Sound Classification 정리 4. Efficient Training of Audio Transformers with Patchout (PaSST)
Sound Classification
목록 보기
5/8
소개
-
이 글은 논문을 읽고 정리하기 위한 글입니다.
-
내용에 오류가 있는 부분이 있다면 조언 및 지적 언제든 환영입니다!
-
간단한 개념 위주로 정리할 예정입니다.
-
개인적으로 Audio & Speech 분야의 Sound Classification 에서 중요하다고 생각하는 논문을 정리해보았습니다.
Efficient Training of Audio Transformers with Patchout (PaSST)
Main Proposal
-
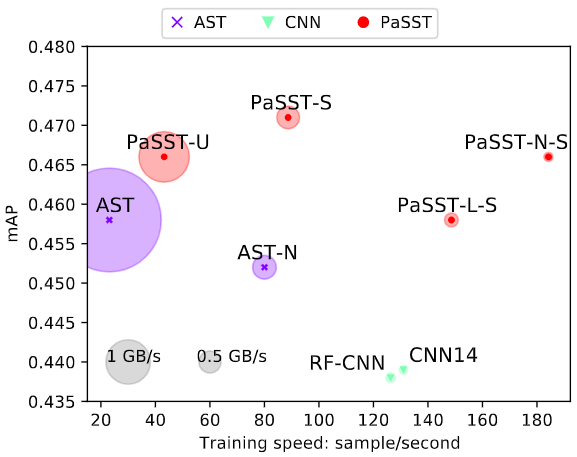
AST는 PSLA보다 높은 성능을 보였지만, Transformer의 Token 개수에 따른 메모리 및 계산 복잡도 문제로 낮은 속도 뿐 아니라 학습을 위한 거대한 GPU 메모리를 요구하였습니다. 본 논문에서는 이러한 문제를 효과적으로 해결하면서 성능까지 올리는 방법을 제안합니다.
-
Patchout 이라는 Regularizer 기법을 적용하여 빠른 학습 속도뿐 아니라 성능향상을 보여줌
-
2D Positional Encoding (PE)을 Frequency PE 와 Time PE 으로 나눠서 각각 학습하게 함
-
추가적인 Data Augmentation 기법 적용
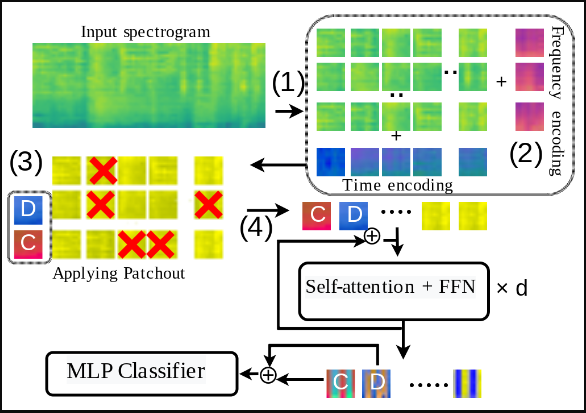
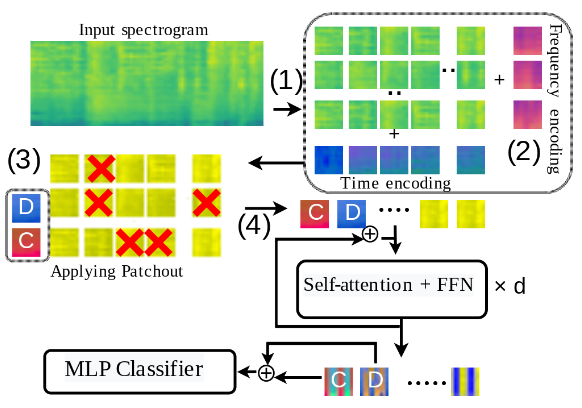
Model 구조 & Patchout
-
Frequency & Time Positional Encoding
- 아래 그림 우측 상단과 같이 Positional Encoding을 변경하여, 다양한 길이에 대한 Inference을 Fine-tuning 없이 Time Positional Encoding을 interpolation 하여 사용할 수 있도록 하였습니다.
-
Patchout
- Transformer 에 입력으로 들어가는 Patch Token들을 랜덤으로 제거하여 Regularizer 효과 뿐 아니라 학습 속도 향상을 보입니다.
- 논문에서는 2가지 방법 Patchout 기법을 제안합니다.
- Unstructured Patchout (U)
- Patch의 Freq, Time에 대한 구조를 사용하지 않고 Flatten 된 Patch 상태에서 Random으로 제거하는 방법. 아래 예시 그림 좌측 Drop 방법과 동일
- Structured Patchout (S)
- SpecAugment와 비슷하게 Freq, Time 구조를 채택하여 제거하는 방법
- 이 방법이 더 많은 Patch를 제거하여 높은 속도로 학습했음에도 더 좋은 성능을 보임
-
No-Overlap Patch (N)
- AST에서 사용한 Overlapped Patching 방법을 사용하지 않았을때 성능 저하 실험 있음
-
Light Model 실험 (L)
- 기존 12개 Encoder Layer 대신 7개 Encoder Layer를 사용하여 실험. Structured Patchout 를 같이 사용시 기존 AST와 유사한 성능을 보임
Data Augmentation
- Two-level Mix-Up
- raw waveform lavel에서 mixup 적용할 뿐 아니라 spectrom 상에서도 mixup 적용
- SpecAugment
- Freq Masking: 48 bin, Time Masking: 192 frame
- Rolling
- waveform Time rolling
- Random Gain
- waveform 의 gain 값 기존 gain의 7 gain 범위 안으로 random으로 변경함 (6dB가 2배)

Audio & Speech AI Researcher 입니다.