Sound Classification 정리 1. PANNs: Large-Scale Pretrained Audio Neural Networks for Audio Pattern Recognition
Sound Classification
목록 보기
2/8
소개
-
이 글은 논문을 읽고 정리하기 위한 글입니다.
-
내용에 오류가 있는 부분이 있다면 조언 및 지적 언제든 환영입니다!
-
간단한 개념 위주로 정리할 예정입니다.
-
개인적으로 Audio & Speech 분야의 Sound Classification 에서 중요하다고 생각하는 논문을 정리해보았습니다.
PANNs: Large-Scale Pretrained Audio Neural Networks for Audio Pattern Recognition
Main Proposal
- Google에서 수집한 유튜브 데이터인 Large-Scale AudioSet 데이터셋을 이용한 Pre-trained Audio Neural Networks 를 제안
- 다양한 오디오 분야에 대해 Transfer learning을 통한 성능 향상을 보임
- 다양한 모델 구조와 계산 복잡도를 가지는 모델들에 대한 성능 비교
- 다양한 학습 전략(Data Augmentation) 적용법 제안 및 성능 비교
- 여러 차원에 Acoustic 특징에 대한 성능 비교
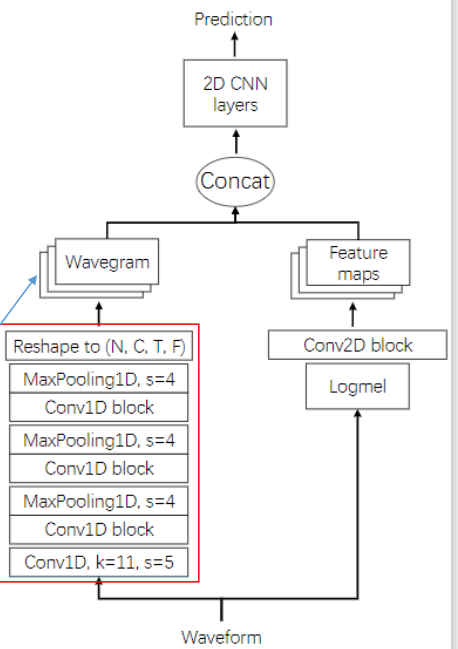
- 제안된 1D-Conv 기반의 모델 Wavegram 로 Raw wave로 부터 Acoutic Feature를 생성하여 사용
네트워크 관점
- 모델 종류
- 2D-Conv based model (VGGish, CNN6, CNN10, CNN14)
- ResNet based model (ResNet22, ResNet38, ResNet54)
- 1D-Conv based model (Res1dNet31, Res1dNet51)
- Wavegram-CNN, Wavegram-Logmel-CNN (raw audio with 1D-Conv + log mel with 2D-Conv)
- 경량화 모델 (MobileNetV1, MobileNetV2)
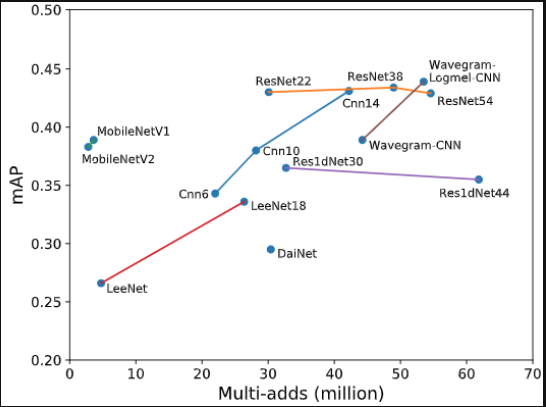
- 결론
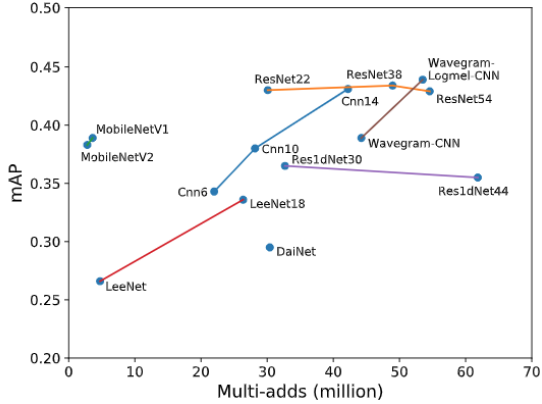
- 2D-Conv vs 1D-Conv
- 일반적으로 2D-Conv가 더 좋은 성능을 보여주고 있음
- 2D-Conv 장단점: Reasonable Pitch Shift 모델링 가능, 고유 주파수 대역 특징 모델링 불가능
- 1D-Conv 장단점: Pitch Shift 모델링 불가능, 고유 주파수 대역 특징 모델링 가능, 높은 차원의 Channel 수를 요구함
- Wavegram
- Wavegram은 Hand-Craft Acoustic Feature (Log-mel, MFCC) 와 같은 방법이 아닌 1D-Conv를 이용한 Acoustic Feature 학습 모델링 함
- 1D-Conv와 2D-Conv의 장단점을 보완하기 위해서 Wavegram 과 Log-mel Feature를 2D-Conv 한 특징을 함께 사용함
- 2D-Conv vs 1D-Conv
다양한 학습 전략
- Unbalanced Data Problem
- AudioSet 데이터는 527-Class에 대한 Multi-label Classification 테스크입니다. 여기서 AudioSet 데이터의 각 Class 별 분포는 굉장히 Unbalanced 한 문제를 가지고 있습니다.
- 본 논문에서는 2가지를 방법으로 관련 라벨 불균형 문제를 해결하려고 합니다.
- Balanced Sampling Strategy
- 본 논문에서는 클래스별 개수가 Balanced 하도록 Balanced Subset를 구성하여 실험하는 방법과 Balanced Sampler를 이용하여 전체 데이터를 사용하는 방법을 사용했습니다.
- 결과적으로 Balanced Sampler를 사용하는 것이 좋은 성능을 보입니다.
- Mixup
- Empirical Risk Minimization 관점에서도 효과가 있겠지만, Unbalanced label 관점에서
적은 개수의 클래스에 대한 데이터 증강 효과,복합 음원 증강과잡음 추가로도 볼 수 있습니다.
- Empirical Risk Minimization 관점에서도 효과가 있겠지만, Unbalanced label 관점에서

Audio & Speech AI Researcher 입니다.