
2강은 어려운 부분이 크게 없었습니다.
대략적인 내용은
1. Data-driven(데이터 추진 접근 방법)
2. 클래스 분류기
3. 거리측정 방식(L1, L2)
4. Setting Hyperparameters
5. Linear Classification
로 구성이 되어 있습니다.

컴퓨터는 이미지를 숫자 조합으로 인식합니다.
(위 그림은 카메라가 다른 곳 비추니 픽셀값 바뀐 것 설명하기 위해서 보여준 것이다.)
Data-driven접근 방법에 대한 이야기도 했는데, 첫번째는, 이미지와 레이블로 구성된 데이터셋을 수집, 두번째는, 머신러닝 훈련을 하고,
세번째는 훈련한 것으로 새로운 이미지를 판별하는 것 입니다.
처음에 들었을 때, 생소한 용어여서 뭔가 했더니, 그냥 train하고, test하는 전체적 흐름을 장황하게 설명하는 것이었다....
클래스 분류기에 대한 이야기도 나왔는데,
1. 최근접 이웃(Nearest Neighbor)
2. K-최근접 이웃(K-NearestNeighbors)
이렇게 두가지에 대해 설명하였습니다.
1. 최근접 이웃(Nearest Neighbor)
최근접 이웃(Nearest Neighbor)는 시간복잡도가 train시에 O(1), predict시에는 O(n)입니다.
학습 할 때는 느리고, 예측은 빨라야 하기 때문에, 요새는 많이 사용하지 않는 분류기라고도 첨언 했습니다.
2. k-최근접 이웃(K-NearestNeighbors)
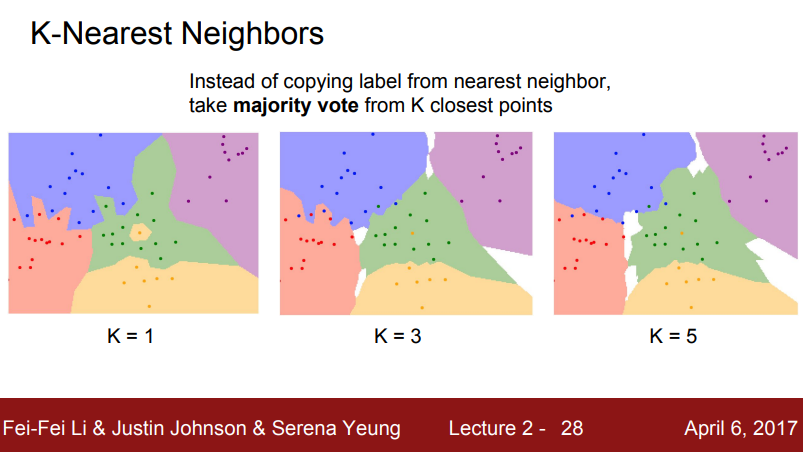
Nearest Neighbor의 취약점을 보완한 분류기 입니다.
위 그림은 K의 숫자가 커지면 커질 수록, 점점 퀄리티가 좋아진다는 것을 뜻합니다. (K는 주변 이웃의 수)
K값을 무조건 높인다고 좋은건 아니다. 상황에 맞춰서, 값 조정하자.
거리측정 방식
L1(Mahatan) distance
L2(유클리드) distance
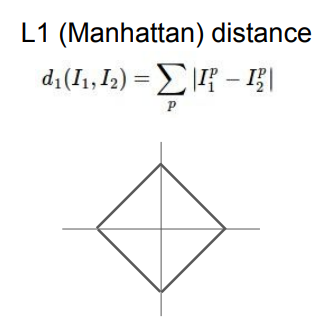
좌표값이 변경되면 거리가 달라지는 특징
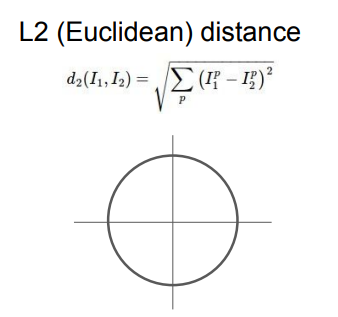
좌표값 변경해도 동일한 특징
(더 자연스럽다)
Setting Hyperparameters
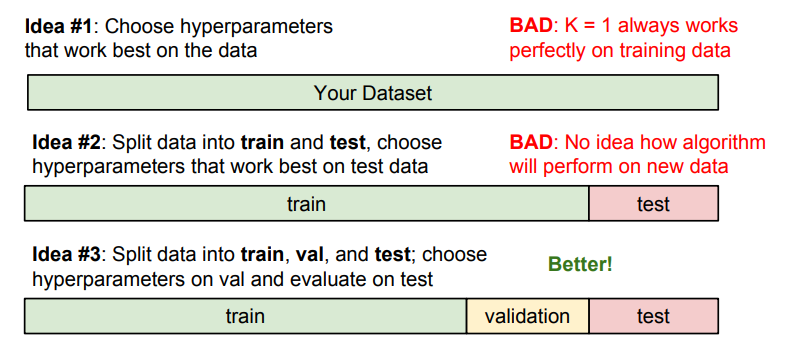
첫번째 방식은 전체 데이터셋에서 train셋, validation셋, test셋으로 분류하는 방식입니다.
검증세트를 중간에 따로 빼놓았기 때문에, overfitting문제를 예방하는데 탁월합니다.
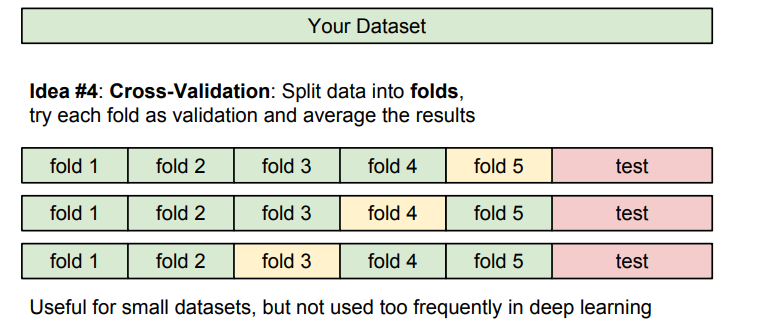
두번째 방식은 Cross-validation(교차검증)방식입니다.
그림에서도 볼 수 있듯이, train셋, test셋 사이에 동일하게 검증셋을 껴넣고, fold하는 방식을 사용합니다.
하지만 딥러닝에서는 시간이 너무 오래 걸리는 문제 때문에, 잘 사용을 안한다고 합니다.
그리고 K-NearestNeighbors방식은 이미지에 잘 사용하지 않는데,
- 사진 여러개 분류 후, L2거리 계산한 결과, distance 똑같이 나옴.
- 이미지는 너무 많은 데이터로 이루어져 있기 때문에, 차원의 저주(curse of dimensionality)에 빠질 위험성.
이 두가지 이유로 이미지에는 잘 사용하지 않는 분류기 입니다.
Linear Classification
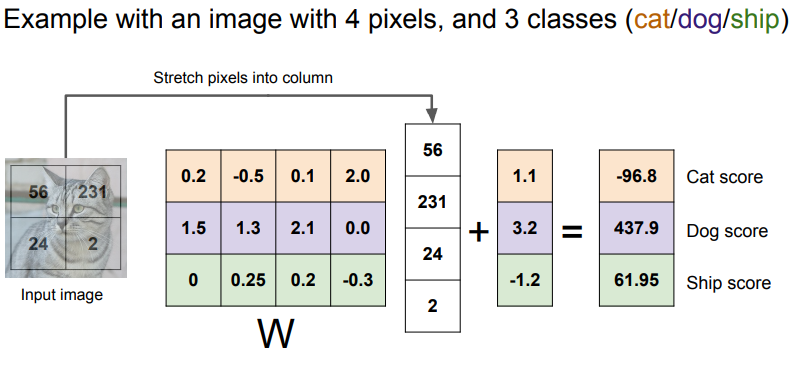
선형 분류는 위의 식처럼 계산이 되는데,
행렬 계산으로 추정값이 나오게 됩니다.
0.2*56 + (-0.5)*231 + 0.1*24 + 2.0*2 = 1.1
이렇게 쭉 계산하고, 뒤에 + 있는 것을 더해주면 최종 Score가 나오게 됩니다.
컴퓨터에서는 이미지를 1차원 형태로 변형하고, 연산을 한다.
Linear Classification은 분류를 어려워 하는 경우가 있습니다.
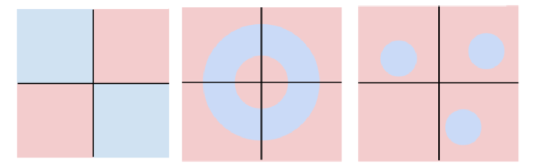
대표적으로 위와 같이 3가지 경우가 있고, 이유를 정리하자면 다음과 같습니다.
1: 선(결정 영역: Decision Region)을 그릴 방법이 없음
2 (동등성 parity): 선형분류기는 픽셀 단위로 세서, 홀수,짝수 구분이 어려움
3 (멀티모드 multi modes): 경계를 그릴 수 있는 방법이 모호
감사합니당 ~ 🦾
참고자료
https://www.youtube.com/playlist?list=PL3FW7Lu3i5JvHM8ljYj-zLfQRF3EO8sYv
http://cs231n.stanford.edu/2017/syllabus
