Data Augmentation in Audio and Speech (Feature-Drop Aspect)
포스팅 업데이트
v0: 22/02/11
소개
-
이 글은 논문을 읽고 정리하기 위한 글입니다.
-
내용에 오류가 있는 부분이 있다면 조언 및 지적 언제든 환영입니다!
-
Audio와 Speech 분야에서의 사용하는 Data Augmentation 를 정리해보고자 합니다.
-
Feature Drop에 관점에서의 Data Augmentation 중심으로 다루었습니다. -
간단한 개념 위주로 정리할 예정입니다.
Paper List
[1] Tempo/Speech perturbation (INTERSPEECH 2015), paper_link
[2] SpecAugment (INTERSPEECH 2019), paper_link
[3] Mix SpecAugment (ICASSP 2020), paper_link
[4] SpecSwap (INTERSPEECH 2020), paper_link
[5] SpecAugment++ (INTERSPEECH 2021), paper_link
[6] FilterAugment (ICASSP 2022), paper_link
[1] Ko, Tom, et al. "Audio augmentation for speech recognition." Sixteenth annual conference of the international speech communication association. 2015.
[2]
@article{2019,
title={SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition},
url={http://dx.doi.org/10.21437/Interspeech.2019-2680},
DOI={10.21437/interspeech.2019-2680},
journal={Interspeech 2019},
publisher={ISCA},
author={Park, Daniel S. and Chan, William and Zhang, Yu and Chiu, Chung-Cheng and Zoph, Barret and Cubuk, Ekin D. and Le, Quoc V.},
year={2019},
month={Sep}
}
[3]
@misc{park2019specaugment,
title={SpecAugment on Large Scale Datasets},
author={Daniel S. Park and Yu Zhang and Chung-Cheng Chiu and Youzheng Chen and Bo Li and William Chan and Quoc V. Le and Yonghui Wu},
year={2019},
eprint={1912.05533},
archivePrefix={arXiv},
primaryClass={eess.AS}
}
[4] Song, X., Wu, Z., Huang, Y., Su, D., & Meng, H. (2020, January). SpecSwap: A Simple Data Augmentation Method for End-to-End Speech Recognition. In Interspeech (pp. 581-585).
[5]
@misc{wang2021specaugment,
title={SpecAugment++: A Hidden Space Data Augmentation Method for Acoustic Scene Classification},
author={Helin Wang and Yuexian Zou and Wenwu Wang},
year={2021},
eprint={2103.16858},
archivePrefix={arXiv},
primaryClass={eess.AS}
}
[6]
@misc{nam2022filteraugment,
title={FilterAugment: An Acoustic Environmental Data Augmentation Method},
author={Hyeonuk Nam and Seong-Hu Kim and Yong-Hwa Park},
year={2022},
eprint={2110.03282},
archivePrefix={arXiv},
primaryClass={eess.AS}
}
Tempo/Speech perturbation
Paper: Audio augmentation for speech recognition (INTERSPEECH 2015)
Task: ASR(Automatic Speech Recognition)
Introduction
Main Proposal
- Tempo/Speed Perturbation 방법을 도입하여 ASR 성능을 소폭 향상 시킴
Perturbation: 미미한 변경을 의미함
- Deep Learning이 막 시작하고 있는 시점에서의 Speech의 Data Augmentation 도입한 의의가 있음
Proposal Method
Tempo Perturbation
- 발화(Utterance)와 발화 사이의 간격을 Tempo 속도 생각할 수 있다.
- 논문에서는 발화 간 간격을 {0.9, 1.0, 1.1}배 와 같이 속도를 조절하여 Augmentation 해보았다.
- 큰 성능 향상을 보지는 못했다.
Speed Perturbation
- 발화의 속도를 조절을 통해서 Data Augmentation를 한다.
- 논문에서 발화의 속도를 {0.9, 1.0, 1.1}배 와 같이 속도를 조절하여 사용했다.
- Time Warping 으로도 볼 수 있지만, 부분적으로 Warping을 하는 것은 아니다.
- speed perturbation시 음원에 대한 resampling 과정이 필요하다.
- 본 논문에서는
Sox라는 audio manipulation tool 를 이용하여 구현했다.
- 수학적 해석
- 발화 속도 factor를 , 원 신호를 라고 하자.
- Speed Perturbation(Time Warping) 적용 시 아래와 같다.
- Time domain에서 Warping은 로 해석할 수 있다.
- 이때 주파수(Freq)에서는 만큼 크기가 scaling 되고 주파수 대역이 shift 되는 것으로 해석할 수 있다.
- if , 즉 Speed가 줄어들었다면
- 신호의 에너지가 Low-frequency 영역으로 이동하게 된다.
- if , 즉 Speed가 빨리진다면
- 신호의 에너지가 High-frequency 영역으로 이동하게 된다.
Expermental
- Speed perturbed 가 효과적이었다. (row 2, 6, 7)

SpecAugment
Paper: SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition (INTERSPEECH 2019)
Task: ASR(Automatic Speech Recognition)
Introduction
Main Proposal
- Proposed
SimpleandComputationally cheap, Feature(Input) drop-out - Three deformations of
log-mel spectrogram- Time Warping
- Time Masking
- Frequency Masking
Proposal Method
Time Warping
- 이미지에서 사용하는 Warping 방식과 거의 동일하다. 그냥
좌우로 늘린다고 생각하면 된다. - 이미지에서는 2D로 6개의 좌표점(Center, Left, Right)에 대해서 Warping이 진행되었다면, Speech는 1D로 3개의 좌표점(Center, Left, Right)에 대해서 Warping 진행된다.
- Random으로 선택된 3개의 좌표에 대해서 Center를 중심으로 Left Point와 Right Point 를 warping factor 만큼 움직이는 것을 의미한다.
- Time Warping은 그렇게 높은 성능 향상을 보이지는 않았다.
Time Masking
- Image에서의
Cutout기법을 Speech의 log-mel spectrogram에 적용한 방법이다. - log-mel spectrogram의 길이가 , 지워내는 영역을 라고 하자.
- Parameter Sampling 방법은 다음과 같다.
- 최대 Time mask 길이를 라고 하자.
- : Time mask 길이
- : Time mask 시작지점
- : 전체 입력 시간에 대해 Time mask의 비율이 최대 p%가 넘지 못하도록 하는 upper bound parameter
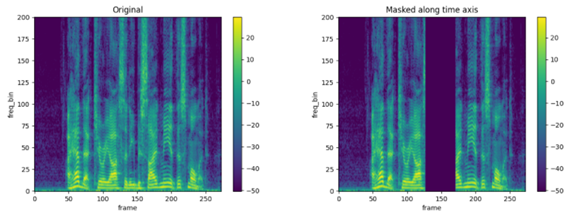
ref: https://tutorials.pytorch.kr/beginner/audio_feature_augmentation_tutorial.html
Frequency Masking
- Time Masking을 Frequency Domain에 대해서 동일하게 적용한다.
- Sampling 방법은 Time Masking 알고리즘과 동일하다.

ref: https://tutorials.pytorch.kr/beginner/audio_feature_augmentation_tutorial.html
Experiment
Model
ASR: LAS(Listen, Attend and Spell) Network
Dataset
- LibriSpeech
- Switchboard
Augmentation Policy
-
2종류 데이터 셋에 대해 각각 2가지 총 4가지 Policy 실험 결과를 보여준다.
-
Hyper-Parameter
- : Time wraping Parameter
- : Maximum Freq mask Parameter
- : Number of Freq mask
- : Maximum Time mask Parameter
- : Time mask의 Upper Bound Parameter
- : Number of Time mask
-
LibriSpeech
- 값인 Time mask 개수 변화에 따른 성능 비교를 보여준다.
-
Switchboard
- 값의 최대 길이를 변화에 따른 성능 비교를 보여준다.
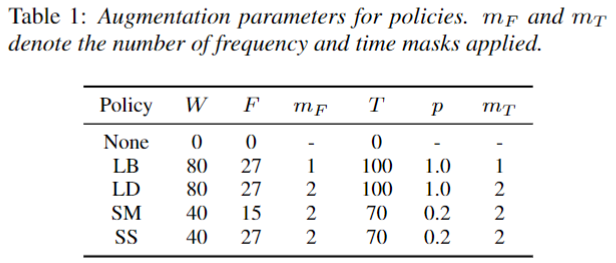
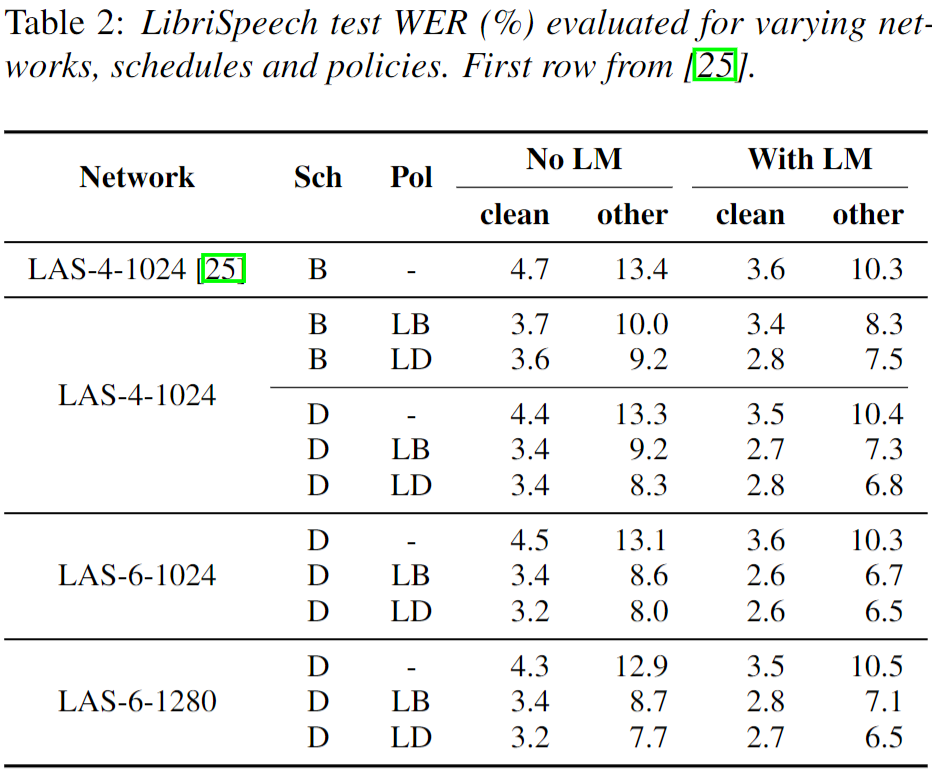
Experiment: Results of LibriSpeech
- 결론
- LAS 모델 크기 종류, 데이터 종류와 LM 여부에 상관 없이 DataAugment 정책이 모두 효과적인 것을 볼 수 있다.
- 특히
LB보다 Time mask 개수가 더 많은LD가 대체로 더 좋은 성능 결과를 보였다. - Learning Schedule은 더 천천히 학습하도록 조절한
D가 기존 학습방법B보다 좋았다.
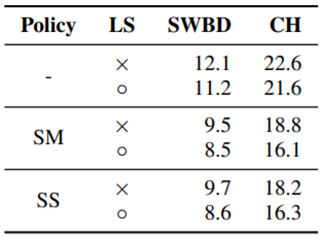
Experiment: Results of Switchboard
- 결론
- Learning Schduler 가 모두 효과적이고, SpecAugment가 효과적이다.
- SM과 SS는 Maximum Freq Mask 크기 변화에 따른 성능 차이를 보여준다.
- SM Policy 방식이 더 좋은 성능을 보인다.
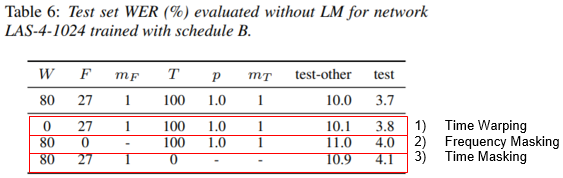
Discussion: Ablation Study
- Librispeech, Basic Scheduler, No LM, LB Policy 기준에 Ablation 결과이다.
- 2,3,4줄은 각각 Time Warping, Frequency Masking, Time Masking 적용하지 않았을때 결과이다.
- Time Warping은 큰 성능 변화를 주지 못했고, Masking 기법은 굉장히 효과적이었음을 실험적으로 보였다.
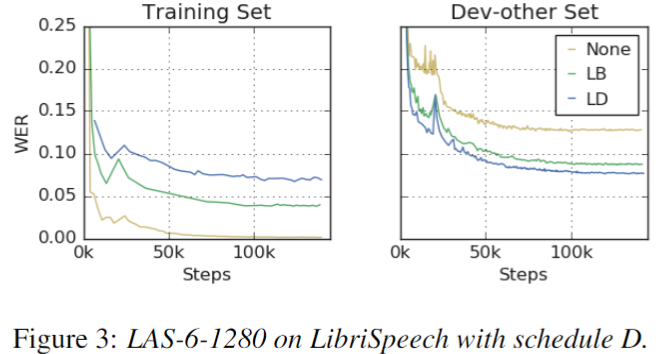
Discussion: Augmentation Converts an over-fitting problem into an under-fitting problem
-
SpecAugment 방법은 기존 학습시 발생하던 over-fitting 문제를 under-fitting 문제로 바꿨다.
-
아래 그림 결과와 같이 Train 과 Dev set 간의 WER gap를 줄이게 되었지만, 기존 Training 보다는 수렴이 보다 높은 것을 볼 수 있다.
-
LB vs LD: Augmentation를 강하게 줄수록 더 Training에서는 수렴이 잘 되지 않는 것을 보이지만, Dev에서는 더 좋은 경향성을 보인다. -
under-fitting 방면 improvement
- large Model, training longer
- deeper network with longer schedules
Mix SpecAugment
Paper: SpecAugment on Large Scale Datasets (ICASSP 2020)
Task: ASR(Automatic Speech Recognition)
Introduction
Limitation
- Large Dataset (MTR) 에 대해서 SpecAugment 추가시 오히려 성능이 저하되는 현상을 보였다.
- SpecAugment는 Time mask와 Freq mask의 길이를 hyper-parameter로 설정해야 한다는 단점을 가지고 있었다.
Main Proposal
- 본 논문에서는 다양한 환경, Audio 길이에 따른
Adaptive 한 SpecAugment방법을 제안합니다.
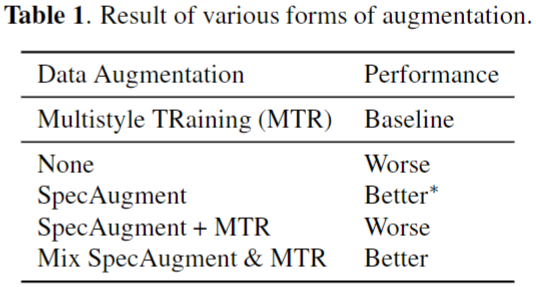
Proposal Method
Mix SpecAugment
-
Domain 별로 Audio 길이의 큰 변동으로 인해서
Maximum Time Mask를 고정된 길이로 사용하는 것이 오히려 성능 저하를 보였다. -
본 논문에서는 Audio 길이에 따른
Maximum Time Mask크기를 Adaptive 하게 설정하는 알고리즘을 제안한다. -
Algorithm
-
1) Adaptive multiplicity
- Time Mask의 크기를 Audio의 길이 와 multiplicity ratio 값 으로 조절함
- Time Mask의 최대 길이를 20으로Cap시키는 것을 볼 수 있다. -
2) Adaptive size
- Maximum Time Mask 값인 또한 Audio 길이에 Adaptive 하게 사용함
-
Experiment
Results of LibriSpeech
- Mix SpecAugment 사용시 기존 SpecAugment 방식보다 더 좋은 성능을 보여준다.
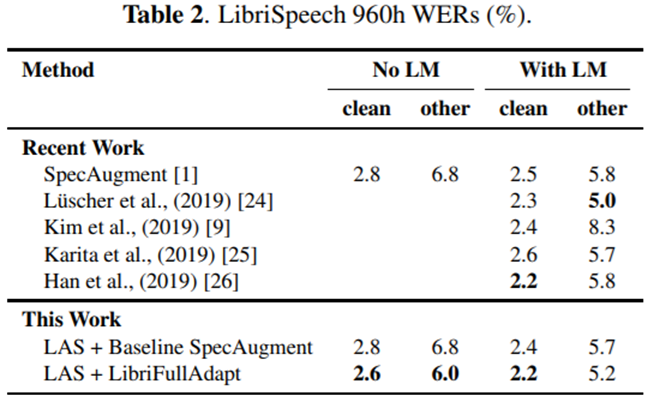
Results of Google Multidomain Dataset
- Large Dataset 에 대해서 Mix SpecAugment 가 좋은 성능을 보였다.
SpecSwap
Paper: A Simple Data Augmentation Method for End-to-End Speech Recognition (INTERSPEECH 2020)
Task: ASR(Automatic Speech Recognition)
Introduction
Main Proposal
- Transformer 기반 ASR의 등장하면서 이를 고려한 새로운 Data Augmentation 방법 제시
- SpecAugment의 Mask 방식이 아닌 Swap 이라는 방법으로 적은 계산량으로 효과적인 Augmentation 방법을 보임
- 기존 저자가 제안한 self-attention networks(SANs)의 모델적 제약을 없애고 보다 General 한 방법을 제시
- 기존에는 Swap 방식을 모델에서 담당하도록 하였음
- 하지만, 이런 방법은 다른 Transformer 기반 ASR에 사용에 있어 한계점 존재
Proposal Method
SpecSwap
Time Swap- 단순하게 2개 Block를 정하고 두 Block을 단순히 Swaping 하는 방법이다.
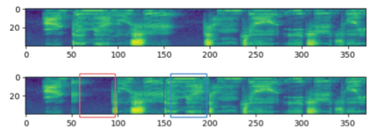
Frequency Swap- Time Swap 방식을 Frequency에도 적용했다.
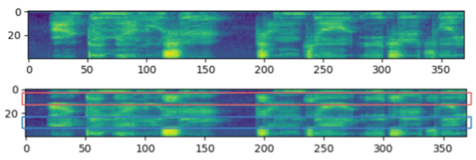
Experiment
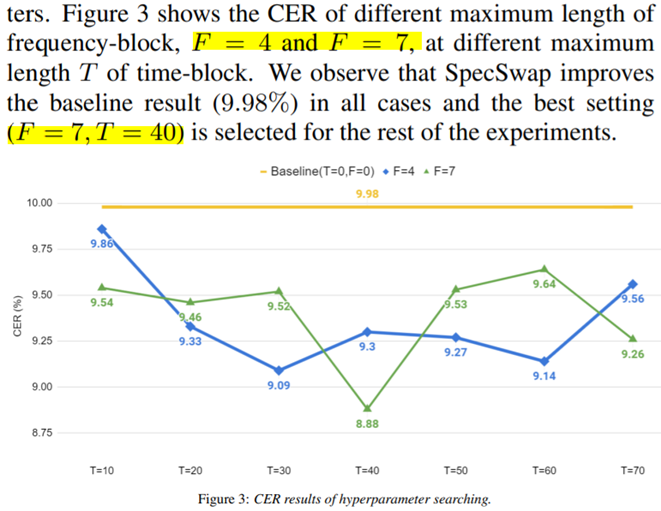
Time & Freq Hyper-parameter
- Freq=7, Time=40 에 대해서 가장 좋은 성능을 보였다.
Experiment: Ablation Study & Results
-
Ablation Study
- Time Swap 기법이 많은 성능 향상을 보었다.
- Freq Swap도 Time Swap 기법과 같이 사용할때 성능 향상을 보였다.
-
Results
- SwapSwap과 SpecMask 방법을 같이 사용했을때 좋은 성능을 보였다.
SpecMask = SpecAugment - Time Warping- 즉, Time & Freq Masking 기법을 사용한 경우를 뜻한다.
- Large Model에 대한 SpecSwap 유무 비교 실험은 없지만, 성능 향상을 보였다.
- LM이 없이 End-to-End 방식으로 Hybrid Approach에 준하는 성능을 달성했다.
- SwapSwap과 SpecMask 방법을 같이 사용했을때 좋은 성능을 보였다.

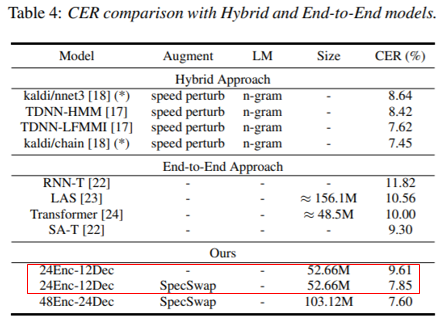
SpecAugment++
Paper: A Hidden Space Data Augmentation Method for Acoustic Scene Classification (INTERSPEECH 2021)
Task: ASC(Acoustic Scene Classification)
Introduction
- SpecAugment은 모델에게 입력을 보다 넓게 볼 수 있도록 하는 장점을 주었다.
- ASC 관점
- DCASE 2019의 Task 1: ASC 는 다양한 마이크 환경에서의 일반화가 중요한 Task 였다.
- 이러한 점에서 다양한 noise 상황에 Robust한 모델을 생성하는 것이 중요한 Task 이며, 다양한 Augment 방법이 제안됨
Limitation
hidden space에 대한 Augmentation 방법 연구 부족cutmix방법- BC learning의 latent space interpolate 하는 방법
SpeechMix의 불안정성 존재 - mixed audio에 대해 label를 정하기 애매함
- 즉 raw audio와 mixed audio 간 energy 분포가 전혀 다름
- BC learning의 latent space interpolate 하는 방법
- Auxiliary classifier GAN(ACGAN)
- fake sample를 생성하여 학습하는 방법
- 추가적인 GAN의 discriminator 학습이 필요함
- 학습 수렴 속도가 느려지고, 학습이 보다 어려워짐
Main Proposal
cutmix방법을 도입하여 추가적인 noise를 도입- 추가적으로 3가지 Augment 방법을 실험적으로 보임
hidden space에 대한 Augment 방법 및 실험 결과 보임
Proposal Method
SpecAugment++
-
SpecAugment의 Time Warping은 사용하지 않음
-
Time, Frequency Mask에 대해 3종류 Mask 제안
- ZM (Zero-value Masking)
- MM (Mixture Masking)
- CM (Cutting Masking)
-
ZM (Zero-value Masking)
- 기존 SpecAugment의 Time Masking 알고리즘과 동일
- 기존 SpecAugment의 Time Masking 알고리즘과 동일

- MM (Mixture Masking)
- 같은 mini-batch 안에 있는 1개의 random sample
y를 정한다. - Augment를 적용할 영역을 SpecAugment 와 동일하게 Sampling 한다.
- 두 영역에 대해서 mix 를 진행한다.
- 같은 mini-batch 안에 있는 1개의 random sample

- CM (Cutting Masking)
- MM과 동일하게 random sample
y와 Augment 영역 Sampling - MM과 다르게 섞지 않고 대체한다.
- MM과 동일하게 random sample

- Hidden Space Augment
- 모델은 ASC task의 base model인 CP-ResNet 를 사용했다.
- 앞에서 언급한 것과 같이 Input (layer 0) 뿐 아니라 추가적인 4개 layer 출력인 Hidden Space에 대해서 Augment를 적용했다.
- Hidden Space와 같은 경우 Channel이 존재하는데, 모든 Channel에 동일한 영역에 Time, Freq Mask를 사용했다.
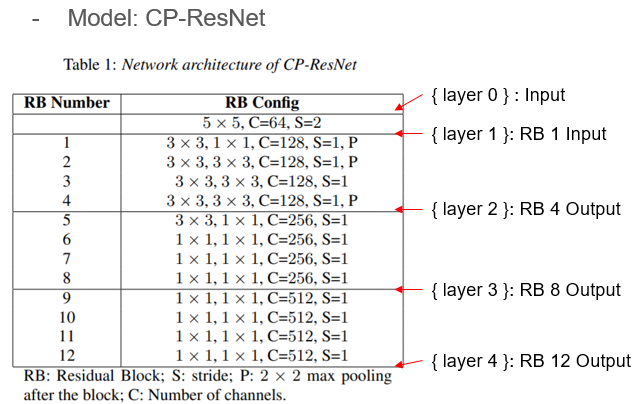
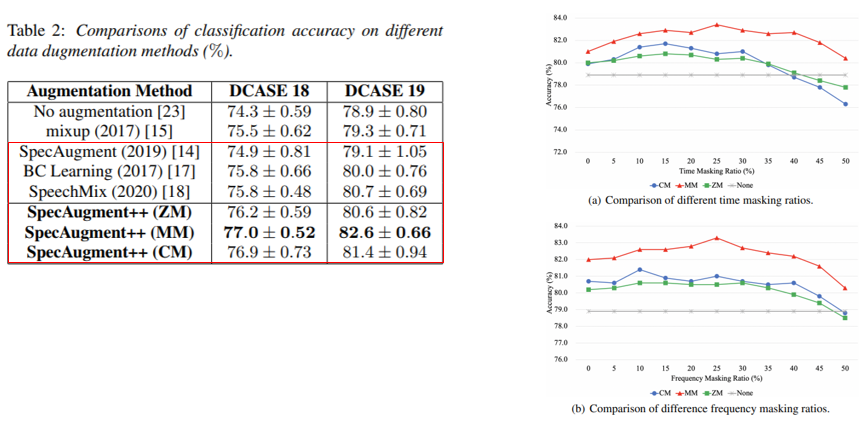
Experiment
Results of Augment Type
- Time Mask Ratio와 Freq Mask Ratio에 따른 성능 분포는 오른쪽과 같다.
- Mixture Masking(MM) 방식이 가장 좋은 성능을 보였다.
- SpecAugment와 SpecAugment++(ZM) 과의 차이는
Hidden Space 적용과Time Warping 적용 차이로 볼 수 있다.
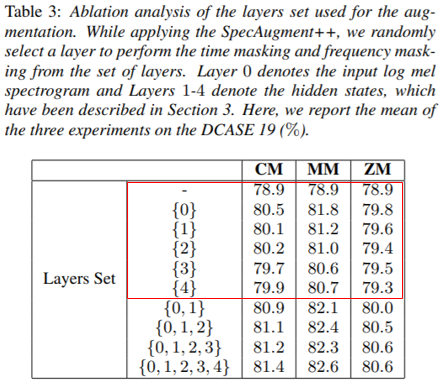
Results of Target Layers
- Layer 별 Augment 적용 결과를 보여준다.
- 입력에 가까울수록 높은 성능 향상을 보여준다.
- 모든 Layer에 Augment 적용시 더 좋은 성능 향상을 보였다.
FilterAugment
Paper: An Acoustic Environmental Data Augmentation Method (ICASSP 2022)
Task: SED(Sound Event Detection), SV(Speaker Verification)
Code:github
Introduction
Limitation
- SpecAugment는 완벽하게 정보를 데이터로 부터 지워버리는 단점을 가지고 있다.
- 마이크에서 발생하는 absorption(흡수), reflection(반사), scattering(산란) 현상을 모델링 하지 못함
- Far Signal, Object Blocking, reverberation 에 따라 변경되는 신호 특징이 Augment에 반영되지 않았다.
Contribution
- Frequency Domain에 대해 zero-masking 이 아닌 filter 형태로 변경
- Linear, Step filter 두 종류의 Frequency Masking를 통해 성능향상을 보임
- Acoustic 특성을 더 잘 Modeling 했다고 볼 수 있음
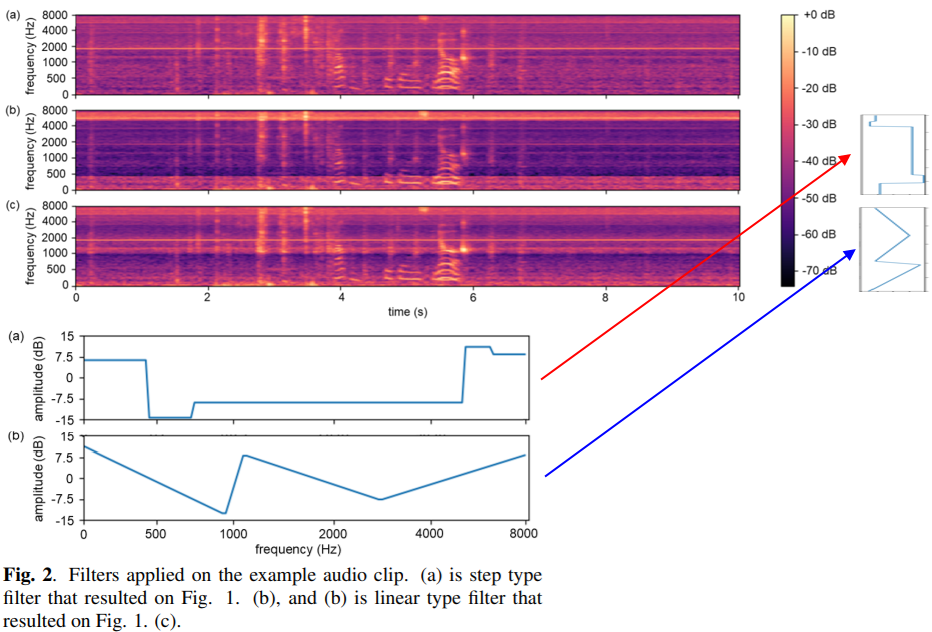
Proposal Method
FilterAugment
-
각 Frequency 에 대해서 다른 Amplitude 값을 가지는 Filter를 적용
-
특정 형태의 filter가 아닌 random filter로 computation cost가 적음
-
장점
- Far Signal 과 같은 경우 High Frequency 영역이 Low Frequency 보다 더 많이 손상되는 현상을 보인다. 이러한 부분을 보다 잘 modeling 할 수 있게 된다고 함
- 소리가 물체에 Block 되었을때도 Frequency 대역별 손실율이 다른데 이를 더 잘 모델링할 수 있다고 주장
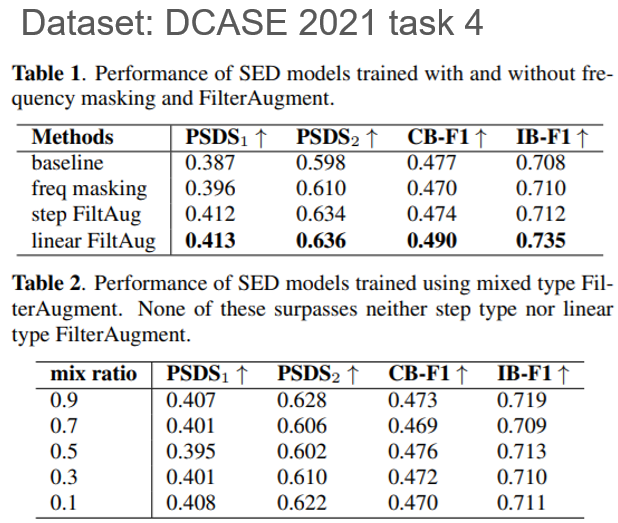
Experiment
Result of Sound Event Detection in DCASE 2021 Task 4
- zero-masking 방식 보다 step, linear Filtering 방식이 더 효과적이었음
- linear filter가 step filter 보다 좋은 성능을 보임
- 논문에서는 보다 연속된 frequency 변화가 좋았던 것으로 설명
- 추가로 mini-batch 내에서 linear filter와 step filter 적용 비율을 조정하면서 실험한 결과는 Table 2와 같음
- 신기하게도, 두 filter는 둘 중 한가지만 사용하는 형태가 가장 좋은 성능을 보임
- 절반씩 사용한 경우 그렇게 큰 성능 향상을 보이지 못함. 오히려 모델에게 방해를 주는 것으로 보임
Result of Speaker Verification in Voxceleb I & II
- Speech에 대해서도 Filter Augment가 좋은 성능을 보임을 보였다.