Sound Classification 정리 5. SSAST: Self-Supervised Audio Spectrogram Transformer
Sound Classification
목록 보기
6/8
소개
-
이 글은 논문을 읽고 정리하기 위한 글입니다.
-
내용에 오류가 있는 부분이 있다면 조언 및 지적 언제든 환영입니다!
-
간단한 개념 위주로 정리할 예정입니다.
-
개인적으로 Audio & Speech 분야의 Sound Classification 에서 중요하다고 생각하는 논문을 정리해보았습니다.
SSAST: Self-Supervised Audio Spectrogram Transformer
Main Proposal
- 이전 AST는 AudioSet을 통한 Audio(Sound) Classification 만을 위한 모델을 모델링 했다면, 본 논문에서는 SSL 방법을 통해 Speech 도메인에서 사용하는 LibriSpeech 데이터 셋을 같이 사용하여 Audio & Speech Classification 에서 동시에 사용할 수 있는 모델을 생성하고 성능 향상 시킴
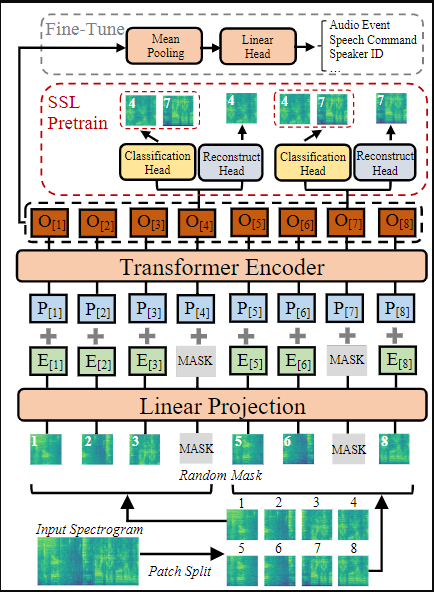
- MSPM(Masked Spectrogram Patch Modeling) 기법을 discriminative 와 generative 방법을 동시에 이용하여 SSL 학습 방법을 Audio & Speech 도메인에 적용함
- AST-Patch (16x16) 와 AST-Frame (128x2) 모드에 따른 도메인별 성능 차이를 보임 (아직 남아있는 문제 규명)
MSPM (Masked Spectrogram Patch Modeling)
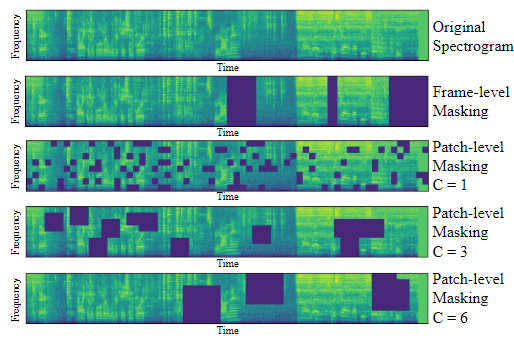
-
BERT와 비슷하게 Patch(Token) 기반으로 Feature Drop 이후 discriminative (InfoNCE Loss) 와 generative objective (MSE Loss)로 학습을 하는 방법입니다.
-
Patch Masking 알고리즘
- 이때 Drop을 주는 방법은 랜덤으로 선택된 Patch 을 중심으로 선택된 C(Squre Length) 만큼 주변 Patch를 Drop 하는 방법을 적용합니다.

- 이때 Drop을 주는 방법은 랜덤으로 선택된 Patch 을 중심으로 선택된 C(Squre Length) 만큼 주변 Patch를 Drop 하는 방법을 적용합니다.
-
Discriminative Objective (InfoNCE Loss)
- 자기 자신을 제외한 나머지 Token 간에 멀어지도록 모델링합니다.
- 본 논문에서는 Negative Sample을 같은 Spectrogram 상에 지워진 Token으로 주기 때문에 계산량과 학습 메모리 측면에서 효과적으라고 말합니다.
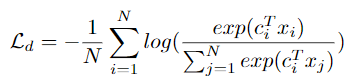
-
Generative Objective (MSE Loss)
- Reconstruction Loss를 주는 부분입니다.
-
전반적인 MSPM 학습 알고리즘
- 입력 Spectrogram (128x1024, log-mel)을 Split 합니다.
- Patch Embedding 합니다.
- Masking 할 위치를 계산해 냅니다. (I matrix)
- Masking 위치를 0 으로 채웁니다.
- PE를 더해서 Transformer의 입력으로 줍니다.
- 각 마스킹됬었던 Patch에 대해서 2개의 각각 MLP header를 이용하여 reconstruction(generative)과 classification(discriminative)를 각각 계산해 냅니다.

-
결론
- MSPM 학습을 통해 future or masked temporal structure 학습 (wav2vec 와 autoregressive 모델 장점) 뿐 아니라 구체적인 Frequency band와 구체적 Time range에 대해서도 학습시킴
모델 관련
-
Aggregation 관련
- 기존 AST는 CLS token 을 Target으로 학습되었습니다. 하지만 MSPM은 각각 Token이 개별적으로 학습이 진행됩니다.
- 이런 점에서
Mean pooling을 이용했다고 했습니다.
-
Patch Split 관점
- SSL에서는 reconstruction task가 존재하므로, 보다 hard task를 상황을 만들기 위해서 Overlapped Split 이 아니라 Non-overlap Split을 사용함
간단한 실험 결과 분석
-
Number of Masking Patch
- 전체 512개의 Patch 중 마스킹 개수에 따른 성능차이
- 100개 보다 400개일때 더 좋은 성능 (사소한 정보를 학습하지 못하도록 마스킹 비율을 주는 것이 중요하다는 것)
- 400개일때 보다 250개일때 Speech task 들에 대해서는 소폭 성능 향상을 보이지만 전반적인 성능은 400개일때 더 좋음
- Inference 시에는 적적한 범위의 Masking 범위까지 점진적 성능 저하를 보여줌
-
Patch-based and Frame-based SSAST(AST)
- SV 연구했던 나로썬 개인적으로 재밋게 읽은 부분!
- 기존 Square Patch 형태와 Frequency를 모두 담는 Frame Patch 형태의 AST를 비교함
- 일반적으로 1D Feature 형태인 Frame-Patch 형태가 2D Feature 보다 학습하기 쉽다고 알려져 있음. `1-D temporal structure is easier to learn than 2-D temporal-frequency structure.
- Scratch 학습 시 Frame-based AST가 좋은 성능을 보였고, MSPM 적용시에는 Speech Task들에 대해서 Frame-based AST가 높은 성능을 보였습니다. (재밋음)
- Patch-based 인 2D Feature 을 그대로 이용하는 Square Patch 방식이 Audio Classification에서 좋은 성능을 보이는데, 저자는 complex frequency structure 을 가지는 nature sound들을 잘 다룰 수 있기 때문이라고 주장합니다.
-
SSL 모델 비교
- APC, Wav2vec 1.0 & 2.0, HuBERT에서 비교
- 솔직히 Wav2vec 2.0과 HuBERT 보다 좋지 않아 보입니다. 하지만 낮은 Batch size(24)을 사용한 점에서 정당비교로 보기에는 어렵다라고 설명하고 있고, Frame-based SSAST 기준으로 보자면 batch size을 늘리고 학습하면 더 좋을 가능성이 있다고 설명합니다. (아쉬움)
- LibriSpeech Only 방식으로 SSAST-Frame 결과가 궁금하긴 합니다. Speech Classification Task 에서 AudioSet 데이터의 영향이 궁금!

Audio & Speech AI Researcher 입니다.