소개
- 이 글은 논문을 읽고 정리하기 위한 글입니다.
- 내용에 오류가 있는 부분이 있다면 조언 및 지적 언제든 환영입니다!
INTERSPEECH 2020, TASLP 2021 에 올라온 논문입니다. (Paper1, Paper2, github)
Citation
[1]
@article{Horiguchi2020EndtoEndSD,
title={End-to-End Speaker Diarization for an Unknown Number of Speakers with Encoder-Decoder Based Attractors},
author={Shota Horiguchi and Yusuke Fujita and Shinji Watanabe and Yawen Xue and Kenji Nagamatsu},
journal={ArXiv},
year={2020},
volume={abs/2005.09921}
}
[2]
@misc{horiguchi2021encoderdecoder,
title={Encoder-Decoder Based Attractor Calculation for End-to-End Neural Diarization},
author={Shota Horiguchi and Yusuke Fujita and Shinji Watanabe and Yawen Xue and Paola Garcia},
year={2021},
eprint={2106.10654},
archivePrefix={arXiv},
primaryClass={eess.AS}
}Introduction
Background
- BLSTM-EEND
- Permutation-Invariant (PIT) loss 의 등장으로 end-to-end diarization 학습이 가능하게 됨 (BLSTM-EEND)
- 기본적인 EEND Architecture 형태 제안 (Input 구조, Encoder Block, 출력 형태 등)
- SA-EEND
- 기존 BLSTM-EEND의 기본
Encoder block을 Transformer Encoder 인Self-Attention으로 변경한 Self-Attention EEND (SA-EEND)의 등장- 주어진 입력 wav내의 화자 관계
Relation information을 해석하는데 있어서, self-attention의global attention특성이 좋은 성능을 보임을 확인- 저자는 Transformer의 Multi-header Attention의 각 header가 이
각 화자의 특징을 찾아내는 것으로 해석했음 (But, 하지만 개인적인 실험 결과는 그런 경향성을 보이지 않았음... 더 연구가 필요해 보임, 예시는 다음에 기회되면 ^_^)- 자세한 내용은 이전 SA-EEND 리뷰 참고!
Previous Limitation
- 1) Fixed-number of speaker
- 학습시 입력 음원 내 찾을 수 있는 최대 화자 수가 정해져 있다.
- 2) Fixed speaker attractor
- SA-EEND의
마지막 Fully-Connected layer의 weight(S x D, S: max number of speaker, D: hidden dim)를,S개의 1xD 길이를 가지는 speaker attractor로 해석할 수 있다.- 이 경우 test시에도 학습된
고정된 speaker attractor (weight)를 사용하여 최적의 speaker attractor가 아닐 수 도 있다.- 3) Degradation of Performance in more than three speaker
- 또한 SA-EEND는
3명 이상인 경우, x-vector 보다 성능이 좋지 않음. 아직 여러 명의 경우 Relation information 을 잘 해석하지 못함
Main Proposal (Contribution)
- 1) Encoder-Decoder Based Speaker Attractor(EDA)
- 기존의 고정된 화자 수와 weight 값 형태로 고정되어 있던
speaker attractor를 LSTM 기반 EDA로 부터 추출하여 사용하는 방법은 제안- 2) SAD(Speech Activity Detection) Post-Processing
- EEND에서 나온 SAD 결과만을 사용하는 것이 아닌,
SAD 만을 담당하는 모듈로 부터 나온 결과를 이용한 후 처리알고리즘은 제안- 3) Iterative inference, Iterative inference+DOVER-Lap
- EEND-EDA도 여전히
학습되지 않은 화자 수에 경우 찾지 못하는 단점을 가지고 있음- Iterative inference 라는 방법을 이용해 많은 화자수가 존재하는 경우에 찾아내는 방법을 제안함 (아직 불안정하다고 생각됨)
Proposed Method
Encoder-Decoder Attractor (EDA)
Intro
- 이 논문에서 중심적으로 제안한 새로운 방법이다.
- 기본적으로 SA-EEND의 Encoder Block을 앞단에 동일하게 사용한다.
- 하지만, 여기서
SA-EEND에서 사용하던 마지막 Linear 대신에 이를 LSTM 기반Encoder-Decoder Attractor(EDA)의 출력 Attractor를 이용한다는 점이 다르다.- 이 방법론에 내가 생각하는 가장 중요한 intuition은 바로!,
- SA-EEND가 생성한 Embedding 에 대해
가변적인 Speaker Attractor vector를 생성하자!이다.- 기존 SA-EEND의 Fully-Connected layer의 weight는 학습된 Speaker Attractor 로 생각할 수 있으며, 고정되어 있다.
- 또한
고정된 개수의 Speaker Attractor만을 다룬다.- 여기서 EDA 는 SA-EEND에서 생성한 Embedding 의 상태를 살펴보고, 이에 맞는 적절한
화자 수와화자 Attractor를 만들어보자! 이다.
Architecture
- 0) Input:
raw input -> T x 345(23 log-mel x 15 (context length, near 7 frame))
- STFT: window size: 25ms, hop size: 10ms
- log-mel: 23 log-mel
- Stacked Frame and Sub-Sampling: context length: 7, step size: 10, so, one frame sampled 10fps (1초에 10개 Frame 생성)
- 1) SA-EEND block:
T x 345 -> T x 256
- 1.1 FC layer:
T x 345 -> T x 256(T 는 Total Frame)
- Transformer 입력을 위한 embedding 과정
- 1.2 Encoder Block: (Self-Attention)
T x 256 -> T x 256
- Transformer (Self-Attention) 을 통한 Frame 별 Audio Feature Encoding 과정
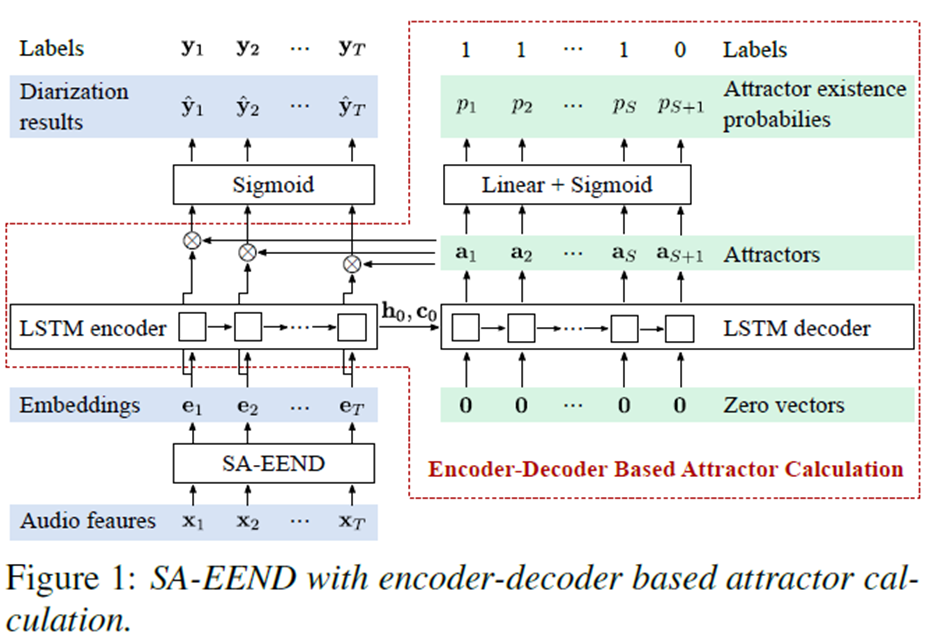
- 2) Encoder-Decoder Attractor
- 2.1 Encoder (LSTM):
T x 256 -> H(1 x 256), C(1 x 256)
- SA-EEND block에서 생성된 embedding을 encoder 하는 과정이다.
- 본 실험에서는 embedding을 LSTM에 넣을때,
시간 순서대로 넣은 방법(Sequential)과무작위로 섞는 방법(Ramdom)으로 넣는 2가지 방법을 실험했다실험 결과는 Random이 좋았다.- 이 LSTM에서 생성된
H(Hidden State)와C(Cell)정보를 Decoder에 입력으로 전달한다.- 2.2 Decoder(LSTM): `H(1 x 256), C(1 x 256), Z(1 x 256) -> (1 x 256)
- Encoder 로 부터 Hidden state 와 Cell 정보를 가져오며, input으로 는 1 x 256의 zero vector 을 입력으로 받는다.
- 이에 대해서 한 명의 Speaker 을 대표하는 1 x 256 크기의
Speaker Attractor를 생성한다.- 2.3 Speaker Exists Decider (FC layer + Sigmoid):
1 x 256 -> 1 x 1
- 여기서는 EDA를 joinly 하게 학습하기 위한 추가적인 auxiliary loss를 사용한다.
- 이 Auxiliary loss 는 EDA가
화자의 수를 정확하게 예측 하였는지에 대해서 평가한다.- FC의 Layer의 결과가 일정 임계치(threshold) 값 이상인 경우 1 아닌 경우 0으로 정한다.
- 여기서 각 숫자의 의미는
1: 추가적인 Speaker 가 존재함을 나타낸다.0: Silence Speaker를 나타내며, Stop Criteria 로 LSTM Decoding 작업을 중지한다.- 여기서 FC layer의 결과가 0 이 나올때 까지 생성된 Attractor의 수가 S개라고 한다면, S-1는 EDA가 예측한(estimated) Embedding내 화자의 수이다.
- 2.4 Use Speaker Attractor:
T x 256 -> T x S-1(S: number of speaker attractor, last sepaker attractor는 silence speaker로 제외)
SA-EEND Block 에서 생성된 Embedding(Not Encoder output)에Decoder에서 생성된 Speaker Attractor를 곱해서Speaker 별 Frame-speaker activity을 구해낸다.- 이 출력을 이용해서 SA-EEND와 동일한 PIT Loss를 이용하여 학습을 진행한다.
Data
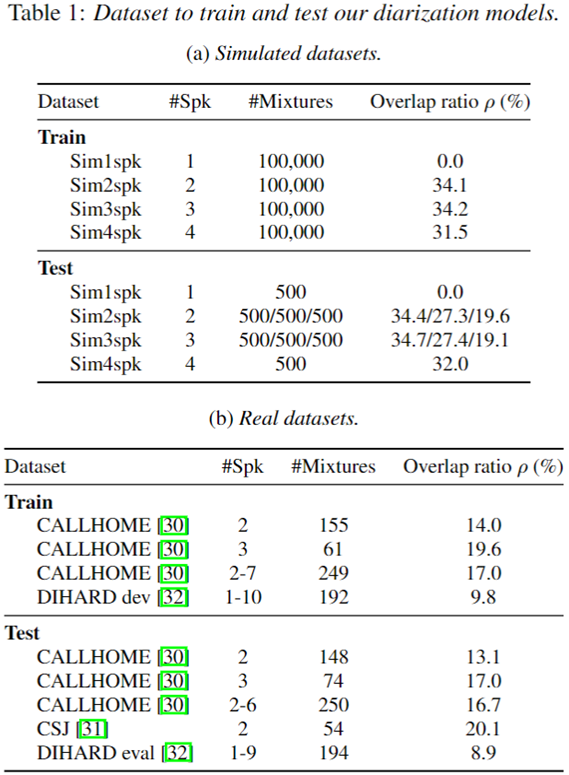
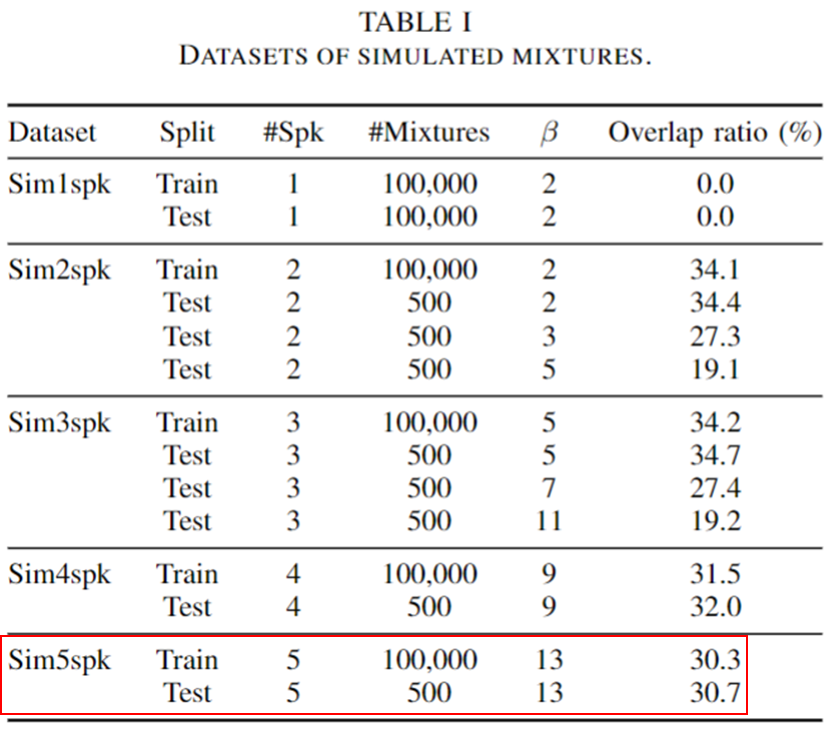
- SA-EEND에서 사용한 SRE 데이터를 동일하게 사용하였으며, 추가적으로 2명뿐 아니라 1-4(5)명에 대한 추가적인 simulation 데이터를 다른 beta 값을 이용하여 생성했다.
- 1,2,3,4(,5) 명에 대해서 각각 10만개의 simulation 데이터를 생성했다.
- Training strategy
- 1) 기존 2-speaker simulation 데이터만 이용하여 100 epoch 학습 진행 (norm warm-up 스케줄러 사용)
- 2) 1,2,3,4(,5) speaker simulation 데이터를 모두 이용하여 25 epoch 학습 진행
- 3) Adaptation: CALLHOME real dataset adaptation를 위해서 100 epoch, 1e-5 learning rate, adam 학습 진행
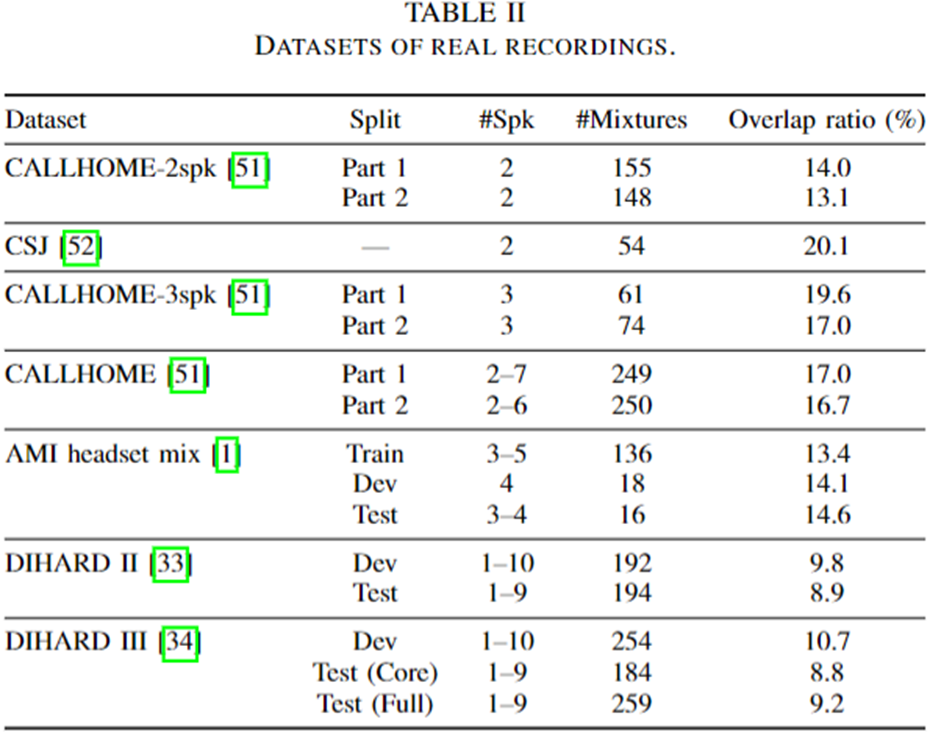
INTERSPEECH 2020 실험 데이터 셋
TASLP 2021 증강된 실험 데이터 셋
Training
- Objective Function (Loss Function)
- Permutation Invariant Training(PIT) Loss
- 기존 SA-EEND에서 사용한 PIT Loss 와 동일
- 각 화자별 diarization error 정도에 대한 loss
- Attractor Loss
- EDA의 Decoder에서 화자 수를 정확하게 예측하였는지에 대한 loss
- Total Loss
- Total Loss = PIT loss + (alpha) * Attractor Loss
SAD(VAD) Post-Processing
- 목적
- SAD(VAD) 결과를 후처리로 이용하여 EEND의 False Alarm과 Miss Alarm를 줄이자.
- 알고리즘
- False Alram(FA)를 별도의 SAD 결과로 없애자
- Miss Alarm(MI)를 SAD를 통해서 줄이자. SAD에서 존재한다고 했다면 EEND의 각 화자 결과중 가장 높은 확률 값을 가지는 화자가 존재한다고 정하자
Iterative Inference
- 목적
- 학습시 사용된 화자수 이상인 경우 잘 찾지 못하는 EEND-EDA의 단점을 극복하고자 하였다.
- 6명 이상의 화자 수에 대해서도 찾아내려고 한 후 처리 방법
- 알고리즘
- EEND-EDA가 찾을 수 있는 최대 화자수(5명) 만큼 EEND-EDA에서 찾은 경우 반복적으로 inference를 취하는 방법이다.
- 만약 EEND-EDA의 출력에 5명의 화자가 나왔다면, Silence 부분에 대해서 EEND-EDA의 재 입력으로 넣어준다.
- 화자 수가 5명이 나오지 않을때 또는 Silence Frame이 존재하지 않을 때까지 Inference를 반복한다.
- 단점
- Iterative Inference 시에 Silence 부분만 재 입력으로 넣어주게 되어
이전에 나온 화자들과의 Overlap이 되는 경우를 무시하게 됨- 이를 위해 Iterative Inference++ 알고리즘 제안됨

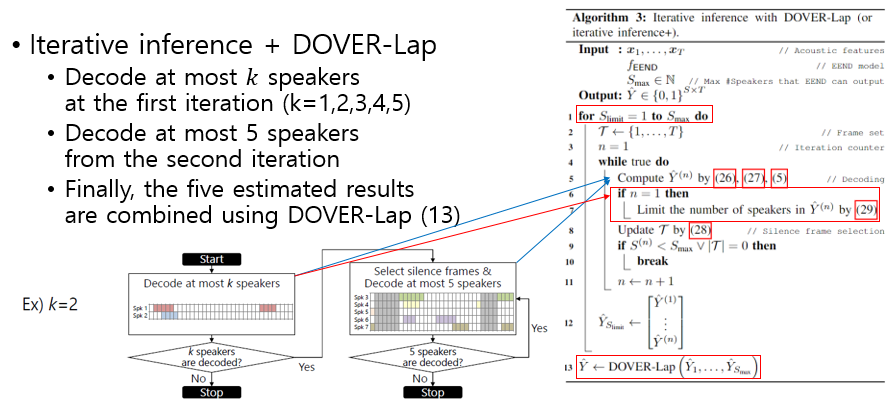
Iterative Inference++
- 목적
- Iterative Inference시에 이전에 등장한 화자와 이후 Iteration에서 등장한 화자 간의 Overlap 여부를 확인할 수 없는 단점에서 시작됨
- 알고리즘
- 시작하기전: 일단 6~10 명인 경우에 더 많이 집중하는 경향이 있음 (DIHARD 대회 기준)
- 1) 첫번째 Inference 에서는 출력 화자수를 최대 k개로 정해 놓고 시작한다.
- 2) 첫번재 이후 Inference에서는 기존 Iterative Inference 와 동일하게 진행한다.
- 3) k를 1~5명에 대해서 위를 모두 반복한다.
- 4) 5개의 출력에 대해서 DOVER-Lap를 통해 출력 앙상블 한다.
- 장점
- 처음 inference의 화자 수를 조절하여 곂쳐지지 않는 화자 수를 최소한으로 하고, 여러 조합에 대한 결과를 DOVER-Lap으로 앙상블 하였다. DOVER-Lap에 대한 자세한 내용은 다른 글에서 다루도록 하겠다.
Experiments Result
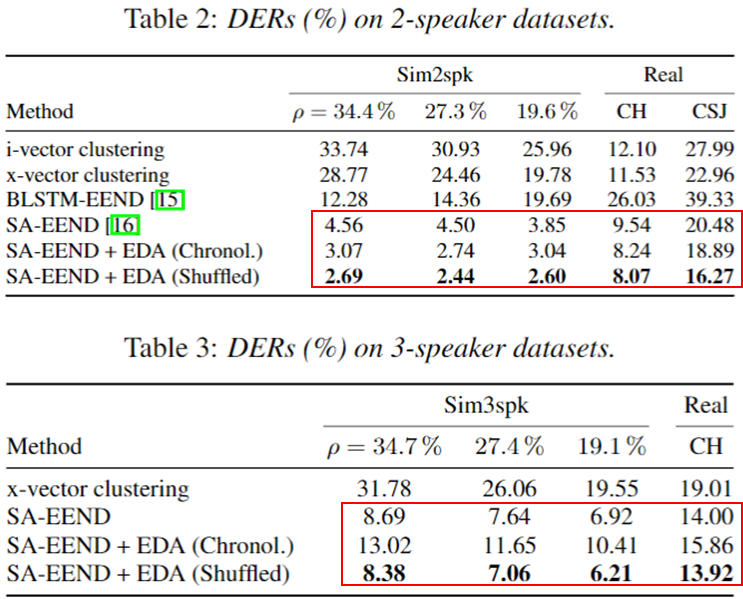
Fixed Number of Speaker
- 2 speaker dataset 결과 (simu, CH, CSJ)
- x-vector, SA-EEND을 능가하는 성능을 보임.
- 3 speaker dataset 결과 (simu, CH)
- SA-EEND와 비슷한 성능을 가짐, x-vector보다는 좋음
- Effect of the input order
- encoder 입력을 시간 순차적으로 주는 것(Sequental order) 보다 랜덤적으로 주는 것(Random order)가 더 좋은 성능을 보였다.
- Embedding Subsampling 관련
- 전체 Embedding이 아닌 일부 Embedding만 Subsampling하여 EDA의 입력으로 주어도 나쁘지 않은 성능을 보이는 것을 볼 수 있다.

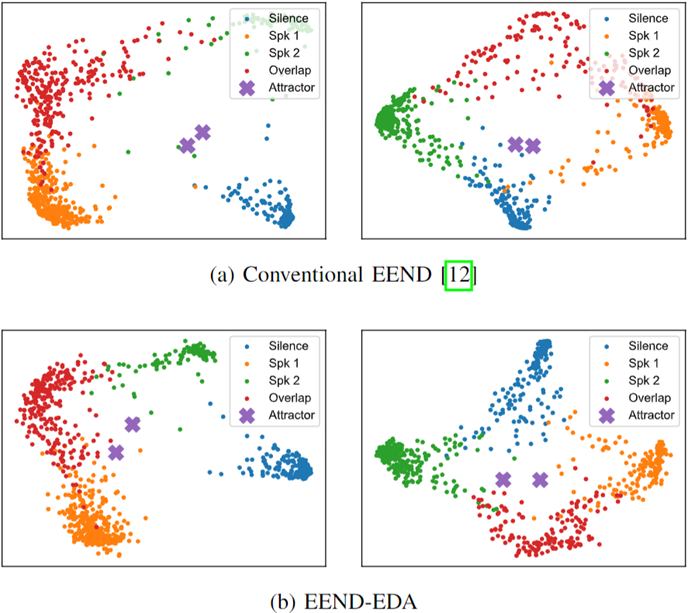
- Visualization
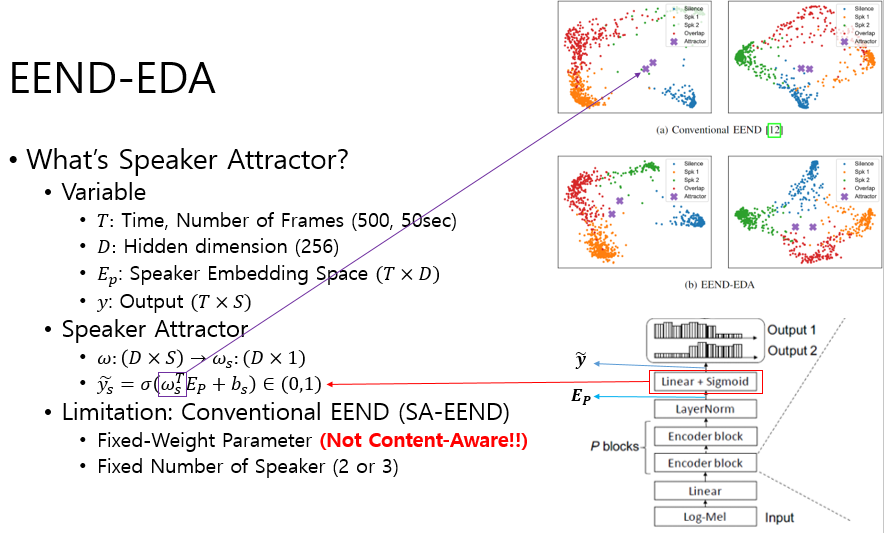
- 본 실험에서 2 speaker simulation dataset에 대해서 PCA visualization 결과를 보여준다.
- 여기서 2명에 대해서 괜찮은 speaker attractor 위치를 구해내는 것을 확인 할 수 있다.
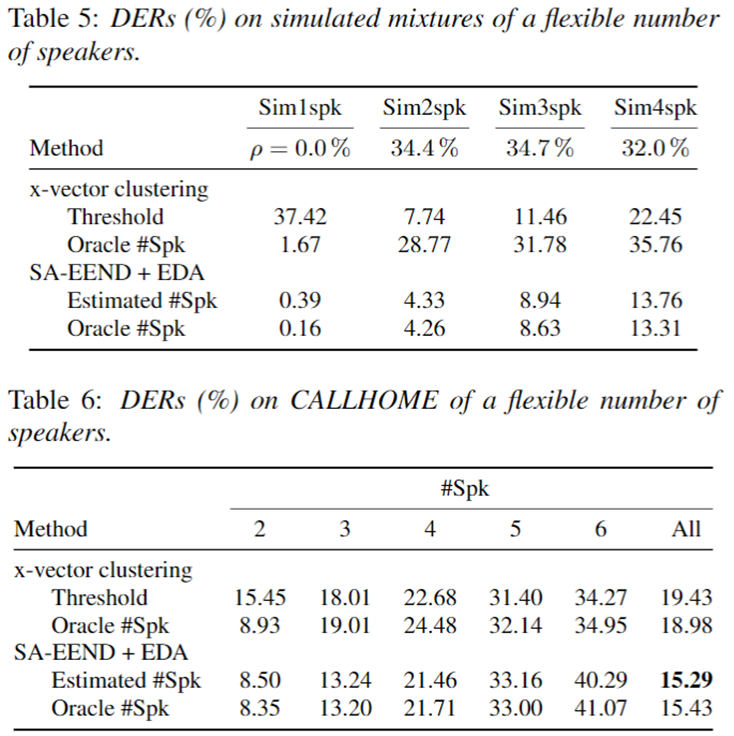
Flexible Number of Speaker
- Simulation dataset 결과
- x-vector와 EEND-EDA 과의 비교 실험 결과 모든 면에서 더 좋은 성능을 보였다.
- simulation datatset은 일반적인 real data 보다 높은 overlap ratio 값을 가지기 때문에 overlap 상황에서는 더 좋은 성능을 보인다고 볼 수 있다.
- CALLHOME dataset 결과
- 1-3명 화자 수에 대해서는 EEND-EDA가 x-vector보다 뛰어난 성능을 보여준다.
- 4명 화자의 경우 EEND-EDA가 x-vector와 비슷하며, 5이상 부터는 x-vector가 더 좋은 성능을 보인다.
- DIHARD I eval
- x-vector 의 후처리 전 성능보다는 EEND-EDA가 좋았지만, x-vector에 후처리를 적용한 성능을 이기지 못했다.
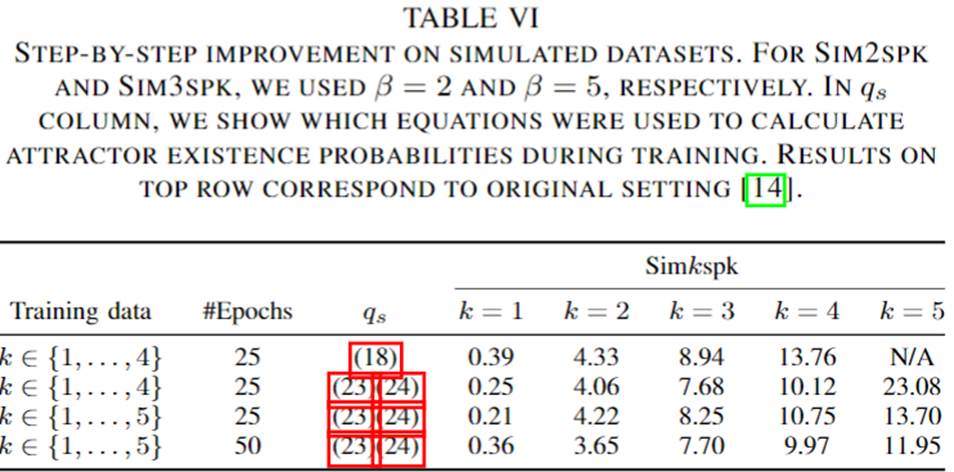
EDA 학습 전략 관련
- EDA 학습 관련
- EDA의 출력인 Speaker Attractor에 대한 화자 여부를 Linear와 Sigmoid 를 통해서 Speaker Existance 를 판별한다.
- 여기서 학습 시, Loss 값이 SA-EEND Block와 EDA에 Back-Propogation 되는 것이 학습에 좋지 않은 영향을 미치는 것을 발견했다고 한다.
- TASLP 2021 논문에서는 이러한 점에서 Loss 값을 Attractor 화자 존재 여부 판별에 관여하는 Linear 학습에만 Back-Propogation 되도록 변경하였고 이것이 성능 향상이 있었다고 말한다. (아래 row 1-2 비교 Table 참고)

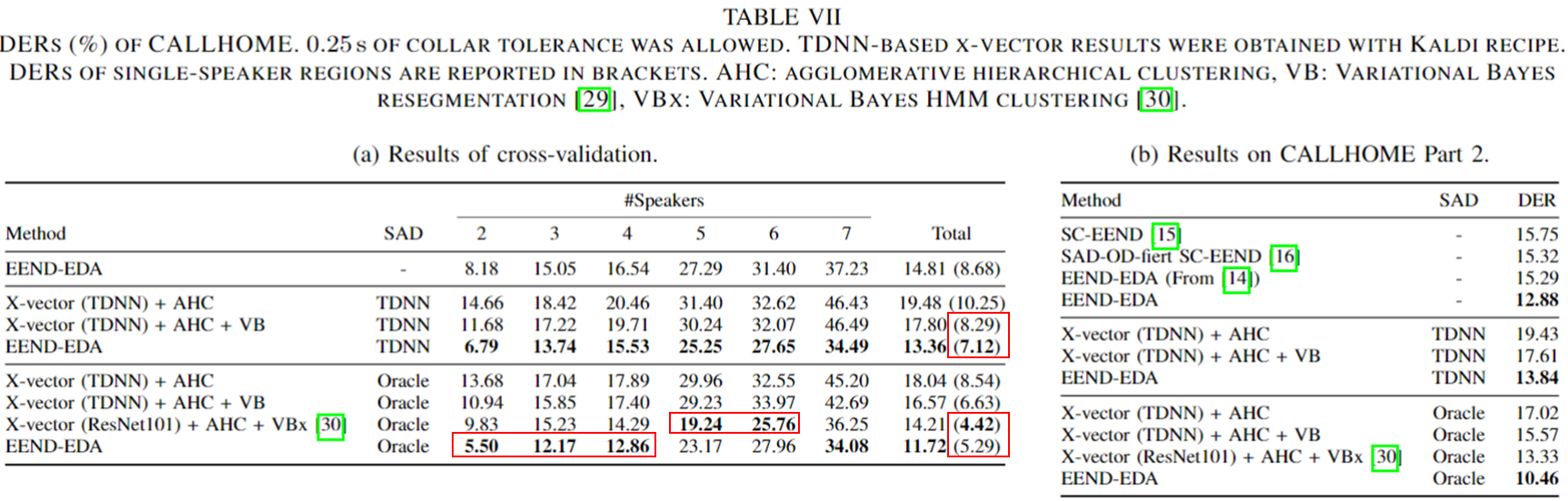
SAD Post-Processing 실험 결과
- SAD Post-Processing의 CALLHOME1 dataset Validation 결과 관련
- 아래 표 왼쪽은 학습 CALLHOME1 dataset의 Validation DER 결과이다.
- row 1,4 는 EEND-EDA의 결과와 TDNN 기반 SAD의 결과로 Post-Processing를 거친 경우 성능이 향상되는 것을 볼 수 있다.
- 추가적으로 ( ) 안에 있는 DER 결과는 Overlap 이 아닌 곳에 대한 결과 인데, row1,3 결과만 보았을때는 Overlap이 아닌 곳에서 EEND-EDA의 결과가 X-vector+AHC+VB 보다 낮은 성능을 보인다. 하지만, SAD Post-Processing를 거친 결과인 row3,4를 보면 보다 나은 성능을 보임을 볼 수 있다.
- SAD Post-Processing의 CALLHOME2 Dataset Eval set 결과 관련
- CALLHOME Eval set 결과는 아래 오른쪽 테이블과 같다.
- 정확한 이유는 적혀있지 않지만, row4,7 결과에서 성능이 저하됨을 확인 할 수 있다.
- CALLHOME에서는 SAD Post-Processing이 좋지 않은 결과를 보이지만 이후 DIHARD 대회 실험 결과에서는 좋은 결과를 보인다.
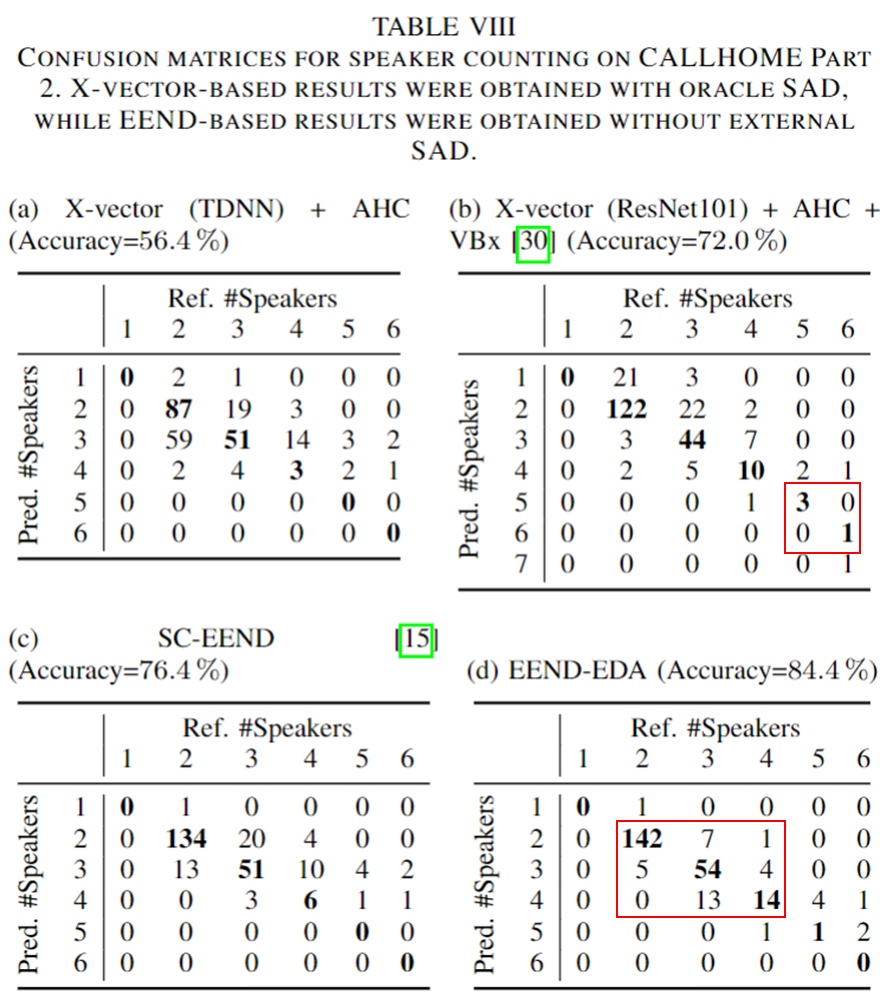
EDA의 화자수 예측 관련 Confusion Matrix 결과
- CALLHOME 데이터 셋 기준 화자 수 예측
- 4가지 방법에 대한 결과 X-vector+AHC, X-vector+AHC+VBx, SC-EEND와 EEND-EDA 결과 비교 결과는 아래 표와 같다.
- 결론, 2~4명 화자까지는 EEND-EDA가 잘 맞추지만, 5명 이상인 경우는 아직 X-vector+AHC+VBx 의 결과가 더 좋다.
AMI Dataset 결과
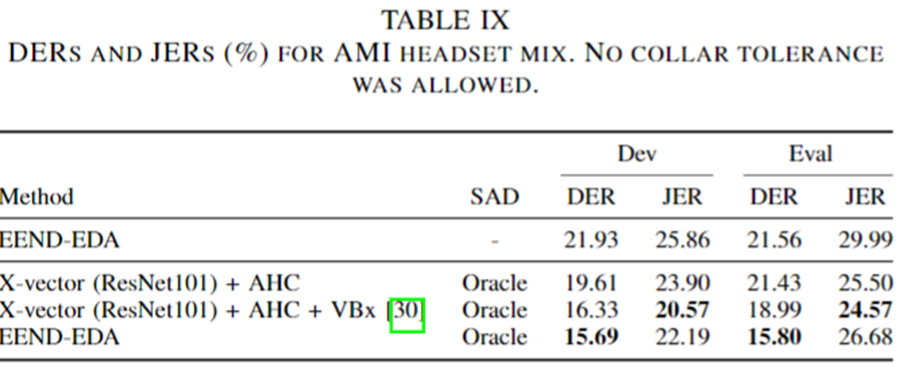
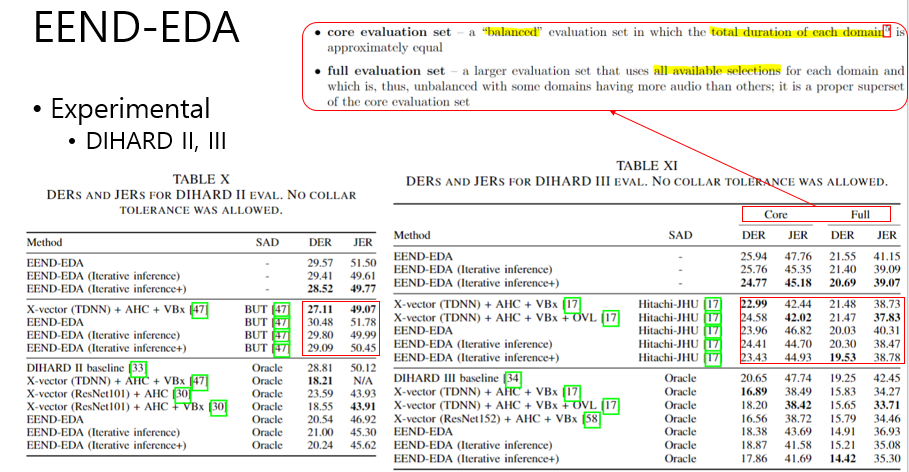
DIHARD 데이터셋 결과
- DIHARD II (왼쪽 Table)
- EEND-EDA 에 대해서 Iterative Inference/Iterative Inference++의 효과가 있음을 보여준다. (row 1-3)
- SAD Post Processing 결과가 DIHARD II에 대해서는 좋지 않았음을 보여준다. (row 1-3, 5-7)
- 아직까진 X-vector + AHC + VBx의 성능을 뛰어넘지 못했음을 보여준다. (row 4,7)
- DIHARD III (오른쪽 Table)
- 데이터셋 관련
CORE: 전체 Evaluation 셋 중 전체 길이와 및 Domain을 Balanced 하게 만든 Eval Set이다.FULL: 전체 Evaluation 셋- Iterative Inference/Iterative Inference++가 효과적임을 보인다. (row 1-3)
- Hitachi-JHU 라는 SAD 모듈을 이용하였을때, DIHARD III 에서 보다 나은 성능을 보임을 볼 수 있다.
COREset에서는 아직 X-vector가 좋은 성능을 보이지만,FULLset 에서는 EEND-EDA가 좋은 성능 추의를 보인다. (row 5, 8)- Oracle SAD 결과를 이용한 결과에 대해서도 일관된 경향성을 보인다. (row 9~15)
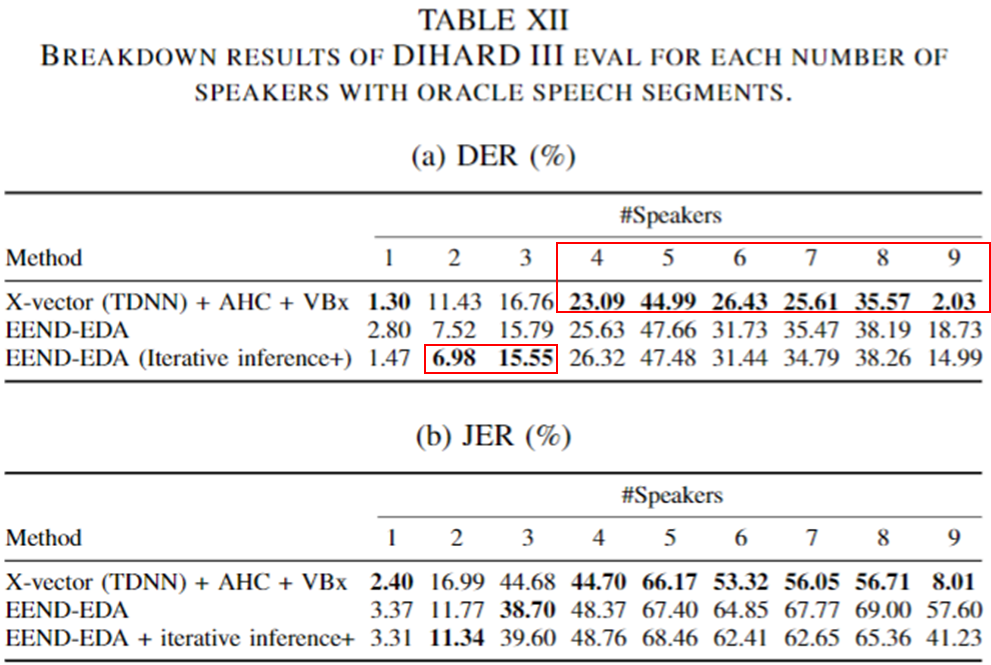
- DIHARD III 화자별 성능
- 2~3 화자 수에 대해서 EEND-EDA가 좋은 성능을 보임을 볼 수 있다.
- 하지만, 4명 이상에 대해서는 아직 X-vector가 좋은 결과를 보인다.
Conclusion
- LSTM기반 Encoder-Decoder Attractor를 이용하여 나름 Flexible Number of Speaker를 다룰 수 있게 되었다.
- SA-EEND에서 생성한 Embedding을 상황에 따라서 더 적절한 Attractor를 생성할 수 있었다.
- 하지만 3명 simulation 데이터 성능과 같은 경우 SA-EEND와 비슷하였으며, 4명이상인 경우 x-vector와 비슷하거나 좋지 못한 성능을 보이는 것을 보아 더 연구가 필요하다.

Audio & Speech AI Researcher 입니다! Speaker Diarization & Speaker Verification 연구 경험을 가지고 있고, 전반적인 Speech Representation 에 대해서 관심을 가지고 있습니다!