
13강은 비지도 학습(Unsupervised Learning)에 관한 내용입니다.
모르고 삭제 눌러서 두번째 쓰는 거다....
비지도 학습은 이전에 쭈욱 나왔던 지도 학습과 달리, Label(정답)이 따로 존재하지 않는 데이터를 학습하는 방식입니다.
그래서 데이터를 무작정 많이 모을 수 있다는 장점을 갖고 있습니다.
동시에 분류 기준을 알 수 없다는 단점 또한 갖고 있다.
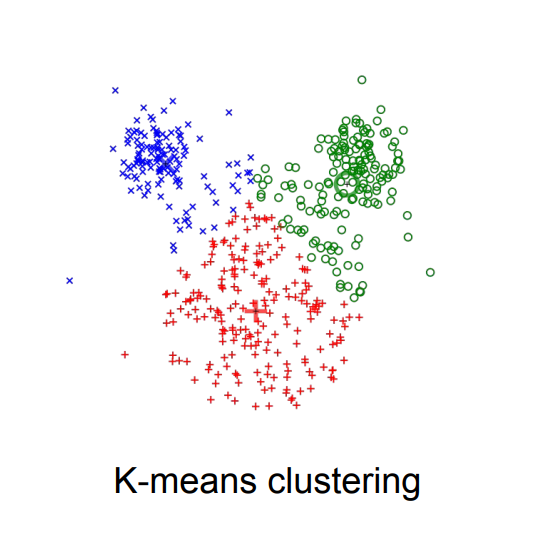
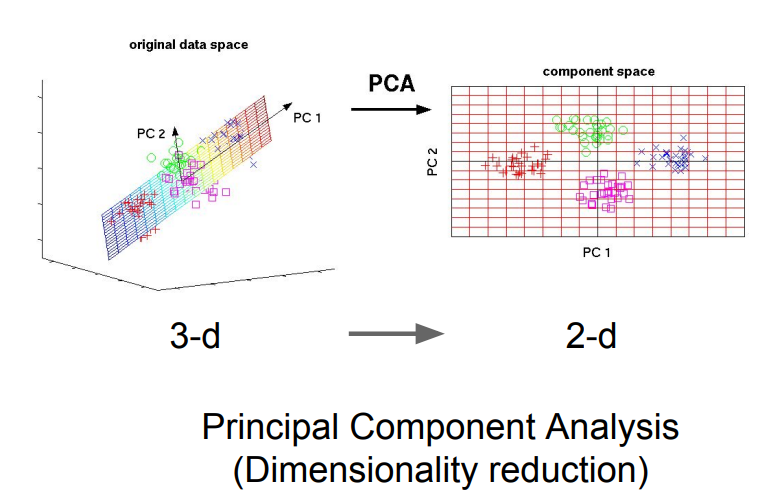
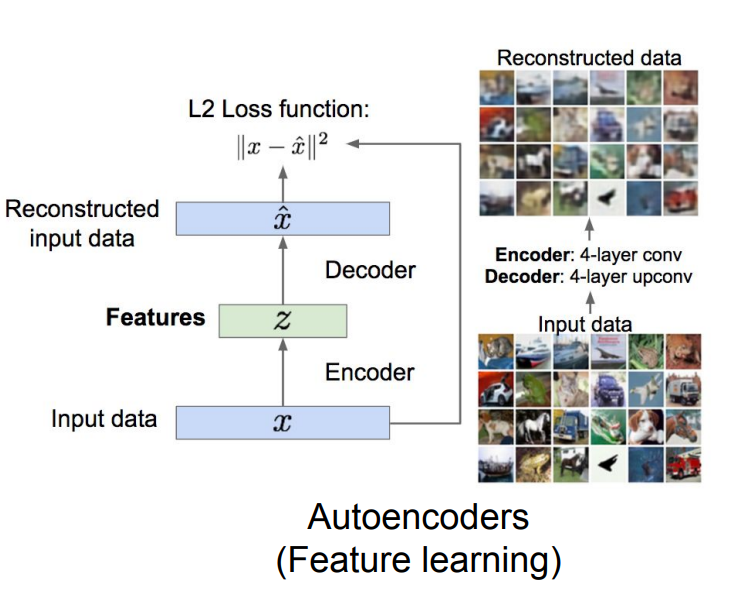
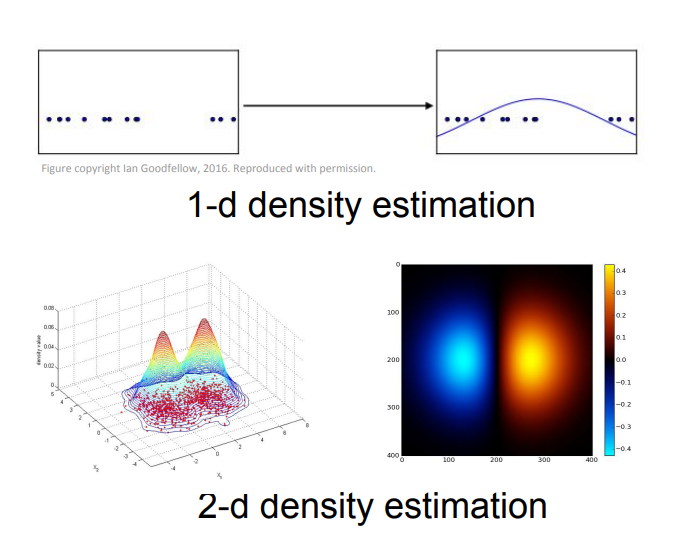
비지도 학습은 크게 4가지로 나뉘는데, 정리하면,
1. Clustering(군집화)
2. Dimensionality Reduction
3. Feature Learning
4. Density Estimation
로 구성이 됩니다.
또한 이 강의에서 생성모델(Generative models)에 대해 자세히 설명을 했는데,
여기서 설명한 Generative Models를 정리하자면,
1. Pixel RNN / CNN
2. Variational Autoencoder
3. GAN
이렇게 총 3가지를 설명했습니다.
정말 너무 어려웠다....
Pixel RNN / CNN
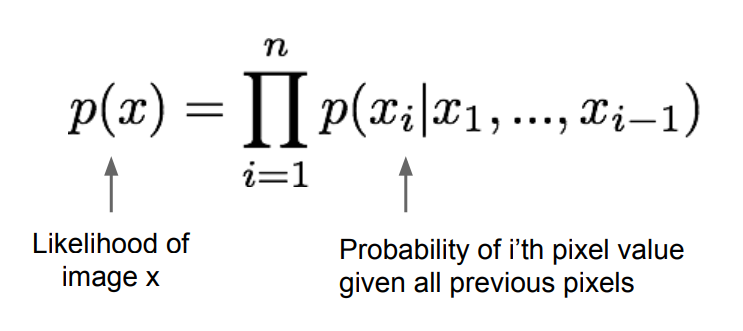
Pixel RNN / CNN은 동일한 확률식이 들어가게 되는데, 위와 같이 조건부 확률 분포를 사용하여 새로운 이미지를 생성합니다.
Pixel RNN
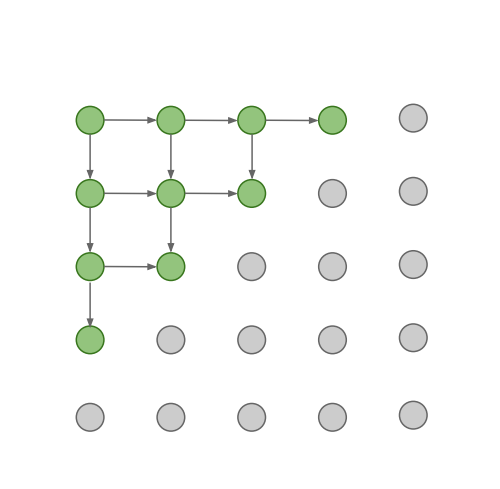
위의 그림은 Pixel RNN의 작동 방식을 잘 설명해주는 그림입니다.
그림에서 알 수 있듯이, 왼쪽 상단에서 부터 시작해, 오른쪽 하단으로 이동하는 순환적인 구조를 가지고 있고, 이전 픽셀값을 이용해서 새로운 픽셀을 생성합니다.
설명에서 유추 가능하듯이, LSTM 방식을 사용합니다.
동그라미 하나하나가 픽셀이라고 보면 되고, 속도가 느리다는 단점을 갖고 있다고 한다.
Pixel CNN
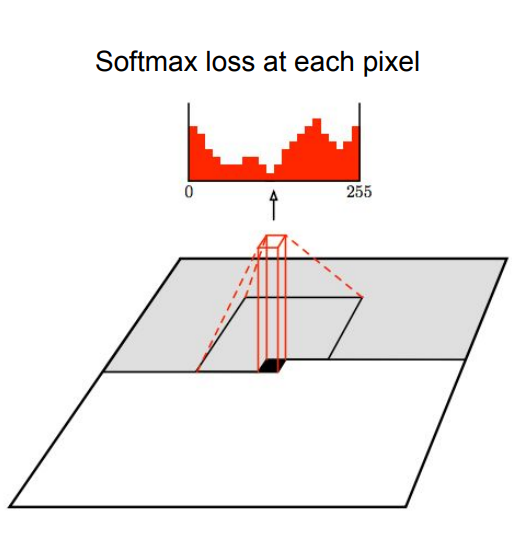
그래서 위의 단점을 보완하기 위해서 나온게, Pixel CNN입니다.
전의 Pixel RNN 방식과 달리, 순환적 구조를 사용하지 않고, 위의 그림과 같이 어떤 공간적 구조를 사용해서 이전 픽셀 정보를 추출, 이를 토대로 현 픽셀의 확률 분포를 예측한다고 합니다.
특정 영역만 사용해서 속도가 더 빠르다고 한다.
Variational Autoencoder
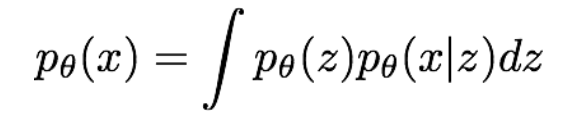
Variational Autoencoder는 줄여서 VAE라고도 부릅니다.
VAE는 앞의 Pixel RNN / CNN의 식처럼 나타내기 불가능해서, 하한선을 구해서 계산 가능한 형태로 바꿔줘야 한다고 합니다.
그래서 나온 식이 위의 식 입니다.
눈에 띄는 점은 Encoder, Decoder라는 개념이 나오는데,
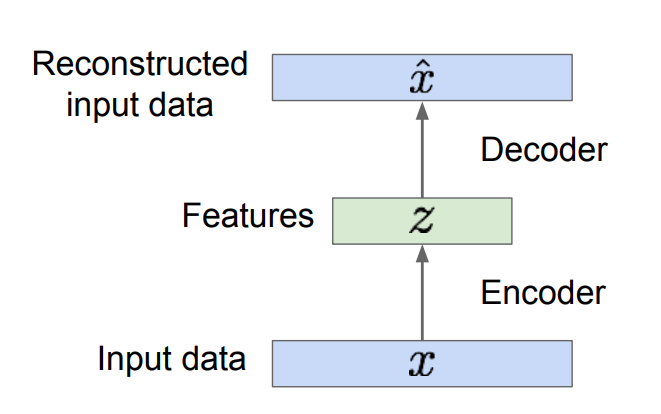
Encoder 파트에서는 input값이 들어오면, Z값을 추출하는 역할을 합니다.
그리고 Decoder 파트에서는 Encoder의 반대 과정이고, 추출된 Z값을 다시 입력 데이터로 구성하게 됩니다.
Sigmoid, FC, ReLU, CNN이야기가 나왔는데, 그냥 딥러닝 코드 구성을 생각하면 될 것 같다.
여기서 무수히 많은 계산식들이 나왔는데,
위의 과정을 위해
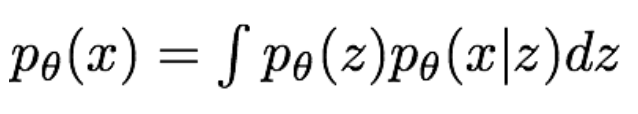
제일 먼저 이 식을 적용하고,
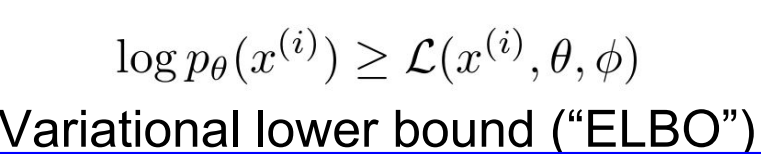
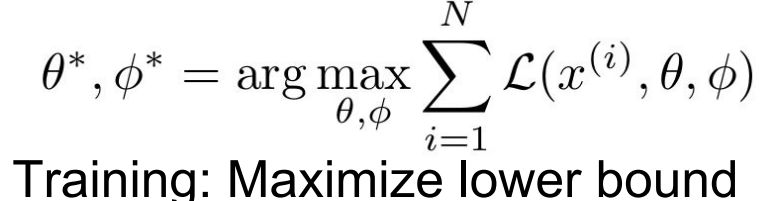
앞의 계산 과정을 거치고, 최종적으로 위의 두개의 식이 나오면,
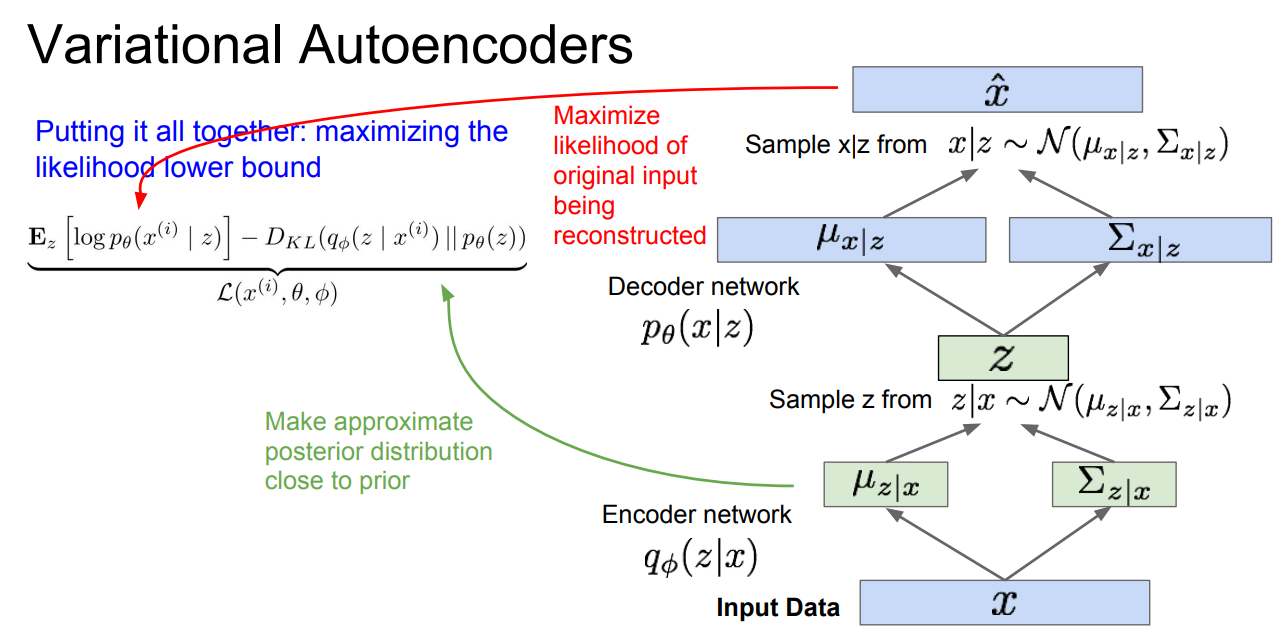
이렇게 최종 training 과정이 구성된다고 합니다.
괴상한 수식이 너무 많이 나와서 자세히 이해하지 못했다. 이정도로 VAE는 넘어가도록 하겠다.
GAN
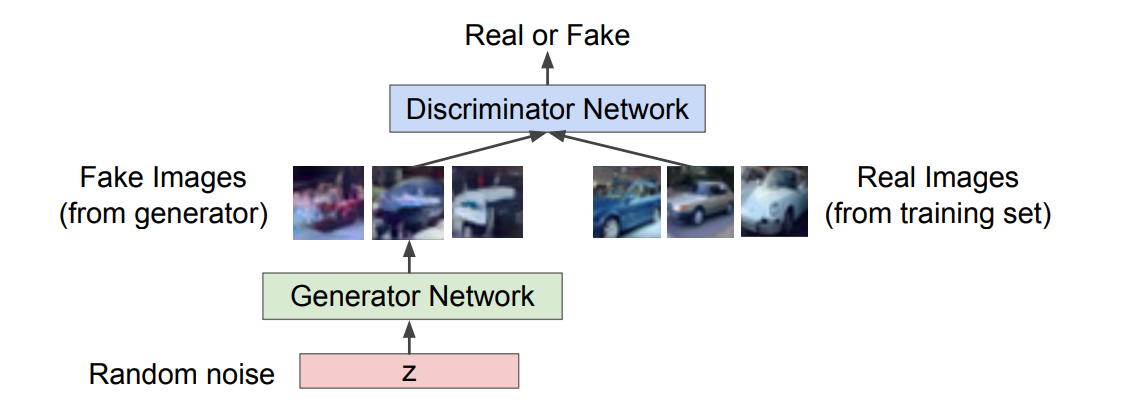
GAN 방식입니다.
위에 처럼 따로 요상한 계산을 거치지 않고, Sample(결과)만 따로 추출하는 아름다운 방식입니다.
여기서는 조금 특이한게, 두개의 신경망으로 구성되는데,
Generator Network(생성자)
Discriminator Network(판별자)
이렇게 두개의 Network로 구성됩니다.
먼저 입력값으로 노이즈 값을 Generator Network가 받게 되는데, 여기서 실제 이미지와 가짜 이미지를 출력하게 됩니다.
그 후에,
Discriminator Network가 Generator Network에서 출력한 결과물을 입력값으로 받게 되고,
출력을 이 입력 이미지가 진짜일 확률값을 뱉게 됩니다.
처음에 어떤 게임을 통해서 더 진짜같은 이미지를 뽑아낸다고 했는데, 그게 Generator Network의 결과물을 뜻하는 것이었다.
여담으로,
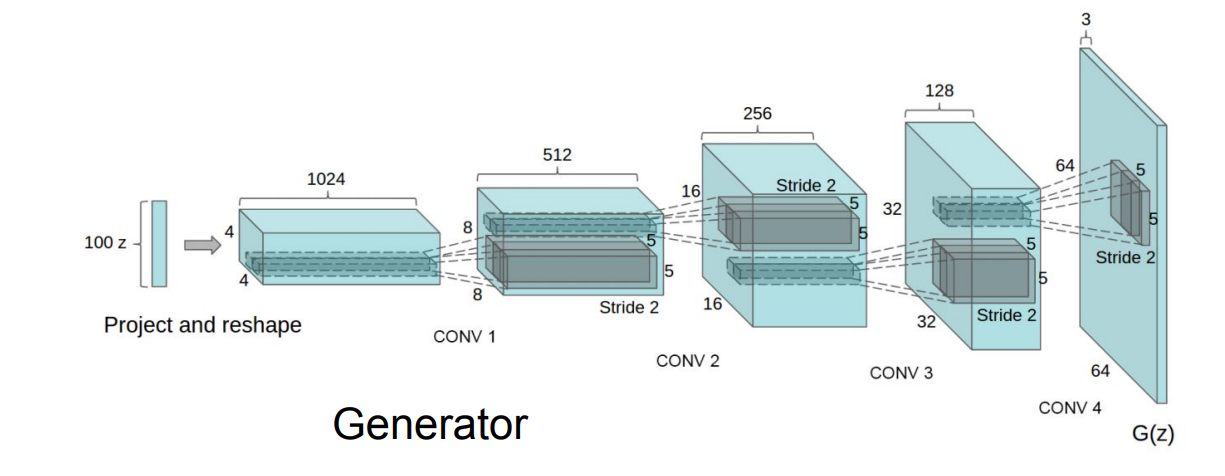
DCGAN이라는 것을 설명했는데, CNN 방식과, 위에서 나온 GAN방식을 섞어서 더더욱 진짜같은 이미지를 뽑아내는 방식이라고 합니다.
Generator, Discriminator 동일하게 존재하는데, 이걸 CNN처럼 더 deep 하게 보낸 구조 정도로만 이해하고 있다.
감사합니당 ~ 🦾
참고자료
https://www.youtube.com/playlist?list=PL3FW7Lu3i5JvHM8ljYj-zLfQRF3EO8sYv
http://cs231n.stanford.edu/2017/syllabus
