소개
- 이 글은 단지 CS231n를 공부하고 정리하기 위한 글입니다.
- Machine Learning과 Deep Learning에 대한 지식이 없는 초보입니다.
- 내용에 오류가 있는 부분이 있다면 조언 및 지적 언제든 환영입니다!
참조
-
https://devkor.tistory.com/entry/CS231n-10-Recurrent-Neural-Networks
-
https://younghk.netlify.app/posts/cs231n-lec10-recurrent-neural-networks/
-
https://www.facebook.com/groups/TensorFlowKR/permalink/478174102523653/
-
https://gist.github.com/ratsgo/6e9a094c7108dee8147ef0a13666de47#file-lstm_loss-py
개요
< Recurrent Neural Networks >
Recurrent Neural Networks
이번에는 새로운 머신러닝 네트워크인 Recurrent Neural Networks(RNN)을 다루겠습니다.
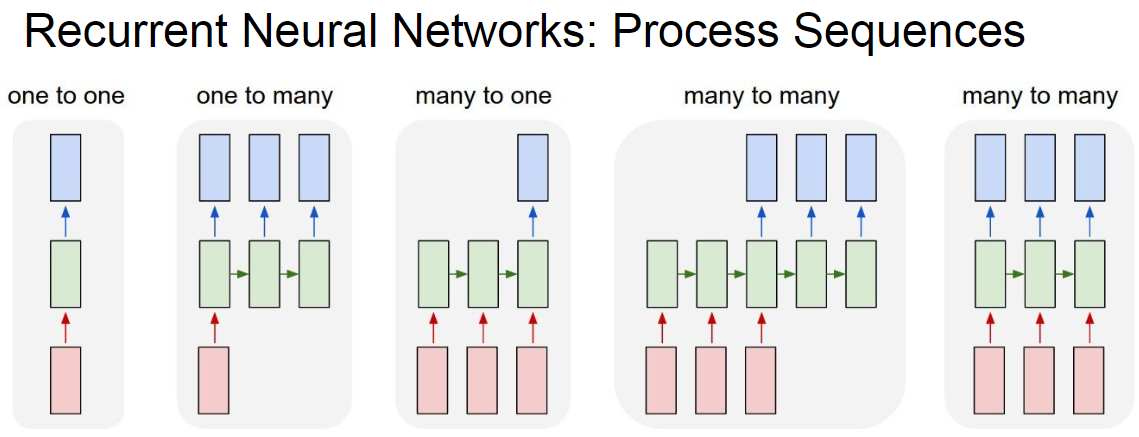
지금까지 배운 네트워크는 one to one model 로 하나의 입력에 대해서 하나의 출력을 가지는 구조였습니다.
하지만 하나뿐 아니라 아래와 같이 여러 입력 또는 여러 출력을 가지는 network도 필요할 것입니다.
여기서 RNN은 이러한 것을 가능하게 해줍니다.
RNN이란 Sequence를 따라 node 사이의 연결의 형태가 방향 그래프인 인공 신경망의 한 종류입니다.
아래의 있는 입력과 출력에 따른 구조를 살펴봅시다.
- one to one
- 가장 기본적인 형태로 하나의 입력과 하나의 출력을 가지는 형태이다.
- one to many
- 하나의 입력에 대해서 여러 출력을 가집니다.
- 예시 : image captioning - 하나의 사진에 대해 여러 단어를 출력함
- many to one
- 여러 입력에 대해서 하나의 출력을 가집니다.
- 예시 : 감정구별
- many to many
- 여러 입력에 대해서 여러 출력을 가집니다.
- 입력에 대해 바로 출력이 나오는 경우가 있고 좀 이후에 나오는 것이 있습니다.
- 입력에 대해 바로 나오는 경우 예시 : 비디오에 대해 프레임 단위로 classification
- 입력에 대해 시간차이가 존재하는 경우 예시 : 기계번역
RNN의 기본 구조와 수식
기본적인 RNN 수식은 아래와 같습니다.
t는 시간, W는 weight 값을 나타냅니다.
RNN은 모든 함수와 parameter 값을 모든 시간에서 동일하게 사용합니다. 이러한 점이 RNN과 MLP(Multiple Layer Perceptron)과의 차이점이라고 합니다.
- xt : 입력
- ht-1 : 전 hidden state
- fW : 현재 hidden state를 구하는 함수
- ht : 현재 hidden state
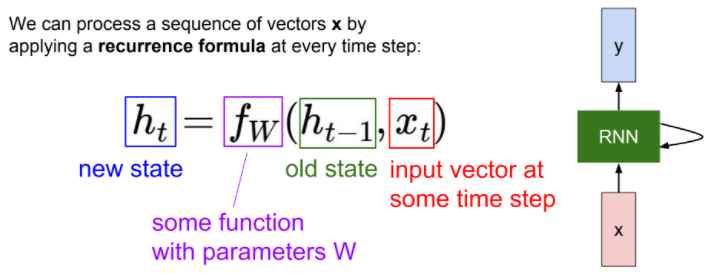
아래 수식은 전 hidden state의 값에 대한 Whh와 현재 입력값에 대한 Wxh weight 값을 각각 곱해줍니다.
이후 활성화 함수 tanh 을 거쳐, Why로 출력 값을 계산합니다.

RNN의 활성화 함수 비교
이 사이트 에서 고수분들에 의견을 대략 정리해봤습니다.
- sigmoid는 평균이 0.5인데 비해서 tanh는 평균이 0이므로 연속적으로 같은 활성화 함수를 쓰는 RNN 입장에서 입력의 noramliaztion 입장에서 더 좋다고합니다. 또한 값이 0일때 기울기가 1인 것이 linear model과 비슷한 효과도 있다고합니다.
- relu는 0 미만 값에 대해서는 큰 양수 값들이 점점더 치웃쳐서 exploding 현상이 일어납니다.
- 이 위에 경우 모두 exploding 과 granient vanishing 문제를 가지고 있습니다.
- 여기서 exploding 현상은 gradient clipping으로 gradient의 threshold 값을 줘 해결 할 수 있습니다.
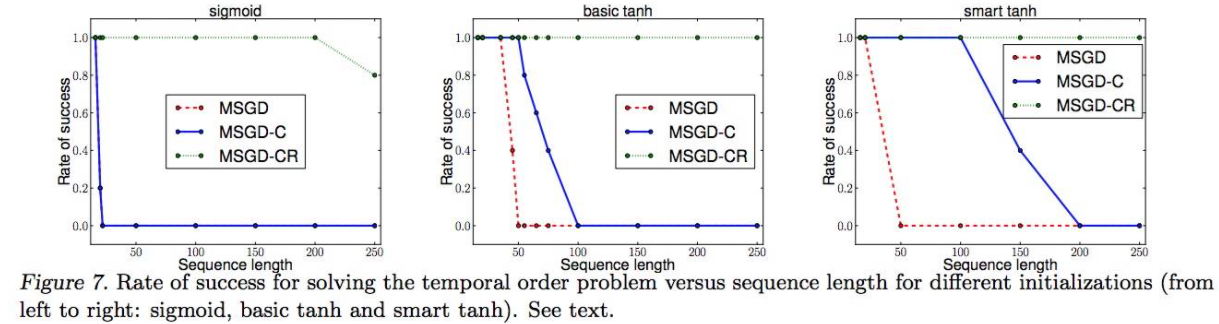
- 다만 vanishing 문제는 해결이 불가능 하며 이에 대한 설명은 아래 그림과 같습니다.
- 벤지오 선생님그룹의 2013 논문 그림 7 (sigmoid vs tanh)
- tanh가 sigmoid 보다 vanishing 문제에 더 강한 것을 볼 수 있습니다.
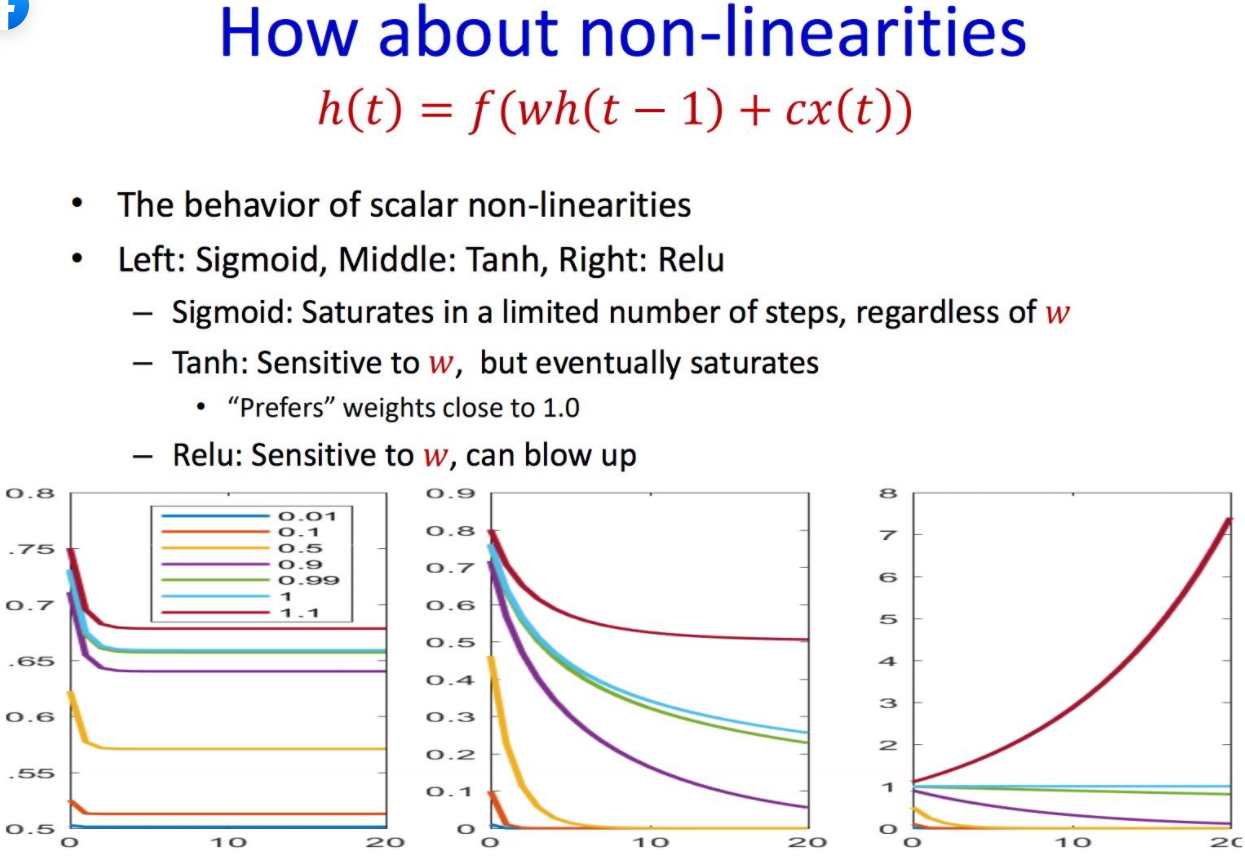
- CMU에서 음성인식하시는 Raj 교수의 슬라이드
- sigmoid와 tanh의 포화 지점을 비교하면 tanh가 좋은 성능을 가지는것을 볼 수 있다.
- relu와 같은 경우 exploding 현상이 존재합니다.
RNN Computational Graph
RNN의 Computational Graph는 아래와 같습니다.
위 RNN을 순차적으로 쌓아올려, 여러 입력을 받아들일 수 있습니다.
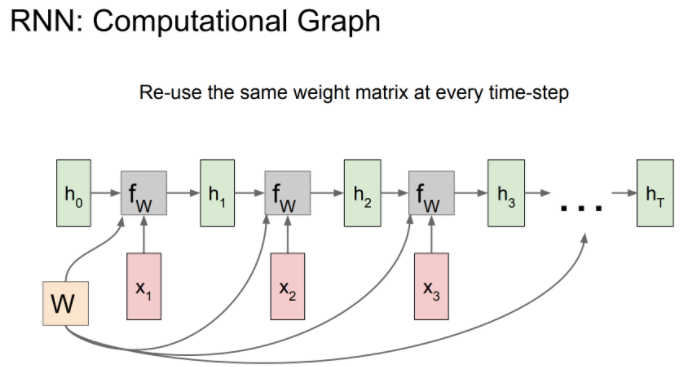
각 hidden state에서 다른 네트워크에 들어가서 yt을 나타낼 수 있습니다.
각 스텝에서 같은 Weight 값을 사용하는 것을 볼 수 있습니다.
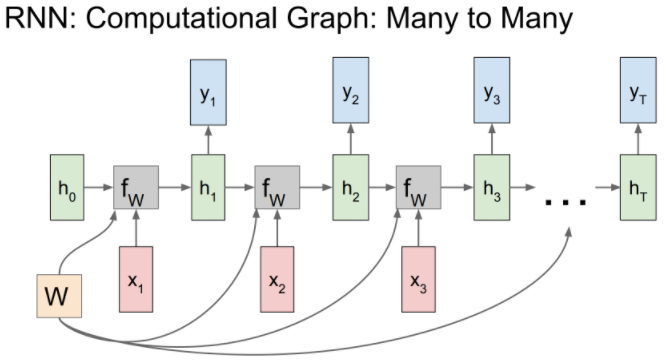
- Gradient : 각 step에서 Weight에 대한 Gradient의 총합
- Loss : 각 step에 구한 yt에 대한 Loss를 모두 더한 값
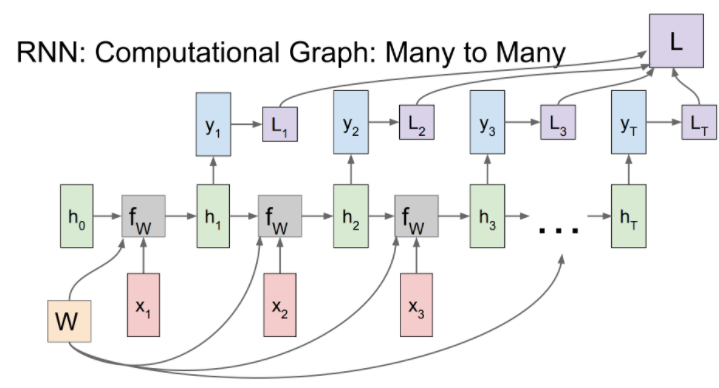
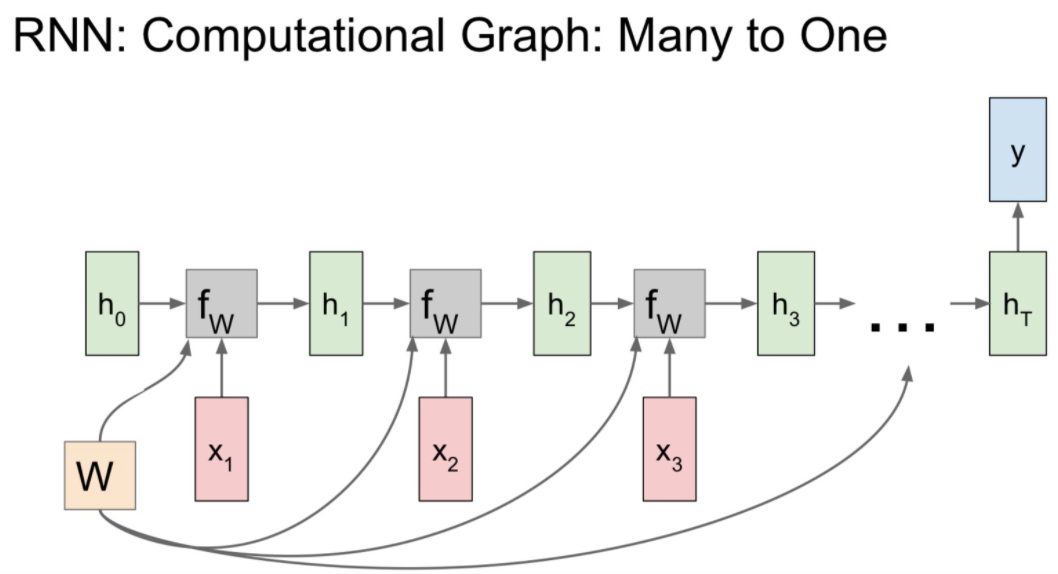
many to one 그래프는 아래와 같습니다.
이 모델은 감정분석 같이 여러 입력을 받고 하나의 출력을 가지는 경우 사용된다고 합니다.
최종 hidden state에서만 결과 값이 나옵니다.
one to many 모델은 아래와 같습니다.
image captioning과 같이 하나의 사진에 대한 여러 단어을 출력하는 모델에서 사용된다고 합니다.
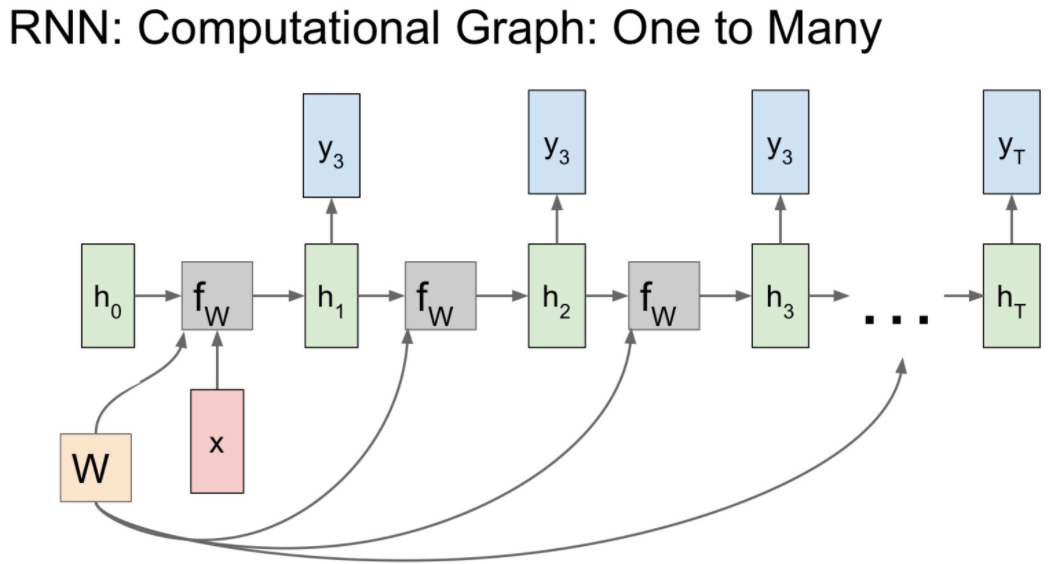
아래 그림과 같이 다른 두 구조인 many to one, one to many를 조합해 사용할 수도 있습니다.
이를 Sequence to Sequence (Seq2Seq) Model이라고 합니다.
- Seq2Seq Model
- 기계번역에서 사용
- Mony to one 과 ono to many의 조합
- Encoder + Decoder
- 예를 들어, Encoder는 영어문장과 같은 가변입력을 받아들여 final hidden state에 전체 sentence를 요약합니다.
- 여기서 Decoder는 이 sentence를 받아 다른 언어로 번역된 문장을 출력할 수 있다.
- END 와 같은 임의에 토큰을 지정하여 출력 길이를 조절할 수 있으며, 입력과 같은 경우 0을 집어넣는 경우가 많다고 합니다.
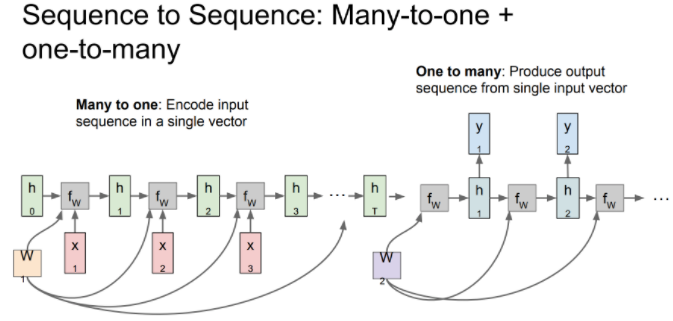
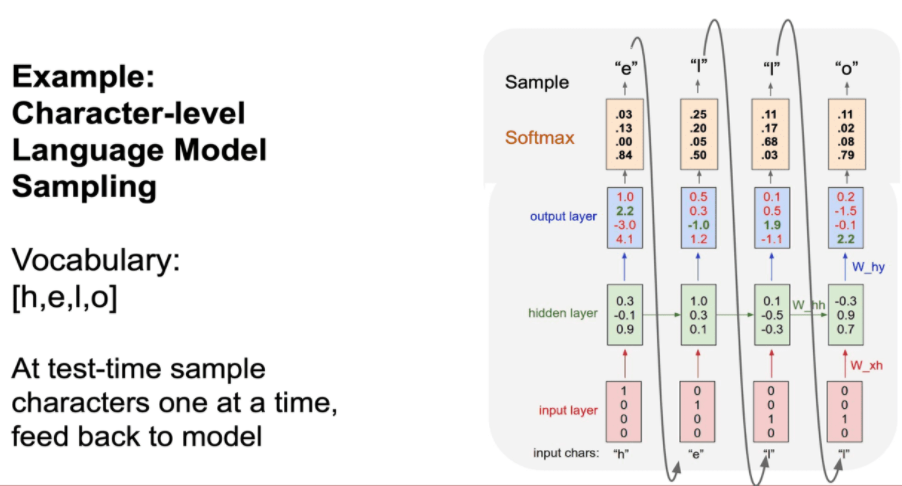
RNN 예제 Character level Language Model
아래는 하나의 문자를 입력받고 다음으로 올 문자열을 예측하는 언어 모델의 예시입니다.
예시로, hell 를 입력받아 다음에 올 o를 출력하여 hello 단어를 추측하는 모델입니다.
즉 앞에 맥락상 가장 올 만한(확률이 높은) 단어를 선택하는 모델입니다.
먼저 각 단어를 One-hot encoding으로 변환하여 입력으로 넣어줍니다.
- One-hot encoding
- 간단하게, 하나의 값만 선택하여 사용하는 방법이다. 예시는 아래와 같습니다.
- h = [1, 0, 0, 0]
- e = [0, 1, 0, 0]
- l = [0, 0, 1, 0]
- o = [0, 0, 0, 1]
위와 같이 4개의 값중에 한 값만 1로 사용하는 형태가 one-hot encoding이라고 생각하면 됩니다.
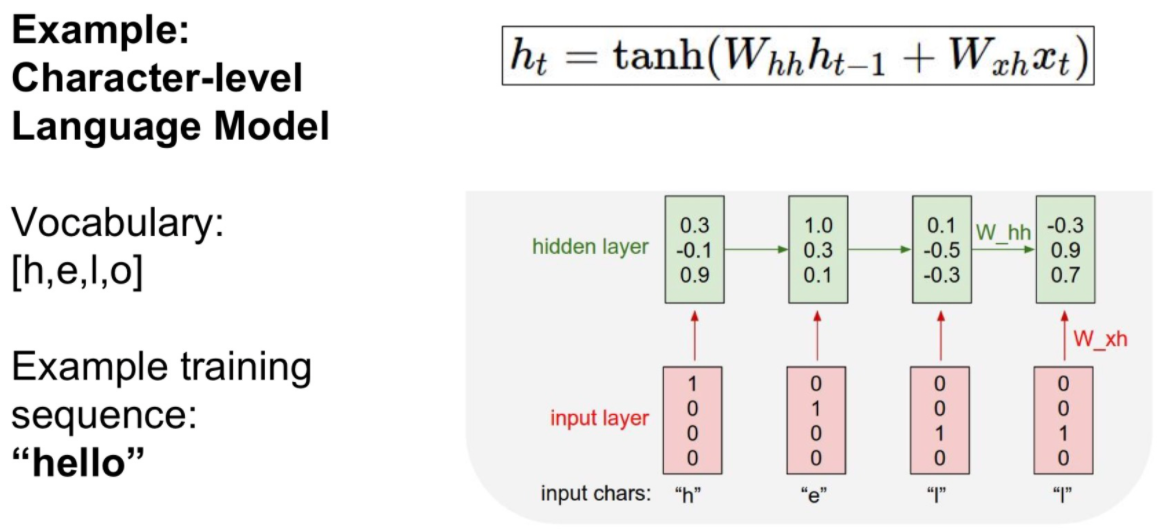
학습(Train)과정은 아래와 같습니다.
아래와 같이 h 값이 들어가면 다음에 나올 값이 e를 예측합니다.
마지막으로 우리가 원하는 4번째 요소인 o의 값이 가장 큰 값을 가지고 올바르게 예측한 것을 볼 수 있습니다.
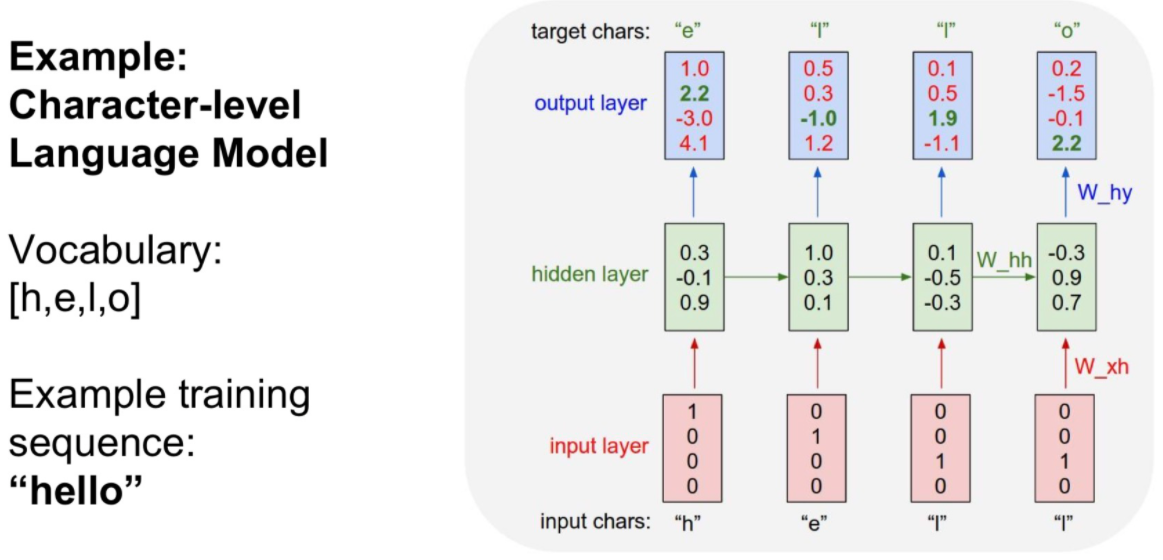
각 입력에 대한 출력을 Sampling 하여 다음 입력으로 넣어주는 방식도 있습니다.
- Softmax를 추가하여 다른 값보다 얼마나 높은지를 추정하고, 다른 값들과 상호 배타적(mutually exclusive)으로 비교 가능합니다.
- 이로써 Cross Entropy 오차로 사용
- 여기서 각 입력에 대해서 출력의 가장 큰 값을 그대로 사용하지는 않는다고 합니다. 학습이 잘 안된다고 하네요.
- RNN은 앞에 hidden state를 이용하여 진행하여 계산시간과 학습시간이 느립니다.
- RNN은 많은 memory를 사용합니다.
- RNN은 Markov assumption(미래는 현재와 과거와 무관하다)을 만족하지 않습니다.
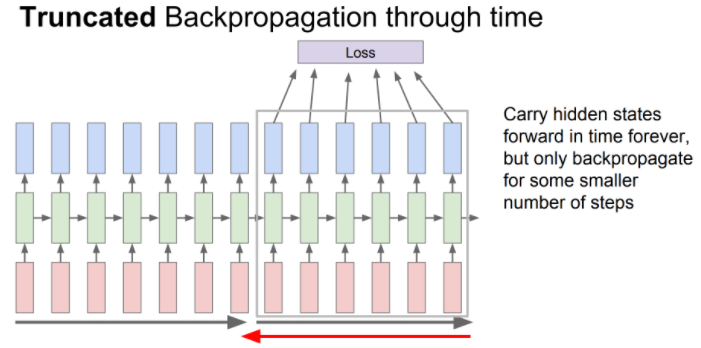
RNN Truncated Backpropagation
일반적으로 RNN은 모든 출력을 구하면서 학습을 진행하면 너무 느립니다.
이러한 문제를 해결하기 위해서 배치별로 나누어서 학습을 진행하는 방법도 사용합니다.
배치 크기만큼에 loss를 보고 학습을 진행하는 방식입니다.
이 방법을 Truncated Backpropagation 이라고 합니다.
이와 관련되어 Stanford의 karpathy님께서 이에 대한 코드를 공유해 놓으셨습니다.
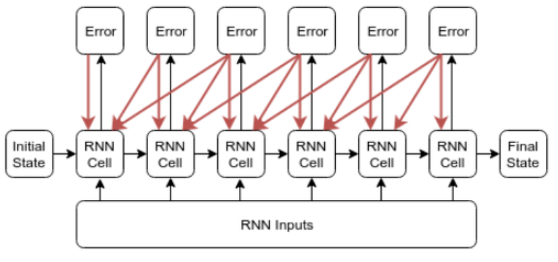
아래 그림은 총 길이가 6이고 Truncated batch의 크기가 3인 경우입니다.
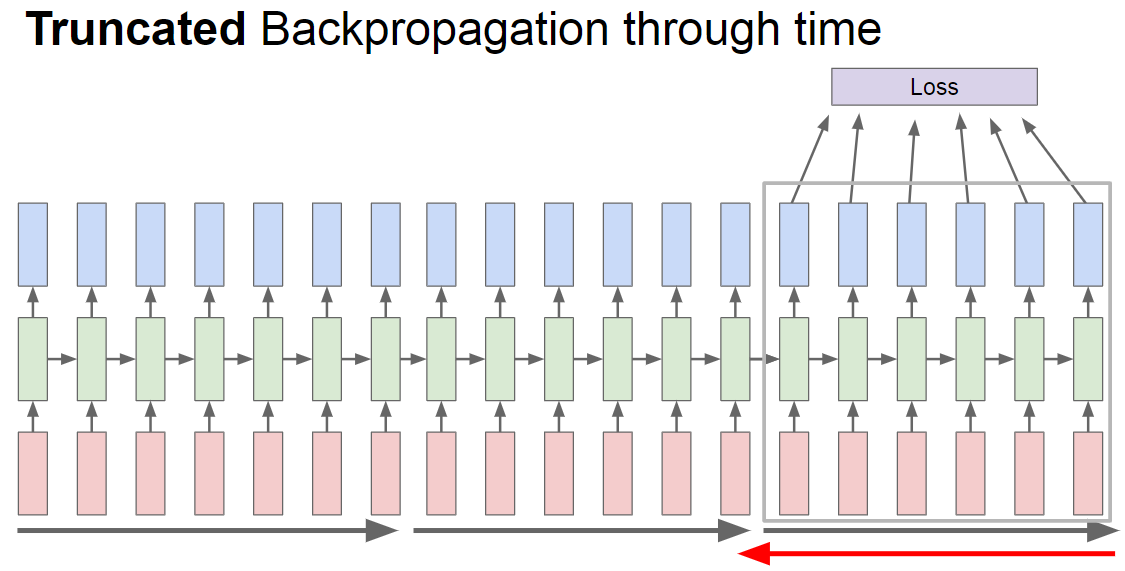
아래 처럼 batch 크기만큼 뛰어가면서 하는 방법도 있다고 합니다. (TensorFlow)
RNN 예제 Image captioning
다른 예제도 살펴봅시다.
Image captioning은 CNN에서 나오는 하나의 출력 값을 RNN의 입력으로 사용하고,
이 정보로 부터 문장을 만들어 내는 방법입니다.
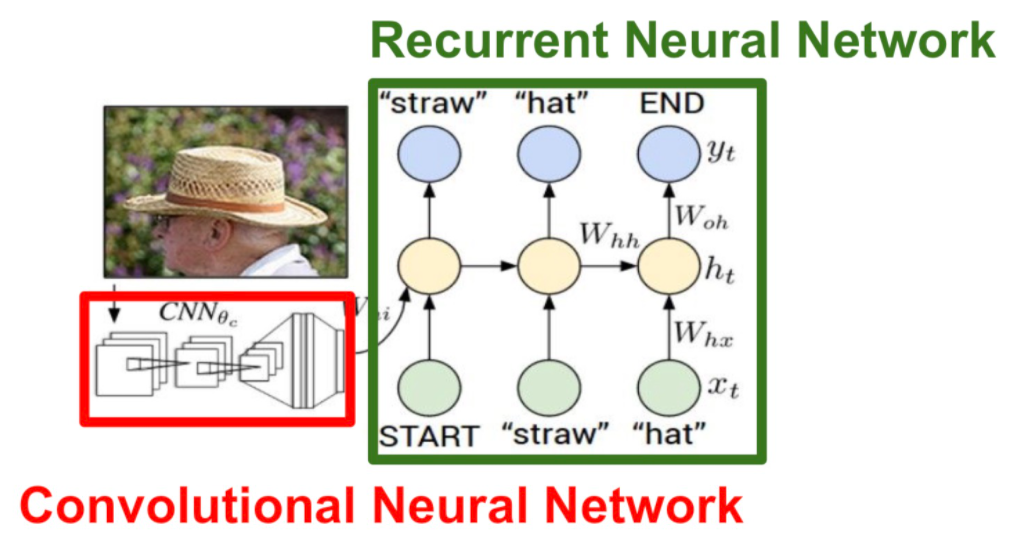
아래와 같이 VCC19의 모델이 있다고 합시다.
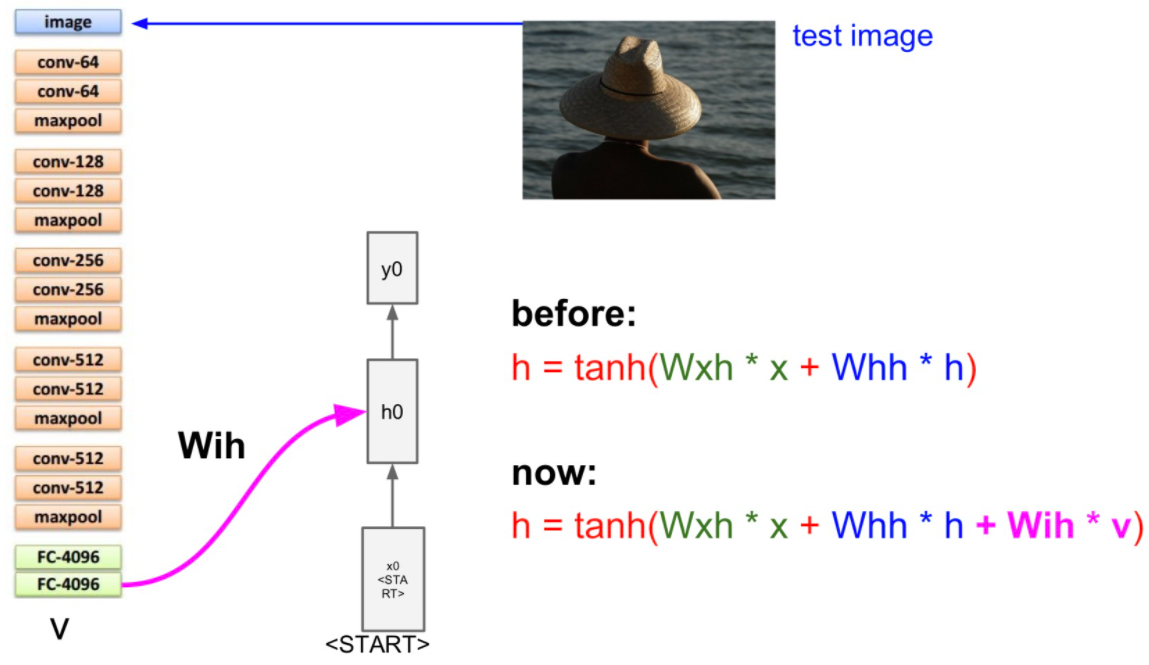
여기서 마지막 단에 softmax 와 FC 레이어 하나를 제거합시다.

위에서 제거한 레이어 전에 나온 입력을 hidden layer의 이전 hidden state 값으로 사용합니다.
그리고 입력 값으로 <start> 토큰을 줍니다.
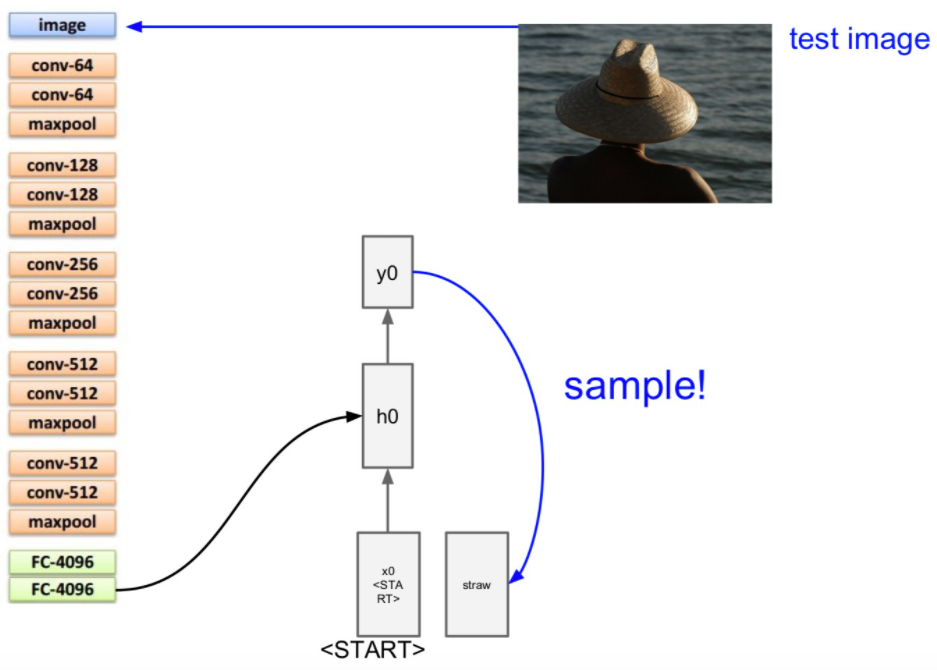
그리고 이 입력에서 나온 출력 y0을 sample 값으로 다음 입력으로 넣어줍니다.
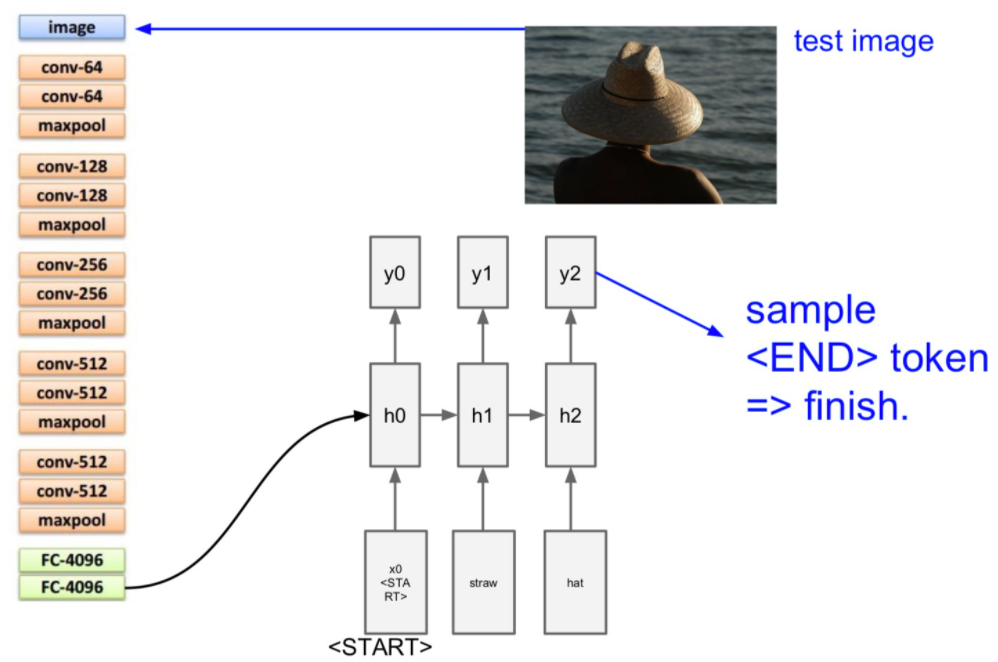
마지막 출력을 <END> 토큰으로 학습시켜 마지막 출력을 알 수 있도록 합니다.
이 모델은 Supervised learning으로 학습시킵니다.
고로 이미지에 대한 caption을 가지고 있어야 하며 이 데이터 셋은 Microsoft COCO dataset이 있습니다.
위처럼, 위 이미지를 통째로 사용하여 얻어진 요점을 언어로 변경하는 Top-Down Approach라고 합니다.
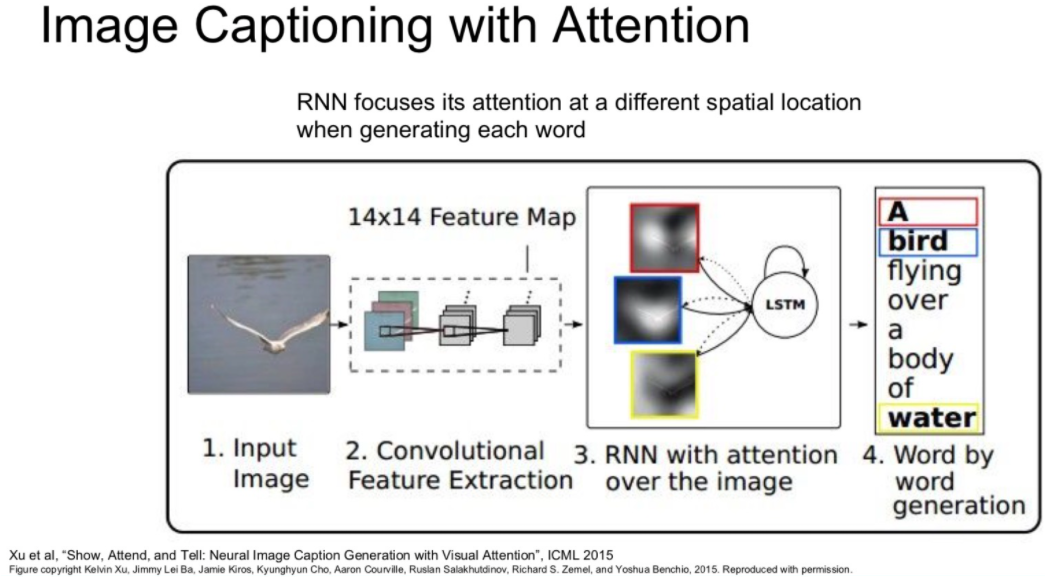
RNN 예제 Image Captioning with Attention
더 발전된 방법으로 Attention이라는 방법이 있습니다.
이 방법은 caption을 생성할 때 이미지의 다양한 부분을 집중해서 볼 수 있습니다.
위에서 사용한 Top-Down Approach는 이미지의 디테일한 부분들에 집중하는 것이 상대적으로 어렵다는 단점을 가집니다.
이 Attention 기법을 이용하면 이미지의 모든 부분으로 부터 단어를 뽑아내어 디테일에 신경을 써줄 수 있습니다.
이 방법을 Bottom-Up Approach라고 합니다.
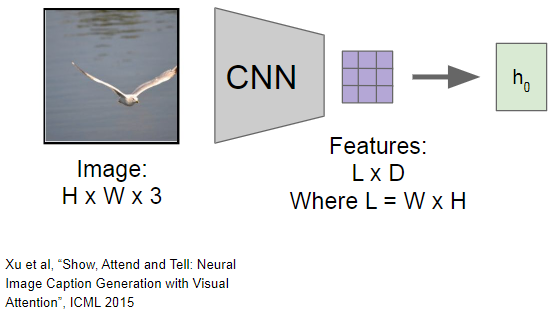
이 Attention 기법은 아까와 다르게 CNN의 출력으로 하나의 벡터를 만드는 것이 아니라, 각 벡터가 공간정보를 가지고 있는 grid of vector(L x D)를 만들어 냅니다.
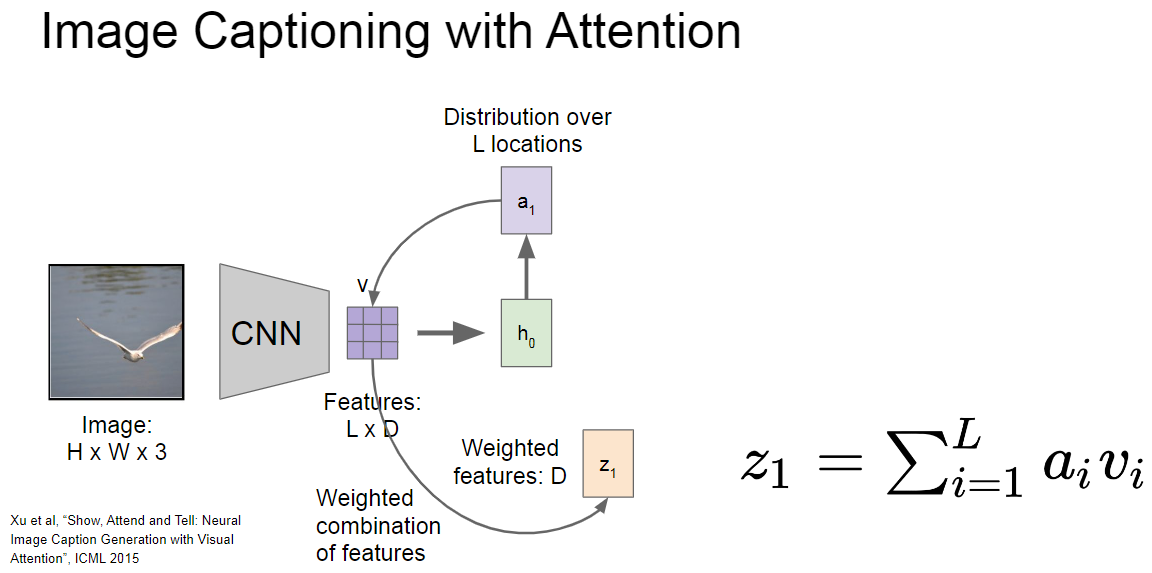
- 진행 순서
- grid of vector 값을 입력으로 넣어서 a1 값을 생성합니다.
- 이 a1(attention) (L x 1)의 요소로 grid of vector (L x D)에 각 depth(1 x D)에 곱하여 scaling 합니다.
- L개의 scaling 된 벡터를 더하여 z1(1 x D) 를 만들고 이를 입력으로 사용합니다.
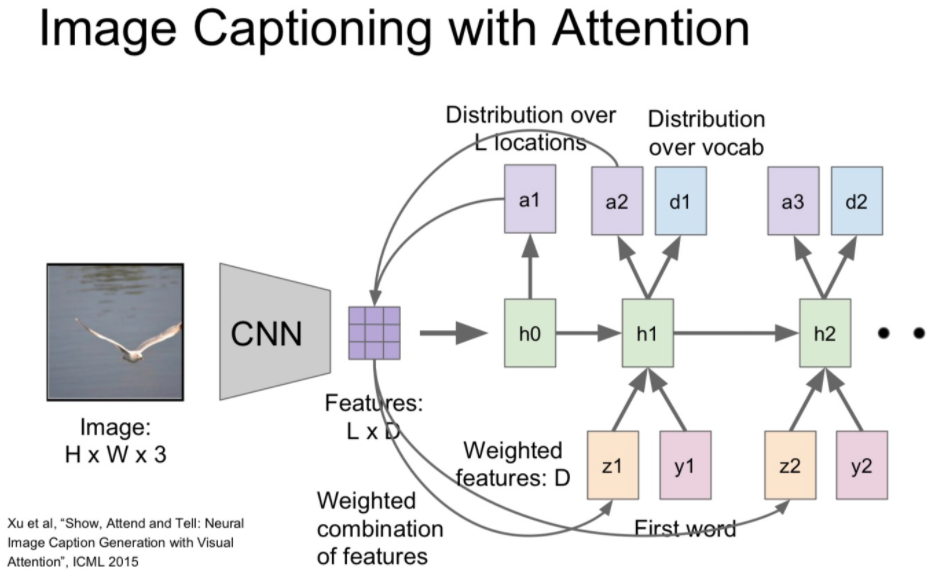
- 위에서 만든 z1과 단어를 함께 입력으로 넣어 다음 attention(a2) 값과 단어의 분포도 값을 얻습니다.
- 위에서 얻은 attention(a2)값을 다시 grid of vector 에 곱하여 다음 z 값을 얻고 이를 반복합니다.
- 여기서 attetion 값은 (L = W x H)로 각 이미지의 어느 부분을 중심적으로 볼지에 대한 정보입니다.
- 아래는 Soft attention과 Hard attention의 차이를 보여줍니다.
- Soft attention: 0~1부터 다양한 범위 값을 부드럽게 사용합니다.
- Hard attention: 0또는 1의 값을 사용하여 정확하게 몇 부분을 집중해서 봅니다.
- 이러한 두 차이점으로 아래에서 두 분포의 차이를 볼 수 있습니다.

아래는 attention의 또 다른 결과 예시입니다.
사람과 비슷하게 사진에서 중요한 부분을 보고 묘사하는 효과를 줄 수 있습니다.

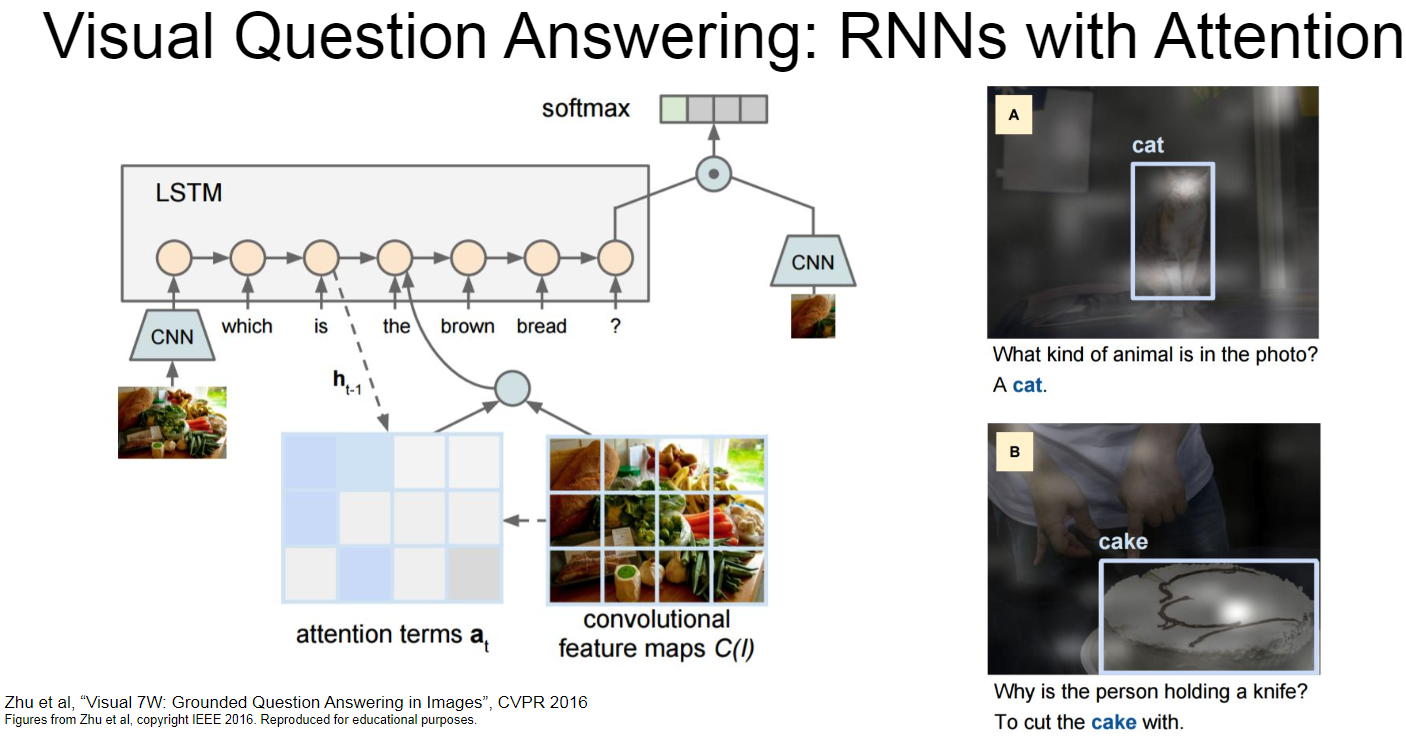
RNN 예제 Visual Question Answering
Image captioning 말고도 사진에 대한 질문과 답을 내는 Visual Question Answering 도 있다고 합니다.
RNN 예제 Gender Bias
이러한 Image Captioning 에서도 남성 또는 여성으로 치중된 양의 데이터의 성별 Bias로 성별을 제대로 구분하지 못하는 경우가 있었는데, 이를 해결한 성과도 있습니다.

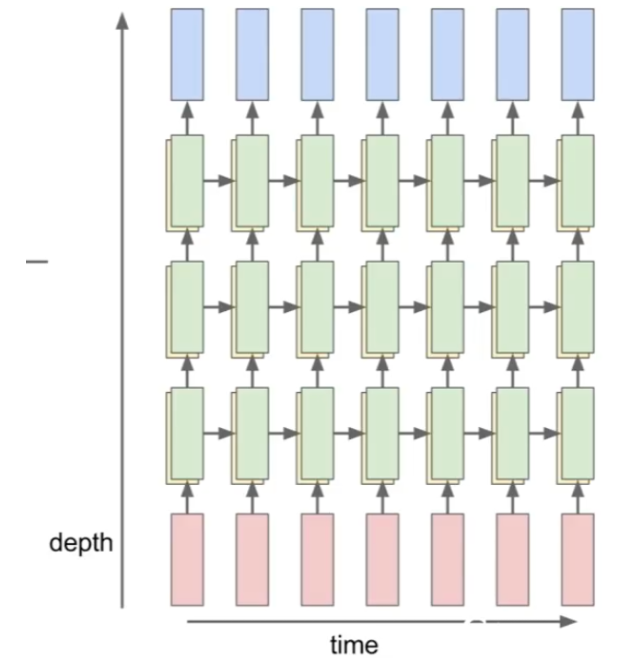
Multilayer RNN
hidden layer를 하나만 사용하는 것이 아닌 여러 개를 사용하는 방법입니다.
RNN Backpropagation Through time
RNN의 BPTT(Backpropagation Through time)에 대해서 알아봅시다.
이에 대해서 잘 설명한 블로그가 있어서 참조했습니다. (출처)
먼저 예시로 기본적인 RNN의 구조가 아래와 같다고 가정합시다.
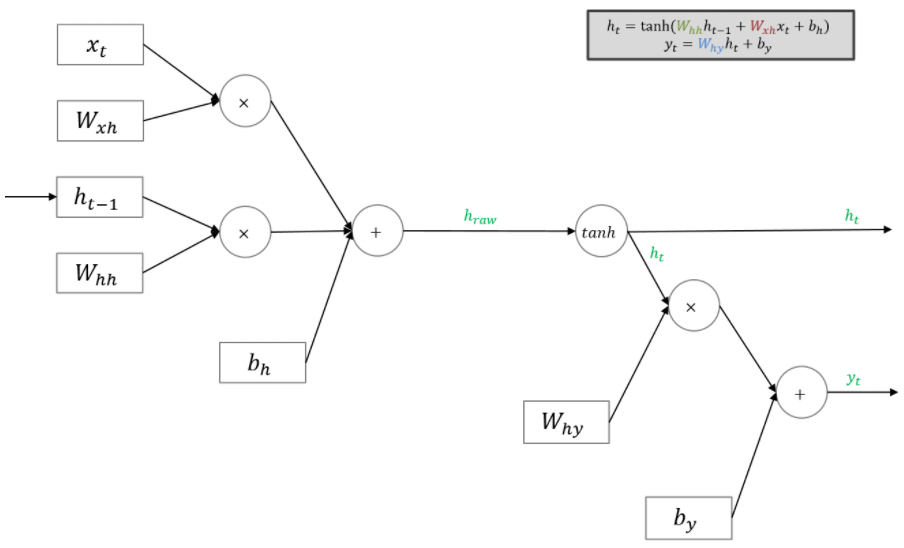
이 RNN의 BPTT은 아래와 같습니다.
예전에 기본적인 BPTT을 배운것 처럼, 뒤에서 부터 역전파를 시작합니다.
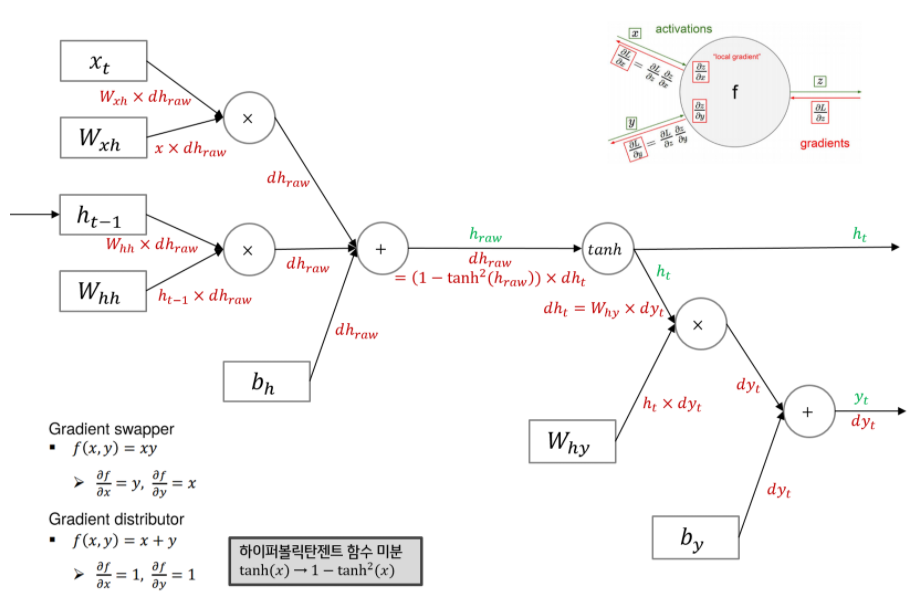
먼저 yt에 대해서만 살펴보면 아래 그림과 같습니다.
- add: 그대로 전 loss 값 전파
- mul: 곱하기 반대편의 값과 전 loss와 곱하여 전파
- tanh: 미분값인
1-tanh^2(x)로 tanh의 입력값인 x를 대입하고 전파
이제 ht-1 값 과 전파된 yt-1를 합친 결과는 아래와 같습니다.
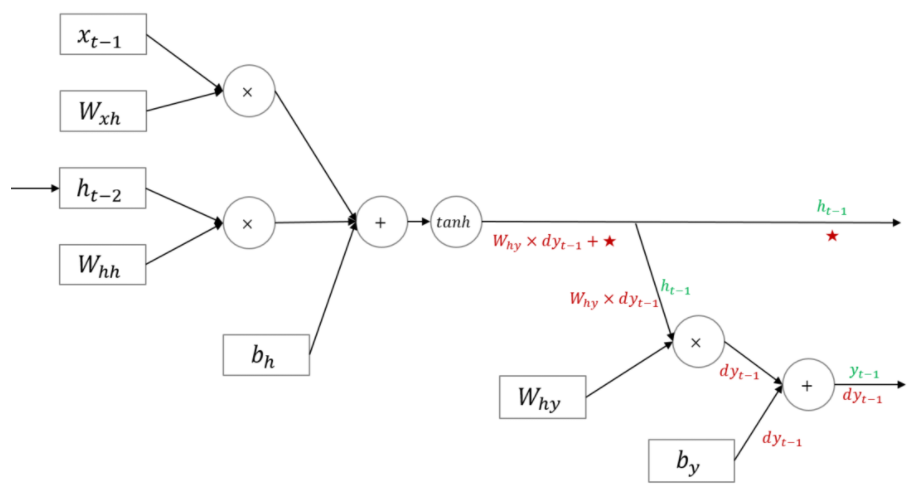
RNN의 BPTT은 아래와 같이 진행됩니다.
여기서 h4에서 부터 시작하여 h0까지 loss를 구하기 위해서는 W의 transpose 요소를 모두 곱해야하는 비효율적인 연산이 반복됩니다.
또한 이러한 곱셈과정에서 값이 1보다 크거나 1보다 작은 경우 각가 Exploding 와 Vanishing gradients 문제를 가지고 있습니다.
그리고 장시간에 걸처 패턴이 반복하면 장시간(Long-Term)의 패턴을 학습할 수 없는 문제를 가지고 있다.
- Exploding gradients : Gradient clipping 으로 해결합니다.
- Vanishing gradients : RNN의 구조를 변경하여 해결합니다. (LSTM)
- 장기 의존성(Long-Term Dependency) : 오래전에 입력에 정보를 사용하지 못하는 문제을 구조 변경으로 해소합니다. (LSTM)
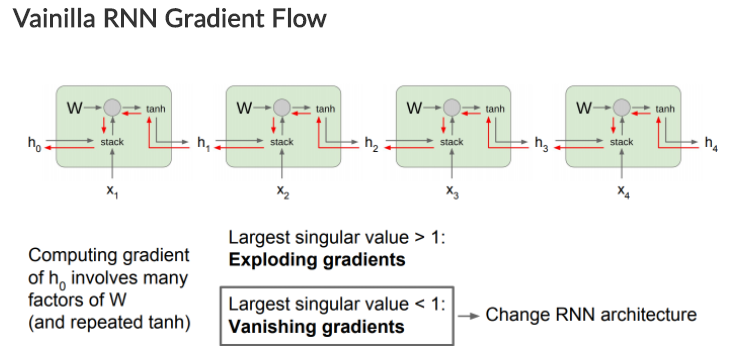
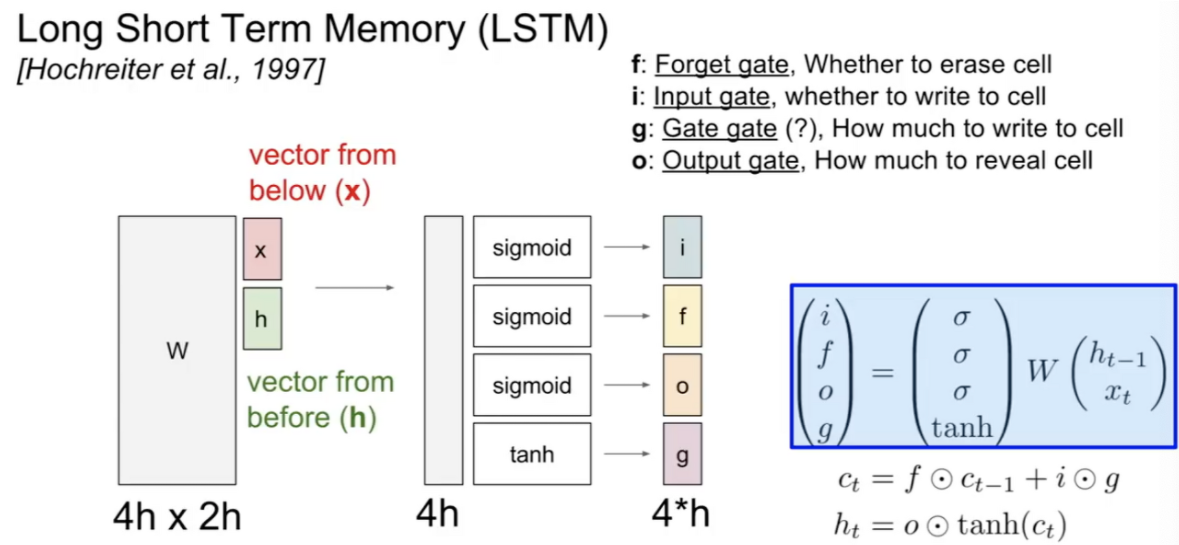
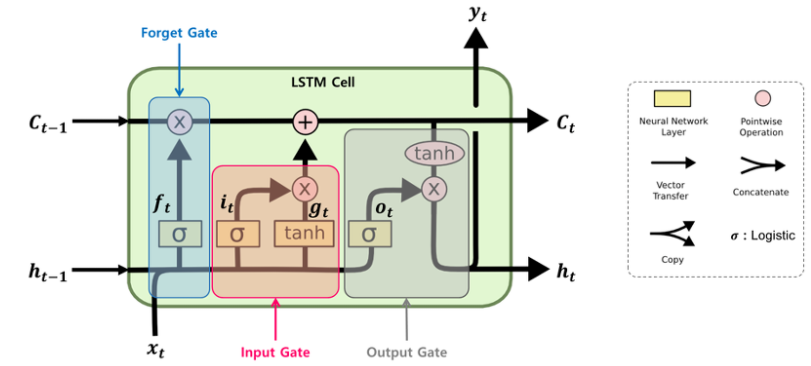
LSTM
위에서 RNN이 가지고 있던 Vanishing gradients의 문제를 완하시키기 위해서 Long Short Term Memory(LSTM)구조가 등장합니다.
LSTM은 RNN과 다르게 f, i, o, g 4개의 값이 사용됩니다.
- i : input gate @sigmoid
- 현재 입력 값을 얼마나 반영할 것인지
- f : forget gate @sigmoid
- 이전 입력 값을 얼마나 기억할 것인지
- o : output gate @sigmoid
- 현재 셀 안에서의 값을 얼마나 보여줄 것인지
- g : gate gate @tanh
- input cell을 얼마나 포함시킬지 결정하는 가중치, 얼마나 학습시킬지 (-1, 1)
- 4개의 함수 Activation function 해석
i, f, o는 잊기 위해서는 0에 가까운 값을, 기억하기 위해서는 1에 가까운 값을 사용하기 위해서 sigmoid를 사용 하였습니다. 마치 스위치와 같은 역할을 한다고 합니다.
g에서 tanh는 0~1의 크기는 강도, -1 ~ 1은 방향을 나타낸다고 생각하면 됩니다.
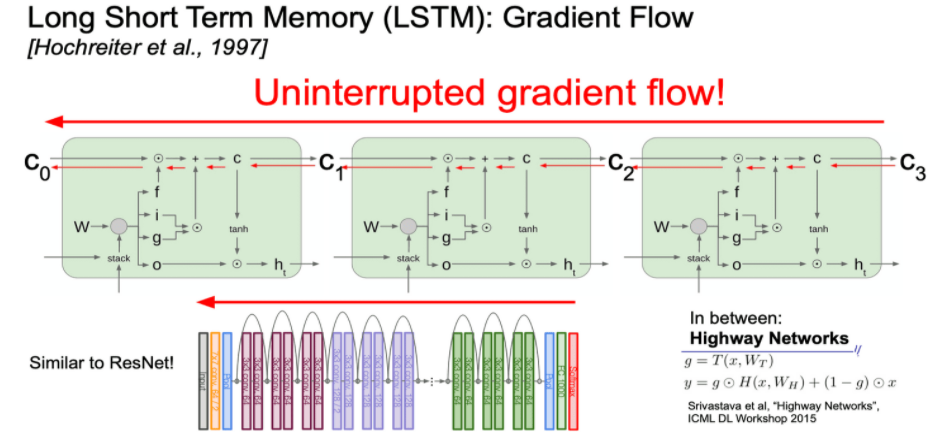
LSTM의 장점
- forget gate의 elementwise multiplication이 matrix multiplication보다 계산적 효율성을 가집니다.
- forget gate 값을 곱하여 사용하므로 항상 같은 weight값을 곱해주던 위 형태와 다르게 입력에 따라 다른 값을 곱해주어 exploding 또는 vanishing 문제를 피하는 이점을 가집니다.
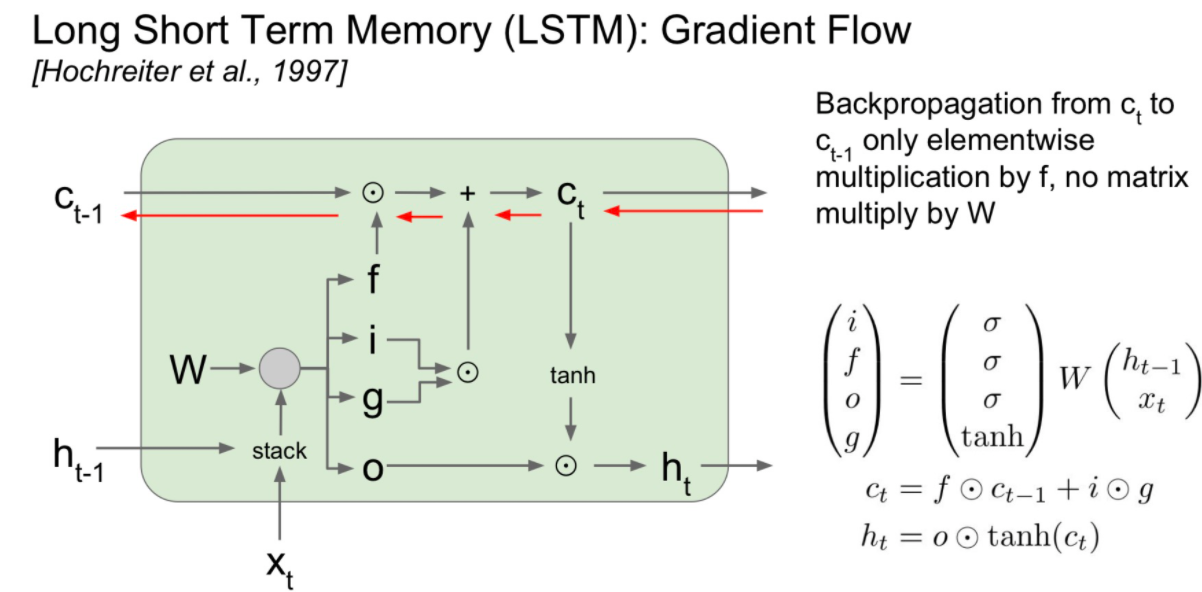
- forget gate의 sigmoid 값으로 bias를 1에 가깝게 만들어주면 vanishing gradient를 많이 약화시킬 수 있습니다.
- Gradient를 구하기 위해서 W 값이 곱해지지 않아되기 때문에 마치 고속도로 처럼 gradient를 위한 빠른 처리가 가능합니다.
- 위에서 사용한 개념은 마치 ReNet의 residual block과 비슷하다고 생각할 수 있습니다.
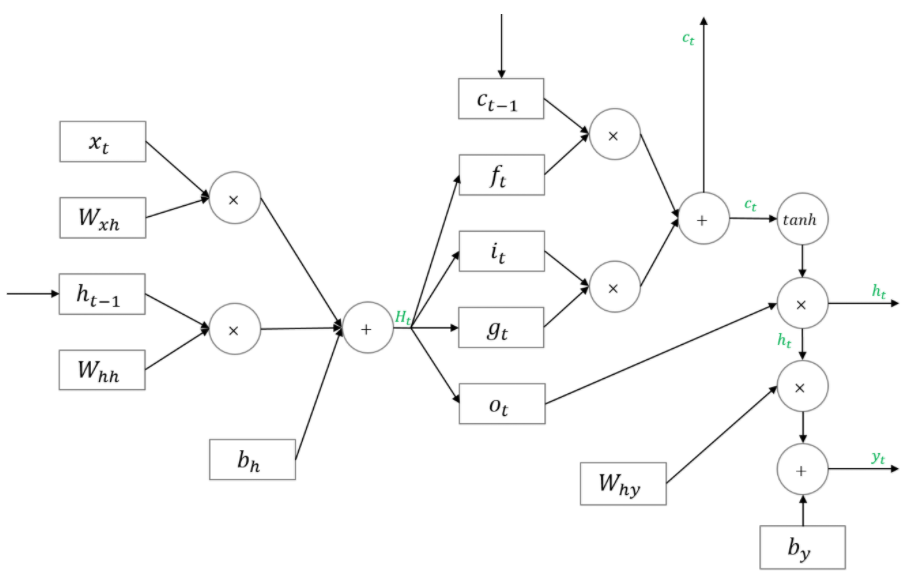
LSTM Backpropagation
이 또한 ratsgo's blog을 참조하였습니다.
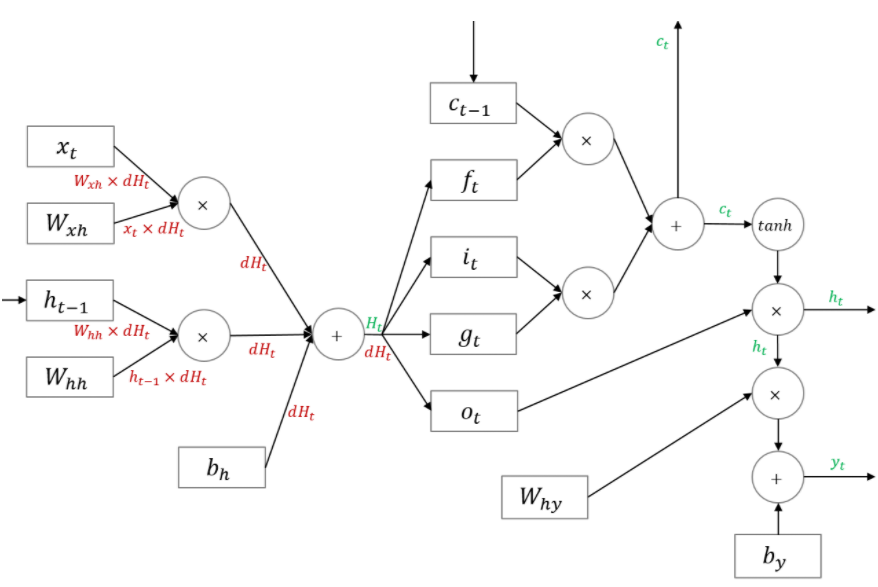
LSTM의 순전파가 아래와 같다고 합시다.
먼저 f,i,o,g 전 함수까지 역전파를 한 모습은 아래와 같습니다.
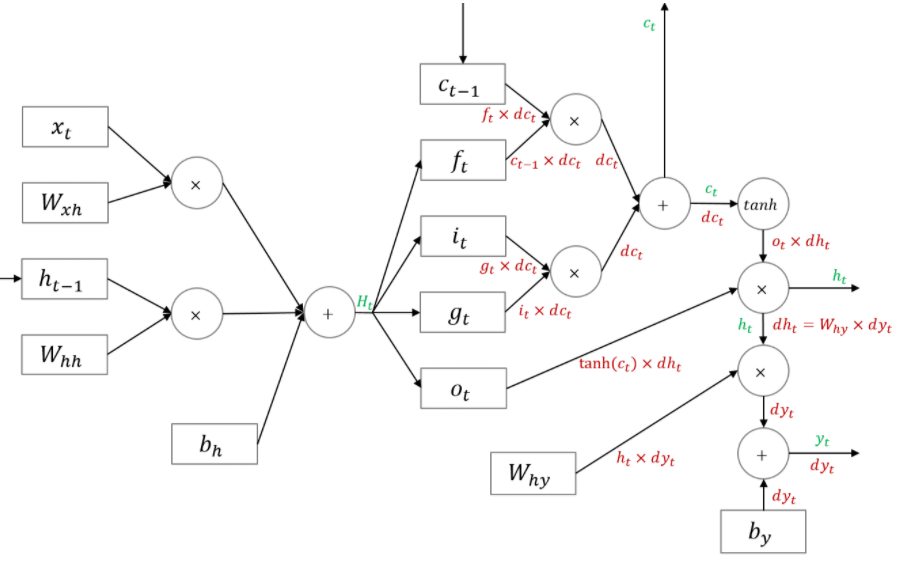
아래는 각 sigmoid 함수와 tanh의 activation의 역전파에 대한 설명입니다.
sigmoid의 gradient 값은 (1-sigmoid(x)) x sigmoid(x)이며,
tanh의 gradient는 1-tanh^2(x)입니다.
이를 적용하여 역전파 한 것이 아래의 모습입니다.
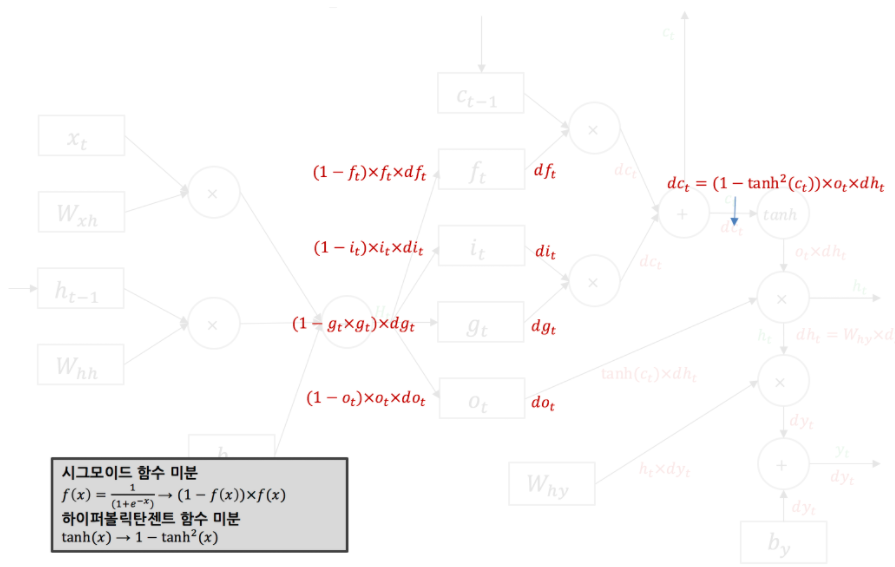
이후 입력과 hidden state에 역전파의 결과는 입니다.
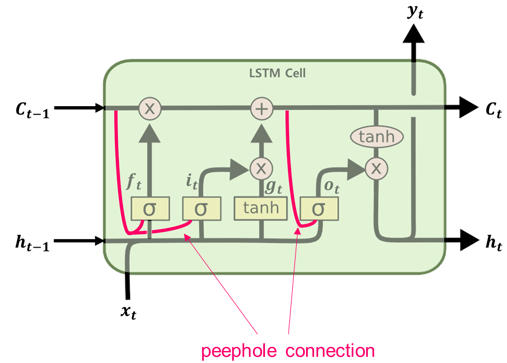
LSTM 핍홀 peephole 연결
핍홀(peephole) 연결은 2000년 F.Gers와 J.Schmidhuber가 'Recurrent Nets that and Count'논문에서 제안한 LSTM의 변종입니다.
기존 LSTM의 gate controller(f, i, o)는 입력 xt 와 ht-1만 입력으로 가집니다.
이 논문에서는 아래와 그림과 같이 다른 입력들도 볼 수 있도록 연결시켜주어 이전 입력 ct-1와 ct의 입력을 추가시켜, 좀 더 다양한 context(맥락)을 인식할 수 있습니다.
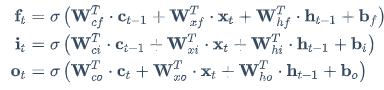
LSTM 파이썬 코드
혹시 LSTM의 파이썬 코드를 보고 싶은 분은 ratsgo님의 코드를 참고하시면 될것 같습니다.
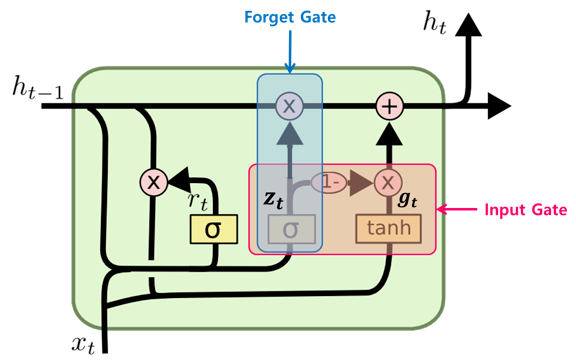
GRU
LSTM의 변형으로 GRU(Gated Recurrent Unit) Cell도 있습니다.
2014년에 K. Cho(조경현) 등에 의해 이 논문에서 제안된 LSTM 셀의 간소화 버전입니다.
- LSTM에서 ct와 ht가 하나의 ht로 합쳐졌습니다.
- rt의 추가로 과거의 정보를 어느정도 reset 할 것인지 정합니다.
- Update를 위해 사용되던 f와 i의 값이 zt와 (1-zt)인 하나 값으로 input과 hidden state의 update 정도를 정합니다.
- 현 시점의 정보 후보군(Candidate)을 계산합니다. gt는 과거 hidden state(은닉층) 값을 그대로 사용하지 않고 reset gate(rt)를 곱하여 사용합니다.
- 현 시점 hidden state(은닉층) 값은 update gate 결과와 Candidate 결과를 결합하여 계산합니다.
LSTM과 GRU의 자세한 설명이 필요하신분은 아래 블로그를 참조하시길 바랍니다.
- LSTM과 GRU 차이점
- 일반적으로 LSTM과 GRU은 거의 비슷한 성능을 가집니다.
- GRU가 LSTM보다 단순한 구조를 가져 학습이 더 빠르다고 합니다.
- 이를 비교하는건 애매하므로 하이퍼파라미터를 더 빨리 찾은 모델을 사용하면 된다고 합니다.

- RNN의 학습 최적화 방법
- Skip connection : residual block과 비슷합니다.
- Dropout (잘 쓰이지 않음) : Weight를 모든 step에서 공유하기에 별로 안좋음, Truncated 시에 Dropout 하는 node를 통일 시켜야합니다.
- Vocabulary 문제: 단어가 너무 많은 경우, 일부 단어만 뽑아 확률을 구하는 방법입니다.

많은 도움 받고 갑니다 감사합니다!