CS231n
1.CS231n 마라톤 시작

이번 포스팅은 2023년 3월부터 쭈욱 들었던 스탠포드 대학 'CS231n'강의에 대해서 정리하는 내용에 앞서, 제가 어떤 식으로 공부를 진행 했었는지에 대해 말하고자 하는 시간을 가져볼까 합니다.학교 공부와 병행하며, 주 두 강의씩 들었고, 분명 강의는 한개당 대략
2.CS231n Lecture 2 정리

Data-driven(데이터 추진 접근 방법)클래스 분류기거리측정 방식(L1, L2)Setting HyperparametersLinear Classification로 구성이 되어 있습니다.컴퓨터는 이미지를 숫자 조합으로 인식합니다.1\. 최근접 이웃(Nearest Ne
3.CS231n Lecture 3 정리

이번 포스팅은 3강에 대한 포스팅 입니다.3강에서 나온 큼지막한 내용은손실함수(Loss Function)정규화(Regularization)최적화(Optimization)이미지 피쳐(Image Feature)에 대한 내용이었습니다.첫번째로 Hinge Loss입니다. 주로
4.CS231n Lecture4 정리

이번 내용은 역전파(Backpropagation)신경망(Neural Networks)이었습니다.Forward Pass(FP)가 순방향, input값에 의해서 마지막까지 어느 영향을 끼치는가에 대한 것이라면,Backpropagation(역전파)은 FP값을 구하기 위해 '
5.CS231n Lecture 5 정리

오늘 포스팅은 Lecture 5는CNN(Convolution Neural Networks)에 대한 내용이었습니다.앞부분에 신경망의 역사에 대해 나오는데, 1957년 퍼셉트론(Backpropagation) 불가.아다린, 마다린(위에 퍼셉트론 겹겹이 쌓은 것, 동일하게 B
6.CS231n Lecture 6 정리
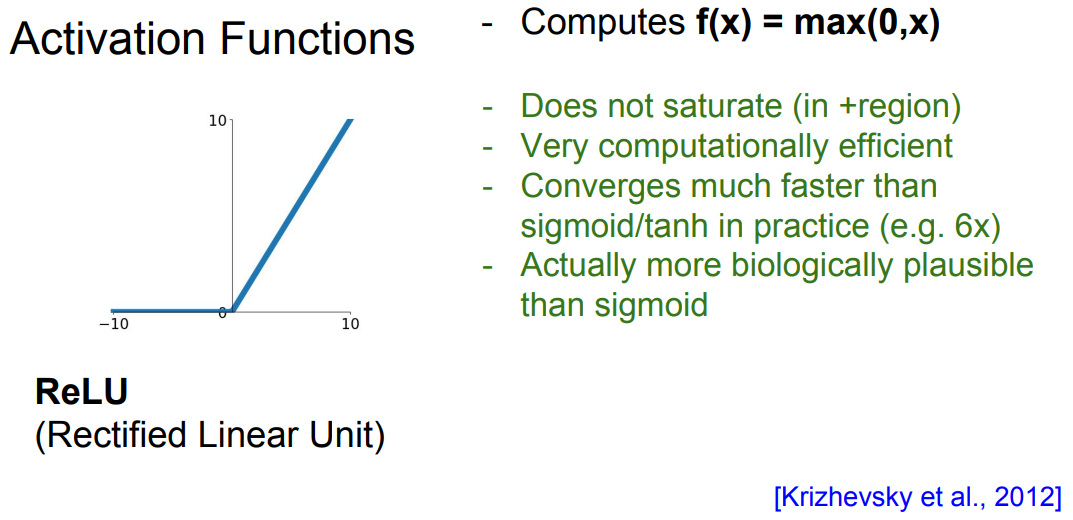
이번 포스팅은 6강에 대한 내용 입니다. 6강에 대한 전체적 내용은 > **1. Activation Functions Data Preprocessing Weight Initialization Batch Normalization Babysitting Learnin
7.CS231n Lecture 7 정리

이번 포스팅은 > **최적화(fancier optimization) 정규화(Regularization) 전이 학습(Transfer Learning)** 에 대한 내용입니다. 앞에 fancier라는 말이 나오는데, 최적화에서 좋은 도구들을 설명해준다. * 최적
8.CS231n Lecture 8 정리

이번 포스팅은 8강, CPU와 GPU의 차이Caffe, Caffe2Theano, TensorFlowTorch, PyTorch에 대한 내용이었습니다.CPU(Central processing unit)는 적은 코어로 처리할 수 있는 작업이 많고,GPU(Graphics pr
9.CS231n Lecture 9 정리 part1

이번 포스팅은 CNN관련 연구에 대한 내용입니다. 1\. AlexNet2\. VGG3\. GoogLeNet4\. ResNet5\. NiN(Network in Network)6\. Wide ResNet7\. ResNeXT8\. Stochastic Depth9\. Dens
10.CS231n Lecture 9 정리 part 2
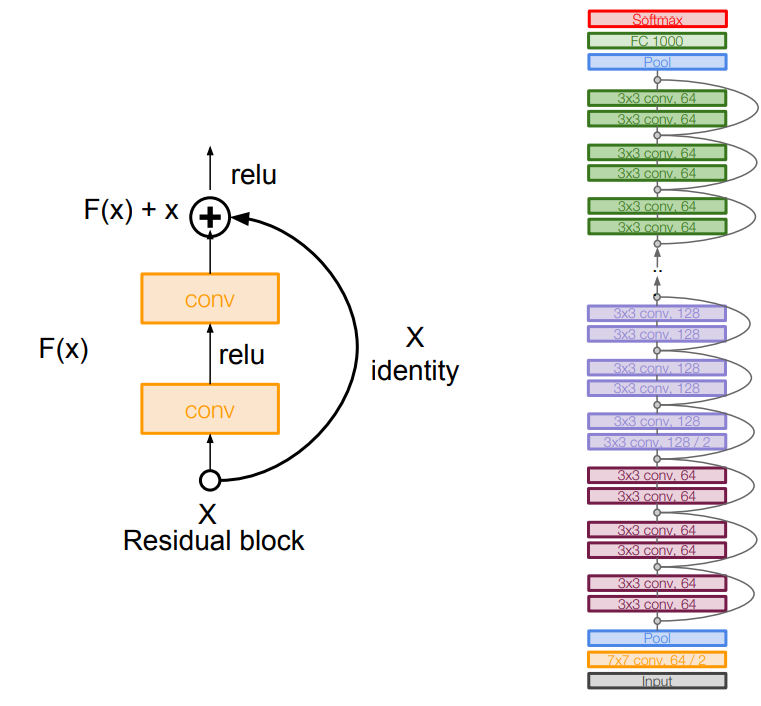
저번 포스팅에 이어서 진행하도록 하겠습니다. ResNet ResNet입니다.전에 나왔던 모델모다 훨씬 더 깊은 계층(152개의 계층)으로 구성이 되어있습니다.이 그림은 각각 20-layer, 56-layer, error값 형태인데, 계층이 더 깊다고 무조건 좋은게 아니
11.CS231n Lecture 10 정리
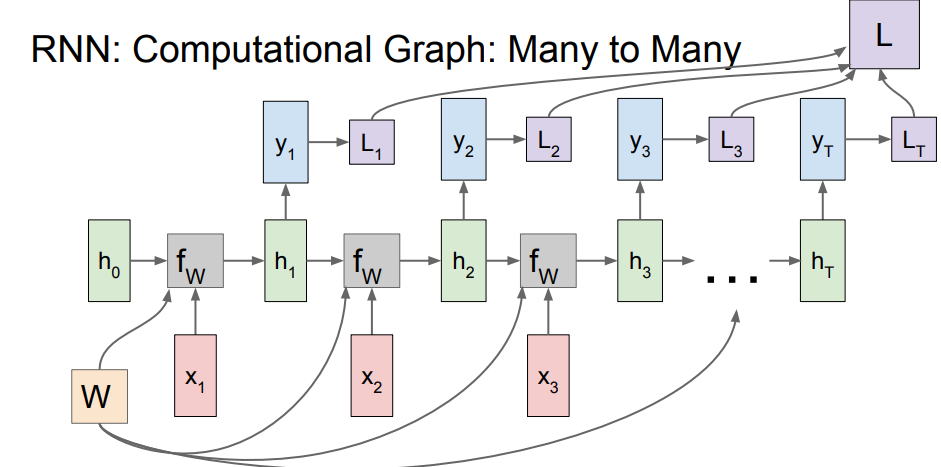
이번 포스팅은 RNN 내용입니다. 순환 신경망(Recurrent Neural Networks)은 시퀀스 데이터(문장, 음성, 시계열)를 처리하는데 사용되는 신경망입니다. 그럼 바로 본론으로 들어가겠습니다. RNN의 작업 과정 모식도 입니다. 첫번째 one t
12.CS231n Lecture 11 정리

오늘은 Segmentation(이미지 분리)Localization(위치 찾기)Detection(탐지)에 관한 내용입니다. Semantic Segmentation 컴퓨터는 각 픽셀을 레이블로 구분합니다.그래서 픽셀만 신경을 써서 오른쪽 그림처럼 소 두마리를 구별 못하는
13.CS231n Lecture12 정리

12강은 활성 layer visualizing의 중요성에 대한 내용입니다. 이 강의에서 말한 시각화의 중요성을 정리하자면, > **딥러닝이 동작하는 이유를 시각적으로 설명하기 위함 딥러닝 내부에서 어떤 동작을 하는지 설명하기 위함** 입니다. Alex
14.CS231n Lecture 13 정리

13강은 비지도 학습(Unsupervised Learning)에 관한 내용입니다.비지도 학습은 이전에 쭈욱 나왔던 지도 학습과 달리, Label(정답)이 따로 존재하지 않는 데이터를 학습하는 방식입니다.그래서 데이터를 무작정 많이 모을 수 있다는 장점을 갖고 있습니다.
15.CS231n Lecture 14 정리

14강은 보강학습(Reinforcement Learning)에 대한 내용입니다.위의 그림과 같이, 어떤 환경에서 agent로 보상을 해주는 형태이고, 이후에 다음 state를 부여하는 형태입니다.여기서 설명한 Reinforcement Learning의 예시로는,카트 위
16.CS231n 마무리

안녕하세요?여기서는 제가 그간 CS231n 강의를 듣고, 정리하면서 느낀 것들을 몇 마디 적으려고 합니다.몇 달동안 귀찮아서 미루고, 피곤하다고 미루고,계속 미루고 미루다가 결국 몇 달만에 CS231n 정리를 끝 마쳤습니다.2강부터 14강까지는 정리를 해서 포스팅을 해