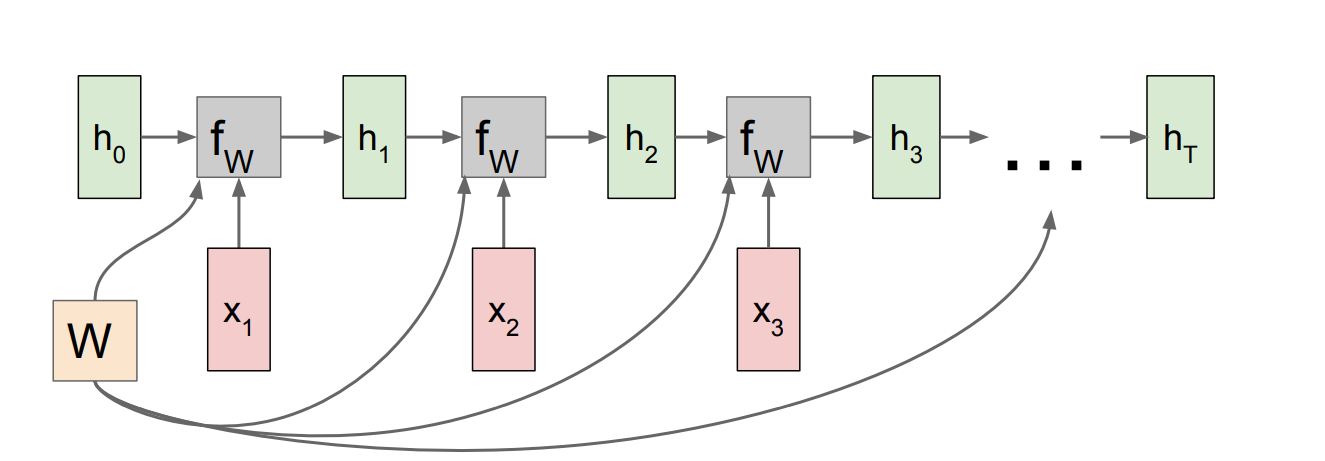
이 그림은 RNN 내부가 어떻게 작동되는지에 대한 그림입니다.
h_0에서 시작하여, x_1(input), f_w 계속해서 거치게 되는데, 새로운 h_1이 생성됩니다.
이런 방식으로 h_T까지 쭈욱 가게 되는데, W값만 계속 중복(똑같은 가중치값)되는 구조 입니다.
이제부터 위에서 간략하게 설명했던 구조에 대해서 자세히 살펴보도록 하겠습니다.
Many to Many
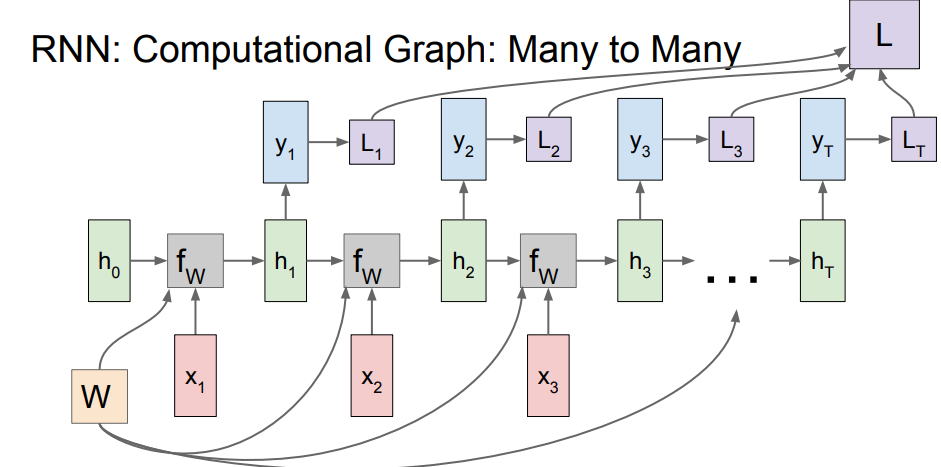
위와 비슷한 형태인데, 똑같은 방식으로 h_T까지 가고, 또 다른 입력으로 들어가서 y_T값을 만들어내게 됩니다.
여기서 y_T는 class score이고, 여기서 각각의 loss값도 개별적으로 계산 가능합니다. 최종 loss는 모든 개별 loss를 전부 더해주면 됩니다.
h는 hidden state, x가 input, y가 output
Many to one
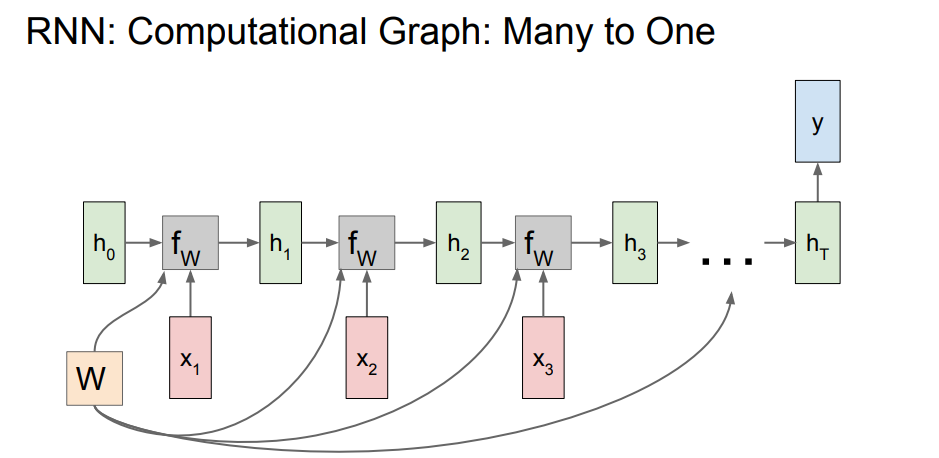
다대일 구조에서는 마지막 hidden계층에서 output값을 뱉게 되는 구조입니다.
One to Many
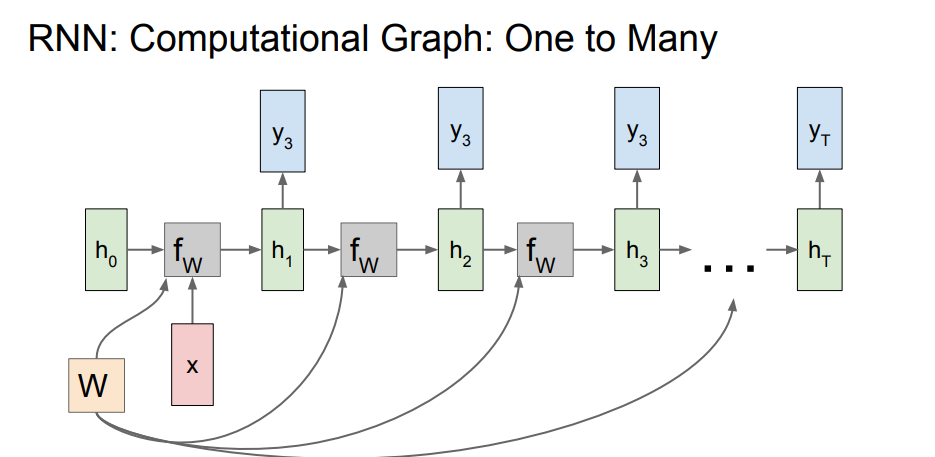
input값(x)를 하나로 고정시키고, 매 hidden 계층에서 output을 가지게 되는 형태입니다.
모든 스텝에서 output값을 가지는 형태입니다.
Sequence to Sequence: 다대일 + 일대다
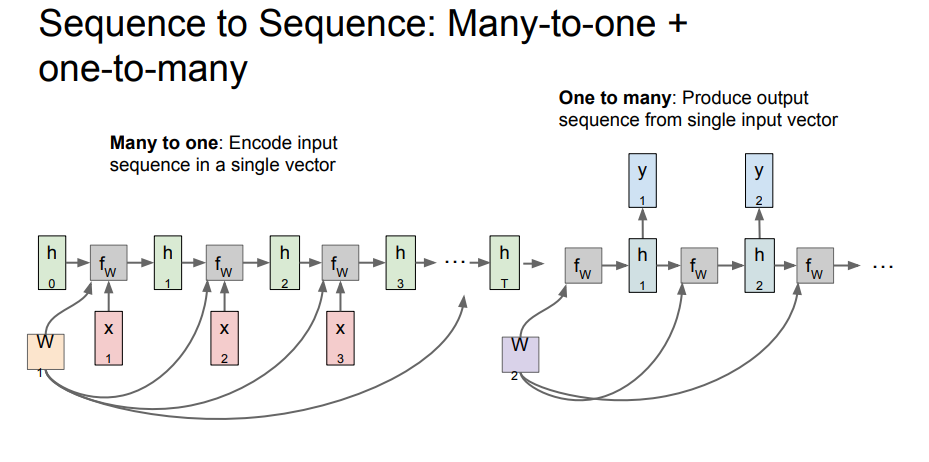
이 구조에서는 두개의 단계로 이루어집니다.
하나는 encoder
하나는 decoder
형태입니다.
왼쪽 many to one파트가 encoder, 오른쪽 one to many파트가 decoder인데,
encoder파트에서 input여러개를 받아서, 최종 hidden 계층에서 하나로 압축을 하고,
그걸 decoder파트, 즉 one to many를 수행하는데, 압축한 벡터를 hidden 계층에서 여러개의 output으로 뱉게 됩니다.
이제부터 자연어 처리 과정을 살펴보겠습니다.
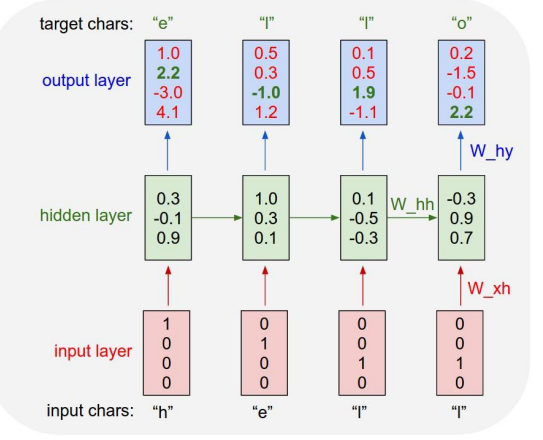
hello라는 단어를 예측하려고 하는 예시입니다.
단어를 하나씩 쪼갠 다음에, input 레이어에서 h를 넣으면, 벡터 형태로 변환(One-hot encoder) 한 다음에, hidden 레이어를 거친 다음에, output 레이어에서 가장 높은 값을 가진 값으로 출력하게 되는 것 입니다.
그 출력된 값을 다시 input으로 넣게 되고, 또 다시 hidden 레이어, 출력, 이 과정을 계속 거치고, 마지막에 'o'를 예측하게 됩니다.
여기서 hidden 레이어는 계속해서 다음 계층으로 전달되는 형태 입니다.
여기서 output 레이어 값이 쫌 이상하게 나와있는데, 알려주는 사람도 잘못된 값이라고 했다.
디테일한 값 계산은 좀 더 찾아봐야 할 것 같다.
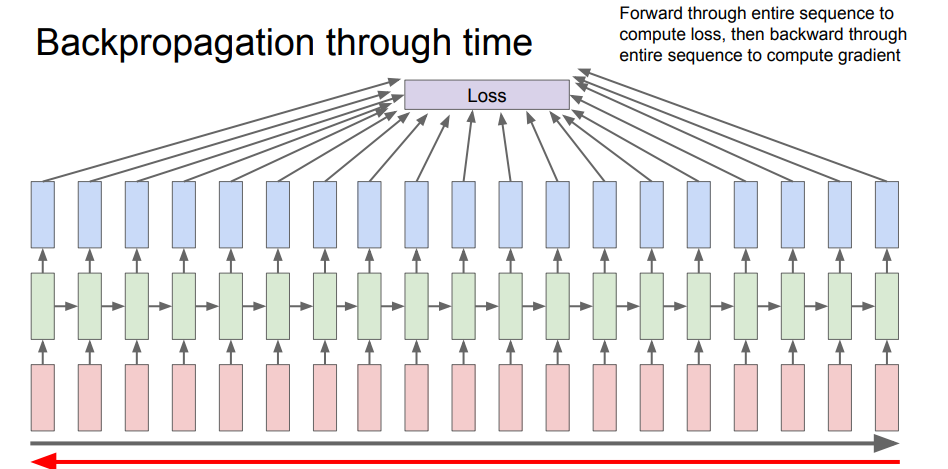
그리고 위의 그림을 보다보면 loss값이 나온것을 알 수 있습니다.
이 loss값은 backpropagation을 통해 계산되는데, sequence길이가 길면, 전체 계산량은 참 많아지게 되고, 메모리도 터질 가능성도 존재합니다.
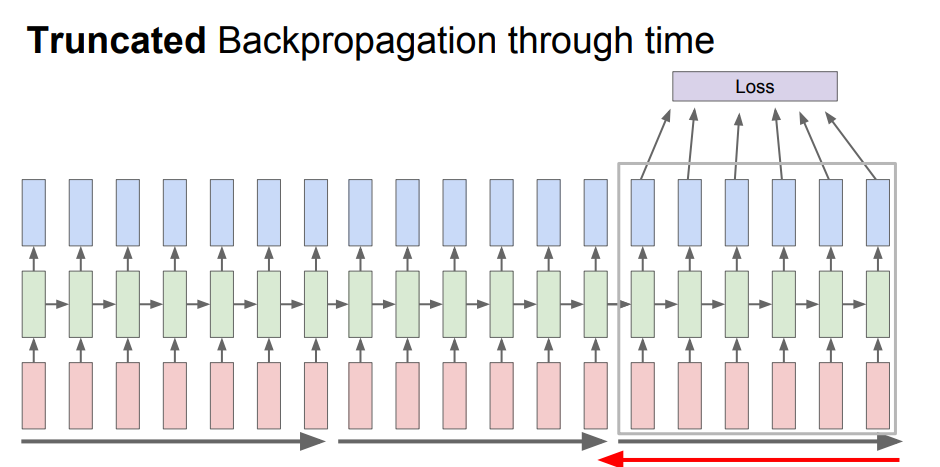
그래서 이런 문제를 해결하기 위해 나온 개념이 Truncated Backpropagation 입니다.
이 방식은 train시에, 일정 단위로 짜르게 되고, 각각의 짜른 것에서 loss값을 다 따로따로 계산하게 됩니다. 이 과정을 계속 반복하게 되고, 결국 위에서 발생했던 문제를 예방 할 수 있습니다.
이전의 hidden state를 가져와서 forward pass, Backpropagation은 현재 hidden state애서만 한다고 한다.
CNN + RNN
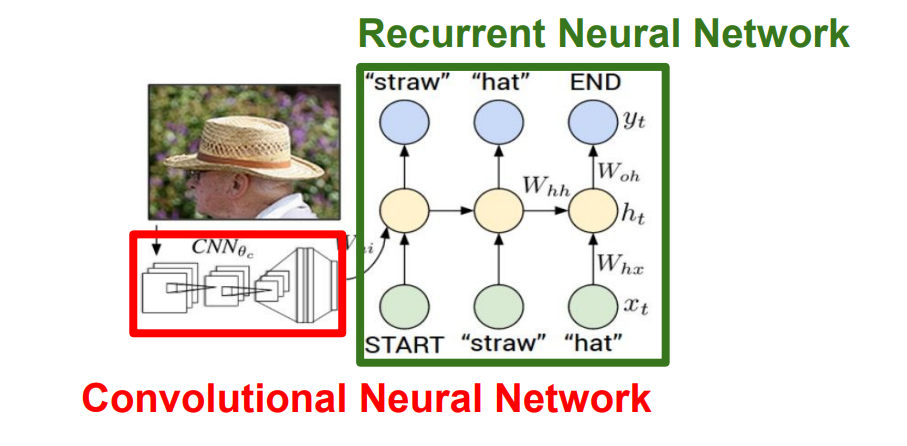
이런식으로 CNN과 같이 엮어서 작업 수행이 가능하고,
CNN에서 수행한 작업을 RNN초기 값으로 들어가 문자를 예측하는 과정을 그림에서 보여줍니다.

다만, 이런식으로 CNN에서 전체 계층을 다 거치는 것이 아닌, 초기 FC계층을 거쳐서 vector값을 출력(이미지 데이터 압축)하게 되고,
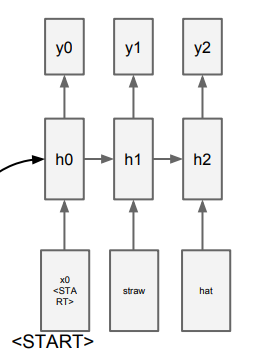
이 압축 값을 RNN의 초기 hidden 레이어로 들어가게 되서 최종 출력값을 갖게 되는 과정을 거치게 됩니다.
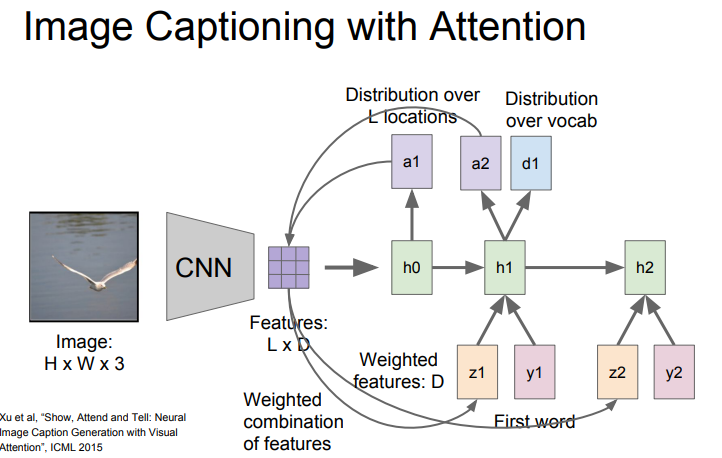
그리고 간략하게 넘어간 개념이지만, Attention개념이 나왔습니다.
이 강의는 Computer vision에 초점이 맞춰져 있다.
Attention이라는 것은, 잘못된 결과를 출력하는 경우가 더러 있어서, 연관된 것 중에서 어떤 부분에 집중을 해야 하는지 결정하는 것이라고 합니다.
그림에서는 CNN을 거치고 나서, 전체 벡터값을 전달하는 것이 아닌, 가중치 값을 벡터 형태로 만들고, 이 부분을 각각의 RNN 계층에 전달하는 것이라고 합니다.

이 결합을 어디에 써먹을 수 있냐에 대한 것인데, 위 그림을 보면 한눈에 파악할 수 있습니다.
Vanilla RNN
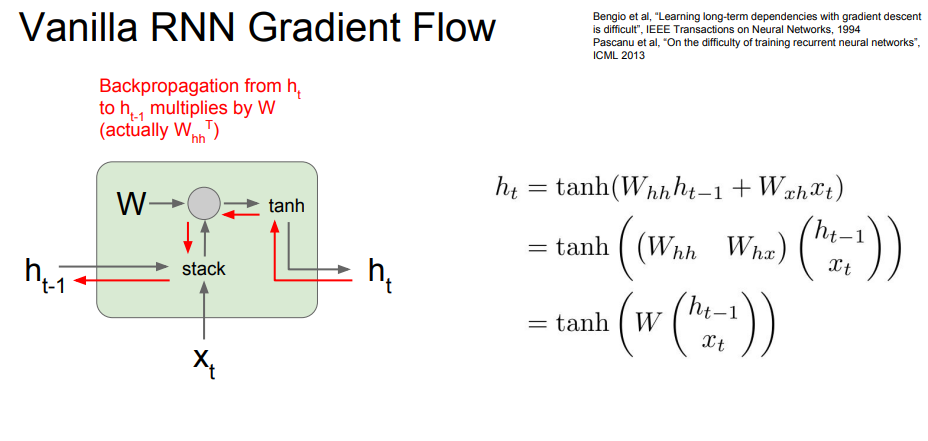
여기서 RNN에서 Backpropagation 과정을 보여줍니다.
빨간 화살표가 역전파 과정이고, 최종 h_t에서 가중치값을 계속 곱해주면 됩니다.
그리고
exploding gradient
vanishing gradient
개념이 나왔습니다.
exploding gradient는 역전파 과정 중에서, 값이 1보다 큰 값을 역전파 한다고 할 때, 최종 경사(h_0)값은 매우 커지게 됩니다.
이 경우에는 gradient clipping과정을 통해, 경사 비율을 조정해서 해결이 가능합니다.
그리고 vanishing gradient는 값이 1보다 작은 값을 역전파 한다고 하면, 경사는 계속해서 줄어들게 됩니다.
이는 따로 해결책이 없는데,
RNN구조 자체를 바꿔야 합니다.
LSTM
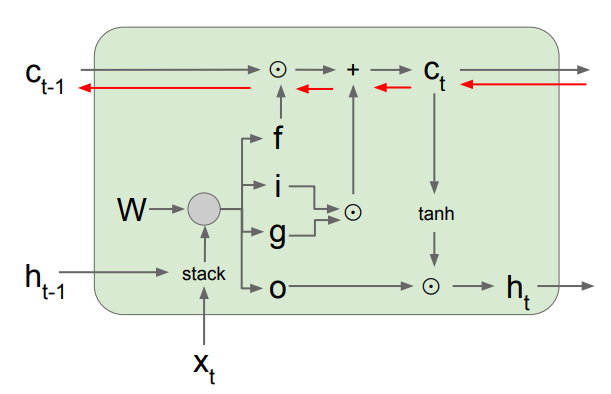
RNN과 형태가 거의 비슷한데, RNN처럼 가중치 값을 곱해주는 과정이 빠졌습니다.
LSTM은 역전파 시, '+'가 두가지로 복사되고, element단위 곱셈을 통해 계산이 되고,
중간에 Forget gate를 통해 exploding gradient, vanishing gradient 문제가 사라진다고 합니다.(W값 반복해서 곱하는거 사라져서)
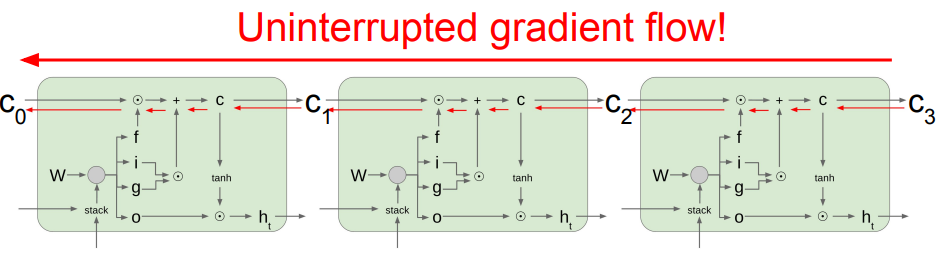
그래서 이렇게 LSTM 셀 여러개 연결해 놓아도, 따로 기울기 흐름에 방해받지 않는다고 합니다.
또 vanishing gradient문제 해결하기 위해 GRU라는 것이 나왔는데, LSTM과 형태가 비슷하니 그냥 넘어가도록 하겠다.
감사합니당 ~ 🦾
참고자료
https://www.youtube.com/playlist?list=PL3FW7Lu3i5JvHM8ljYj-zLfQRF3EO8sYv
http://cs231n.stanford.edu/2017/syllabus

좋은 정보 얻어갑니다, 감사합니다.