1. 감성분석 (Sentiment Analysis)
💬 감성분석이란?
텍스트를 읽고 감정·의견의 방향을 자동으로 판단하는 NLP 태스크입니다.
입력: "주문한 지 하루 만에 도착했고, 포장도 꼼꼼해서 정말 만족스러워요."
출력: ⭐⭐⭐⭐⭐ → 긍정 (Positive)
입력: "소재가 사진이랑 너무 달라요. 환불 신청했습니다."
출력: ⭐ → 부정 (Negative)💡 감성분석은 이진 분류(Binary Classification) 가 기본입니다.
레이블:
positive(1)vsnegative(0)
🏗️ RNN으로 감성분석 구현하기
감성분석은 문장 전체를 읽고 하나의 결론을 내리는 태스크입니다.
따라서 Many-to-One 구조의 RNN을 사용합니다.
문장: ["배송이", "너무", "느려요", "다음엔", "안", "살게요"]
↓ ↓ ↓ ↓ ↓ ↓
[LSTM]→[LSTM]→[LSTM]→[LSTM]→[LSTM]→[LSTM]
↓
긍정 / 부정 ← 마지막 출력만 사용예시 문장
The movie is not good처리 과정
movie → 중립
is → 중립
not → 부정 방향
good → 긍정이지만 이전 부정과 결합hidden state 변화
h1 → 중립
h2 → 중립
h3 → 부정
h4 → 약한 부정즉, 문장의 의미 상태가 계속 업데이트됨.
문장 → 마지막 hidden state → classifier → sentiment
classifier가
h4 → negative probability
h4 → positive probability계산해서
negative = 0.7
positive = 0.3이면 결과 = 부정
핵심 파라미터: return_sequences = False
# Many-to-One 감성분석 모델 예시
import tensorflow as tf
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim), # 단어 → 벡터
tf.keras.layers.LSTM(64, return_sequences=False), # 마지막 출력만
tf.keras.layers.Dense(1, activation='sigmoid') # 0~1 확률 출력
])return_sequences | 출력 형태 | 사용 시나리오 |
|---|---|---|
False (기본값) | 마지막 step 출력 1개 | 감성분석, 스팸분류, 문서 분류 |
True | 모든 step 출력 | 번역, 개체명 인식, 품사 태깅 |
📊 실제 학습 데이터셋
① IMDB 영화 관람평 (영어)
규모: 훈련 25,000개 + 테스트 25,000개
레이블: positive / negative (이진 분류)
특징: 영어권 감성분석의 기본 벤치마크 ("NLP의 Hello World")
데이터 예시:
"Absolutely loved it. One of the best movies I've seen in years." → positive
"A complete waste of time. The plot made no sense whatsoever." → negative② 네이버 영화 관람평 (한국어, NSMC)
규모: 훈련 150,000개 + 테스트 50,000개
레이블: positive / negative (이진 분류)
특징: 한국어 감성분석 표준 데이터셋
데이터 예시:
"연기가 너무 자연스럽고 스토리도 탄탄해요" → positive
"억지스러운 전개에 배우들 연기도 어색함. 비추천" → negative한국어 데이터 전처리 시 추의사항
| 문제 | 처리 방법 |
|---|---|
| null 데이터 존재 | 학습 전 반드시 결측치 제거 (data cleansing) |
| 한글 이외 문자 | 특수문자·숫자·영문 제거 또는 별도 처리 |
| 불용어 | "의, 가, 이, 은, 들, 는, 좀, 잘, 걍, 과" 등 제거 |
| 띄어쓰기 오류 | 형태소 분석기 필수 (공백 기준 토큰화 불가) |
KoNLPy Okt 형태소 분석 예시
from konlpy.tag import Okt
okt = Okt()
sentence = "오늘날씨가너무좋아서기분이최고다"
tokens = okt.morphs(sentence)
# → ['오늘', '날씨', '가', '너무', '좋아서', '기분', '이', '최고', '다']
# 명사만 추출
nouns = okt.nouns("카카오뱅크주가가오늘상한가를기록했다")
# → ['카카오뱅크', '주가', '오늘', '상한가']⚠️ 한국어는 "아버지가방에들어가신다" → '아버지가 방에 들어가신다' vs '아버지 가방에 들어가신다'처럼
띄어쓰기 하나로 의미가 완전히 달라집니다. 형태소 분석기 없이 공백 기준으로만 나누면 심각한 오류가 발생합니다.
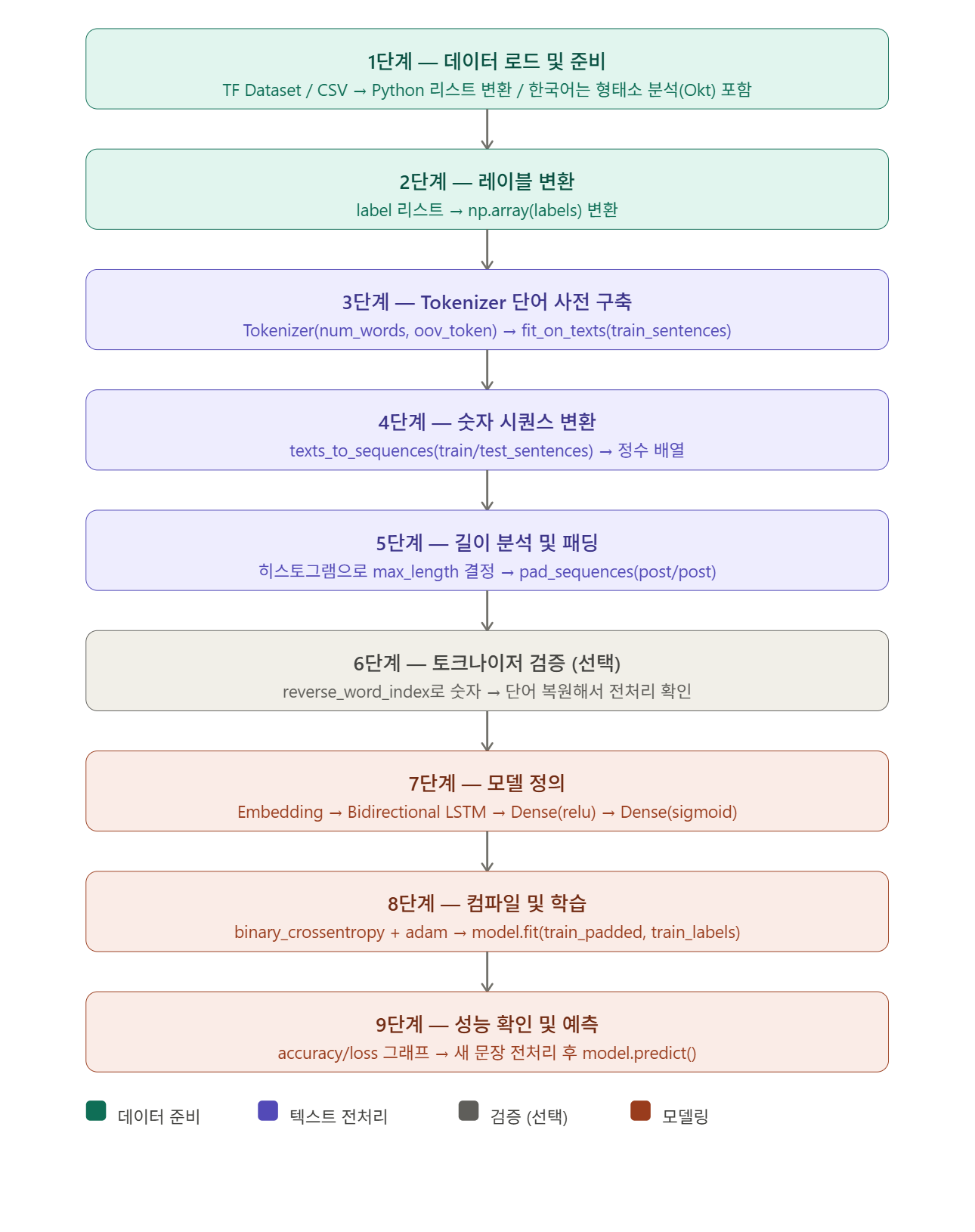
감성 분석 단계
2. Embedding Layer 시각화
🧭 학습된 임베딩을 눈으로 보려면?
Embedding Layer는 단어를 고차원 벡터로 표현합니다.
이 벡터들을 3D 공간에 시각화하면 의미적으로 유사한 단어들이 가까이 모여있는 것을 확인할 수 있습니다.
고차원 벡터 (예: 16차원)
"환불" → [0.12, -0.34, 0.87, ...] ─┐
"반품" → [0.11, -0.31, 0.85, ...] ─┤ 서로 가까이 위치
"배송" → [0.09, -0.29, 0.81, ...] ─┘
"재미" → [0.72, 0.61, -0.23, ...] ─┐
"흥미" → [0.70, 0.58, -0.21, ...] ─┘ 서로 가까이 위치
"환불" ↔ "재미" : 멀리 위치 (의미 다름)시각화 도구: TensorFlow Embedding Projector
사용 방법:
1. 학습 완료 후 임베딩 벡터를 파일로 저장
- vecs.tsv : 단어별 벡터값 (숫자)
- meta.tsv : 단어 목록 (레이블)
2. projector.tensorflow.org 접속
3. "Load" 클릭 → 두 파일 업로드
4. 3D 공간에서 단어 클러스터 확인임베딩 저장 코드 예시
import numpy as np
import io
# 학습된 모델에서 임베딩 가중치 추출
embedding_layer = model.layers[0]
weights = embedding_layer.get_weights()[0] # shape: (vocab_size, embedding_dim)
# 벡터 파일 & 메타데이터 파일 저장
out_vecs = io.open('vecs.tsv', 'w', encoding='utf-8')
out_meta = io.open('meta.tsv', 'w', encoding='utf-8')
for word, idx in tokenizer.word_index.items():
vec = weights[idx]
out_vecs.write('\t'.join([str(x) for x in vec]) + '\n')
out_meta.write(word + '\n')
out_vecs.close()
out_meta.close()💡 무엇을 확인할 수 있나?
- 긍정 감성 단어들 (최고, 만족, 추천)이 한 클러스터에 모임
- 부정 감성 단어들 (별로, 실망, 환불)이 반대쪽 클러스터에 모임
- 임베딩이 제대로 학습됐는지 직관적으로 검증 가능
3. Tokenization & Tokenizer 완전 정리
🔪 Tokenization이란?
텍스트를 단어(word) 또는 서브워드(sub-word) 단위로 분리하는 과정입니다.
입력: "스마트폰배터리가빨리닳아서교체했어요"
공백 기반: ["스마트폰배터리가빨리닳아서교체했어요"] → 통째로 1개 (😱 실패)
형태소 기반: ["스마트폰", "배터리", "가", "빨리", "닳아서", "교체", "했어요"] → 의미 단위 분리
서브워드 기반: ["스마트", "폰", "배터리", "가", "빨리", "닳", "아서", "교체", "했어요"]⚖️ Tokenizer 종류 비교
| 구분 | 사전 기반 (Dictionary) | 서브워드 기반 (Sub-word) |
|---|---|---|
| 대표 도구 | KoNLPy (Komoran, Mecab, Okt) | BPE, WordPiece, SentencePiece |
| 토큰 단위 | 알려진 단어 / 형태소 | 글자 단위로 시작해 점진적 확장 |
| 사전 크기 | 무제한 (언어별 사전) | 고정 크기 (예: 8,000 / 32,000) |
| 언어 지식 | 필요 (언어학적 규칙) | 불필요 (통계 기반 자동 학습) |
| 미등록 단어 | <UNK> 처리 | 서브워드로 분해 → UNK 최소화 |
| 다국어 적용 | 언어별 별도 개발 필요 | 하나의 모델로 다국어 처리 가능 |
미등록 단어 처리 비교 예시
신조어 "갓생" 처리 시:
사전 기반: "갓생" → <UNK> (사전에 없으므로 처리 불가)
서브워드 기반: "갓생" → "갓" + "생" (의미 있는 조각으로 분해)📏 Rule-based Tokenization의 한계
가장 단순한 방법은 공백 또는 구두점으로 단어를 분리하는 것입니다.
하지만 이 방식은 심각한 문제가 있습니다.
문제: 사전(Vocabulary) 크기 폭발
영어 예:
"run" / "running" / "runs" / "ran" → 4개의 다른 단어로 처리
"Transformer" / "Transformer's" / "Transformers" → 또 다른 3개
결과:
Transformer XL 모델: 267,735개 단어 사전 생성
→ 임베딩 행렬 크기 = 267,735 × embedding_dim (엄청난 메모리 낭비)
→ 학습 속도 급감, 메모리 부족 위험서브워드 방식으로 해결
원칙 1: 자주 쓰이는 단어 → 분리하지 않고 하나의 토큰으로 유지
원칙 2: 드물게 쓰이는 단어 → 의미 있는 서브워드로 분해
예시:
"먹다" (매우 빈번) → ["먹다"] (분리 안 함)
"먹히다" (덜 빈번) → ["먹", "히다"] (분해)
"먹어치우다" (드묾) → ["먹", "어", "치우다"] (더 잘게 분해)💡 교착어(한국어, 터키어, 일본어 등)는 조사·어미가 단어에 붙어 변형이 많아 서브워드 방식이 특히 효과적입니다.
🔤 WPM (Word Piece Model)
개요
- 2015년 구글이 처음 제안, 2016년 구글 번역기에 도입
- 하나의 단어를 통계 기반으로 의미 있는 서브워드 단위로 분리
- BERT에서 사용 (104개 언어 버전: vocabulary size 110,000)
핵심 아이디어
기존 띄어쓰기 → 언더바(_)로 치환 (나중에 원문 복원을 위해)
원문: "반도체 수출액이 역대 최고치를 갱신했다"
변환: "_반도체 _수출액이 _역대 _최고치를 _갱신했다"
분리 후: ["_반도체", "_수출", "액이", "_역대", "_최고", "치를", "_갱신", "했다"]BPE (Byte Pair Encoding) 알고리즘 작동 방식
Step 1: 모든 단어를 글자 단위로 분리
"갱신" → ["갱", "신"]
"경신" → ["경", "신"]
"기록" → ["기", "록"]
Step 2: 가장 자주 등장하는 글자 쌍을 하나로 병합
("경", "신") 쌍이 100번 등장 → "경신"으로 병합
("기", "록") 쌍이 80번 등장 → "기록"으로 병합
Step 3: 목표 vocabulary 크기에 도달할 때까지 반복🌐 Google SentencePiece
WPM과의 차이점
WPM: 사전 토큰화(공백 분리) → 그 후 서브워드 분리
→ 공백이 없는 언어(중국어 등)에 적용 어려움
SentencePiece: 원문 그대로 입력 → 공백도 특수 기호로 처리
→ 언어에 완전 독립적서브워드 표시 방식
입력: "embedding"
SentencePiece 결과:
["▁em", "bed", "ding"]
↑
▁(언더바): 단어의 시작을 의미
나머지 토큰은 ▁없이 시작 = 단어 중간 부분SentencePiece 실습 예시 (NSMC 데이터 기반)
import sentencepiece as spm
# 토크나이저 학습
spm.SentencePieceTrainer.Train(
input='nsmc_train.txt',
model_prefix='nsmc_spm',
vocab_size=5000
)
# 토크나이저 로드 및 사용
sp = spm.SentencePieceProcessor()
sp.Load('nsmc_spm.model')
# 새로운 예시 (강의 예시와 다름)
sentence = "스크린이 너무 작아서 자막이 잘 안보였어요"
tokens = sp.EncodeAsPieces(sentence)
# → ['▁스크린', '이', '▁너무', '▁작아서', '▁자막', '이', '▁잘', '▁안', '보였어요']
ids = sp.EncodeAsIds(sentence)
# → [143, 8, 52, 4321, 892, 8, 76, 131, 2287]📊 Tokenizer 선택 가이드
내 태스크에 맞는 Tokenizer는?
한국어 + 언어 전문 지식 있음 + 정확도 최우선
→ KoNLPy (Mecab 추천)
다국어 지원 필요 OR 신조어·오타 많음 OR 빠른 실험
→ SentencePiece / BPE
BERT, GPT 등 사전학습 모델 활용
→ 해당 모델의 전용 Tokenizer 사용 (WordPiece / BPE)4. 개체명 인식 (NER, Named Entity Recognition)
🏷️ 개체명 인식이란?
문장 속에서 이름을 가진 고유 개체를 찾아 유형을 분류하는 태스크입니다.
입력 문장:
"카카오 창업자 김범수가 서울 여의도 본사에서 기자회견을 열었다."
NER 결과:
카카오 → 조직명 (ORG)
김범수 → 인물명 (PER)
서울 → 지명 (LOC)
여의도 → 지명 (LOC)
기자회견 → 기타 (해당 없음)인식 대상 개체 유형
| 태그 | 의미 | 예시 |
|---|---|---|
| PER | 인물 (Person) | 이재용, 오바마, BTS |
| ORG | 조직·단체 (Organization) | 삼성전자, 유엔, 카카오 |
| LOC | 장소·지명 (Location) | 서울, 한강, 제주도 |
| MISC | 기타 고유명사 (Miscellaneous) | 코로나19, 월드컵, 태극기 |
🎯 NER이 왜 필요한가?
① 검색엔진 효율화
사용자 검색: "애플 CEO 신제품 발표"
→ NER이 "애플" = 회사명, "CEO" = 직함 으로 인식
→ 단순 키워드 검색보다 정확한 결과 제공② 추천 엔진
사용자 A 검색 이력: {테슬라(ORG), 머스크(PER), 전기차(제품)}
사용자 B 검색 이력: {테슬라(ORG), 머스크(PER), 스페이스X(ORG)}
→ NER 기반 유사 사용자 그룹핑 → 맞춤 콘텐츠 추천③ 자동 트레이딩 (Automatic Trading)
뉴스 수집: "현대차, 美 조지아 공장 가동 시작… 생산능력 30만대 확보"
NER 처리:
현대차 → ORG (회사)
조지아 → LOC (지역)
감성 분석: 긍정 (Positive)
자동 매매:
긍정 뉴스 + 회사명 인식 → 현대차 주식 자동 매수 신호④ 고객 서비스 (Customer Service)
고객 문의: "저 어제 강남점에서 에어팟 프로 2세대 샀는데 이어팁이 없어요"
NER:
강남점 → LOC (지점)
에어팟 프로 → 제품명
2세대 → 버전
→ 담당 부서·담당자 자동 연결 (강남점 AS팀)🏗️ RNN으로 NER 구현하기
NER은 각 단어마다 태그를 출력해야 합니다.
따라서 Many-to-Many 구조 (= return_sequences=True) 를 사용합니다.
입력: ["삼성전자", "이재용", "회장이", "서울에서", "기자회견을", "열었다"]
↓ ↓ ↓ ↓ ↓ ↓
[LSTM] → [LSTM] → [LSTM] → [LSTM] → [LSTM] → [LSTM]
↓ ↓ ↓ ↓ ↓ ↓
출력: B-ORG B-PER O B-LOC O OBidirectional LSTM을 쓰는 이유
단방향 LSTM (앞→뒤):
"이재용"을 읽을 때 뒤에 "회장"이 나온다는 사실을 모름
양방향 LSTM (앞→뒤 + 뒤→앞):
"이재용"을 읽을 때 뒤의 "회장"까지 고려 → PER 태그 확신도 증가
NER에서는 Bidirectional LSTM이 압도적으로 성능이 좋음import tensorflow as tf
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim),
tf.keras.layers.Bidirectional(
tf.keras.layers.LSTM(64, return_sequences=True) # 모든 step 출력
),
tf.keras.layers.Dense(num_tags, activation='softmax') # 각 단어별 태그 확률
])🏷️ BIO 태깅 방식
개체명의 시작, 내부, 외부를 구분하는 표준 표기법입니다.
| 태그 | 의미 | 설명 |
|---|---|---|
| B-XXX | Begin | 개체명이 시작되는 첫 번째 토큰 |
| I-XXX | Inside | 개체명이 계속되는 내부 토큰 |
| O | Outside | 개체명이 아닌 일반 단어 |
BIO 태깅 예시
문장: "현대자동차 정의선 회장이 경기도 화성 공장을 방문했다"
단어 | BIO 태그
------------|----------
현대자동차 | B-ORG ← 조직명 시작
정의선 | B-PER ← 인물명 시작
회장이 | O ← 일반 단어
경기도 | B-LOC ← 지명 시작
화성 | I-LOC ← 지명 계속 (경기도 화성 = 하나의 지명)
공장을 | O ← 일반 단어
방문했다 | O ← 일반 단어B-와 I-를 구분하는 이유
"삼성 서울 병원"이라는 하나의 기관명이 있을 때:
B/I 없이: 삼성(ORG) 서울(ORG) 병원(ORG) → 3개 별개 개체로 오해
B/I 있이: 삼성(B-ORG) 서울(I-ORG) 병원(I-ORG) → 하나의 개체임을 명확히 표현📋 CoNLL-2003 데이터셋 형식
NER 학습에 가장 널리 쓰이는 영어 벤치마크 데이터셋입니다.
각 토큰에 [단어 / 품사 태그 / 청크 태그 / 개체명 태그] 4가지 정보가 부여됩니다.
실제 데이터 형식 예시
단어 품사 청크 개체명
-------------|-------|-------|-------
Apple NNP B-NP B-ORG
Inc. NNP I-NP I-ORG
announced VBD B-VP O
its PRP$ B-NP O
new JJ I-NP O
iPhone NNP I-NP B-MISC
in IN B-PP O
San NNP B-NP B-LOC
Francisco NNP I-NP I-LOC품사 태그 (주요 항목)
| 태그 | 품사 | 예시 |
|---|---|---|
| NNP | 고유명사 단수 | Apple, Korea |
| VBD | 과거형 동사 | announced, went |
| JJ | 형용사 | new, big |
| IN | 전치사 | in, at, on |
| PRP | 인칭대명사 | he, she, its |
청크 태그 (Chunk Tag)
| 태그 | 의미 | 예시 |
|---|---|---|
| B-NP | 명사구 시작 | "Apple Inc." → B-NP I-NP |
| B-VP | 동사구 시작 | "announced" → B-VP |
| B-PP | 전치사구 시작 | "in San Francisco" → B-PP |
🔬 실습: Bidirectional LSTM NER 모델
import tensorflow as tf
# 모델 구성
model = tf.keras.Sequential([
# 1. 임베딩 레이어: 단어 → 벡터
tf.keras.layers.Embedding(
input_dim=vocab_size,
output_dim=64,
mask_zero=True # 패딩 무시
),
# 2. 양방향 LSTM: 앞뒤 문맥 모두 학습
tf.keras.layers.Bidirectional(
tf.keras.layers.LSTM(
128,
return_sequences=True # 모든 단어에 대한 출력 필요
)
),
# 3. Dropout: 과적합 방지
tf.keras.layers.Dropout(0.3),
# 4. 출력층: 각 단어의 개체명 태그 확률
tf.keras.layers.Dense(num_tags, activation='softmax')
])
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)CoNLL-2003 태그셋 (실습용)
O : 개체명 아님
B-PER : 인물명 시작 (예: 이재용)
I-PER : 인물명 계속 (예: 이재용 → I-PER 없음, 한 토큰)
B-ORG : 조직명 시작 (예: 삼성전자)
I-ORG : 조직명 계속 (예: Samsung Electronics → Samsung(B) Electronics(I))
B-LOC : 지명 시작 (예: 서울)
I-LOC : 지명 계속 (예: San Francisco → San(B) Francisco(I))
B-MISC : 기타 개체 시작 (예: 코리아컵)
I-MISC : 기타 개체 계속5. 전체 흐름 요약
🗺️ 감성분석 vs 개체명 인식 비교
| 항목 | 감성분석 (SA) | 개체명 인식 (NER) |
|---|---|---|
| RNN 구조 | Many-to-One | Many-to-Many |
| return_sequences | False | True |
| 출력 | 문장당 1개 레이블 | 단어마다 1개 태그 |
| LSTM 방향 | 단방향 가능 | Bidirectional 권장 |
| 레이블 예시 | positive / negative | B-PER, I-ORG, O ... |
| 대표 데이터셋 | IMDB, NSMC | CoNLL-2003, KLUE-NER |
🔁 NLP 파이프라인 전체 그림
원문 텍스트 입력
↓
[1] 전처리 (Preprocessing)
- 소문자 변환, 특수문자 제거
- 한국어: 형태소 분석기 적용
↓
[2] 토크나이징 (Tokenization)
- 사전 기반: KoNLPy (정확도 우선)
- 서브워드: SentencePiece / BPE (범용성 우선)
↓
[3] 수치화 (Vectorization)
- 단어 → 정수 인덱스 변환
- Padding으로 길이 통일
↓
[4] 임베딩 (Embedding)
- 정수 인덱스 → 밀집 벡터 (Embedding Layer)
↓
[5] 시퀀스 모델 (RNN / LSTM / GRU / Bidirectional)
- 감성분석: Many-to-One (return_sequences=False)
- NER/품사태깅: Many-to-Many (return_sequences=True)
↓
[6] 출력 (Output)
- 감성분석: 긍정/부정 확률
- NER: 각 단어별 개체명 태그🎯 마무리 퀴즈
Q1. 감성분석에서 return_sequences=False를 쓰는 이유는?
정답: 감성분석은 문장 전체를 읽고 하나의 결론(긍정/부정)을 내리는 Many-to-One 구조이기 때문입니다. 마지막 hidden state 하나만 있으면 충분합니다.
Q2. 한국어 데이터를 공백으로만 토큰화하면 안 되는 이유는?
정답: 한국어는 띄어쓰기가 잘 지켜지지 않고, 조사가 단어에 바로 붙는 교착어이기 때문입니다. "먹었다"와 "먹어요"를 같은 어간으로 처리하려면 형태소 분석기가 필요합니다.
Q3. BPE 서브워드 방식이 Rule-based 방식보다 좋은 이유는?
정답: Rule-based는 신조어·오타를 모두
<UNK>로 처리하지만, BPE는 알려진 서브워드 조각으로 분해하여<UNK>없이 처리합니다. 또한 vocabulary 크기를 고정하여 메모리 효율이 높습니다.
Q4. NER에서 B 태그와 I 태그를 구분하는 이유는?
정답: 연속된 여러 토큰이 하나의 개체를 이룰 때, B(시작)와 I(내부)를 구분하지 않으면 각각이 별개의 개체인지 하나의 개체인지 알 수 없습니다. 예: "삼성(B-ORG) 서울(I-ORG) 병원(I-ORG)" = 하나의 기관명
