Sound Classification 정리 6. HTS-AT: A Hierarchical Token-Semantic Audio Transformer for Sound Classification and Detection
Sound Classification
목록 보기
7/8
소개
-
이 글은 논문을 읽고 정리하기 위한 글입니다.
-
내용에 오류가 있는 부분이 있다면 조언 및 지적 언제든 환영입니다!
-
간단한 개념 위주로 정리할 예정입니다.
-
개인적으로 Audio & Speech 분야의 Sound Classification 에서 중요하다고 생각하는 논문을 정리해보았습니다.
HTS-AT: A Hierarchical Token-Semantic Audio Transformer for Sound Classification and Detection
Main Proposal
- 기존 ViT 구조였던 AST를 Swin Transformer 형태로 변경하여 성능 향상을 보임
- Swin Transformer 구조를 통해서 전반적인 모델 경량화함
- SED(Sound Event Detection) 과 같이 Frame-level label Task 에 보다 효과적으로 Downstreaming 가능하도록 하기 위해서 Token-Sematic CNN 방법을 도입함
- 기존 AST의 ImageNet weight initialize 의존성 문제를 완하하여 Model-Scalability를 높임
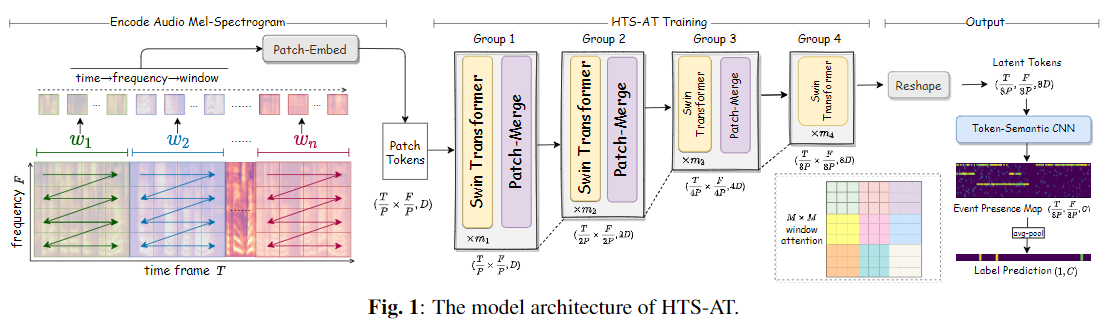
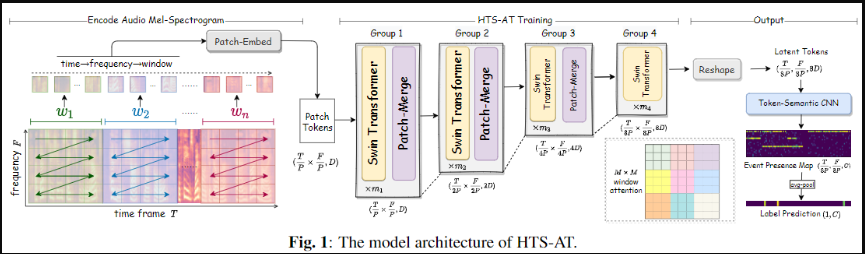
모델 구조
-
Hierarchical Transformer
- Swin Transformer 와 동일하게 Patch Merge을 통해 Patch를 점진적으로 줄여 경량화 함
-
Window Attention
- Time->frequency->Window 의 순서로 Patch Split 하여 Window 구성
- 잘 이해가 안되서 한번 분석 (틀릴 수도 있음)
Input: Bx1x64x1024 (Bx1xFxT) Interpolation: Bx1x256x1024 Patch size: 4x4 Patched Embedding: BxDx64x256 (BxCxFxT) Attention Window: 8x8 Window Attention Form Group 1: ( Bx8x32 )x1Dx8x8 Group 2: ( Bx4x16 )x2Dx8x8 Group 3: ( Bx2x8 )x4Dx8x8 Group 4: ( Bx1x4 )x8Dx8x8 Encoded Feature: Bx8Dx8x32 (BxCxFxT)
-
Token Segmantic CNN
- Transformer 를 통해서 생성된 Feature를 Frame 단위의 Classification 결과로 변경하기 위한 모델입니다.
- 위에서 생성된 (BxCxFxT) 에 대해서 Kernel size (F, 3), Padded Size (0, 1) 로 Frequency 성분을 주변 Frame을 보면서 Pooling 하여 Frame 별 Class 결과 Bx(Cls)x1xT 를 생성합니다.
- Frame 단위 출력의 경우 위 생성된 값에 Sigmoid 함수를 이용해 바로 사용하고, 단지 Classification의 경우 Average Pooling을 합니다.
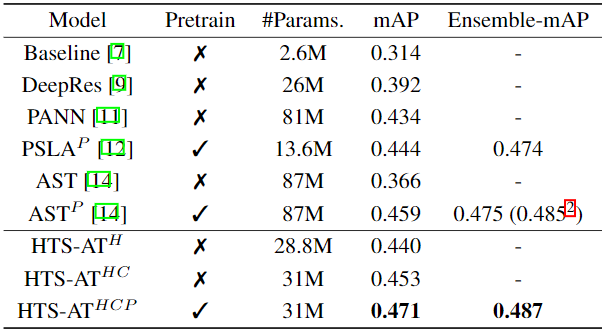
결과
- Single Model과 Ensemble 기준 모두 높은 성능을 보여줌
- Token-Segmentic CNN 효과 (HTS-AT^
Hvs HTS-AT^HC)- 단순히 Frequency Mean을 사용하는 것 보다 2D Conv 이용하는 것이 더 효과적임을 보임
- Pretrained 사용 여부 (ImageNet pretrained weighted initialize
P)- AST에서의 Pre-trained weighted 사용하지 않았을때의 심각한 성능 저하를 HTS-AT에서는 성능 저하가 줄어들었음을 보여줌
- 논문 언급
The pretrained model definitely improves the performance by building a solid prior on pattern recognition

Audio & Speech AI Researcher 입니다.