
이번 포스팅은 6강에 대한 내용 입니다.
6강에 대한 전체적 내용은
1. Activation Functions
2. Data Preprocessing
3. Weight Initialization
4. Batch Normalization
5. Babysitting Learning Process
6. Hyperparameter Optimization
이렇게 총 6가지 였습니다.
Activation Functions

저번에 나왔던 6가지 Activaiton Function에 대해 자세하게 다루었습니다.

위 함수는 Sigmoid 함수이고, 음수로 내려가는 값이 아닌, 0 ~ 1사이의 범위로 숫자를 밀어넣습니다.
그래프를 보면, 0 중심이 아니며, exp계산 때문에, 시간이 오래 걸린다는 문제가 있습니다.
이 6개 중에서는 가장 오래된 함수이다.

위의 함수는 tanh함수입니다. sigmoid와 다르게 -1 ~ 1값의 범위를 갖고, 0을 중심으로 갖는 것을 확인할 수 있습니다.
하지만 기울기를 죽이는 문제는 그래프를 보아하면 똑같이 알 수 있습니다.
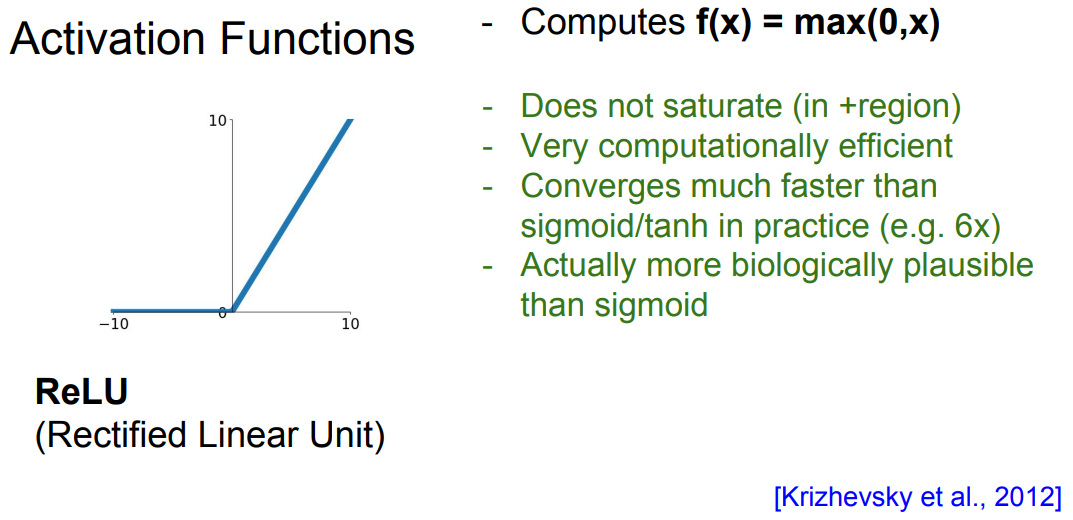
잘 알고 있는 ReLU함수 입니다.
y축 0 이상의 값에서 x축에 평행하게 그려지지 않아(포화되지 않아) 계산할 때 효과적입니다.
또한 sigmoid, tanh보다 훨씬 빠르고, 현실과 더 잘 맞습니다.
다만 0줌심으로 출력하지 않고, y축 음수 방향은 버리는 경향이 있기 때문에, 데이터 전부를 고려하지 못한다는 단점이 있습니다.

다음은 Leaky ReLU함수 입니다.
x축 y축에 평행하지 않고,(포화되지 않음), 계산할때 매우 효과적이라고 합니다.
위에와 동일하게, sigmoid, tanh보다 훨씬 빠르고, 기울기가 죽는 문제를 개선했습니다.
또한 RPeLU에 대한 언급을 했는데, 이는 이름에서 알 수 있듯이, 좀 더 진보된 ReLU함수라고 생각하면 됩니다.
0.01로 상수값을 고정시킨게 아닌, 알파값으로 둬서 훨씬 더 유연합니다.

다음은 ELU함수 입니다.
ReLU함수의 좋은점만 갖고온 함수 입니다.
평균 출력이 0에 가깝고, Leaky ReLU보다 음의 방향쪽에 포화 영역이 있어, 좀 더 견고합니다.
다만, exp계산이 들어가서, 시간이 더 오래걸립니다.
ReLU와 비교를 많이 하게 되는데, 가장 표본이 되는 활성화 함수가 ReLU여서 그러려니 한다.
그리고 exp들어가면 시간이 오래 걸린다고 하는데, 계속해서 상수값을 제곱하는 형태이기 때문에, 그런듯 하다(아마?)

그리고 그간 들어본적 없는 Maxout함수에 대해 언급했습니다.
계산식을 보면, ReLU와 Leaky ReLU를 섞은 형태이고, 기존에 언급했던 함수보다 좀 더 진보된 형태 입니다.
포화되지 않는다는 특징을 갖고 있고, 그래프를 그려보면 선형적이라고 합니다.
보통 활성화 함수로 ReLU를 가장 많이 쓰고, Leaky ReLU, Maxout, ELU, tanh 이것저것 실험해보는 것이 좋다고 한다.
Sigmoid는 별로라고 하는데.. 왜...? 나는 자주 사용한다.
Data Preprocessing(데이터 전처리)
머신러닝에서는 PCA, 화이트닝이 자주 쓰이는 것을 확인할 수 있습니다.
이미지(영상)에서는 이걸 사용하기 매우 까다롭다.
그래서 이미지에는 아래와 같은 기법이 사용됩니다.
평균 이미지 뺴기(AlexNet)
채널당 편균 빼기(VGGNet)
연구 방식은 너무 간략하게 설명했다. 다음에 매우 자세히 나오니 그냥 넘어가겠다.
Weight Initialization

위 코드는 난수 설정하는 코드인데, random해서 딥러닝에서 문제 발생 가능성이 큽니다.
난수 생성값 0.01
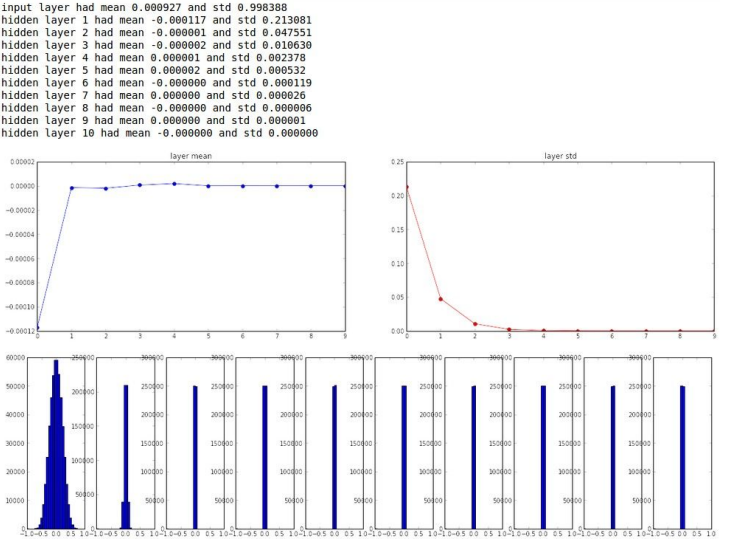
결국엔 0으로 줄어드는 것을 확인 할 수 있습니다.
난수 생성값 1.0
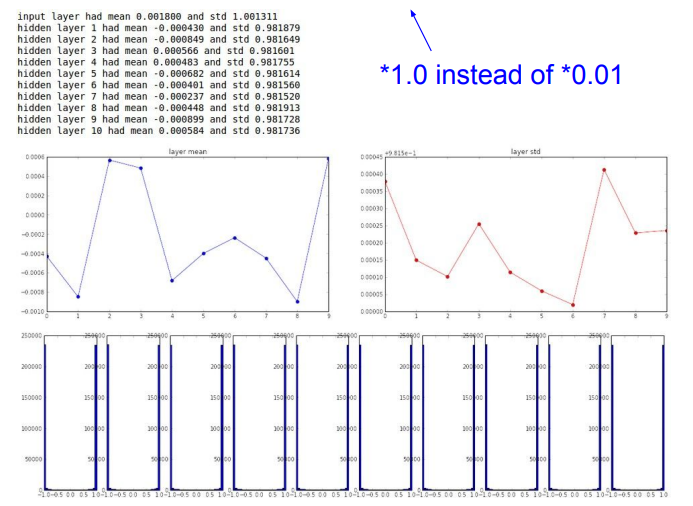
활성화 함수로 tanh를 통과시킨 것입니다.
포화상태가 되고, 결국 모든 경사가 0이 됨을 확인할 수 있습니다.
Xavier
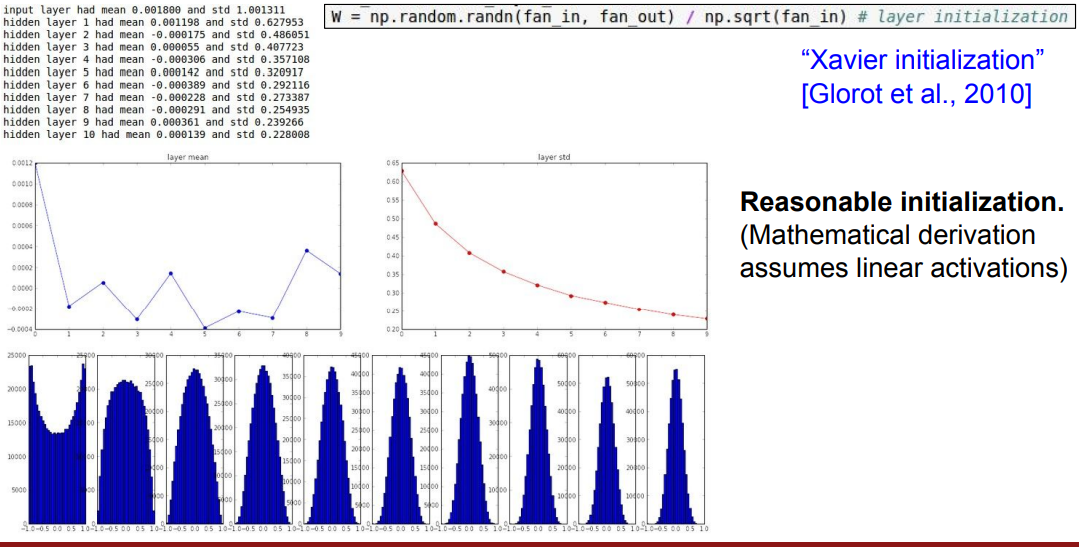
Xavier를 사용하니, 가장 이상적인 W값을 갖고,
ReLU
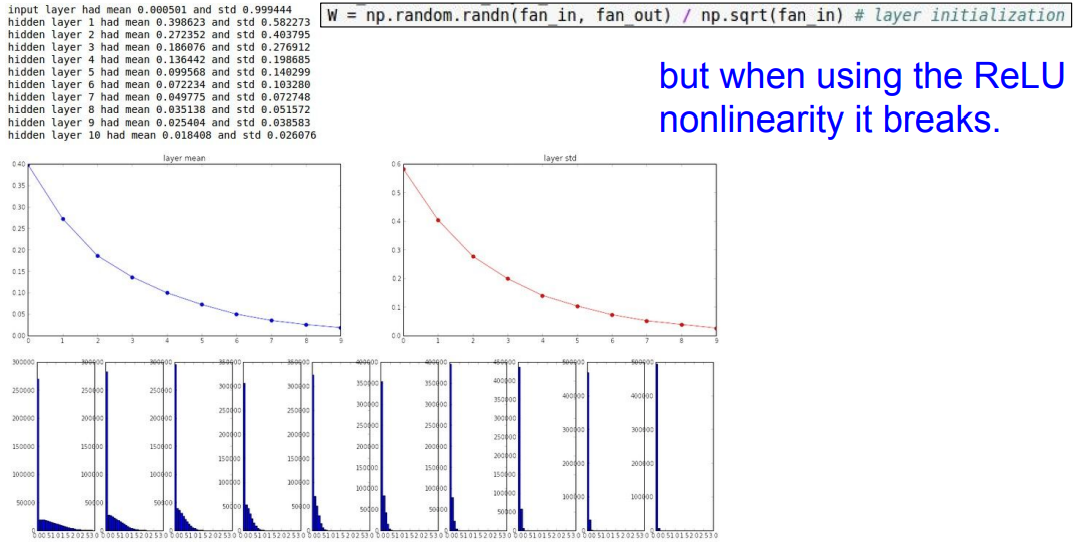
ReLU함수 사용 시, 다 깨지는 것을 확인할 수 있습니다.
위에서 봤지만, ReLU함수가 음수값을 고려 못하기 때문에 그렇다.
2로 나누었을 때
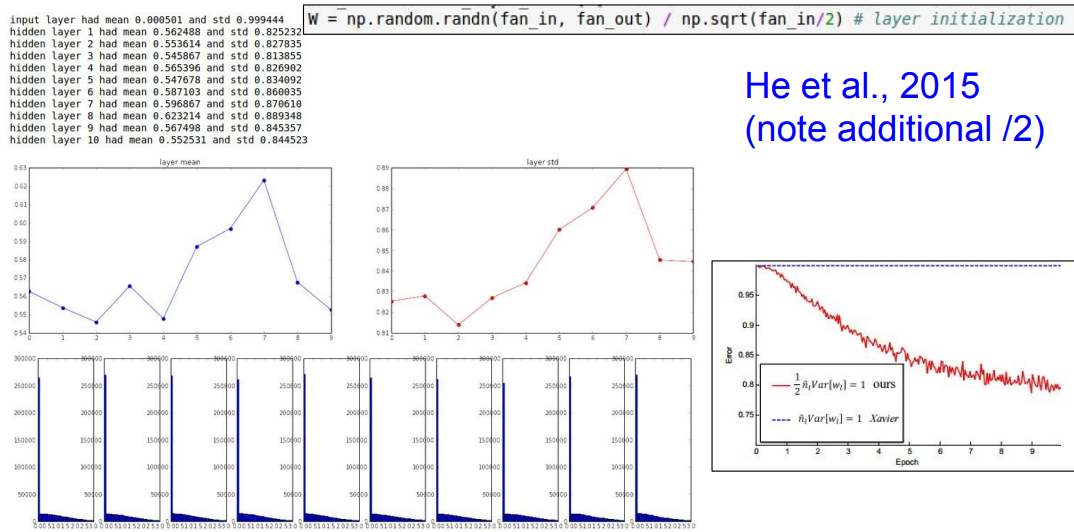
2로 나누었을 때의 경우입니다.
상대적으로 잘 작동하는 것을 알 수 있습니다.
그냥 가중치 값 이것저것 다 해보는 과정을 보여줬다.
Batch Normalization(배치 정규화)
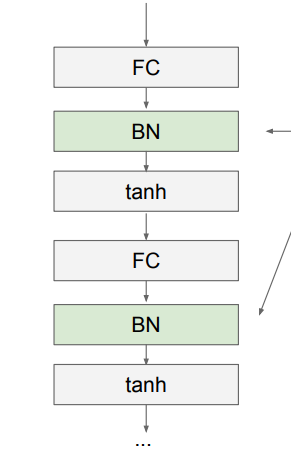
배치 정규화 적용 형태는 이렇게 구성이 됩니다.
self.layer = nn.Sequential(
nn.Conv2d(1,16,3,padding=1),
nn.BatchNorm2d(16), #
nn.ReLU(),
nn.Conv2d(16,32,3,padding=1),
nn.BatchNorm2d(32), #
nn.ReLU(),
nn.MaxPool2d(2,2), 파이토치로 구현하면 이렇게 됩니다.
Babysitting Learning Process


위의 예시를 들면서 설명을 했습니다.
학습률에 변화를 준 내용인데, Loss값이 더 떨어진 것을 알 수 있습니다.
Babysitting의 의미는 학습 과정에서 계속해서 확인하며 수정해야 함을 뜻한다.
하이퍼파라미터 영역이라고 좋은 말이 있는데, 그냥 이건 노가다 작업인 것 같다.
Hyperparameter Optimization
하이퍼파라미터 Optimization에서는
Random Search
Grid Search
이렇게 두가지에 대해 설명을 했습니다.
Random Search는 하이퍼파라미터 값을 랜덤하게 넣고, 값 좋은 것을 따와서 모델 생성하는 방식을 말합니다.
--> 불필요한 탐색 횟수 감소
Grid Search는 순차적으로 입력 후, 가장 높은 성능 보이는 하이퍼파라미터 탐색하는 것을 말합니다.
--> 시간이 오래 걸린다는 단점...
항상 이렇게 보면서 느끼는 건데, 뭐가 막 좋다 라는 것은 없는 것 같습니다.
그냥 이것저것 다 적용해보면서, 더 좋은 것을 갖다 쓰는게 최고인 것 같습니다.
감사합니당 ~ 🦾
참고자료
https://www.youtube.com/playlist?list=PL3FW7Lu3i5JvHM8ljYj-zLfQRF3EO8sYv
http://cs231n.stanford.edu/2017/syllabus
