
14강은 보강학습(Reinforcement Learning)에 대한 내용입니다.
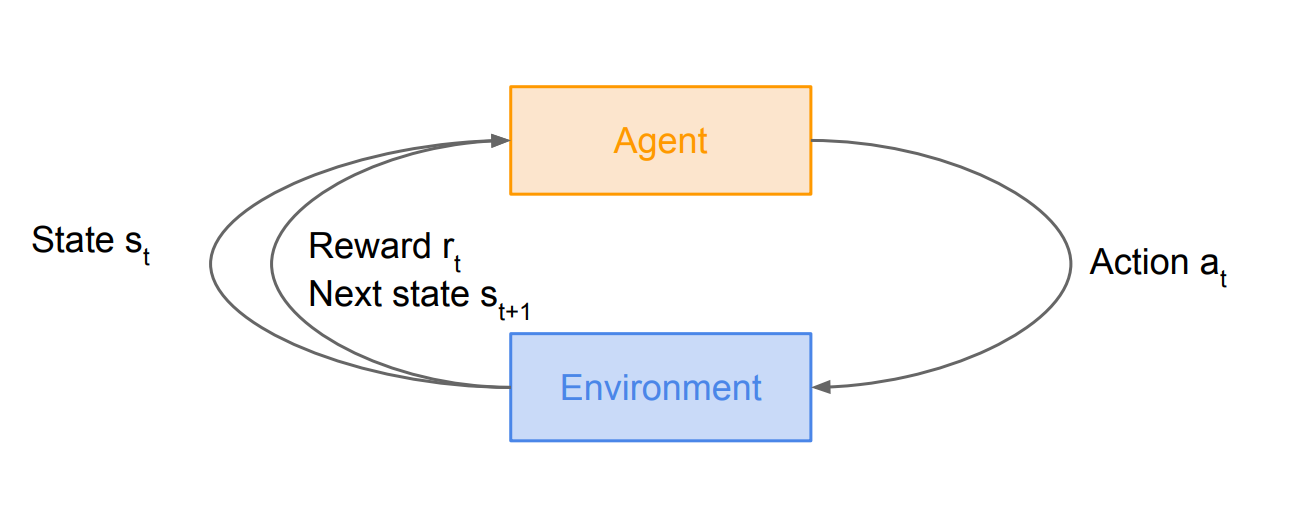
위의 그림과 같이, 어떤 환경에서 agent로 보상을 해주는 형태이고, 이후에 다음 state를 부여하는 형태입니다.
여기서 설명한 Reinforcement Learning의 예시로는,
카트 위에서 균형 잡기
로봇 앞으로 가게 하기
게임 높은 점수로 끝내기
바둑게임
입니다.

그리고, Markov Decision Process(MDP)에 대해서도 간략하게 설명을 했는데, 이는 강화학습법을 수식화 한 것 입니다.
한글로 정리하면,
S: 가능한 상태의 집합
A: 가능한 액션 집합
R: 보상에 대한 분포
P: 다음 상태에 대한 분포(전이 확률)
r: 보상 받는 시간의 중요성
이 됩니다.
누적 보상에 대한 이야기가 나왔는데, 강화 학습은 이를 최대화 하는것이 목표라고 한다.
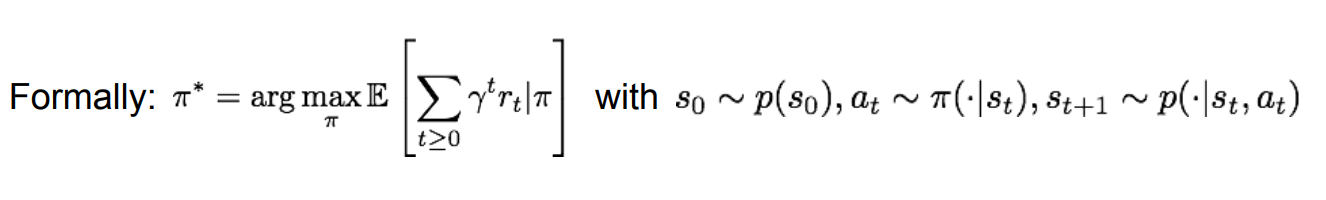
이 식은 MDP를 수식화 한 것이고, 미래 보상들의 합에 기댓값을 최대화 하는 식 입니다.
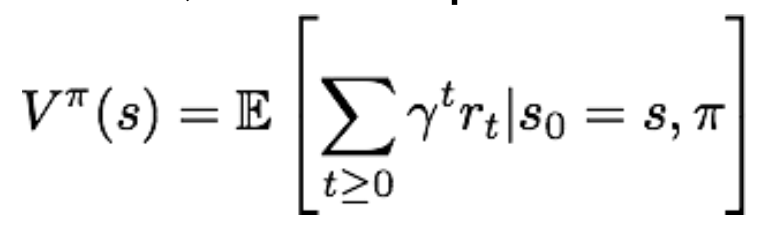
이건 Value Function, 기댓값을 수식화 한 것이고,
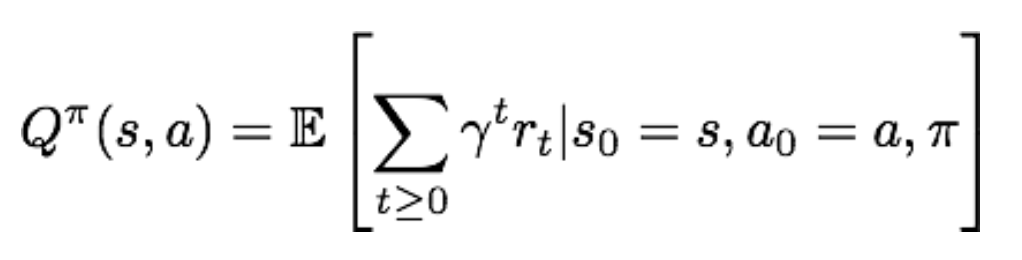
이건 Q-value function으로, 어떤 행동을 해야 가장 좋은지 알려주는 함수 입니다.
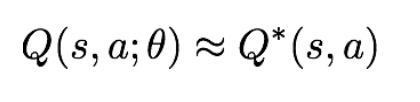
위의 식은 Q-learning에 대한 식인데, Q-value function에서 가장 높은 값을 뽑아내는 것입니다.
또한 Deep Q-learning에 대한 이야기도 했는데, 이는 NN을 써서 Q(s,a)값에 가장 근사하게 하는 것이라고 합니다.
위의 설명을 Atari game에 적용하면,
상태: 게임의 픽셀 전부
행동: 게임의 방향키
보상: 게임 점수
목표: 가장 높은 점수
이 된다고 합니다.
Policy Gradients

Policy Gradients입니다.
위에서도 봤듯이, 함수가 매우 복잡한 Q-learning에서의 문제를 보완한 방식입니다.
상태를 학습하는 것이 아닌, Policy 자체를 학습한다는 차별성을 두고 있습니다.

앞에 여러 설명이 나왔는데, 건너띄고, 위의 식이 Policy Gradients의 최종 식 입니다.
구체적인 값은 몰라(유사값)도 Gradient를 구해서 최적의 정책 찾기가 가능합니다.
문제는 분산값이 높다고 한다.
그래서 이 Variance(분산)값 줄이는 방식을 설명했습니다.
다음과 같습니다.
Variance reduction 1st Idea
현재 스탭에서 종료 시점까지 얻을 수 있는 보상의 sum값 고려.
Variance reduction 2nd Idea
지연된 보상에 '할인률'을 적용한다고 하는데, 미래에 받을 보상과 지금 바로 받을 보상을 구분하는 역할로 보면 됩니다.
Variance reduction 3rd Idea
우리가 얻은 보상이 앞으로 얻을 것이라고 예상했던 것 보다 좋은건지 나쁜건지 판단하는 것이 중요한데, Basline function은 우리가 얼만큼의 보상을 원하는지 설명해주는 함수입니다.
한마디로, 어떤 기준점을 잡는 함수 하나를 더 껴 넣는다고 보면 됩니다.
그리고, 항상 그렇듯이,

Actor-Critic Algorithm에 대해 설명했습니다.
이는 위에서 보았던 Policy Gradient 방식이랑, Q-learning을 조합한 알고리즘이라고 합니다.
여기서 Actor는 Policy로 어떤 상태로 결정할지 정해주는 것이고,
Critic은 Q-function으로 좋은지 나쁜지 판별하고, 어떤 방식으로 조절해 나가야 하는지 결정해 줍니다.
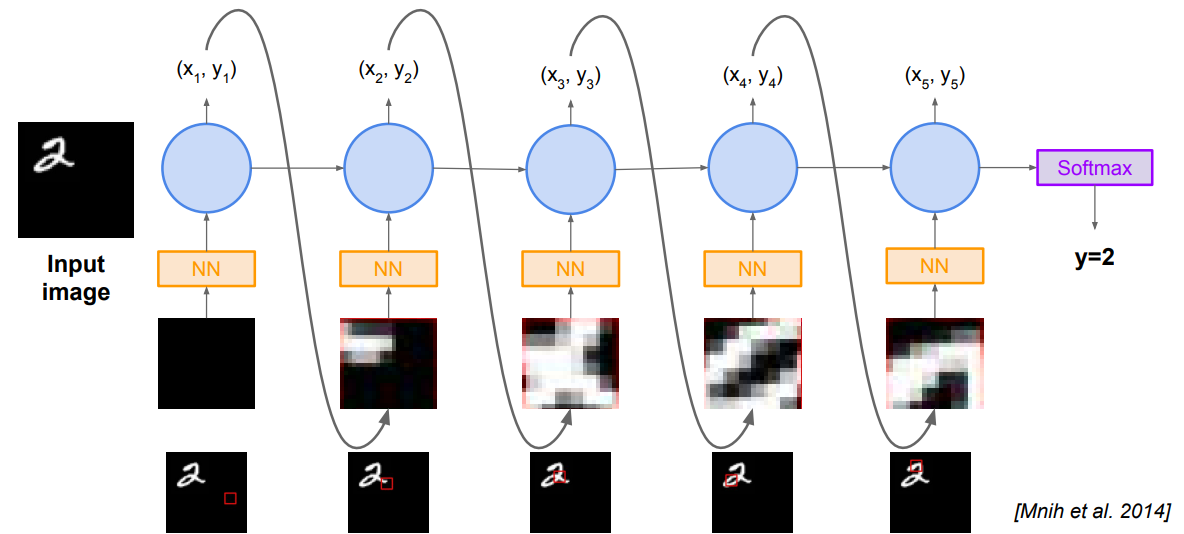
그리고 이런식으로 그간 보았던 RNN을 강화학습에 적용해서도 쓸 수 있다고 합니다.
감사합니당 ~ 🦾
참고자료
https://www.youtube.com/playlist?list=PL3FW7Lu3i5JvHM8ljYj-zLfQRF3EO8sYv
http://cs231n.stanford.edu/2017/syllabus
