
이번 포스팅은 3강에 대한 내용 입니다.
3강에서 나온 큼지막한 내용은
손실함수(Loss Function)
정규화(Regularization)
최적화(Optimization)
이미지 피쳐(Image Feature)
에 대한 내용이었습니다.

첫번째로 Hinge Loss입니다. 주로 SVM(서포트 벡터 머신)에 사용되는 손실함수 입니다.
SVM은 지도 학습 모델 중 하나, 분류, 회귀에 사용됩니다.
위의 식을 보면 max 함수가 사용된 것을 알 수 있는데,
총 3개의 측정값이 있다고 하면, S_y_i에 기준이 되는 측정값, S_j에 나머지 2개의 측정값을 넣고, 최대값을 뽑은 후, 전부 sum 해주면, 손실에 대한 값이 나오게 됩니다.
그리고 Softmax함수도 나왔습니다.
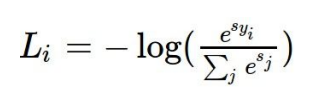
똑같은 손실함수 이며, -log값을 최소화 하는것이 목적입니다.
모든 확률값을 더하면 '1'이 되는 특징을 갖고 있습니다.
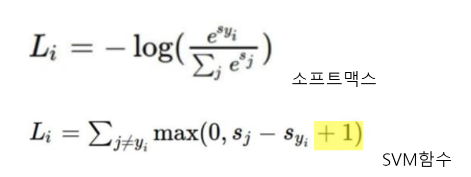
두 손실함수의 차이에 대해 고민을 하게 되었는데, SVM함수는 뒤에 '+1'이라는 마진 값이 있어서, 변화에 크게 민감하지 않고,
반대로 소프트맥스 함수는 모든 레이블을 다 보기 때문에, 매우 민감하다고 합니다.
정규화(Regularization)
정규화는 어떤 그래프를 그렸을 때, 그 그래프가 구불구불 하면, 좋지 않습니다.
overfitting을 말하는 것 같다.
직선 그래프(단순 그래프)로 예측하는게 더 좋은데, 이렇게 만드는 과정을 'Regularization'입니다.
수식을 보면,
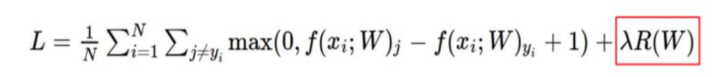
이렇게 구성이 되어 있습니다.
위에 빨간 네모(정규화 손실)를 제외하면, SVM손실 함수와 굉장히 유사한데, 이 두개가 충돌하면서, 최적의 값을 찾는 내용의 식 입니다.
최적화(Optimization)
최적화의 나쁜 예시 두가지를 들었는데,
1. 랜덤 탐색(Random Search)
2. 경사 따라가기(Follow the slope)
이렇게 두가지의 안 좋은 예시가 있습니다.
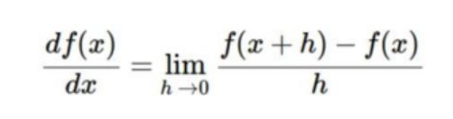
위의 식은 단순 미분식 인데, 기울기를 구하려면 미분을 하는게 맞습니다.
근데 이것은 매우 근사한 값에 지나지 않고, test시에 매우 느리다는 단점을 가지고 있습니다.
loss값을 구하는게 중요한데, 위의 미분은 W(가중치, 파라미터)의 함수에 지나지 않는다.
그래서 아래와 같은 Gradient 나왔습니다.
수치적 경사(Numerical gradient): 대략적, 느림, 작성하기 쉬움
분석적 경사(Analytic gradient): 정확, 빠름, 오류 발생 확률 높음
위와 같은 각각의 단점, 장점을 잘 활용하기 위해 두가지 방식을 잘 섞어서 쓴다고 합니다.
처음에는 'Numerical gradient' 쓰다가 정확한 검토 할 때는 'Analytic gradient'
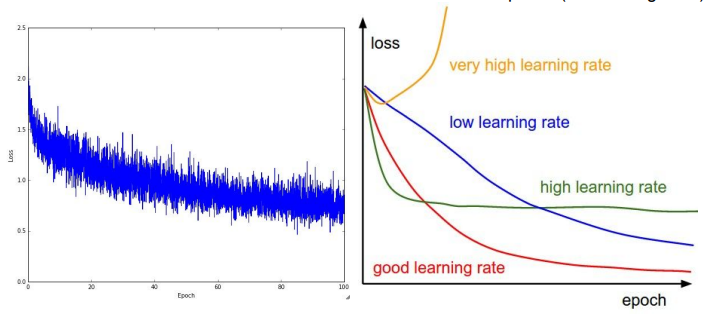
그리고 위 그래프가 강의자료에 있었는데, learning_rate에 따른 loss값 비교를 한눈에 알아 볼 수 있습니다.
epoch값이 증가할수록, loss값 또한 증가하면, learning_rate가 매우 높은것, epoch값 증가할수록, loss값 이쁘게 내려가면, 적당한 learning_rate.
근데 보통 계층 어떻게 설계하느냐에 따라서 learning_rate 높이자, 줄이자 하는 말이 나오는 것 같다.
Mini-batch Gradient Descent
Mini-batch Gradient Descent는 나눠 놓은 train세트 중, 일부만 뽑아서 쓰는 방식 입니다.
Full-batch는 그냥 train셋 전부 다 쓰는 것. 그냥 이거 반대로 생각하자.
미니배치 사이즈는 그 환경에 맞춰서 쓰면 된다고 합니다.
다만, 이렇게 하면 단기간에 노이즈가 쫌 생기는데, 장기적으로 보면 loss값이 서서히 내려가서 좋은 방식이라고 합니다.
Image Features
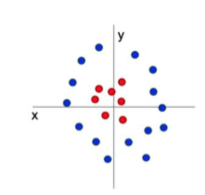
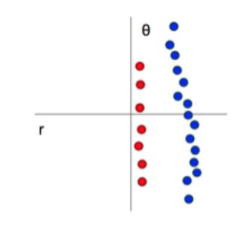
이미지 피쳐 방식도 간단하게 설명을 했습니다.
Linear Classifier(선형 분류기)를 사용하긴 하는데,
이걸 바로 사용하면 큰일나고,
1. 픽셀 추출
2. 각각의 픽셀을 Linear Classifier(선형 분류기)에 넣기
3. 이렇게 뱉은 계산값 하나로 합치기
4. 다시 Linear Classifier(선형 분류기)
이런 과정을 거쳐야한다고 합니다.
당연하게, 위에 원 모양 scatter는... 그래프 그리는게 굉장히 까다롭기 때문이다.
몇가지 예시를 들어줬는데,
1. 색 히스토그램(Color Histogram)
2. Histogram of Oriented Gradients(HoG)
3. Bag of words
이미지에서 사용하는 방식이 이렇게 있다고 합니다.
시간이 흐름에 따라, Color Histogram -> HoG -> Bag of words 방식으로 발전했다고 합니다.
감사합니당 ~ 🦾
참고자료
https://www.youtube.com/playlist?list=PL3FW7Lu3i5JvHM8ljYj-zLfQRF3EO8sYv
http://cs231n.stanford.edu/2017/syllabus
