[FS-EEND 리뷰] Online end to end diarization handling overlapping speech and flexible numbers of speakers
0
EEND
목록 보기
5/11
소개
- 이 글은 논문을 읽고 정리하기 위한 글입니다.
- 내용에 오류가 있는 부분이 있다면 조언 및 지적 언제든 환영입니다!
INTERSPEECH 2021 논문으로, Online 상황에서 EEND method를 적용하고자 연구한 논문입니다. (Paper, github)
Citation
@misc{xue2021online,
title={Online Streaming End-to-End Neural Diarization Handling Overlapping Speech and Flexible Numbers of Speakers},
author={Yawen Xue and Shota Horiguchi and Yusuke Fujita and Yuki Takashima and Shinji Watanabe and Paola Garcia and Kenji Nagamatsu},
year={2021},
eprint={2101.08473},
archivePrefix={arXiv},
primaryClass={cs.SD}
}Introduction
기존 EEND 사전 연구
- offline method
- SA-EEND, EEND-EDA, SC-EEND
- Faster loss calculation approach [1]
- online method
- Speaker-tracing buffer (STB): 2명의 화자로 제한되어 있음 [2]
- BW-EDA-EEND: 10초인 large latency 필요로 함
[1] Qingjian Lin, Tingle Li, Lin Yang, Junjie Wang, and Ming Li, “Optimal mapping loss: A faster loss for end-to-end speaker diarization,” in Odyssey, 2020, pp. 125–131.
[2] Yawen Xue, Shota Horiguchi, Yusuke Fujita, Shinji Watanabe, and Kenji Nagamatsu, “Online end-to-end neural diarization with speaker-tracing buffer,” arXiv preprint arXiv:2006.02616, 2020.
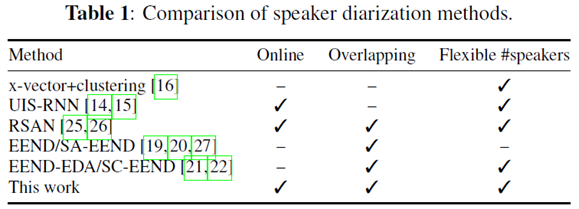
Related Work in Online Speaker diarization and Limitation
- Recurrent Selective Attention Networks (RSAN)
- 장점
- Online mode, overlapping speech, flexible number speaker 문제를 모두 다룰 수 있음
- 단점
- SD(Speaker Diarization) task 가 아닌 speech sparation 를 target으로 학습됨
- real recoding 환경에 적응하기 어렵다.
- real scenarios를 평가하기 어렵다.
본 논문의 제안
- Extend EEND model with STB(Speaker-tracing buffer)
- 기존 STB의 Computation Complxity 경량화를 통한 현실적 online method 실현
Proposed Method
FS-EEND (Flexible-number-of-Speakers EEND)
- 이 논문에서는 Flexible-number-of-Speakers를 EEND로 처리하기위한 FS-EEND를 제안한다.
- input
- 기존 EEND와 동일하게 Stacked Sub-Sampling 사용
- 실시간 입력은 짧은 chunk 크기로 online 으로 도착한다고 가정한다.
- Output: Estimated speakers() 와 time-sequence(T) 로 사용
- EEND Online Method의 문제점
inter-block label permutation problem
- 추적된 화자의 index는 chunk 마다 달라 전체 record에서 일관된 결과를 얻을 수 없다.
- 즉, EEND가 1번째 Slot에 예측한 화자가 다음에는 다른 slot에 예측될 수도 있다.
- 이를 해결하기 위해 inference 시에 Speaker-Tracing Buffer (STB) 방법을 사용을 제안한다.
Speaker-Tracing Buffer (STB)
- SA-EEND에서 Chunk 간에 일관된 index를 가지지 못하는 문제(
inter-block label permutation problem)를 해결하기 위한STB가 제안됨 [1]- 한계점
overlapping speech다루지 못함- 높은 계산 복잡도 문제
- 이 논문에서는 이 문제를 해결한 extended STB를 제안한다.
[1] Yawen Xue, Shota Horiguchi, Yusuke Fujita, Shinji Watanabe, and Kenji Nagamatsu, “Online end-to-end neural diarization with speaker-tracing buffer,” arXiv preprint arXiv:2006.02616, 2020.
Extended STB
- 여기서는
화자 수의 따른 유연한 길이의 STB를 사용한다.- Enrollment Rule
- 화자수가 전에 비해서 늘어났을때, 즉
새로운 화자가 추가되는 경우 STB의 zero-padding를 추가한다.- Update Rule
- STB 에는
이전 정보와 현재 정보를 적절하게 선정해야하여 저장해야한다.- 기존에는 correlation coefficient를 사용하였지만, 여기서는
Covariance를 이용하여 더 적은 계산량으로 효율적으로 처리하였다.- 위에서 STB를
update하기 위해서 4가지 종류의 방법을 제안하고 이들의 성능을 비교하였다.
Algorithm
- 입력은
실시간으로 chunk size의 입력이 들어온다.- STB 는 L의 길이를 가지며
최대 길이는 L_{max}로 제한한다.- STB는
이전 입력 값들을 적절히 저장해 놓은 X^{buf}이다.
알고리즘 순서는 다음과 같다.
- 1) 이전에 입력 와 실시간 입력 를 EEND의 입력으로 넣어준다.
- 2) 함수는 출력 Y의 speaker의 수를 측정하는 함수로
이전에 가지고 있는 화자수와현재 입력의 화자 수를 계산한다.

- 3)
이전 화자 보다 화자수가 늘어나면 Zero-padding를 적용한다.
- 대부분의 경우 화자 수가 늘어나며 줄어나는 경우에는 길이를 줄여준다.
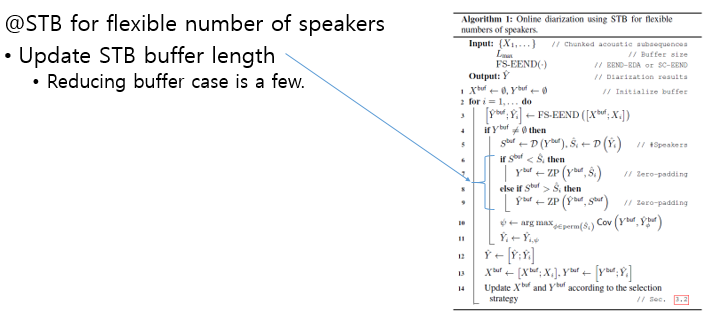
- 4)
Covariance값을 이용하여이전 STD 출력과 현재 출력간에 Matching Cost가 최소인 Permuation조합을 찾아Inter-block label permutation 문제를 해결한다.

- 5) Permutation 순서가 맞춰진 출력을 이전 출력 및 STB Buffer에 추가한다.
- 6)
STB의 길이가 최대 길이를 넘는 경우. 이를 위한Selection strategy알고리즘 4가지 중 한가지를 사용한다.

Selection Strategy
- 마지막에 STB의 최대 길이를 초과하는 경우
버려야 하는 버퍼가 생긴다. 이때어떤 것을 버리는 것이 좋은지에 대한 전략 연구로는 다음과 같다.- 1) First-in-first-out (FIFO)
- 2) Kullback-Leibler Divergence based selection (KD)
- KD란
두 확률 분포 간에 거리를 측정하기 위한 distance matrix 이다.- 여기서 Speaker의 분포는 uniform으로 가정한다. 즉
각 화자가 입력으로 들어올 확률은 Uniform하다.
- 3) Uniform Sampling
- 4) Weighted sampling using KLD selection
Uniform Sampling 과 KLD selection 를 적절히 조합하여 사용한다.
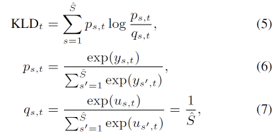
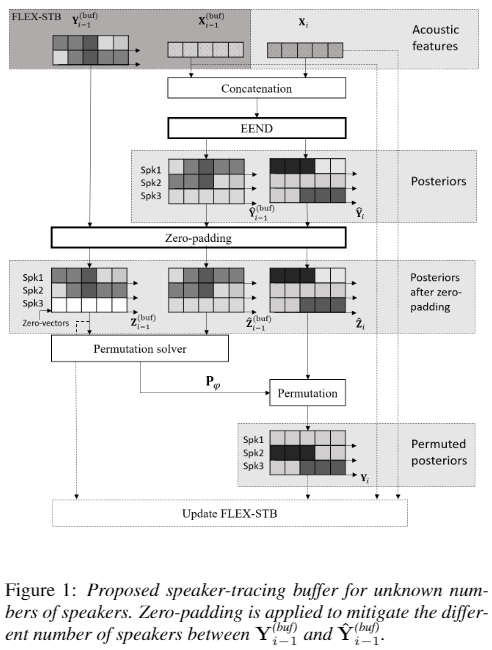
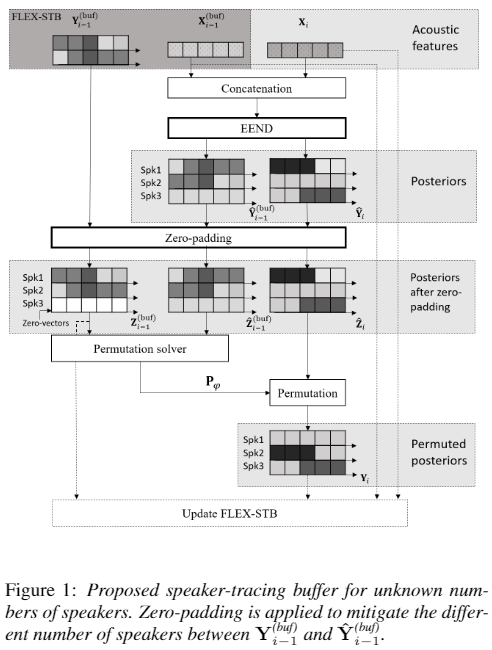
Overall architecture
- 1) FLEX-STB에 있는 이전 입력들과 실시간 입력를 Concatenation하여 EEND에 입력으로 넣는다.
- 2) 기존 화자 수보다 늘어난지를 확인한다.
- 3) 화자수가 늘어난 경우 의
spk3부분 처럼 출력 에 새로운 화자를 담을 Zero-vectors를 FLEX-STB에 추가한다.- 4) Covariance 값을 이용하여 FLEX-STB 출력과 FLEX-STB 입력에 대한 출력간 화자 Permutation 순서를 맞춰준다.
- 5) FLEX-STB의 길이가 최대 길이를 넘어가는 경우, Slection Strategy 에 따라 FLEX-STB를 Sampling 하여 Update 한다.
Experimental Results
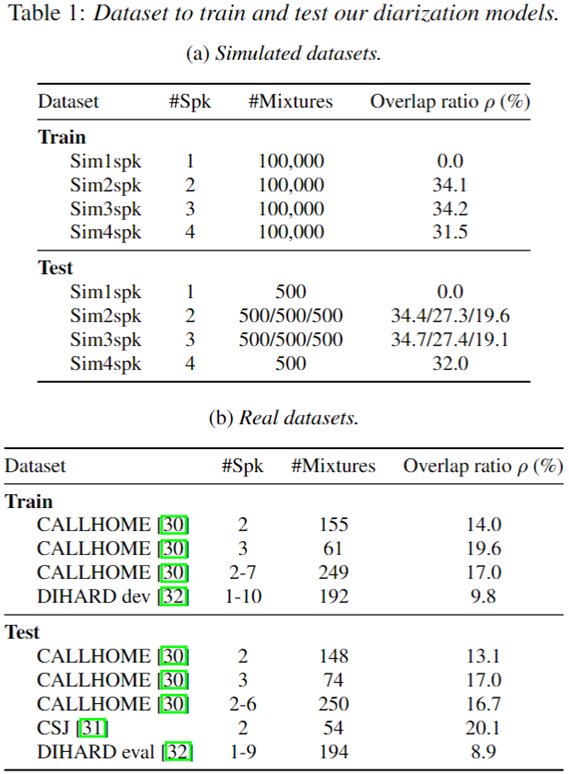
data
- Training Dataset
- EEND-EDA에서 사용한 것과 동일한 100k simulated mixture를 사용한다.
- Eval Dataset
- CALLHOME Dataset
- DIHARD II Dataset
Training Setup
- EEND-EDA
- two-speaker 데이터에 대해서 100 epoch 사전 학습 진행
- 이후 1명부터 4명까지 각각 25 epoch 학습 진행
Experimental result
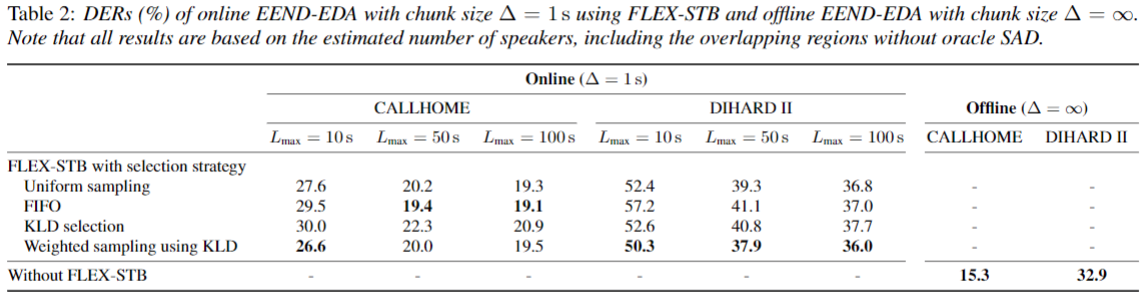
- 아래는 EEND-EDA와 SC-EEND의 L_{max} 길이와 4종류의 selection 전략에 따른 Callhome과 DIHARD II 데이터의 결과를 보여준다.
- 실시간 입력은 로 1초의 입력이 들어오는 것을 가정한다.
- L_{max}의 값이 10초인 경우에는 4번째 전략의 SC-EEND가 좋은 성능을 보이는 것을 볼 수 있다.
- L의 길이가 늘어남에 따라서 좋은 성능을 보임을 볼 수 있다.
- CALLHOME 데이터 셋은 FIFO가 좋은 성능을 보이고, DIHARD II 데이터 셋에 대해서는 Weighted sampling using KLD 가 에 대해서 좋은 성능을 보인다.
CALLHOME & DIHARD II 데이터 셋 관련 연구 성능 비교
- CALLHOME Dataset에 대해서 10초의 긴 입력 latency를 가지는 BW-EDA-EEND 보다 좋은 성능을 보인다.
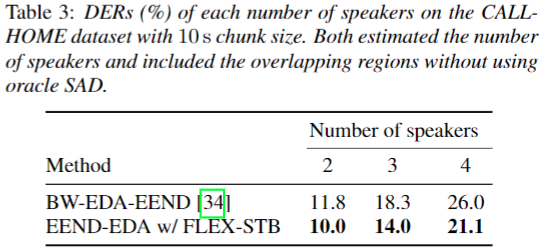
- DIHARD II 데이터셋에 대해서 UIS-RNN과 DIHARD II baseline의 offline 성능보다 좋은 성능을 보인다.


Audio & Speech AI Researcher 입니다! Speaker Diarization & Speaker Verification 연구 경험을 가지고 있고, 전반적인 Speech Representation 에 대해서 관심을 가지고 있습니다!