1. Sequence 데이터란?
💡 Sequence 데이터 = 순서가 있는 데이터. 앞뒤 맥락이 중요하며, 순서를 바꾸면 의미가 달라집니다.
일반적인 신경망(Feedforward NN)은 각 입력을 독립적으로 처리합니다. 하지만 현실의 많은 데이터는 앞에 무엇이 왔느냐가 중요합니다.
예시 — 왜 순서가 중요한가?
일반 데이터 (순서 무관):
고양이 사진의 픽셀값 → 고양이인지 판단 (앞뒤 맥락 불필요)
Sequence 데이터 (순서 중요):
"나는 __ 를 먹었다" → 밥? 피자? 앞 문맥을 알아야 다음 단어 예측 가능
오늘의 주가 → 내일 주가 예측 시 지난 30일 흐름이 필요Sequence 데이터의 실제 활용 분야
| 분야 | 입력 | 출력 |
|---|---|---|
| 음성 인식 | 마이크 파동의 연속 | 텍스트 단어 |
| 감성 분석 | 리뷰 문장 전체 | 긍정 / 부정 |
| 자동 번역 | 한국어 문장 | 영어 문장 |
| 주가 예측 | 과거 N일치 시세 | 다음날 주가 |
| DNA 분석 | 염기서열 (A, T, G, C) | 질병 유무, 단백질 종류 |
| 작곡 생성 | 앞 마디의 음표들 | 다음 음표 |
| 영상 행동 인식 | 연속된 프레임 | 걷기 / 뛰기 / 넘어짐 |
⚠️ 기존 Feedforward NN은 이런 순서 정보를 처리할 수 없습니다. 이것이 RNN이 등장한 이유입니다.
2. RNN (Recurrent Neural Network)
🧠 RNN의 핵심 아이디어: "기억"
RNN은 이전 입력을 기억하면서 새로운 입력을 처리합니다. 마치 사람이 책을 읽을 때 앞 내용을 기억하며 다음 문장을 이해하는 것과 같습니다.
💡 "Recurrent"(순환) 이라는 이름은 같은 네트워크를 매 시간 단계(time step)마다 반복 적용하기 때문에 붙었습니다.
일반 신경망 vs RNN 비교
일반 신경망 (Feedforward NN):
입력₁ → [네트워크] → 출력₁ (각 입력을 독립 처리, 기억 없음)
입력₂ → [네트워크] → 출력₂
입력₃ → [네트워크] → 출력₃
RNN:
입력₁ → [네트워크] → 출력₁
↓ (기억 전달)
입력₂ → [네트워크] → 출력₂
↓ (기억 전달)
입력₃ → [네트워크] → 출력₃📐 RNN의 수식
RNN은 두 가지 계산을 수행합니다.
① 내부 상태 (Hidden State) 업데이트
h_t = tanh(W_h × h_(t-1) + W_x × x_t + b)| 기호 | 의미 |
|---|---|
h_t | 현재 시간 t의 hidden state (기억) |
h_(t-1) | 이전 시간의 hidden state (과거 기억) |
x_t | 현재 시간 t의 입력 |
W_h | 이전 hidden state에 곱하는 가중치 (과거 기억을 얼마나 반영할지 결정하는 파라미터) |
W_x | 현재 입력에 곱하는 가중치 (현재 입력의 영향력을 조절) |
tanh | 활성화 함수 (-1 ~ +1 범위로 압축) |
② 출력 계산
y_t = softmax(W_y × h_t + b_y)참고로 b_y는 선형 변환에서 사용하는 bias(편향)이고, softmax는 값을 확률로 바꿔주는 함수입니다.
💡 가중치 공유의 의미: 모든 time step에서 같은 W를 재사용합니다. 이 덕분에 문장이 길어져도 파라미터 수가 늘지 않습니다.
직관적 이해 — 뉴스 헤드라인 분류 예시
입력 문장: "삼성전자 주가 사상 최고치 경신"
t=1: "삼성전자" 입력 → h₁ = 기업 관련 기억
t=2: "주가" 입력 → h₂ = 기업 + 주식 기억
t=3: "사상" 입력 → h₃ = 기업 + 주식 + 강조 기억
t=4: "최고치" 입력 → h₄ = 기업 + 주식 + 상승 기억
t=5: "경신" 입력 → h₅ = 전체 맥락 요약 → "경제" 카테고리 출력🌀 RNN 펼치기 (Unfolding)
RNN을 시간 순서대로 펼치면, 가중치를 공유하는 매우 깊은 신경망이 됩니다.
[접힌 표현] [펼친 표현 (Unfolded)]
x₁ x₂ x₃ x₄
↓ ↓ ↓ ↓
h → [RNN] → h h₀→[RNN]→h₁→[RNN]→h₂→[RNN]→h₃→[RNN]→h₄
↑ (순환) ↓ ↓ ↓ ↓
y₁ y₂ y₃ y₄- 왼쪽(접힌 표현): 같은 블록이 순환하는 모습
- 오른쪽(펼친 표현): time step 수만큼 층이 쌓인 깊은 신경망
- 모든 블록의 W는 동일 — 학습 시 이 W를 공유해서 업데이트
📚 BPTT (Backpropagation Through Time): 펼친 구조에서 일반적인 역전파(Backpropagation)를 시간 축으로 적용하여 파라미터를 학습합니다.
3. RNN의 종류 (구조별 분류)
입력과 출력의 개수에 따라 RNN 구조가 달라집니다.
| 구조 | 입력 | 출력 | 대표 사례 |
|---|---|---|---|
| One-to-One | 1개 | 1개 | 일반 신경망 (RNN 아님) |
| One-to-Many | 1개 | 여러 개 | 이미지 → 설명 문장 생성 (Image Captioning), 음악 작곡 |
| Many-to-One | 여러 개 | 1개 | 감성 분석, 스팸 메일 분류 |
| Many-to-Many (동기) | 여러 개 | 여러 개 (같은 길이) | 품사 태깅, 개체명 인식 |
| Many-to-Many (비동기) | 여러 개 | 여러 개 (다른 길이) | 기계 번역, 챗봇, Q&A |
각 구조 직관적 이해
One-to-Many (이미지 캡셔닝):
[고양이 사진] → "귀여운 고양이가 소파 위에 앉아있다"
Many-to-One (감성 분석):
"배송도 빠르고 품질도 정말 좋아요" → ⭐⭐⭐⭐⭐ (긍정)
Many-to-Many 동기 (품사 태깅):
나는 밥을 먹었다
↓ ↓ ↓
대명사 명사 동사
Many-to-Many 비동기 (번역):
"오늘 날씨 정말 좋다"
↓↓↓↓ (Encoder가 전체 이해)
"The weather is really nice today" (Decoder가 순차 생성)4. RNN의 학습 원리
학습 시나리오: 주식 시황 요약 문장 생성
4개의 단어만 있다고 가정합니다: 상승, 하락, 급등, 급락
각 단어를 One-Hot Encoding으로 표현합니다.
상승 → [1, 0, 0, 0]
하락 → [0, 1, 0, 0]
급등 → [0, 0, 1, 0]
급락 → [0, 0, 0, 1]학습 목표: 상승을 시작으로 상승→급등→급등→하락 순서를 출력하도록 훈련
time step 1: 입력 "상승" → 예측 목표: "급등"
time step 2: 입력 "급등" → 예측 목표: "급등"
time step 3: 입력 "급등" → 예측 목표: "하락"학습 과정
- 현재 입력 + 이전 hidden state → 새로운 hidden state 계산
- hidden state → output 계산 (각 단어일 확률)
- 정답 단어의 확률이 높아지도록 Gradient Descent + BPTT로 W 업데이트
⚠️ 중요 포인트: "급등" 다음에 올 단어는 "급등" 하나만 보고는 알 수 없습니다. 앞에 "상승"이 있었는지 "하락"이 있었는지 등 이전 문맥(history) 전체가 필요합니다. 이것이 hidden state가 존재하는 이유입니다.
5. LSTM (Long Short-Term Memory)
😰 Simple RNN의 한계: 장기 의존성 문제
문장: "저는 어릴 때부터 부산에서 자랐고, 부산 사투리로 말하고,
부산 음식을 좋아하며, 대학도 부산에서 다녔기 때문에
제 모국어는 당연히 [ ]입니다."
정답: "한국어" (또는 "부산 사투리")[ ]를 채우려면 수십 단어 앞의 "부산"이라는 맥락이 필요합니다. Simple RNN은 기울기 소실(Vanishing Gradient) 문제로 이렇게 먼 과거 정보를 기억하지 못합니다.
💡 기울기 소실: BPTT로 역전파 시, 시간이 멀어질수록 기울기가 0에 가까워져 학습이 사실상 중단되는 현상.
🏗️ LSTM의 해결책: 두 가지 기억 경로
LSTM은 두 개의 독립적인 기억 을 유지합니다.
| 기억 종류 | 이름 | 역할 |
|---|---|---|
| 장기 기억 | Cell State (c_t) | 중요 정보를 오랫동안 보존하는 컨베이어 벨트 |
| 단기 기억 | Hidden State (h_t) | 현재 시점의 작업용 기억 (출력에 직접 사용) |
Simple RNN: 입력 → [tanh] → hidden state → 출력
↑ 하나의 기억만 존재
LSTM: 입력 → [게이트 × 3] → cell state (장기) ──→ 출력
→ hidden state (단기) ─↗🚪 LSTM의 3개 게이트
게이트(Gate)는 0~1 사이의 값을 출력하는 시그모이드(σ) 함수로, 정보를 얼마나 통과시킬지 결정하는 밸브입니다.
게이트 ① — Forget Gate (망각 게이트)
"과거 기억 중 얼마나 지울까?"
G_f = σ(W_f × [h_(t-1), x_t] + b_f)
출력 범위: 0 (완전히 잊음) ~ 1 (완전히 기억)비유 — 독서 메모 지우기
책을 읽으며 메모하는 상황:
5장을 읽고 나서 1~4장 내용 중 이제 필요 없는 정보는 지운다.
"주인공 이름 → 계속 필요 (G_f ≈ 1, 기억 유지)"
"1장의 날씨 묘사 → 이제 필요 없음 (G_f ≈ 0, 잊음)"게이트 ② — Update Gate (업데이트 게이트, Input Gate)
"새로운 입력을 얼마나 받아들일까?"
새 후보값: c̃_t = tanh(W_c × [h_(t-1), x_t] + b_c) → -1~1 (새로운 기억 후보)
게이트: G_i = σ(W_i × [h_(t-1), x_t] + b_i) → 0~1 (얼마나 받아들일지)비유 — 독서 메모 추가하기
새 챕터를 읽고:
"중요한 반전 정보 → 확실히 메모 (G_i ≈ 1, 완전히 기록)"
"단순한 날씨 묘사 → 메모 생략 (G_i ≈ 0, 무시)"게이트 ③ — Output Gate (출력 게이트)
"현재 기억 중 얼마나 출력할까?"
G_o = σ(W_o × [h_(t-1), x_t] + b_o)비유 — 발표 준비하기
모든 메모를 가지고 있지만:
"지금 질문과 관련된 내용 → 꺼내서 답변 (G_o ≈ 1)"
"지금 질문과 무관한 내용 → 일단 보류 (G_o ≈ 0)"⚙️ LSTM 전체 계산 흐름
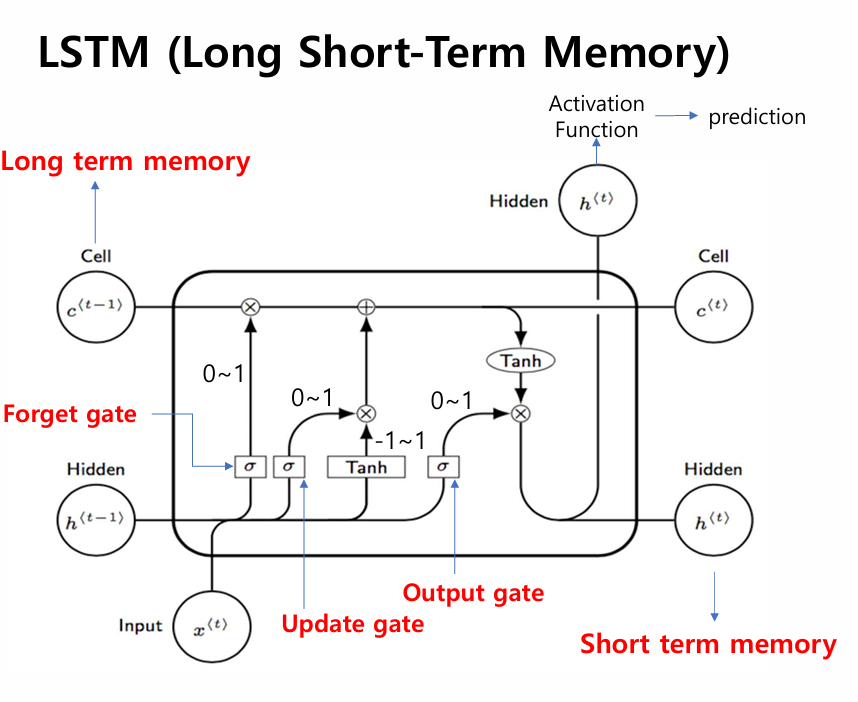
입력: x_t (현재 단어), h_(t-1) (이전 단기 기억), c_(t-1) (이전 장기 기억)
Step 1. 새 기억 후보 계산
c̃_t = tanh(W_c × [h_(t-1), x_t] + b)
Step 2. 망각 게이트 — 과거를 얼마나 지울지
G_f = σ(W_f × [h_(t-1), x_t] + b_f)
Step 3. 업데이트 게이트 — 새 정보를 얼마나 받을지
G_i = σ(W_i × [h_(t-1), x_t] + b_i)
Step 4. 출력 게이트 — 얼마나 내보낼지
G_o = σ(W_o × [h_(t-1), x_t] + b_o)
Step 5. 장기 기억(Cell State) 업데이트
c_t = G_f × c_(t-1) + G_i × c̃_t
└─ 과거 중 남길 것 └─ 새로 추가할 것
Step 6. 단기 기억(Hidden State) 계산 → 출력
h_t = G_o × tanh(c_t)
출력: h_t (이번 step 출력), c_t (다음 step으로 전달)전체 흐름 다이어그램
x_t
│
h_(t-1) ──┤
│
┌──────────▼──────────────────────────────┐
│ │
│ c_(t-1) ──[× G_f]──[+ G_i × c̃_t]──── c_t ──→ 다음 step
│ ↑ ↑ │
│ Forget gate Update gate tanh │
│ × G_o
│ │
└────────────────────────────────────────────┘
h_t ──→ 출력 & 다음 step💡 핵심: Cell State는 정보의 고속도로입니다. 게이트가 열려 있으면 수십 단계 전의 정보도 거의 손실 없이 전달됩니다.
6. GRU (Gated Recurrent Unit)
🎯 GRU란?
LSTM의 장점을 유지하면서 구조를 단순화한 모델입니다 (2014년 Cho et al. 제안).
LSTM vs GRU 비교
| 항목 | LSTM | GRU |
|---|---|---|
| 게이트 수 | 3개 (Forget, Update, Output) | 2개 (Reset, Update) |
| 기억 종류 | Cell State + Hidden State | Hidden State만 |
| 파라미터 수 | 많음 | 적음 (약 25% 감소) |
| 학습 속도 | 느림 | 빠름 |
| 성능 | 긴 시퀀스에서 우세 | 짧은 시퀀스에서 유사 |
GRU의 2개 게이트
Reset Gate (r_t): 과거 기억을 얼마나 리셋할지 → 0이면 과거 무시, 1이면 유지
Update Gate (z_t): 새 정보와 과거를 어떻게 섞을지 → LSTM의 Forget+Input 통합GRU 계산 흐름
r_t = σ(W_r × [h_(t-1), x_t]) ← Reset gate
z_t = σ(W_z × [h_(t-1), x_t]) ← Update gate
h̃_t = tanh(W × [r_t × h_(t-1), x_t]) ← 새 후보 기억
h_t = (1 - z_t) × h_(t-1) + z_t × h̃_t ← 최종 hidden state💡 언제 GRU를 쓸까?
- 데이터가 적거나 빠른 학습이 필요할 때
- 시퀀스가 짧을 때
- LSTM과 성능 차이가 없다면 GRU가 효율적
7. LSTM 입출력 형태 완전 정리
📦 LSTM 입력 shape
(batch_size, timesteps, features)
↑ ↑ ↑
한번에처리할 시퀀스 각 시점의
문장 수 길이 특징 벡터 크기예시: 32개의 문장, 각 문장 20단어, 단어당 100차원 벡터
input_shape = (32, 20, 100)📤 return_sequences 옵션
return_sequences=False (기본값)
입력: [x₁, x₂, x₃, x₄, x₅]
출력: [ h₅] ← 마지막 time step의 출력만 반환
사용 사례: Many-to-One
예) 리뷰 문장 전체를 읽고 별점 하나 예측
"이 제품 정말 별로예요, 환불하고 싶어요" → ⭐ (1점)return_sequences=True
입력: [x₁, x₂, x₃, x₄, x₅]
출력: [h₁, h₂, h₃, h₄, h₅] ← 모든 time step의 출력 반환
사용 사례: Many-to-Many 또는 LSTM 여러 층 쌓기
예) 각 단어의 품사를 순서대로 예측
["나는", "학교에", "갔다"] → ["대명사", "명사+격조사", "동사"]📤 return_state 옵션
return_state=False (기본값)
반환: output만return_state=True
반환: (output, last_hidden_state, last_cell_state)
↑ ↑
마지막 h_t 마지막 c_t
사용 사례: Seq2Seq 모델에서 Encoder의 최종 상태를 Decoder로 전달할 때4가지 조합 정리
| return_sequences | return_state | 반환값 |
|---|---|---|
False | False | 마지막 출력만 |
True | False | 모든 time step 출력 |
False | True | 마지막 출력 + h_t + c_t |
True | True | 모든 출력 + 마지막 h_t + c_t |
Python 코드 예시
import tensorflow as tf
# return_sequences=True, return_state=True
lstm = tf.keras.layers.LSTM(64, return_sequences=True, return_state=True)
output, last_h, last_c = lstm(input_data)
# output.shape → (batch, timesteps, 64) 모든 step 출력
# last_h.shape → (batch, 64) 마지막 hidden state
# last_c.shape → (batch, 64) 마지막 cell state8. Bidirectional LSTM
🔄 왜 양방향이 필요한가?
일반 LSTM은 앞에서 뒤로만 읽습니다. 하지만 문장의 의미는 뒤 맥락도 중요합니다.
문장: "그는 [ ] 앞에서 긴장한 듯 손을 떨었다"
→ 일반 LSTM: "그는" "앞에서" "긴장한" ... 앞→뒤로만 읽음
→ "면접관" "의사" "교수" 등이 정답 후보 → 뒤 문맥도 봐야 확실
→ Bidirectional LSTM: 앞→뒤 + 뒤→앞 동시에 읽음
→ "손을 떨었다"를 먼저 보고 역방향으로 올라오면 더 정확한 추론 가능⚙️ Bidirectional LSTM 구조
순방향 (Forward) LSTM: x₁ → x₂ → x₃ → ... → xT
역방향 (Backward) LSTM: xT → x_(T-1) → ... → x₁
각 time step에서 두 방향의 hidden state를 합쳐(concatenate) 출력출력 형태
각 timestep t의 출력 = [순방향 h_t ; 역방향 h_t]
예시 (LSTM units=64):
순방향 h_t → 64차원
역방향 h_t → 64차원
합친 출력 → 128차원특수한 경우 — 최종 출력 (output at T)
순방향 마지막 출력: timestep T의 forward state (전체 문장을 앞에서 읽은 결과)
역방향 마지막 출력: timestep 1의 backward state (전체 문장을 뒤에서 읽은 결과)
→ 이 둘을 이어붙여 반환 = 문장 전체 맥락을 양방향으로 요약한 벡터Python 코드 예시
import tensorflow as tf
# Bidirectional LSTM
bilstm = tf.keras.layers.Bidirectional(
tf.keras.layers.LSTM(64, return_sequences=True, return_state=True)
)
output, fwd_h, fwd_c, bwd_h, bwd_c = bilstm(input_data)
# output.shape → (batch, timesteps, 128) ← 64×2, 양방향 concatenate
# fwd_h.shape → (batch, 64) ← 순방향 마지막 hidden state
# fwd_c.shape → (batch, 64) ← 순방향 마지막 cell state
# bwd_h.shape → (batch, 64) ← 역방향 마지막 hidden state
# bwd_c.shape → (batch, 64) ← 역방향 마지막 cell state활용 사례
| 모델 | 방향 | 이유 |
|---|---|---|
| 번역 Encoder | 양방향 | 원문 전체를 완전히 이해해야 함 |
| BERT | 양방향 | 단어의 의미는 앞뒤 문맥 모두에 의존 |
| 번역 Decoder | 단방향 | 생성 시 미래 단어를 미리 알 수 없음 |
| 실시간 음성인식 | 단방향 | 아직 발화되지 않은 미래 음성 불가 |
9. 전체 비교 요약
| 모델 | 장점 | 단점 | 주요 사용처 |
|---|---|---|---|
| Simple RNN | 구조 단순, 이해 쉬움 | 장기 의존성 학습 불가 (기울기 소실) | 짧은 시퀀스, 교육용 |
| LSTM | 장기 의존성 해결, 안정적 학습 | 파라미터 많음, 느림 | 번역, 감성분석, 시계열 예측 |
| GRU | LSTM보다 빠름, 파라미터 적음 | 매우 긴 시퀀스에선 LSTM이 우세 | 짧은 텍스트, 빠른 실험 |
| Bidirectional LSTM | 앞뒤 문맥 모두 활용 | 실시간 처리 불가, 연산 2배 | NER, BERT Encoder, 품사 태깅 |
🎯 마무리 퀴즈
Q1. RNN에서 모든 time step이 같은 가중치를 공유하는 이유는?
정답: 파라미터 수를 일정하게 유지하기 위해서입니다. 문장 길이가 달라도 동일한 W를 재사용하여 효율적으로 학습합니다.
Q2. Simple RNN이 "저는 부산에서 자랐기 때문에 제 모국어는 [ ]입니다"를 틀리게 예측할 수 있는 이유는?
정답: 기울기 소실(Vanishing Gradient) 문제로 멀리 있는 "부산"이라는 단서를 기억하지 못하기 때문입니다. LSTM의 Cell State가 이를 해결합니다.
Q3. LSTM의 Forget Gate 값이 0에 가까울 때와 1에 가까울 때 각각 어떤 의미인가요?
0에 가까울수록: 이전 cell state를 완전히 잊음 (새 문단 시작 등)
1에 가까울수록: 이전 cell state를 완전히 유지 (중요 맥락 보존)
Q4. return_sequences=True가 필요한 경우는?
① LSTM 층을 여러 개 쌓을 때 (다음 LSTM 층이 모든 time step 출력을 입력받아야 할 때)
② Many-to-Many 구조가 필요할 때 (각 time step마다 출력이 필요한 번역, 품사 태깅 등)
