이번 포스팅은 Caltech101 데이터셋 정확도 개선에 관한 내용입니다.
Caltech101 데이터셋은 101개의 범주로 구성되어 있고, 총 9144개의 이미지로 구성되어 있습니다.
실습할 때, 어렵지 않게 사용했던 MNIST 데이터셋 보다 확실히 더 많은 이미지, 복잡한 이미지로 구성되어 있음을 알 수 있습니다.
(그래도 한번 도전해보자는 느낌으로 시작했다...)
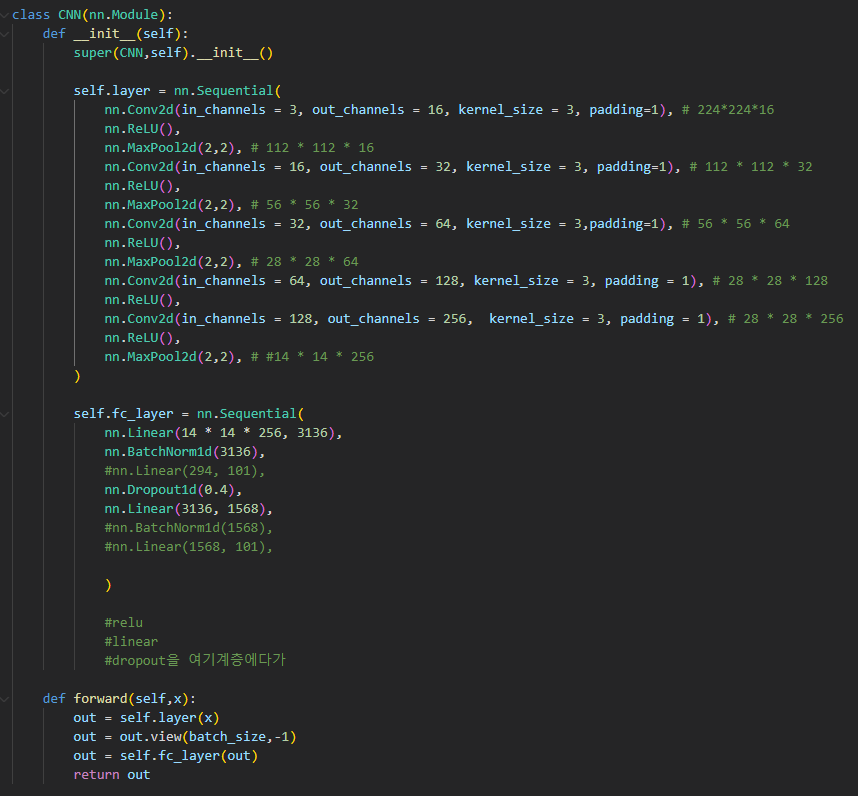
class CNN(nn.Module):
def __init__(self):
super(CNN,self).__init__()
self.layer = nn.Sequential(
nn.Conv2d(in_channels = 3, out_channels = 16, kernel_size = 3, padding=1), # 224*224*16
nn.ReLU(),
nn.MaxPool2d(2,2), # 112 * 112 * 16
nn.Conv2d(in_channels = 16, out_channels = 32, kernel_size = 3, padding=1), # 112 * 112 * 32
nn.ReLU(),
nn.MaxPool2d(2,2), # 56 * 56 * 32
nn.Conv2d(in_channels = 32, out_channels = 64, kernel_size = 3,padding=1), # 56 * 56 * 64
nn.ReLU(),
nn.MaxPool2d(2,2), # 28 * 28 * 64
nn.Conv2d(in_channels = 64, out_channels = 128, kernel_size = 3, padding = 1), # 28 * 28 * 128
nn.ReLU(),
nn.Conv2d(in_channels = 128, out_channels = 256, kernel_size = 3, padding = 1), # 28 * 28 * 256
nn.ReLU(),
nn.MaxPool2d(2,2), # #14 * 14 * 256
)
self.fc_layer = nn.Sequential(
nn.Linear(14 * 14 * 256, 3136),
nn.BatchNorm1d(3136),
#nn.Linear(294, 101),
nn.Dropout1d(0.4),
nn.Linear(3136, 1568),
#nn.BatchNorm1d(1568),
#nn.Linear(1568, 101),
)
#relu
#linear
#dropout을 여기계층에다가
def forward(self,x):
out = self.layer(x)
out = out.view(batch_size,-1)
out = self.fc_layer(out)
return outCNN계층 설계할 때, MaxPooling계층도 넣어보고, 배치 정규화도 해보고, 다시 뺐다가 다시 넣어보고, 활성화 함수도 이것저것 다 써보고, epoch, Learning_rate 값도 높였다 줄였다 해도 정확도가 50%를 넘은게 손에 꼽을 정도였습니다...
Dropout 계층도 넣으면 보통 잘된다는 조언을 받았었는데... 조금 올라갔던게 기억에 남는다. 물론 아주 조금 ㄷㄷ
그렇게 흔들리는 멘탈을 거듭 붙잡으며, 우연히 보게된 자료가 있었는데,
그 자료가, 바로 ResNet34 방식을 적용한 것.
class ResNet34(nn.Module):
def __init__(self, pretrained):
super(ResNet34, self).__init__()
if pretrained is True:
self.model = pretrainedmodels.__dict__['resnet34'](pretrained='imagenet')
else:
self.model = pretrainedmodels.__dict__['resnet34'](pretrained=None)
# change the classification layer
self.l0 = nn.Linear(512, len(lb.classes_))
self.dropout = nn.Dropout2d(0.4)
def forward(self, x):
# get the batch size only, ignore (c, h, w)
batch, _, _, _ = x.shape
x = self.model.features(x)
x = F.adaptive_avg_pool2d(x, 1).reshape(batch, -1)
x = self.dropout(x)
l0 = self.l0(x)
return l0
#model = ResNet34(pretrained=True).to(device)
단 epoch값 5로 정확도 96%를 찍었습니다.
이미 누군가 만들어 놓은 것이어서 코드는 굉장히 짧다!!

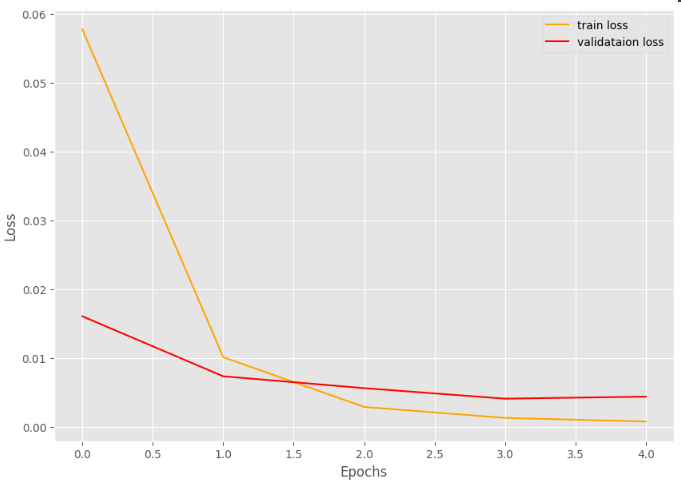
이렇게 train loss, validation loss도 발산하지 않고, 거의 0에 수렴하는 것을 확인할 수 있었습니다.
전체코드
https://github.com/Ryuchanghoon/Blog_Code/blob/main/accuracy_96.ipynb
한줄 요약
확실히 똑똑한 사람들이 만든게 최고긴 하다.
그래도 계속 공부해서 나만의 좋은 모델 하나 만들어야겠다.
참고자료
https://debuggercafe.com/getting-95-accuracy-on-the-caltech101-dataset-using-deep-learning/

Vision AI Researcher