업데이트
- v0 (2021-01-29)
- v1 (2021-09-23)
소개
- 이 글은 논문을 읽고 정리하기 위한 글입니다.
- 내용에 오류가 있는 부분이 있다면 조언 및 지적 언제든 환영입니다!
2019 ASRU, 2020 TASLP에 올라온 논문입니다. (Paper, author github based on chainer, github based on Pytorch)
Citation
[1] Yusuke Fujita, Naoyuki Kanda, Shota Horiguchi, Yawen Xue, Kenji Nagamatsu, Shinji Watanabe, " End-to-End Neural Speaker Diarization with Self-attention," Proc. ASRU, pp. 296-303, 2019
[2] Y. Fujita, S. Watanabe, S. Horiguchi, Y. Xue, and K. Nagamatsu, “End-to-end neural diarization: Reformulating speaker diarization as simple multi-label classification,” arXiv:2003.02966, 2020.
Introduction
Background
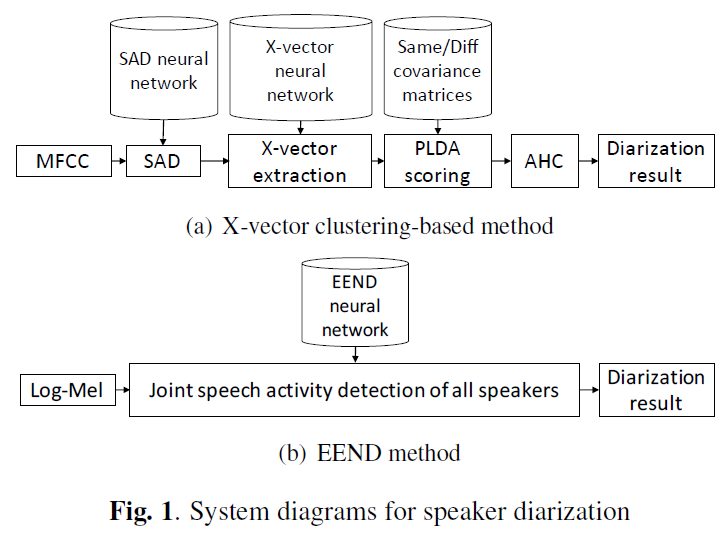
Clustering-based diarization
- 설명
- 이전에는
화자인식 Speaker IDentification(SID)으로 학습한 네트워크를 이용하여 화자 특징을 가지는embedding을 추출하고, 이 embedding 들을clustering하여 화자 분류를 하는clustering-based diarization이 좋은 성능을 보였다.Method
- 1)
SAD(Speech Activity Detection)으로 Speech Activity Region을 찾는다.- 2) Speech Activity Region을
일정(uniform) 간격으로 잘라 여러 개의 segment를 생성한다. (일반적으로 uniform, utterance 단위로 하는 경우도 있음. 보통 1.5초 길이 와 0.75초 step size를 사용함)- 3) 2에서 생성한 segment 들을
audio feature(ex. log-mel, MFCC) 로 변경한다.- 4) 3에서 생성한 각 segment feature 을 화자 인식으로 미리 학습된 neural network(ex. x-vector, i-vector)에 입력으로 넣어 최종 출력 전 or 전전 layer의 출력 vector을
speaker embedding으로 사용한다.- 5) 각 segment에서 추출된 Speaker Embedding들 간의
유사도 점수을 계산한다. (ex. PLDA(Probabilistic Linear Discriminant Analysis) scoring, Cosine Similarity scoring)- 6) 유사도 점수를 이용한
Clustering을 진행한다. (ex. AHC(Agglomerative Hierarchical Clustering), SC(Spectral Clustering), K-means Clustering)- 7) 다양한
후 처리(post-processing)를 한다. (ex. VB-HMM, Overlap-Assign, Dover-lap, etc...)Limitation
- 1) Speaker Diarization error를 곧바로 최적화 하지 못한다!
- Multi-Stage 구조로, 각
모듈 별 최적화가 진행되어jointly optimization가 불가능하다.- 즉,
End-to-End Speaker Diarization Training이 되지 않는다. (SAD, x-vector 따로따로 학습됨, 앞 stage의 error가 propagation 됨)- 대부분
clustering method는 Unsupervised learning methods이다. (Deep Neural Clustering(DNC) 같은 Supervised method가 있긴하지만 논외)- 2) Speaker Overlap 을 다루지 못한다.
- 각 segment은 하나의 speaker에 대응시키는
Set problem으로,한 segment에 대해 단 한명의 화자만 mapping되어 Speaker Overlap 을 다루지 못한다.
End-to-End Speaker Diarization(EEND)
- 설명
- 단 한 개의 Neural Network(NN)가 end-to-end 로 Speaker Diarization(SD) Error 을 곧바로 학습하는 방법이다.
- BLTSM-EEND 에서 Permutation-free loss 도입으로 end-to-end 학습을 시도했다.
Method
- 1) 입력 wav 데이터를 STFT 한 이후 audio feature(log-mel)를 추출한다.
- 2) 각 Frame이 화자의 특징을 잘 담을 수 있도록 stacked-frame 형태로 주변 audio feature을 차곡차곡 쌓아서 하나의 frame을 만든다.
- 3) 생성된 frame 들을 네트워크 입력으로 넣어 diarization 결과를 바로 구한다.
Limitation
- BLSTM-EEND는 기존 clustering-based diarization 성능을 능가하지 못했다.
Proposed Method
Self-Attention End-to-End Neural Diarization(SA-EEND)
- Intro
- 화자 인식(SID)에서는
굉장히 많은 화자들 간에 구별 가능한 섬세한 특징을 modeling 하는 것이 중요하였다.- 화자 분류(SD)는
주어진 입력 내 화자간 입력 관계(relation information)을 해석하는 것이 중요한 과제이다.- 일반적인 대화 속에는 통상적으로 2~6 명 정도의 화자가 나오는 경우가 많다. 이 점에서, 화자 분류는 화자 인식만큼 엄격하게 유사도를 판별하는 것이 중요하지는 않고, 주어진 입력 내 화자간 관계성을 파악하는 것이 더 중요하다.
- 본 연구에서는 BLSTM-EEND의 구조를 그대로 사용하지만,
BLSTM 기반 Encoder Block 을 Transformer로 대체했다.- 여기서 encoder Transformer의
Self-Attention mechanism의 global attention 효과가 모든 frame 들 간의 관계성을 해석하는데 좋은 성능을 보였고, Clustering-based diarization 방법을 성능을 능가했다.
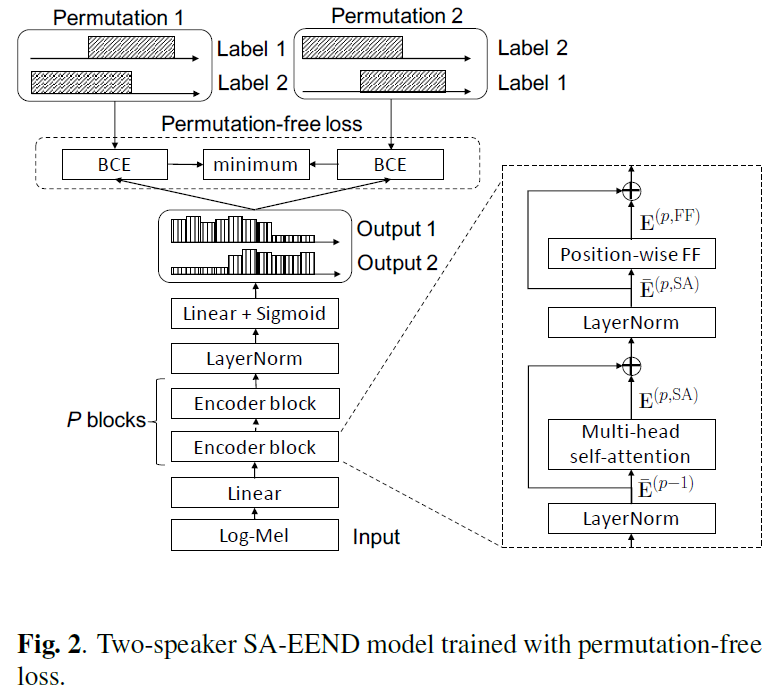
- Architecture
- Variable
- T : The total number of frame (500 if 50 sec)
- F : Feature dimension (345)
- D : Encoder hidden dimension (256)
- S : Fixed-number of Speaker (2)
- P : Number of Encoder Block (4)
- 0) Stacked sub-sampling:
raw input -> T x F
- 0.1 STFT + log-mel:
raw input -> 10T x 23
- window size:
25ms- hop size:
10ms- log-mel:
23 log-mel- 0.2 Stacked-frame:
10T x 23 -> 10T x F(345)(F: 23 log-mel x 15 = 345)
- context length:
15 samples(previous 7 sample + current 1 sample + next 7 sample)- 0.3 Sub-sampling:
10T x F -> T x F
- Step size:
10, Sampled 100ms per frame (hop size 10ms x10= 100ms)- 1) SA-EEND:
T x F(345) -> T x D(256)
- 1.1 FC layer:
T x F -> T x D
- Transformer 입력을 위한 embedding 과정
- 1.2 Encoder Blocks:
T x D -> T x D
- P개의 Transformer(self-attention) 로 구성 됨
- self-attention mechanism 기반 모든 Frame 간 관계 해석을 통한 embedding encoding 과정
- 1.3 Layer Norm:
T x D -> T x D- 1.4 Linear + Sigmoid:
T x D(256) -> T x S(2)
- 1.4.1 Linear:
T x D(256) -> T x S(2)
- Encoding 된 Speaker Embedding 의 각 Frame 에 대해서 Linear 을 이용하여 hidden dim(256)을 화자 수(S)로 project 한다.
- 이때, Linear 의 weight인
D x S을 각 화자 S 명의1 x D길이의 attract vector로도 해석 할 수 있다. (이해 하지 않아도 문제 없음)- 1.4.2 Sigmoid
- 각 Frame 의 화자 activity 값을 0~1 사이로 나타내기 위해 사용한다.
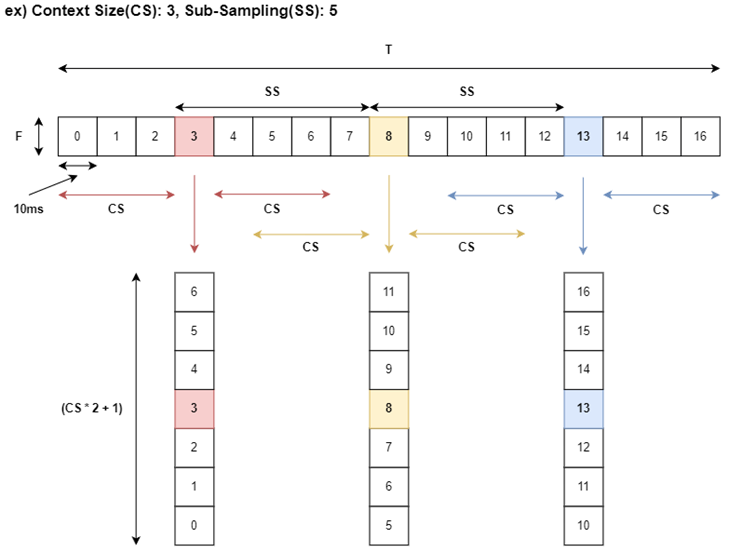
Stacked sub-sampling (Input Frame)
- Method
- 10ms 마다 생성된 log-mel feature를 Transformer의 그대로 넣어서 사용하기에는 메모리뿐만 아니라 각 Frame이 화자 특징을 대표하기에는 너무 짧은 시간이다.
- 본 논문은 이전 BLSTM-EEND의 입력 형태인 Stacked sub-sampling 를 그래도 이용한다.
- Hyper-Parameter
- Context Size(CS): 현재 프레임의 Context Size만큼 이전과 이후 feature들을
Stacking하여 사용하는 방법이다. 본 논문은7를 사용하였다.- Sub-Sampling(SS): 일정 Frame 마다 Sub-Sampling 하여 사용하는 방법이다. 본 논문은
10를 사용하고, 이는 한 Frame이 100ms를 대표하는 것으로 볼 수 있다.- 예시
- 아래 그림은 Context Size가
3, Sub-Sampling이5일때의 예시이다.
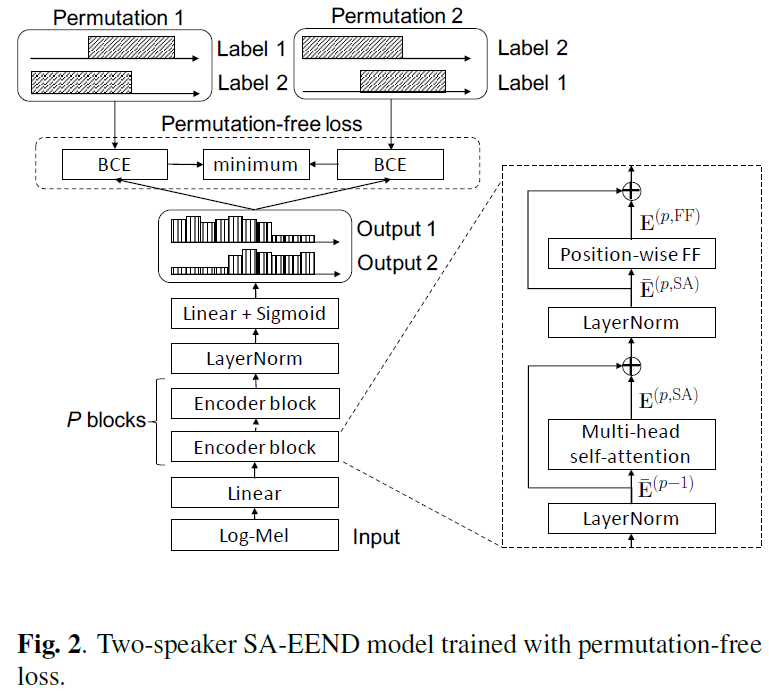
Encoder Block: Self-Attention (Transformer)
- Architecture
- Variable
- T : The total number of frame (500 if 50 sec)
- D : Encoder hidden dimension (256)
- d_ff : FFN internal units (1024)
- 0) Positioning Encoding
- 본 실험에서는 Positioning Encoding은 사용하지 않았다.
- 개인 실험 결과, Positioning Encoding 사용 시 성능 하락 (정확한 이유 불분명)
- 이후 제안된 Conformer 와 같은 경우 relative position encoding이 성능 효과 보임
- 1)
Layer Normalization
pre-Norm구조- 일반적으로 학습 속도를 빠르게 해준다고 합니다. (layer 별 gradient 값 range 보장)
- 2)
Multi-head self-attention (MHSA)
Query, Key, Value 에 동일한 입력을 넣어준다.- Number of Header:
4- Residual Connection
- 3)
Layer Normalization- 3)
Position-wise FF (FFN)
- 설명
- 2개의 Linear 이후, Residual Connection
- Model
- 1st Linear:
T x D(256) -> T x d_ff(1024)- 2nd Linear:
T x d_ff(1024) -> T x D(256)
Objective Function
Permutation-free loss(PIT loss)
정답 화자 순서를 섞어서 만들 수 있는 모든 permutation들과EEND 출력간Binary Cross Entropy(BCE)값들 중최소 값을 loss로 사용하는 것을 Permutation-free loss 라고 합니다.label ambiguity: 화자의 label은 모호성은 신경쓰지 않겠다!
- SD는 입력 음원 내 각 화자의 발화 시간이 동일하게 mapping 되면 된다. SID 와 달리 정확한 화자 ID를 요구하지 않는다.
Speaker ID가 0 으로 라벨링된 화자를EEND에서 Speaker label 을 0으로 나오던 1로 나오던 상관 없이 발화 시간만 맞춘다면 라벨을 신경쓰지 않겠다는 말이다.- 예시 Figure 2
- 정답으로 2명의 화자가 존재한다고 가정한다.
- Speaker label을 배치하는 방법이 (label 1, label 2)와 (label 2, label 1) 으로 총 2 가지가 존재한다.
- EEND의 결과와 2가지 정답 Permutation 간 BCE loss를 계산한다.
- 2개의 BCE loss 중, 더 작은 값을 가지는 Permutation 2 (label 2, label 1)의 loss를 선택한다.

Experimental Setup
Data
Dataset 구성
Real Datasets
SWBD: Switchboard-2 (Phase I, II, III), Switchboard Cellular (Part 1, Part 2)SRE: NIST Speaker Recognition Evaluation datasets (2004, 2005, 2006, 2008)- Sampling rate: 8kHz
- Total Speakers: 6,381
- Split speakers of two subset
- 1) Training set: 5,743 speakers
- 2) Test set: 638 speakers
- Channel: 2 Channel
- each speaker in each Channel
- Labels 생성
- 이 데이터 셋은 speaker diarization label이 존재하지 않기 때문에, Time-delay neural network(TDNN) 기반 Speech activity detection(SAD)와 statistics pooling를 이용하여 라벨을 생성했다.
Simulation Datasets
- 설명
- Real dataset은 overlap ratio의 평균 3.7%로 낮은 overlap ratio를 가지며, overlap ratio가 높은 real 데이터을 찾기 어려웠다.
- BLSTM-EEND 에서는 이를 위해 높은 overlap ratio를 가지는 simulation dataset 생성하였다.
- Data augmentation
- Room Impulse Responses(RIRs)
- Simulated Room Impulse Response Database: 10,000 개
- Background noises
- MUSAN corpus: 37 recordings
- SNR: [ 10dB, 15dB, 20dB ]
- Algorithm
- Variable
- N_spk(2): 섞을 화자 수 (Mixture 개수)
- N_umax(20), N_umin(10): 각 화자 Mixture 내 최대, 최소 발화(utterance) 개수
- beta(2): 각 화자 Mixture 내 화자 간 발화 평균 간격(시간) (Non speech)
- Method
- 1) 전체 화자들(Training set 기준 5,743 명) 중 N_spk (2명) 수 만큼 Random sampling
- 2) 각 화자에 대한 Mixture 생성
- 2.1
i: 10,000개 RIR 중 1개 랜덤 선택- 2.2
N_u: Mixture 내 사용할 화자 발화(utterance) 개수를 N_umin과 N_umax 사이 값 랜덤 선택- 2.3 한 화자 Mixture 생성
- 이전 까지 생성된 mixture 사이에 간격
delta을 sampling 한다.
- 여기서
delta인 간격은 beta 값에 비례한다.- 이전 까지 생성된 mixture 사이에
delta만큼에 간격(non speech)을 준다.- 이후 RIR를 적용한 utterance 를 mixture 뒤에 이어 붙인다.
- 3) 생성된 화자별 Mixture를 더하여 하나의 Mixture
y생성- 4) MUSAN noise 와 SNR을 랜덤 선택
- 5) noise recording 길이를 mixture
y길이에 맞추기 위한 mixing scale p를 구한다.- 6) noise을 mixing scale 후 mixture
y에 더해준다.

Training set (2 speaker)
- [1] (처음 SA-EEND 제안한 논문의 Simulation 데이터)
- Training sets
- beta = 2 (34.4% overlap ratio) 100,000개의 mixture을 사용
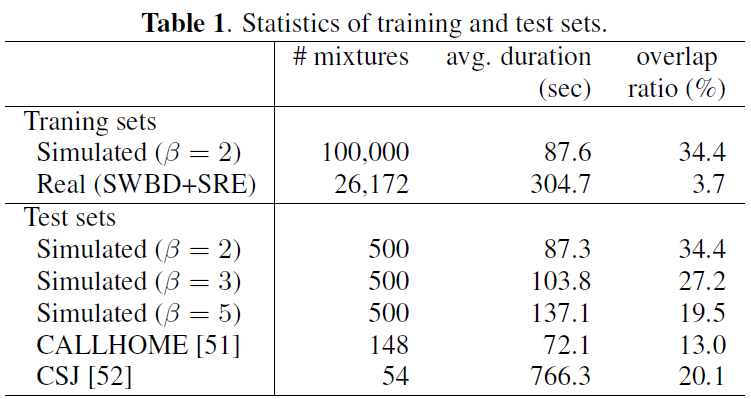
- [2] (revised SA-EEND 추가 실험한 논문의 Simulation 데이터)
- Training sets
- beta = 2,3,5,7 에 대한 다양한 overlap ratio를 100,000 개의 mixture 합친
SimLarge추가 구성SimLarge와Realdataset을 합친Comb데이터셋 추가 구성
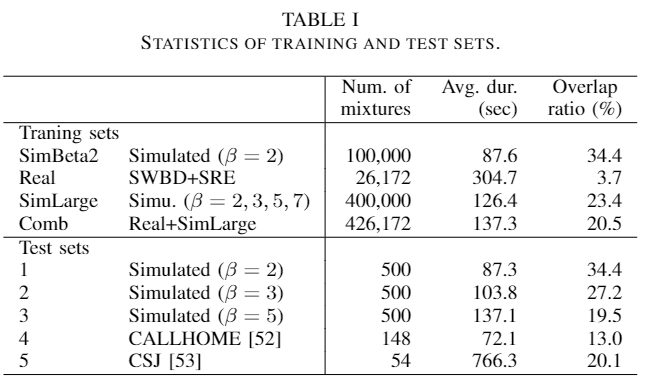
- [1], [2] 의 Validation, Adaptation and test set
- Validation set
- beta = 2, 3, 5 인 여러 종류의 overlap ratio 상황 각 500개 사용
- Adaptation set
- CALLHOME: 155 recordings
- Test set
- CALLHOME: 148 recordings
- CSJ: 54 recording
Model Configure and Training strategy
Model Configure
- Input
- 학습 시 오디오 최대 길이: 50초 (500 frames)
- SA-EEND
- Encoder Configure
P(Number of Encoder block) : 4D(Encoder hidden dimension) : 256d_ff(FFN internal units) : 1024S(Fixed-number of Speaker) : 2
Training strategy
- batch Size: 64
- 1) Training set ( Dataset: Simulated + Real (SWBD+SRE) )
- learning rate: 1.0
- scheduler
- norm warm up: 100k
- optimizer
- adam
- epoch: 100
- 2) Average model parameters
- 마지막 10 epoch model parameter 값을 averaging 하여 사용
- 즉, 각 91~100 epoch에 checkpoint model parameter 들을 평균하여 하나의 model parameter 생성
- 구체적인 설명은 없지만, Adaptation 전에 General 한 model을 사용하고 싶었던 것 같다.
- 3) Adaptation ( Dataset: CALLHOME dataset )
- 설명
- CALLHOME dataset 은 모델을 학습 시키기엔 적은 데이터 양이기 때문에, adaptation 과정을 이용한다.
- learning rate: 1e-5
- optimizer
- adam
- epoch: 100
- 4) Average model parameters
- 3의 결과에 대해서 2와 동일하게 적용
Results
Test set 평가 (method 별) [1]
- simulation dataset으로 학습한 경우 simulated 부분 SOTA 성능을 보임
- Real dataset으로 학습한 경우 simulated 은 성능이 떨어지지만, CH과 CSJ 부분 SOTA 성능
- Training set과 Test set에 overlap ratio 차이가 모델 성능이 영향이 있음을 보인다.
- overlap ratio 가 낮은 Real dataset 으로만 학습한 경우, overlap ratio가 높은 simulated validation set에 대해서 낮은 성능을 보인다.
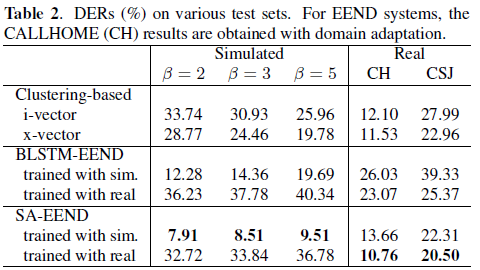
Test set 평가 (method 별) [2]
- 4종류의 beta 값(2,3,5,7)으로 구성된 SimLarge 데이터로 학습한 경우 simulated validation set 에 대해서 SOTA 성능을 보임
- SimLarge 와 Real dataset 을 섞어서 학습하면 Simulated 와 Real 둘다 괜찮은 성능을 보인다.
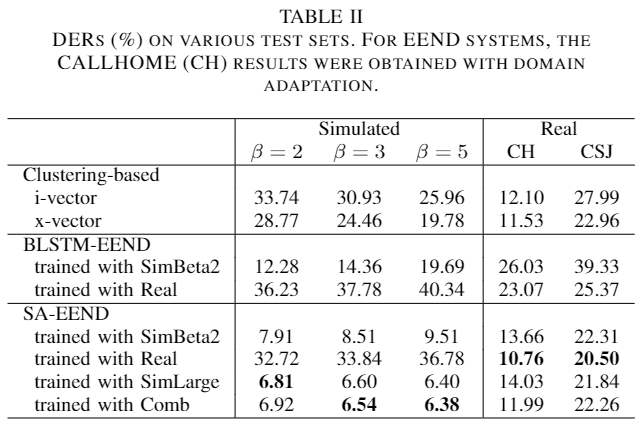
CALLHOME domain adaptation 결과 [2]
- Adaptation 이 성능에 많은 영향을 미치는 것을 보여준다.
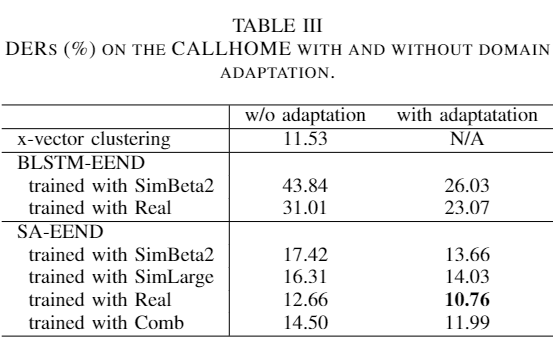
DER과 MI, FA, CF 및 SAD 관점 [2]
- Miss(MI), False alarms(FA), Confusion(CF) 관점 해석
- Miss(MI), False alarms(FA), Confusion(CF) 란?
- MI: 화자가 존재하지만 찾지 못한 경우
- FA: 화자가 존재하지 않는 있다고 한 경우
- CF: 화자가 존재하지만 다른 화자라고 한 경우
- MI, CF 관점에서 x-vector 보다 좋은 성능을 보인다.
- FA는 안 좋음. 이는 overlap FA에 따른 차이로 볼 수 있다 (FA의 SAD error 거의 동일).
- SAD 관점
- SA-EEND의 SAD error가 기존 SAD 모듈에 상응하는 성능을 보입니다.
Transformer header 개수에 따른 SA-EEND의 loss 값 및 실험 결과
- Header의 개수가 8인 경우 가장 좋은 성능을 보인다.
- Header의 개수가 늘어난다고 해서 항상 성능이 올라가는 것은 아니다. (H=16)
- Header 개수가 1개인 경우에는 학습이 진행되지 않는다.
- 이전 각 Header가 다른 역할을 하는 것을 보였다.
- 무성음과 유성음을 구분하는 VAD 역할
- 각 화자의 특성을 추출하는 역할
- 결국 이 2가지 역할을 하기 위해서 적어도 2개 이상의 Header가 존재해야한다고 주장한다. (실제로 찍어보면... 막상 이렇지도 않음 ㅎㅎ...^^... 보완이 필요함)
![]()
![]()
Transformer Layer 개수, Warm up step, Residual connection 사용에 따른 loss 및 실험 결과
- 1) Residual Connection
- Table VI에서 1, 2번째 줄 실험 결과는 Encoder Block 사이에 Residual Connection 사용 변화를 보여준다.
- CSJ를 제외한 다른 데이터에 대해서 Residual Connection 사용이 좋은 성능을 보인다.
- 이점에서 다른 실험에서도 Residual Connection을 모두 사용한 것을 볼 수 있다.
- 2) Transformer Layer 개수
- 개수가 늘어남에 따라 성능이 좋아지는 것을 볼 수 있다.
- 3) Norm warm-up step
- Norm warm-up은 시작 learning rate를 설정한 lr 에 설정한 step 값의 특정 승수 (-1.5)를 사용하여 나눠,
점점 step이 지날 수록 lr 값은 기존 값과 비슷하게 만들어준다.- Norm warm-up step 이 100k인 경우 더 낮은 loss 값에 수렴하는 것을 볼 수 있다.
![]()
![]()
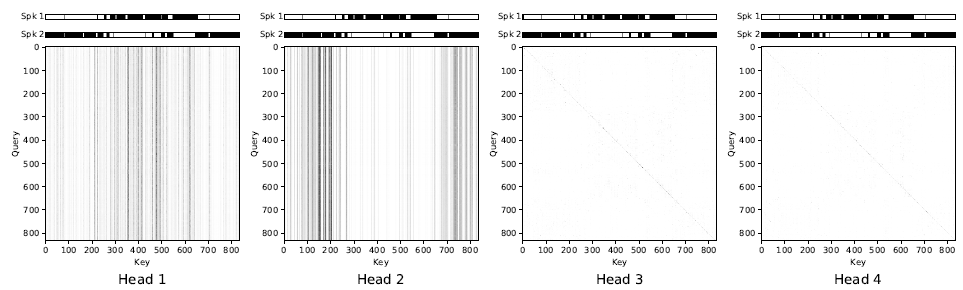
Visualization of self-attention [2]
- 이 SA-EEND의 2번 encoder block은 4개의 head 를 가지고 있다.
- 이 head는 각 query에 대해서 다른 key 값 형태를 보이는 것을 아래에서 볼 수 있다.
- Header 1, 2
- 먼저 1,2 head 같은 경우 각 쿼리 위치에 대해서 같은 key 값을 가지며 head 1은 spk 1의 발성 부분에, head 2는 spk 2의 발성 부분의 weight 값을 가진다.
- 이 1,2 head는 각 query에 대한 같은 key값으로 weighted mean과 같이 작동한다.
- 이는
global speaker의 특징을 대표하고, 두 화자를 분리하는 것으로 볼 수 있다.- Header 3, 4
- 3,4 head와 같은 경우 Query와 Key 값에 대해서
identity matrices와 같이 보이며, 이는position-independent linear transforms과 같이 작용한다.- 여기서는 이 head의 역활을
speech/non-speech detection으로 유추하지만, 정확한 실험이 더 필요해 보인다.

Audio & Speech AI Researcher 입니다.