Sound Classification 정리 - 0. Index
Sound Classification
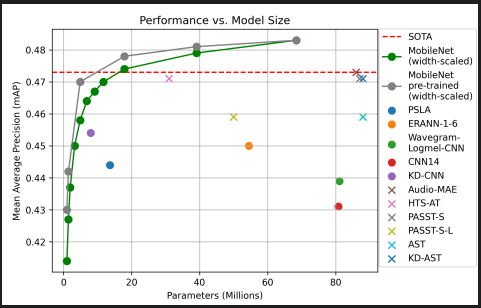
소개
-
이 글은 논문을 읽고 정리하기 위한 글입니다.
-
내용에 오류가 있는 부분이 있다면 조언 및 지적 언제든 환영입니다!
-
간단한 개념 위주로 정리할 예정입니다.
-
개인적으로 Audio & Speech 분야의 Sound Classification 에서 중요하다고 생각하는 논문을 정리해보았습니다.
-
Sound Classification은 전반적인 Sound(Audio) Representation을 연구하는 분야로 여러 Sound(Audio, Speech) 분야에서 BackBone 모델로 접근을 많이 하고 있는 중요한 모델입니다. 이러한 점에서 관심있게 공부했던 내용을 정리해보록 합니다.
Paper List
[1] PANNs: Large-Scale Pretrained Audio Neural Networks for Audio Pattern Recognition
[2] PSLA: Improving Audio Tagging with Pretraining, Sampling, Labeling, and Aggregation
[3] AST: Audio Spectrogram Transformer
[4] Efficient Training of Audio Transformers with Patchout (PaSST)
[5] SSAST: Self-Supervised Audio Spectrogram Transformer
[6] HTS-AT: A Hierarchical Token-Semantic Audio Transformer for Sound Classification and Detection
[7] CMKD: CNN/Transformer-Based Cross-Model Knowledge Distillation for Audio Classification
[8] Masked Autoencoders that Listen
[9] BEATs: Audio Pre-Training with Acoustic Tokenizers
[10] Efficient Large-scale Audio Tagging via Transformer-to-CNN Knowledge Distillation
