
이번 포스팅은
최적화(fancier optimization)
정규화(Regularization)
전이 학습(Transfer Learning)
에 대한 내용입니다.
앞에 fancier라는 말이 나오는데, 최적화에서 좋은 도구들을 설명해준다.
최적화(fancier optimization)
SGD(Stochastic Gradient Descent)
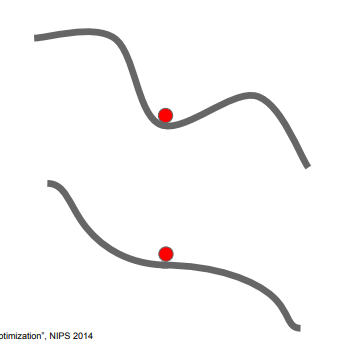
위 그림은 확률적 경사하강법에 대한 그림 입니다.
SGD란, 위의 선을 훑고 내려가면서 최적의 파라미터 값 θ를 찾는 것입니다.
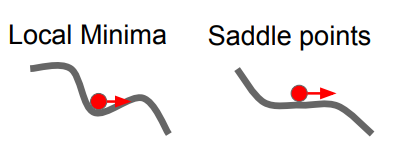
위 그림은 과연 두개의 손실 함수 중에서 지역 최솟값(Local minima)과 안착점(saddle point) 중에서 과연 손실 함수 형태가 더 좋은지에 대한 이야기 입니다.
위 그래프(1번째 그림)는 기울기가 0(경사가 0)인 곳에서 멈추게 되고, 시간도 오래 걸리기 때문에 별로 좋지 않다고 합니다.
옛날에 만들어진 것 이어서, 지역 최솟값에 빠질 위험성이 있다는 것으로 이해했다.
SGD + 모멘텀
위 그림은 똑같은 느낌인데, 공에 단순 방향성이 아닌, 속도를 껴넣은 느낌입니다.
속도의 방향으로 가기 때문에, 극소값에 멈추지 않는다는 특징이 있습니다.

코드로 구현하면 이렇게 됩니다.
도통 어디가 Velocity를 의미하는지 잘 모르겠다. 나중에 쓸일 있음 갖다 쓰자.
Nesterov Momentum
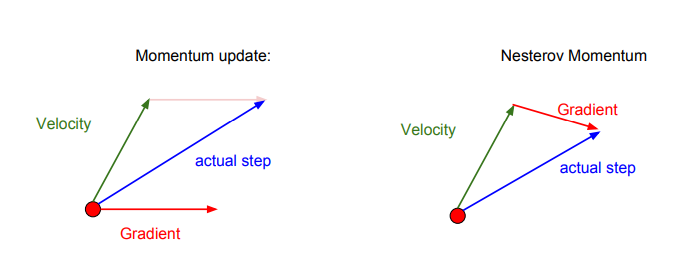
위에서 모았던 것에 좀 더 진보된 이야기 입니다.
나름 최신의 모멘텀을 설명해줬는데, 그게 Nesterov 입니다.
속도와 기울기를 어떤 벡터 형태로 나타내면, Nesterov가 확실히 더 짧은 기울기를 갖고 있습니다.
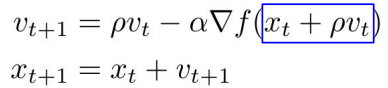
또한 Nesterov를 수식으로 표현하면, 위와 같이 나타나는데, 이 파란 박스안의 식이 현재 속도와 이전 속도 사이의 오류를 수정하는 항 입니다.
SGD, SGD+Momentum보다 속도는 느리지만, '오버슈팅' 동작이 최소화 됩니다.
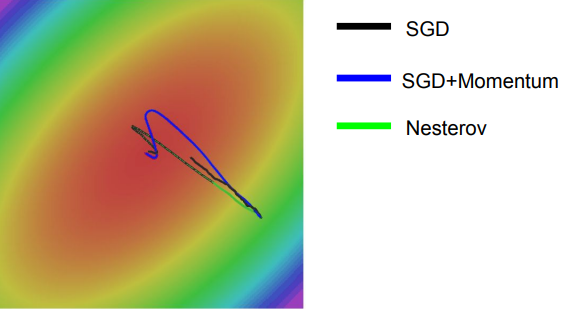
오버 슈팅은 어떤 목적지까지 갈 때, 더 먼 경로로 가는 것이다.
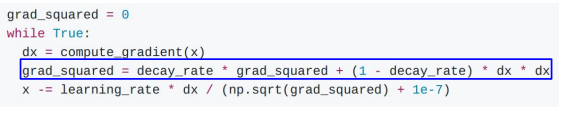
AdaGrad

AdaGrad를 코드로 나타내면 이렇게 구현이 됩니다.
빨간 박스가 쳐져있는 grad_squared가 계속해서 합산되는 형태인데, 이게 업데이트를 할수록, 점점 느려지게 됩니다.
RMSProp
AdaGrad의 속도 느려지는 부분을 보완했습니다.
grad_Squared부분이 바뀐 것을 확인할 수 있습니다.
Adam
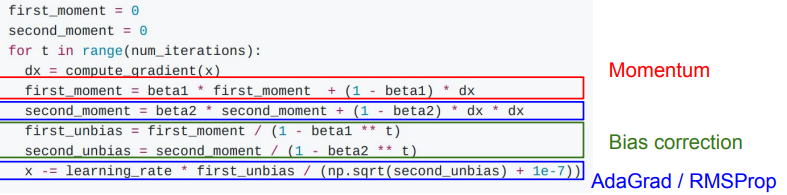
그간 보았던, SGD Momentum, Adagrad, RMSProp을 합친 형태 입니다.
위에 변수 두개를 0으로 고정하는 이유가, 시작때 부터 크게 움직이는 걸 막기 위함 입니다.
최적 파라미터 값 찾는데, 처음부터 확확 움직이면 안착점 찾는데 시간이 더 오래 걸린다. 못 찾을수도?
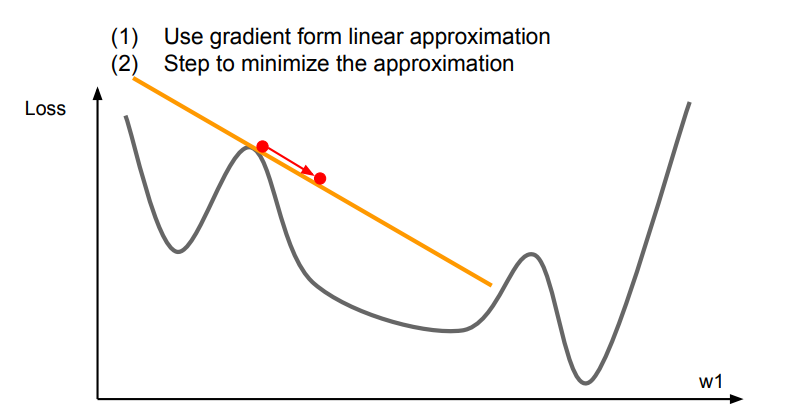
위 그래프는 가장 기본적인 경사(미분값)을 나타냅니다. 1차 함수여서 1차 최적화 라는 말을 사용합니다.
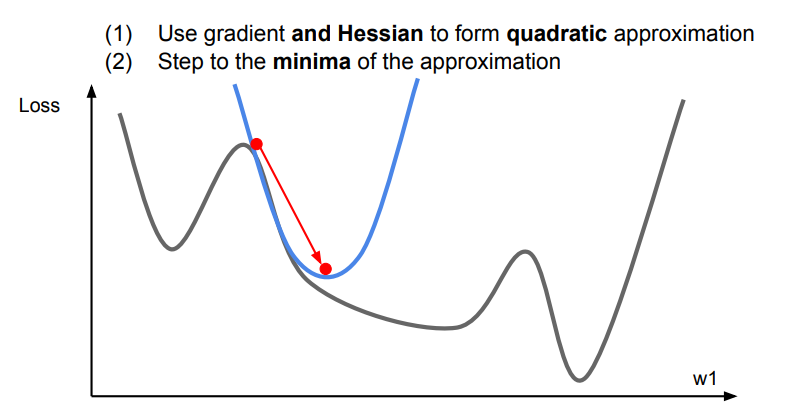
위 그래프는 2차 함수여서 2차 최적화 라는 말을 사용했습니다.
이 2차 최적화에는
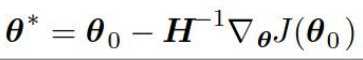
뉴런 스텝(다차원 2차 최적화에 사용)이 적용되는데, 위 함수에 학습률이 존재하지 않고, 매 step마다 최소의 step으로 나아갑니다.
다만, O(N^2)의 원소를 갖고, O(N^3) 역행렬 시간이 걸리기 때문에, 딥러닝에서는 사용을 잘 안합니다.
그리고 슥 지나가는 느낌으로 BFGS, L-BFGS를 설명을 했습니다.
BFGS는 제한 조건 없는 함수에서 x값을 최소화 시키는 것인데, 여기서 뉴턴 방법을 사용한다고 합니다. 역행렬을 만드는 대신, 1로 업데이트하는 방식이라고 합니다.
또한 L-BFGS는 제한된 BFGS라고 설명했는데, 역행렬을 전체 생성하거나, 저장 자체를 안하는 방식이라고 합니다.
보통 Adam을 일반적으로 많이 사용하고, full-batch할 수 있으면,L-BFGS를 사용하자.
모델 앙상블(Model Ensembles)
모델 앙상블 구현 코드입니다.
모델 앙상블은 하나의 모델을, 여러 개로 조화롭게 학습을 하는 기법입니다.
여러 모델 예측값의 평균을 내는 방식이다.
훈련 과정에서 여러 snapshot 갖고 있다가 앙상블로 활용합니다.
그리고 train동안에 이 앙상블(학습 내용)을 계속 갖고 있기 때문에 참 좋은 방식입니다.
정규화(Regularization)
정규화는 모델에 제약을 주는 것 입니다.
train 데이터에 완전히 학습되면, 과적합에 빠질 가능성이 매우 높습니다. 이를 방지하기 위해 사용하는 방법이 정규화 입니다.
드롭아웃
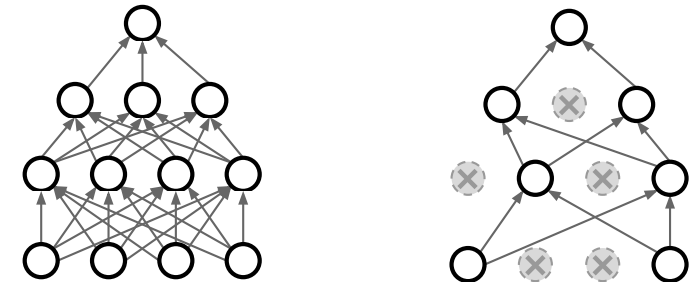
흔히 볼 수 있었던, 드롭아웃 그림입니다.
순전파(forward pass)할 때, 임의의 뉴런들을 0으로 설정해서 계층을 몇개 뺀것과 같은 효과를 내는 방식 입니다.

드롭아웃 구현 코드 입니다.
프레임워크 쓰면, 보통 한 줄에 끝난다.
드롭아웃을 사용하는 이유는
1. 과적합 해결
2. 모델 내부에서 앙상블을 하고 있음
로 정의할 수 있습니다.

맨 위의 식에 ∫(인테그랄)식이 나옵니다. 이는 드랍아웃 자연계 수학 식인데, 이 값을 그냥 가지고 컴퓨터 연산을 하면, 시간이 오래 걸립니다.
그래서 아래의 E[a] = 1/4블라블라 식이 나왔습니다.
test했을 때의 출력값과, train시의 기대값이 같아야 합니다.
데이터 증강(data augementation)
데이터 증강은 CNN에서 train 중에 이미지를 변형하는 것을 의미합니다.
데이터 증강 예시로는
1. 고양이 사진 좌우 반전, 구역별로 짜르고 그걸 모아다가 평균


2. 밝기 변경 후, 각 색들을 샘플링, 그리고 이걸 다 SUM

이 방식은 어려워서 잘 안 쓴다고 한다.
드랍커넥트(DropConnect)
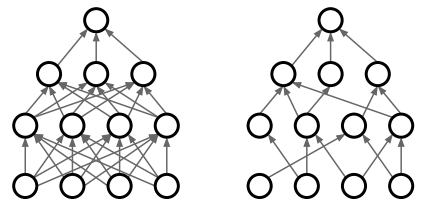
형태는 드랍아웃 형태와 비슷한데, 활성값을 0으로 만들어버리는게 아닌, 행렬값의 일부를 0으로 만드는 형태입니다.
Fractional Max Pooling
보통 맥스 풀링을 거친다고 하면, 각 구역에서 최댓값을 뽑아내는 것인데, 이 Fractional 맥스 풀링은, 이 지역이 임의로 지정하게 됩니다.
Stochastic depth
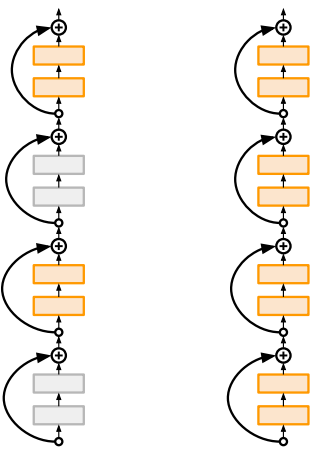
train중에 계층들을 확률적으로(임의로) 드랍하고, test시에는 계층 전부를 사용하는 방식입니다.
설명해주는 대학원생이 극찬했다.
전이 학습(transfor Learning)
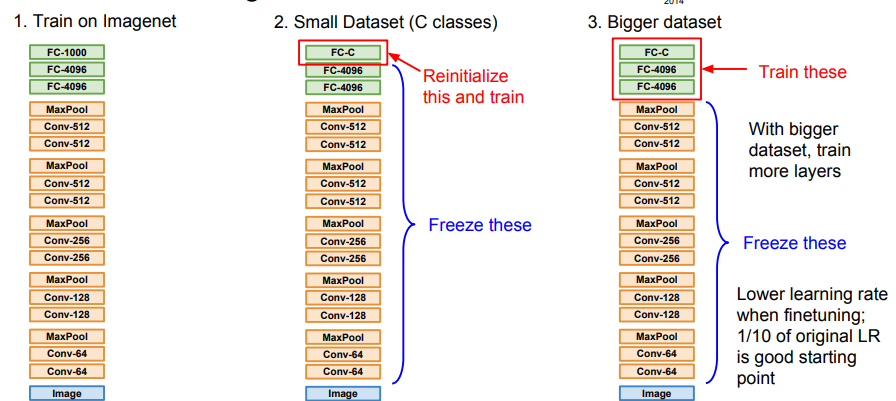
위의 그림은 전이학습을 표현하는 그림입니다.
전이학습은 어떤 데이터셋을 학습한 후, 그 학습한 가중치의 일부를 새로운 데이터셋에서 다시 학습하는 것을 말합니다.
데이터셋이 크면 클수록, 기존에 학습해야 하는 데이터셋을 크게 해야합니다.
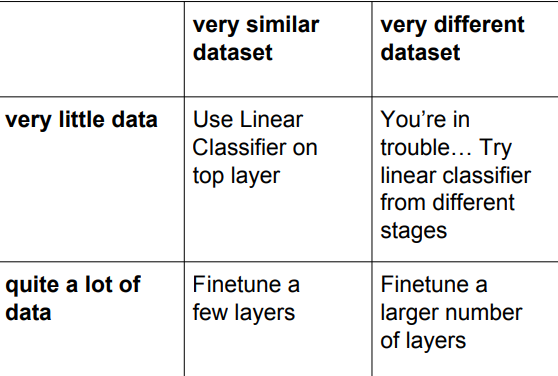
전이학습 꿀팁으로,
1. 작고 비슷한 데이터 셋: 맨 위 계층에서 선형분류기 적용
2. 많고 비슷한 데이터 셋: 몇개 계층 미세조정
3. 작고 다른 데이터셋: 이것저것 다 선형 분류기 적용해보기.
4. 많고 다른 데이터셋: 더 많은 계층 미세조정
이렇게 설명을 했습니다.
CNN에서 많이 사용한다고 한다.
감사합니당 ~ 🦾
참고자료
https://www.youtube.com/playlist?list=PL3FW7Lu3i5JvHM8ljYj-zLfQRF3EO8sYv
http://cs231n.stanford.edu/2017/syllabus

가치 있는 정보 공유해주셔서 감사합니다.