
이번 포스팅은 CNN관련 연구에 대한 내용입니다.
Lecture 9는 내용이 너무 많아서, part 1, 2로 나누었습니다.
여기서는 많이 들어봤던 연구들이 나오고,
1. AlexNet
2. VGG
3. GoogLeNet
4. ResNet
5. Wide ResNet
6. ResNeXT
7. Stochastic Depth
8. DenseNet
9. FractalNet
10. SqueezeNet
위 신경망 구성 방식을 함축해서 알려줬습니다.
위에서부터 순서대로 취약점을 보완해 나간 연구라 생각하면 된다.
LeNet-5
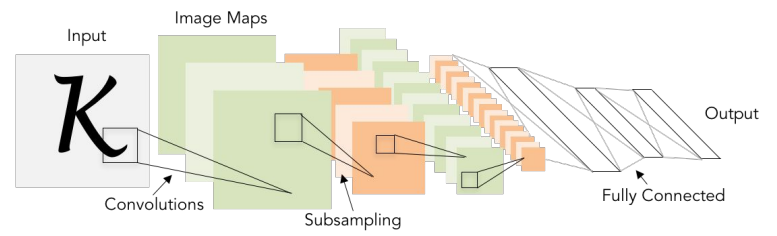
여기서 설명한 연구에서 가장 오래된 연구(1998년) 입니다.
숫자 인식에 사용되었고, 그림을 유심히 살펴보면 흐름을 알 수 있는데, 이미지를 input하고,
[5 x 5] 필터(그림에서 보이는 작은 네모박스)를 적용하고, stride값을 1로 적용하였습니다.
그 다음 FC Layer를 거치는 것을 알 수 있고, 그렇게 output으로 뱉는 내용입니다.
AlexNet
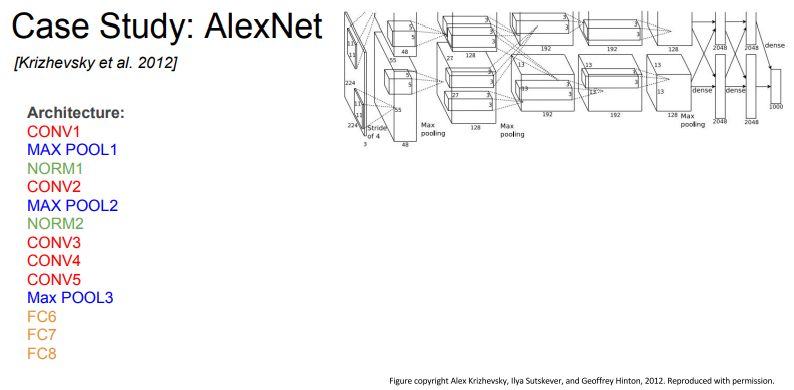
두번째로 AlexNet입니다.
처음에 input 계층에서 [227 x 227 x 3]으로 이미지를 조정(resize)하고, 설계한 계층에 넣습니다.
첫번째 계층에서 Conv1(1차원)으로 받아줍니다. 여기서 11 x 11 필터가 적용되었고, 스트라이드 값 4를 적용하였습니다.
계층 쭉쭉 거치다가 마지막 output에는 55 x 55 x 96 크기의 이미지를 출력하게 됩니다.(55 x 55 사이즈의 이미지가 96개의 채널값을 가진다는 말)
그리고 파라미터 계산법이 나왔는데, 첫번째 계층에서 11 * 11필터, stride 4, 최종 채널 값 96, input 채널 3차원이기 때문에, 총 파라미터 계산식은
(11 x 11 x 3) x 96 = 35000
이 됩니다.
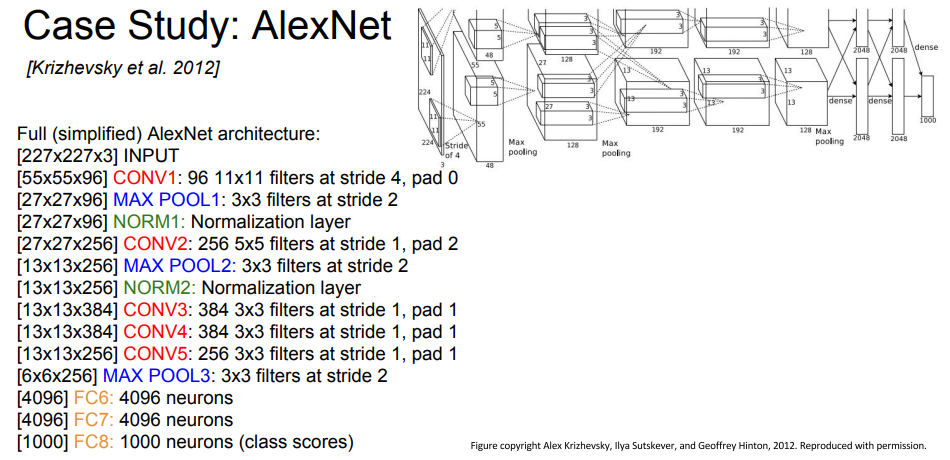
각 계층에 대해 자세히 나와있습니다. 한번 슥 보는 것도 좋을 듯 합니다.
처음에 NORM1계층은 처음 봐서 뭔가 했더니, 정규화 계층이라고 한다. 그리고 그림만 보고 처음부터 1차원으로 그냥 아무렇게나 바꾸고 넣는 줄 알았는데, 다 계획적으로 resize거치고 넣었다고 하는 것에 쫌 놀랐다.
ZFNet
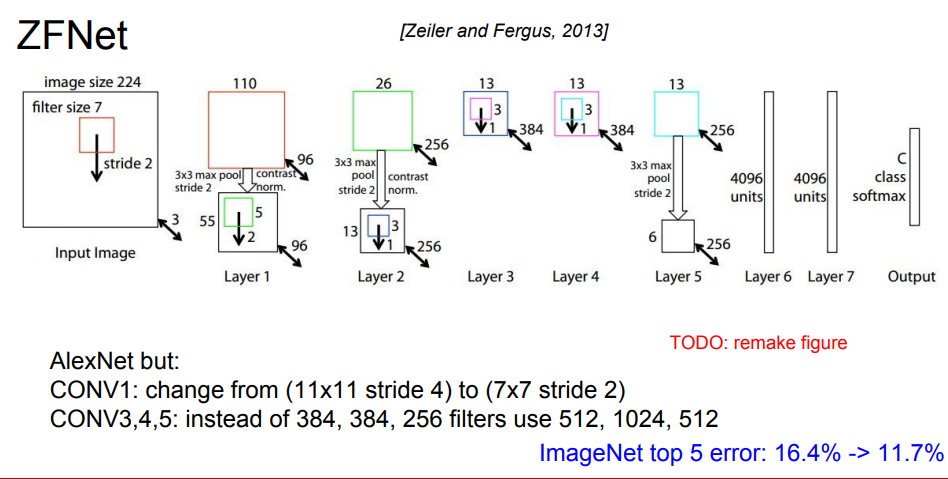
다음으로 ZFNet입니다.
AlexNet과 비슷한 구조이고, AlexNet에서 필터값 11 x 11, 스트라이드값 4를 적용했다면, 여기서는 필터 7 x 7 사이즈, 스트라이드 값 2로 변경하였습니다.
그리고 Conv3, Conv4, Conv5 계층에서 384, 384, 256개의 필터 대신, 512, 1024, 512개의 필터를 적용한 것을 알 수 있습니다.
이렇게 하니 오류율이 개선되었다고 합니다.
정말 단순한 변경으로 정확도 0.0001 올리면 논문 쓴다는 이야기가 떠오른다.
VGGNet
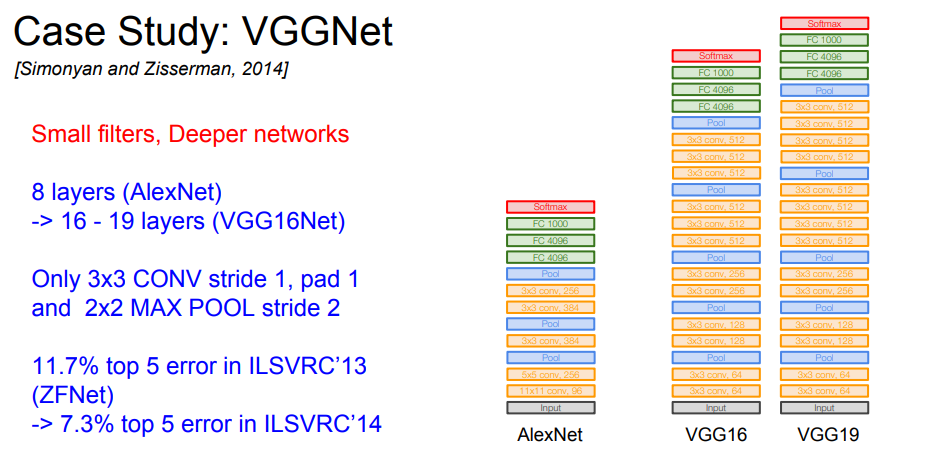
다음으로 VGGNet입니다.
AlexNet의 8 계층에서, 계층수를 16, 19계층으로 늘렸습니다.
그리고 필터 사이즈가 파라미터 양에 큰 영향을 끼친다는 것을 위 계산식을 통해 알 수 있는데, 여기서 더 작은 필터를 사용했습니다.
계층은 더 깊은데, 파라미터 수를 대폭 줄였다는 이야기 이다.
그리고 계층이 깊어지면 깊어질 수록, 비선형성이 증가한다는 이야기도 나왔는데, 활성화 함수들 형태가 대부분 비선형적인 형태를 띈다는 것을 알 수 있습니다. 이 활성화 함수 계층을 계속해서 거치게 되는데, 이는 이미지 패턴을 더 잘 학습한다는 의미 입니다.
매우 좋은 형상인데, 더 많은 메모리를 차지 한다는 단점을 갖고 있습니다.
GoogleNet

다음으로 GoogleNet 입니다.
GoogleNet의 특징은, 22개의 계층을 사용했다는 것이고, FC계층이 없다는 특징을 갖고 있습니다.
또한, 영화 제목으로 유명한
Inception module
이 등장합니다.
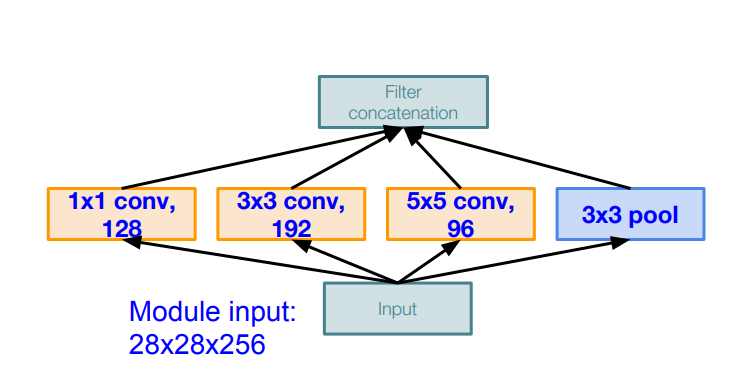
input 사이즈에서 28 x 28 x 256 크기의 이미지를 밀어 넣습니다.
각 Conv 계층에서
28 x 28 x 128,
28 x 28 x 192,
28 x 28 x 96,
28 x 28 x 256
크기를 가지게 됩니다.
그래서 그림에서 최종적으로 전달해주는 Filter에는 28 x 28 x 672크기의 연산을 시행하게 됩니다.
한눈에 봐도 계산량이 어마무시합니다.
그래서 이 문제를 해결한게 BottleNeck 계층 입니다.

여기서 빨간 글씨가 병목 계층입니다.
계층은 더 늘어났으나, 최종 필터에서 28 x 28 x 480으로 계산량이 감소한 것을 확인할 수 있습니다.
감사합니당 ~ 🦾
참고자료
https://www.youtube.com/playlist?list=PL3FW7Lu3i5JvHM8ljYj-zLfQRF3EO8sYv
http://cs231n.stanford.edu/2017/syllabus
