소개
-
이 글은 논문을 읽고 정리하기 위한 글입니다.
-
내용에 오류가 있는 부분이 있다면 조언 및 지적 언제든 환영입니다!
-
간단한 개념 위주로 정리할 예정입니다.
-
개인적으로 Audio & Speech 분야의 Sound Classification 에서 중요하다고 생각하는 논문을 정리해보았습니다.
AST: Audio Spectrogram Transformer
Main Proposal
- Computer Vision의 ViT 모델을 채용하여 Audio Pattern Recognition에서도 Pure Attention 기반 모델의 사용 가능성을 보임
모델
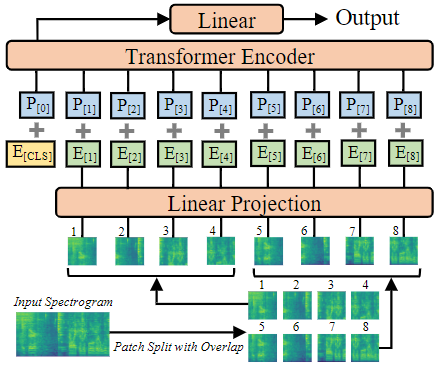
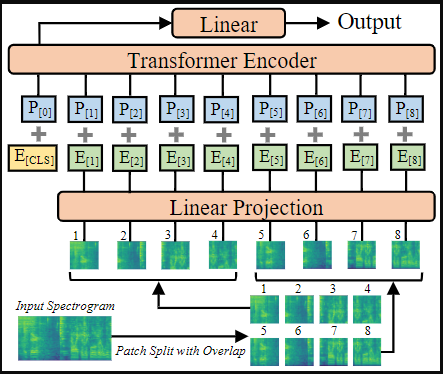
- PSLA와 동일한 Acoustic Feature 사용 (Log-Mel 128-d)
- Patch Embedding 이후 CLS Token 을 이용하여 Classification 진행
- 기존 ViT와는 다르게 Overlapped Patch Split 사용
- PSLT와 동일하게 ImageNet Weight Initialization 사용
- Patch Embedding Layer
- Log-Mel은 3-channel 이미지와 다르게 1-channel 이므로 첫번째 Layer의 Weight의 평균 값을 사용
- Input Normalize (0, 0.5) 사용
- Positional Embedding
- ImageNet 학습시 사용된 Token 개수가 달라짐. 이를 해결하기 위해 ViT에서 Downstream시 사용했던 Bi-linear interpolation 동일하게 사용
- Patch Embedding Layer
Parameter
- Input size: 1000 x 128
- Patch Size: 16 x 16
- Stride Size: 10 (Overlaped Patch)
- Embedding Size: 768, Layer: 12, Head: 12 (ViT-Base)- 결론
- 수정된 ViT 모델을 통해서 기존 CNN+Attention 모델 PSLA를 제치고 SOTA 달성

Audio & Speech AI Researcher 입니다.
audio spectrogram transformer가 low resource에도 사용이 가능한가요?
예를들면, voice disorder classification 같은 문제입니다.