[RPNSD 리뷰] Speaker Diarization with Region Proposal Network
소개
- 이 글은 논문을 읽고 정리하기 위한 글입니다.
- 내용에 오류가 있는 부분이 있다면 조언 및 지적 언제든 환영입니다!
ICASSP 2020 에 올라온 논문입니다. (Paper, github)
참조
Citation
@misc{huang2020speaker,
title={Speaker Diarization with Region Proposal Network},
author={Zili Huang and Shinji Watanabe and Yusuke Fujita and Paola Garcia and Yiwen Shao and Daniel Povey and Sanjeev Khudanpur},
year={2020},
eprint={2002.06220},
archivePrefix={arXiv},
primaryClass={eess.AS}
}Introduction
Background
- 기존 Speaker Diarization 은 음원을 일정 길이로 자른 segment 을 화자 인식으로 학습된 네트워크를 통과 시켜 Speaker embedding 을 추출하고 이를 Clustering 하는 Clustering-based Diarization 이 좋은 성능을 보였다.
Limitation
- Overlap speech
- 기존 Clustering-based Diarization은 각 segment를 하나의 centroid로 대응시키는 set problem 으로 multi-classification task 가 아니다.
- 또한, 기존 Speaker embedding extractor 네트워크는 segment에 하나의 화자만이 있는 상황만 가정되어 있다.
- 이러한 점에서, 이 방법은 하나의 segment가 여러 화자에 대응되는 overlap speech를 다루지 못한다.
- End-to-End Training
- 기존 Clustering-based Diarization 은 SAD(Speech Activity Detection), Speaker embedding extractor, clustering module 과 같이 여러 stage를 가지고 있다.
- 이러한 점에서 End-to-End 방식으로 jointly Optimization이 불가능하다.
Main Proposal
- Region Proposal Network based Speaker Diarization (RPNSD)
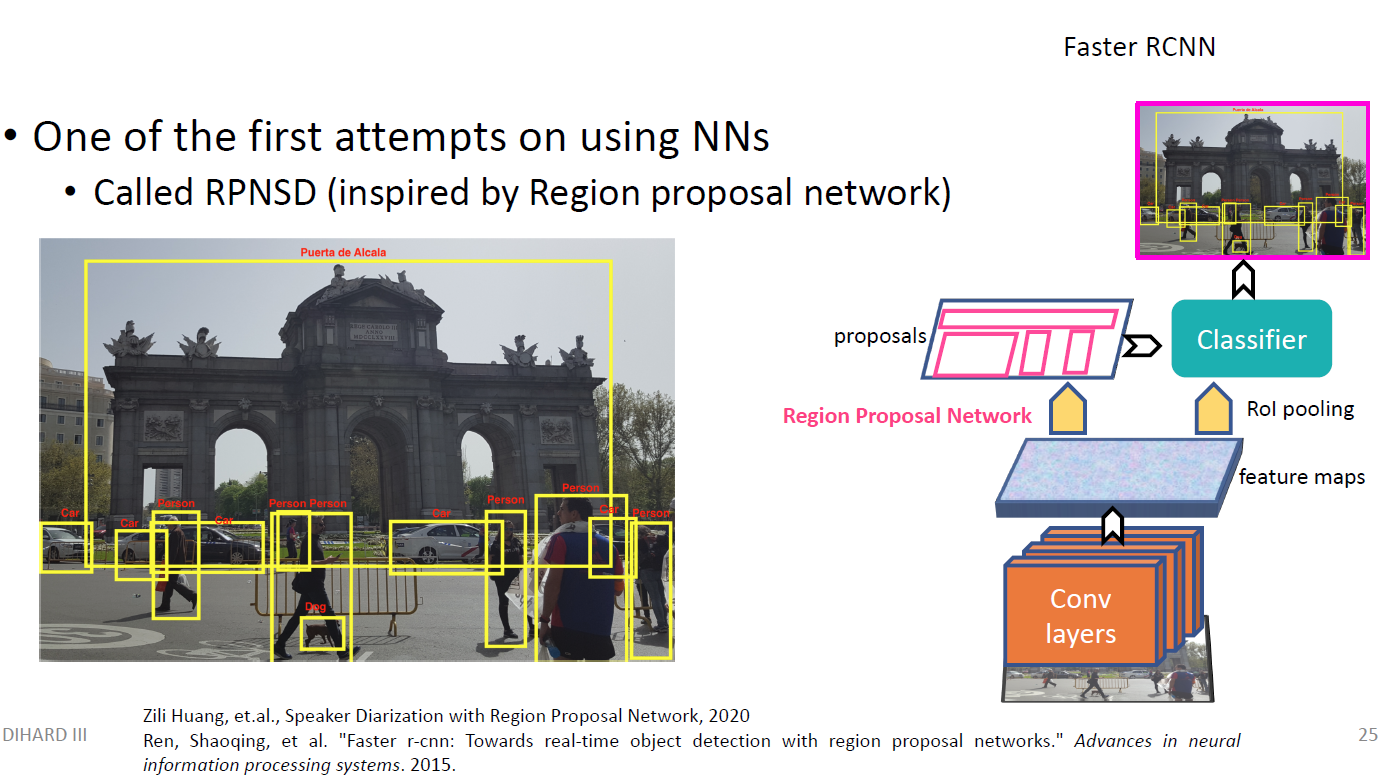
- Speaker Diarization Task를 Computer Vision의 Object Detection 문제와 비슷하다고 보았다.
- Object Detection에서 유명한 구조인 Faster R-CNN 를 Speaker Diarization task로 End-to-End로 학습 시켰다.
- 결론
- CALLHOME 데이터 셋에 대해서, 기존 x-vector + VB-HMM 후처리 성능을 뛰어넘었다.
- CALLHOME 데이터 셋에 대해서, 기존 x-vector + VB-HMM 후처리 성능을 뛰어넘었다.
Proposed Method
RPNSD
Introduction
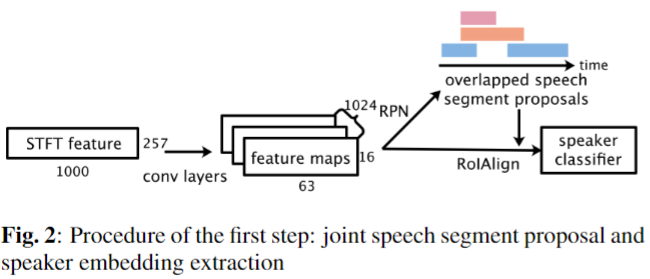
- 10초의 음원에 STFT를 적용한다. 이를 이미지로 생각하고 네트워크 입력으로 넣어준다.
- ResNet101 Backbone에서 나온 feature를 Region Proposal Network(RPN)에 입력으로 넣어주어 Speech segment region 후보를 추려낸다.
- 각 Speech segment와 Backbone feature와 대응 되는 위치를 RoIAlign를 진행한다.
- 각 region으로 부터 나온 박스들에 대해서 Speaker Classifier 한 뒤 NMS를 이용하여 각 speech segment의 region과 class 정보를 알아낸다.
- Inference 시에 K-means Clustering 알고리즘으로 비슷한 speaker embedding를 merge 한다.
Architecture
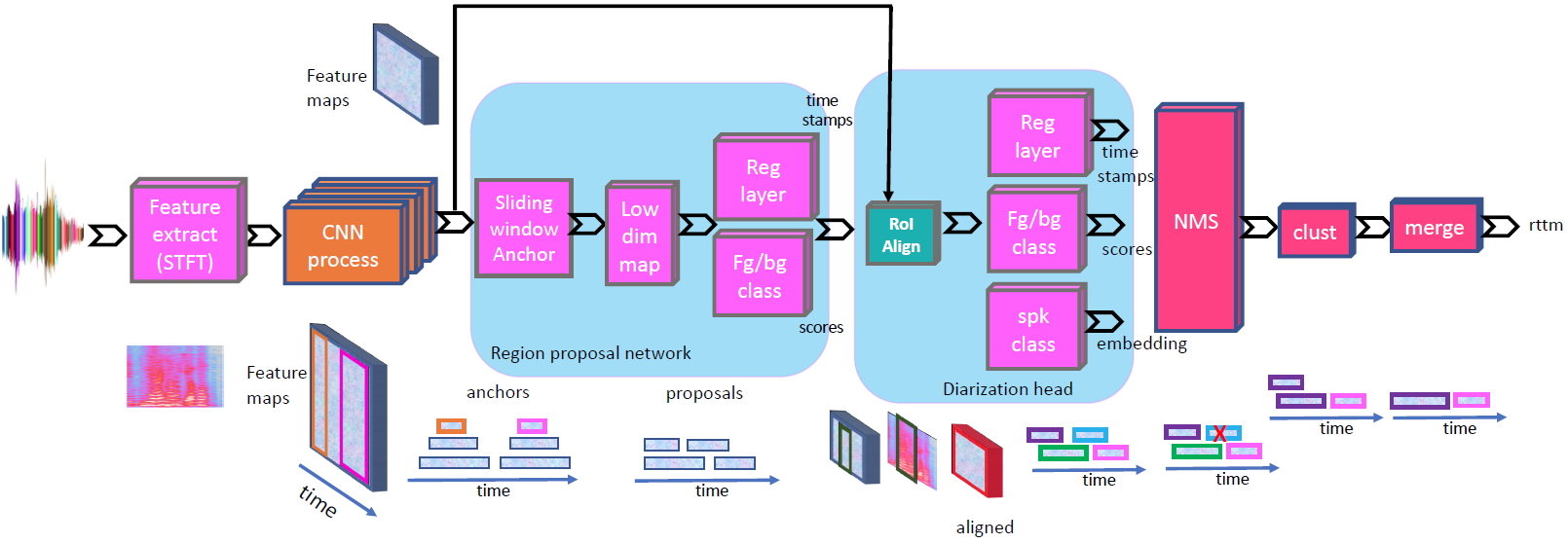
-
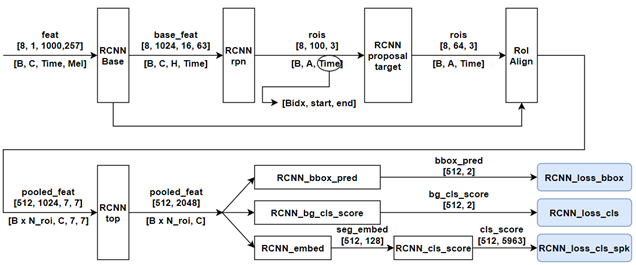
0) Input:
-> 1 x 257 x 1000- Length: 10 sec
- Sample rate: 8kHz
- 0.1) STFT
- Window size: 64ms, Hop size: 10ms
- frequency bin: 257 (n_fft=512)
-
1) Backbone:
1 x 257 x 1000 -> 1024 x 16 x 63- 아래 그림 layer-101 (ResNet101)를 그대로 사용함
- 여기서
Conv5_x를 통과하기 전인 layer3(Conv4_x)의 출력까지 사용하고, layer 4(Conv5_x)는 사용하지 않는다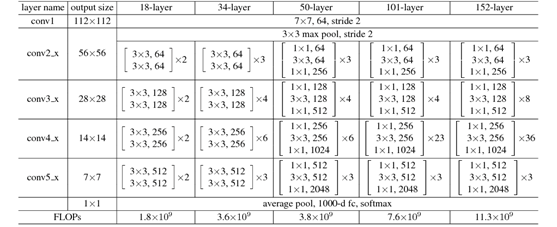
-
2) Region Proposal Network(RPN):
1024 x 16 x 63 -> 1 x 100 x 3
-
2.1) make bounding box embeddings and class embeddings
-
2.2) RPN Proposal layer
- 2.2.1) RPN bbox prediction 를 anchor 에 대한 모든 boxes를 구함 (567개 = 63 time width * 9 base anchor)
- 2.2.2) 실제 시간 범위를 넘어가는 box들을 clipping
- 2.2.3) 박스들의 cls prob 값으로 sorting 하고 각 order 별로 접근
- 2.2.4) pre_nms_topN (400개) 를 높은 확률 값 순서로 거른다. (더 적은 경우 유지)
- 2.2.5) Non Maximum Suppression(NMS) 알고리즘으로 post_nms_topN(100개)만 남긴다.
- 2.2.6) 남겨진 100개의 proposal bounding box를 output 으로 가진다.
1 x 100 x 3- 여기서, 3 dimension 값은 (batch_idx, start time, end time) 값이 이다. 시간 값은 0~1 사이로 normalize 되어 있다.
- 2.2.1) RPN bbox prediction 를 anchor 에 대한 모든 boxes를 구함 (567개 = 63 time width * 9 base anchor)
-
2.3) RPN Anchor target layer (train, dev only. get loss)
- 2.3.1) rpn의 bbox와 base anchor 로 가능한 모든 anchor 를 만든다.
- 2.3.2) clipping 범위 안에 들어오는 predict anchor 들만 남긴다.
- 2.3.3) gt box와 predict anchor 간에 overlap region 인 IoU 값을 계산한다.
- 2.3.4) 각 gt_box중 가장 높은 IoU 박스만 추출한다.
- 2.3.5) 각 gt_box에 대해 가장 높은 IOU를 가진 박스를 잠재적 positive 로 설정한다.
- IOU 값이 0.7 보다 큰 경우 잠재적 positive 로 설정한다.
- IOU 값이 0.3 보다 작은 경우 잠재적 negative 로 설정한다.
- 만약 RPN_FG_FRACTION(0.5) * RPN_BATCHSIZE(128) = 64 보다 positive 개수가 많다면, random으로 positive를 64개 선택한다.
- RPN_BATCHSIZE – FG_POSITIVE 개수를 나머지 BG_NEGATIVE 로 정한다. 이 또한 random으로 설정한다.
- 2.3.6) sampling 된 박스들에 대해서만, rpn_loss_cls 와 rpn_loss_bbox 를 계산한다.
-
-
3) RCNN Anchor target layer (train, dev only):
1 x 100 x 3 -> 1 x 64 x 3- Training 에서만 사용하며, RPN에서 Anchor target layer와 비슷하게 fg와 bg boxes 들을 sampling 하고, loss 함수에 사용할 target 형태로 box 값을 변경해준다.
- 위 nms 과정에서 추출된 100개 박스 중 Training 에서 사용할 high quality box 64개 만을 남기고자 한다.
- 2.3에서 설명한 RPN Anchor target layer와 동일
-
4) Pooling(RoI Align):
(1024 x 16 x 63) + (1 x 64 x 3) -> (64 x 1024 x 7 x 7)- 각 Box에 대응 되는 Backbone feature 정보를 7x7 region에 추려낸다.
-
5) RCNN top (Resnet101 - layer4):
64 x 1024 x 7 x 7 -> 64 x 2048- layer4 에 1x1 conv를 통해서 2048 channel로 projection 한다.
64 x 1024 x 7 x 7 -> 64 x 2048 x 7 x 7 - 뒤쪽 7 x 7 channel 정보는 mean average 하여 1 x 1 으로 만들어준다.
64 x 2048 x 7 x 7 -> 64 x 2048
- layer4 에 1x1 conv를 통해서 2048 channel로 projection 한다.
-
6) RCNN bbox prediction:
64 x 2048 -> 64 x 2- 1-layer FC
- output meaning: (# of box) x (bbox center point, bbox width)
-
7) RCNN background class score:
64 x 2048 -> 64 x 2- 1-layer FC
- output meaning: (# of box) x (background probability, foreground probability)
-
8) RCNN class speaker score:
64 x 2048 -> 64 x 5963- 2-layer FC + softmax
- 8.1) First FC layer (speaker embedding):
64 x 2048 -> 64 x 128- dimension reduction and representation
- 8.2) Second FC layer + softmax (speaker classification):
64 x 128 -> 64 x 5963- Speaker classification
- Total number of training speaker: 5963

loss function
-
Total Loss
-
1) Classification loss (
cls)- Binary cross-entropy (BCE) loss
- Binary cross-entropy (BCE) loss
-
Bounding box loss (
reg)- Smooth L1 loss
- Smooth L1 loss
-
Speaker classification loss
- cross-entropy loss
- alpha 값은 Training시 1.0, Adaptation시 0.1 로 사용했다.
- cross-entropy loss
Experiments Result
Dataset
-
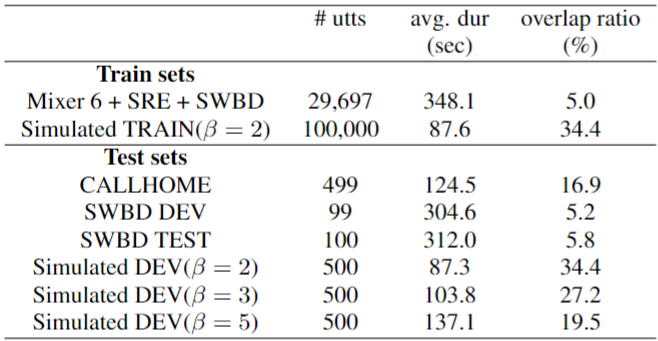
Train dataset
- Real dataset (Mixer 6 + SRE + SWBD)
- Simulated dataset (100k, )
- Real dataset를 이용하여 생성하며, 보다 높은 overlap ratio 를 가지는 학습 데이터를 얻기 위한 방법이다.
-
Test dataset
- CALLHOME
- SWBD DEV
- SWBD TEST
- Simulated DEV (beta = 2, 3, 5)
Training Strategy
- Batch Size: 8
- Training
- Learning rate: 0.01, decays twice to 0.0001
- Optimizer: SGD
- Adaptation
- Learning rate: 4 x 10^-5
Results: SWBD
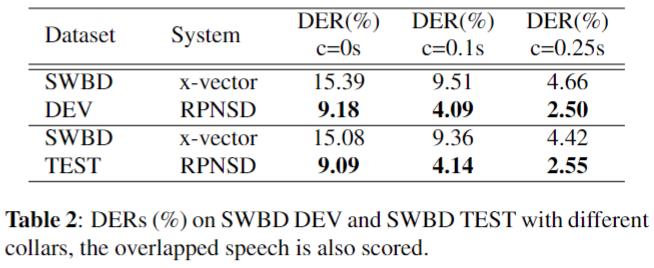
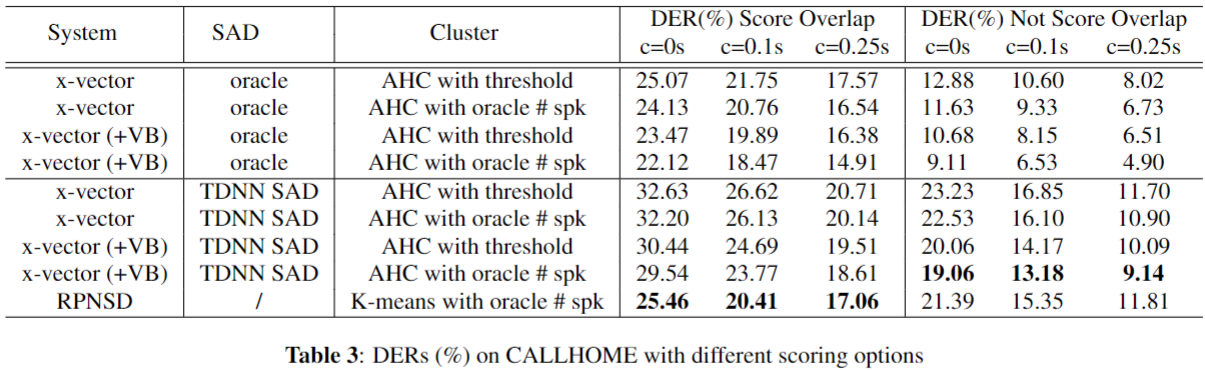
Results: CALLHOME
- 성능이 좋아보이지만, 결국 K-means로 oracle speaker 개수가 주어진 상태에 대한 measure만 했다...?
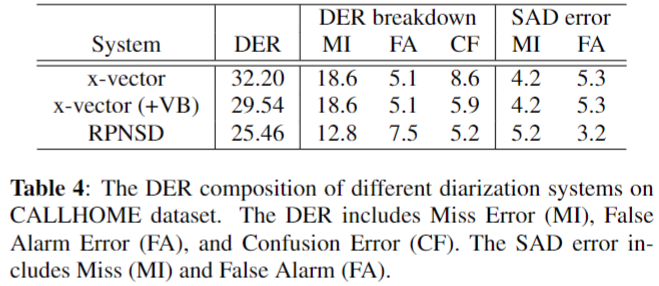
- 각 DER의 Miss, False Alarm, Confusion 과 SAD의 Miss, False Alarm 성능 비교
- SAD
- Miss Alarm 측면에서는 RPNSD가 떨어지지만, False Alarm이 줄어들었다.
- DER
- 확실히 overlap를 찾아내어 Miss가 줄어들었다.
- Confusion 부분에서도 좋은 성능을 보였다.
- 하지만 overlap false alarm의 영향인지 False alarm 이 늘어난 것을 볼 수 있다.
- SAD
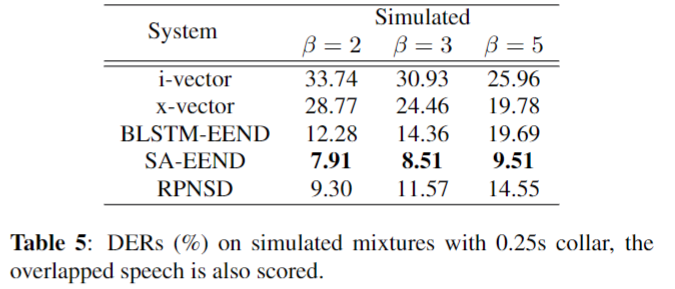
Results: Simulated Mixtures
- SA-EEND보다 떨어지는 성능을 보였다. 하지만, BLSTM-EEND와 x-vector보다 좋은 성능을 보였다.
Conclusion
- End-to-End Speaker Diarization 학습을 이뤄냈다.
- Image Object Detection의 Faster R-CNN 구조를 Speaker Diarization에 적용시켰다.
- Variable Number Speaker 상황(2~7명)에서도 잘 작동하였고 x-vector 성능을 뛰어넘었다. 하지만 Oracle speaker 수를 아는 상황에서 이다.
여담
- RPNSD 은 Speaker Diarization task를 Object Detection task로 풀어내었다.
- 하지만 여전히 inference시 Speaker Diarization를 위한 별도의 Clustering method (K-means)가 필요하였다.
- 또한, Resnet101의 모델은 상당히 큰 편이며, 한번에 10초의 입력만을 넣을 수 있는 것이 아쉽다.
- 추가로, RPNSD에 Feature Pyramid Network(FPN) 를 적용하였지만 성능 향상이 없었다.
- 개인적으로 이미지와 다르게 Time-Frequency 에 대한 원근감? 같은 것이 없다는 점과 utterance segment 길이가 매우 긴 경우가 적기 때문이지 않을까 싶다.
- resolution 보강을 통한 성능 향상을 기대 했는데 아쉽다.
- SA-EEND에서 Transformer의 Global Attention mechanism 은 relation information 해석에 뛰어난 성능을 보였다. 또한 Object Detection에 등장한 DETR과 같은 구조에 대한 연구 또한 Speaker Diarization에 필요하다고 생각은 되지만 어렵다ㅠㅠ... (이후 MaskFormer를 기반으로 한 EEND 구현 보임... 이걸?)
