NLP
1.자연어 처리 기초부터 Word2Vec까지

💡 한 줄 정의: NLP(Natural Language Processing)는 컴퓨터가 사람의 언어를 이해하고 처리하게 만드는 기술입니다.자연어 이해 (NLU, Natural Language Understanding)감성분석 — "이 영화 진짜 재미없었어" → 🔴
2.Deep Learnig Sequence Model
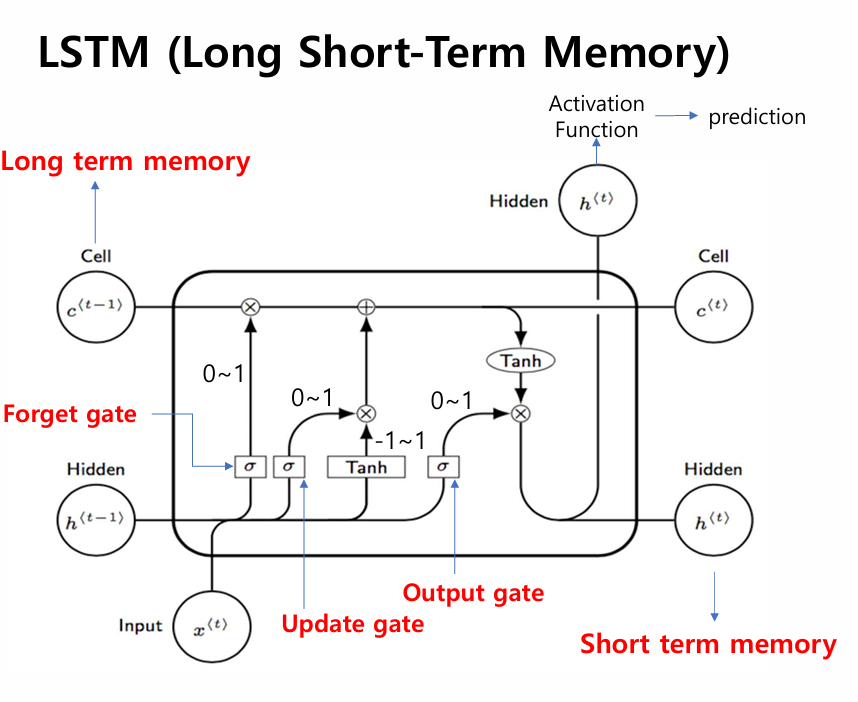
💡 Sequence 데이터 = 순서가 있는 데이터. 앞뒤 맥락이 중요하며, 순서를 바꾸면 의미가 달라집니다.일반적인 신경망(Feedforward NN)은 각 입력을 독립적으로 처리합니다. 하지만 현실의 많은 데이터는 앞에 무엇이 왔느냐가 중요합니다.예시 — 왜 순서가
3.Deep Learnig Sequence Model II
텍스트를 읽고 감정·의견의 방향을 자동으로 판단하는 NLP 태스크입니다.💡 감성분석은 이진 분류(Binary Classification) 가 기본입니다.레이블: positive(1) vs negative(0)감성분석은 문장 전체를 읽고 하나의 결론을 내리는 태스크입니
4.NSMC 감성 분류 — Bidirectional LSTM 단계별 실험
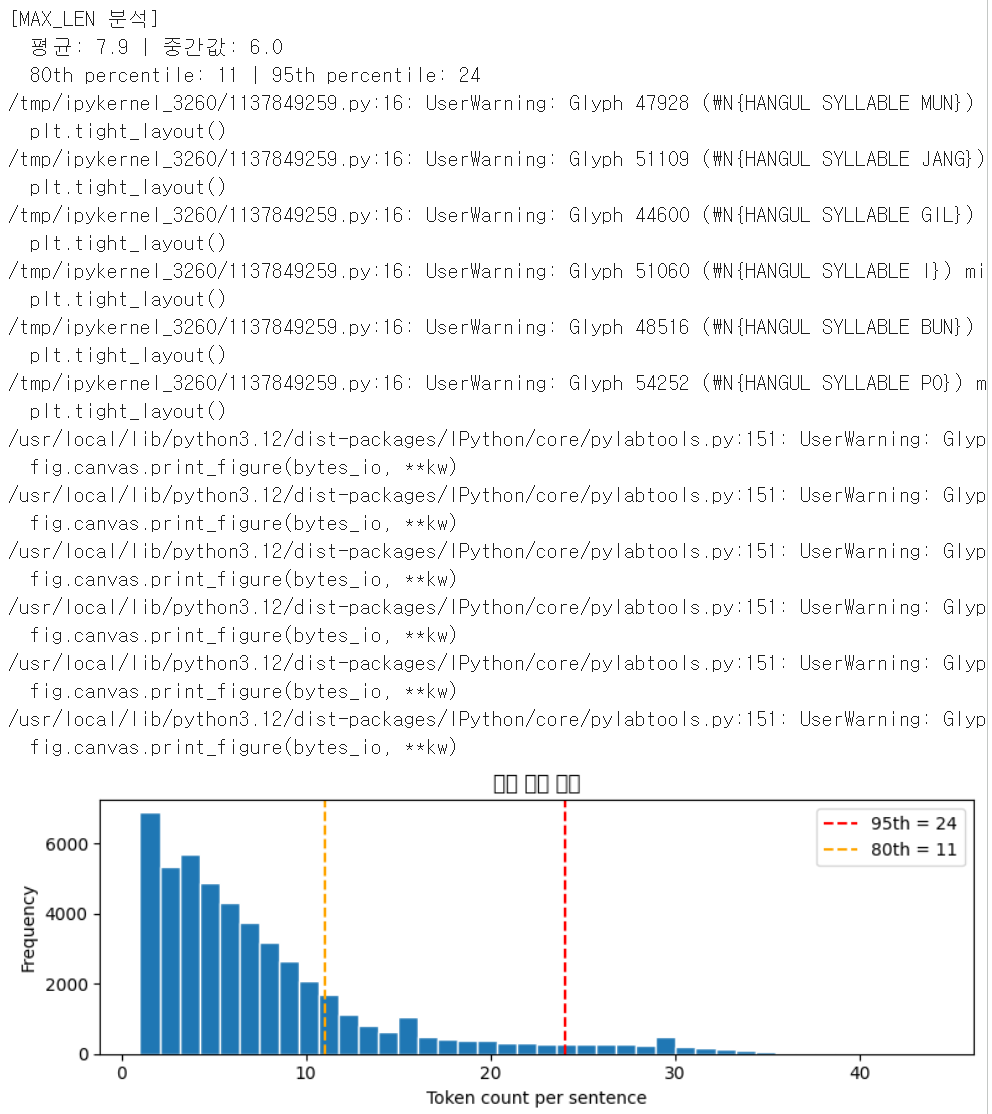
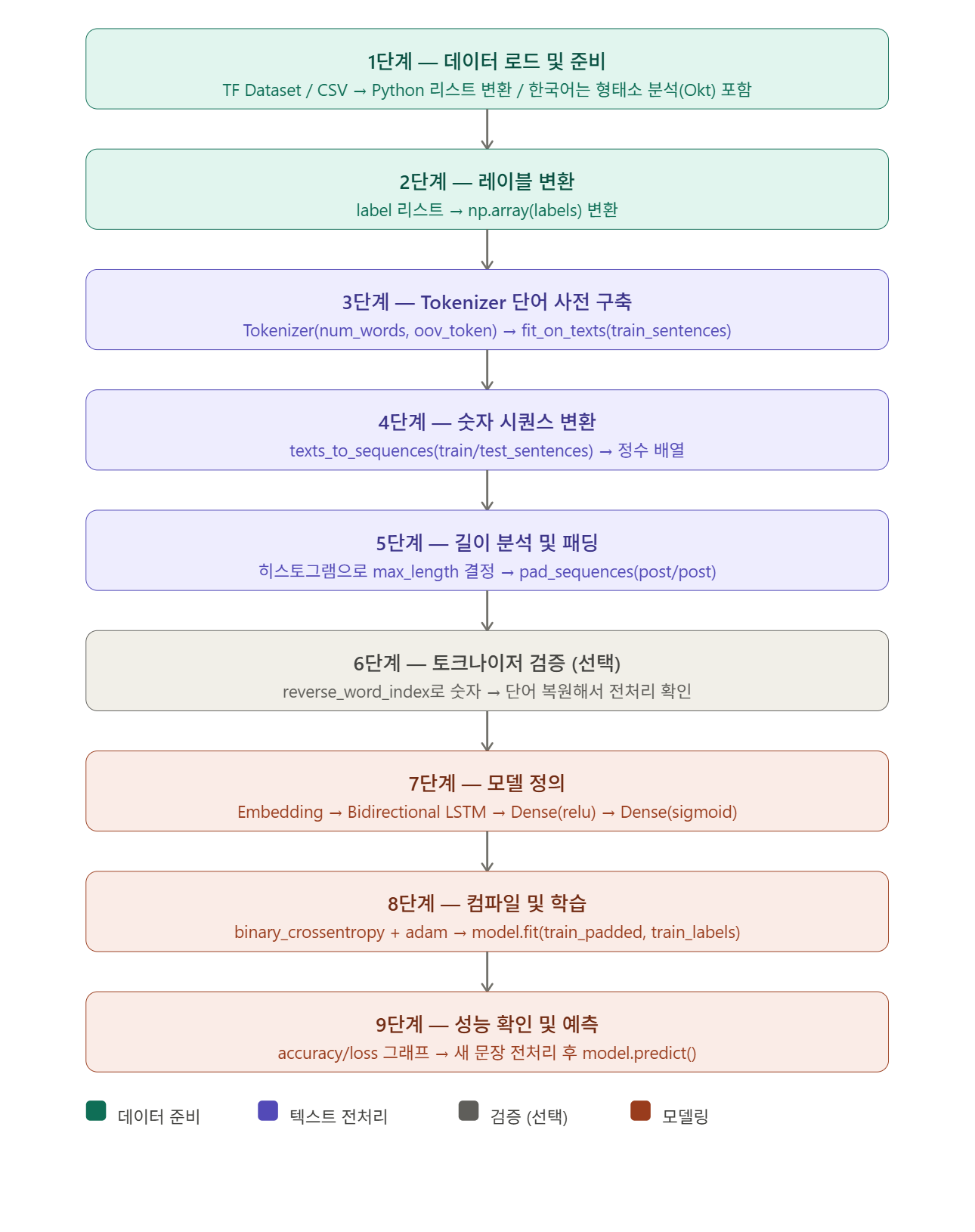
NSMC 데이터셋으로 감성 분류 모델을 구현하고, Bidirectional LSTM + 전처리 최적화로 Test Accuracy 85% 이상을 달성구글 드라이브에서 직접 파일을 로드, train 50,000개 / test 5,000개로 샘플링하고, dropna()로 n
5.딥러닝 Language Model — Seq2Seq · 기계번역 · 챗봇
Language Model이의 핵심 임무는 단 하나입니다.“지금까지 나온 단어들을 보고, 다음에 올 가장 자연스러운 단어를 예측한다”스마트폰 키보드의 자동완성, ChatGPT의 문장 생성, 번역기가 모두 이 원리로 작동합니다.Language Model은 단어를 한 번에
6.Seq2Seq로 한국어 감성 챗봇 만들기 — Greedy vs Beam Search 비교 실험
과제 Chatbot_data_for_Korean (11,876 문답 쌍)을 사용하여 Seq2Seq Encoder-Decoder 기반 한국어 감성 챗봇을 구현하고 Greedy vs Beam Search Decoding Strategy를 비교 실험한다정량 평가: BL
7.Transformers
💡 NLP Mountain: Transformer(2017)를 이해하면 이후 BERT, GPT, ChatGPT까지 모두 이해할 수 있습니다. Transformer가 현대 NLP의 출발점입니다.Transformer 이전에는 LSTM이 NLP의 표준이었습니다. 하지만 세
8.자연어 전이학습 (NLP Transfer Learning)
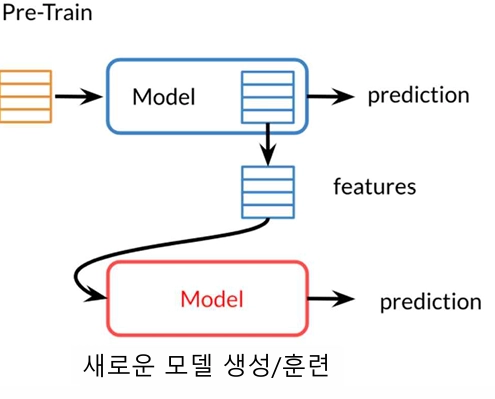
NLP 전이학습은 범용 언어 지식을 먼저 학습(Pre-training) 해두고, 내가 원하는 특정 task에 짧게 추가 학습(Fine-tuning) 하는 방식입니다.Pre-trained 모델의 출력(feature)을 새로운 모델의 입력으로 사용하는 방법입니다.image
9.ChatGPT와 멀티모달 AI
GPT-3는 인터넷에 있는 방대한 텍스트를 읽고, 다음에 올 단어를 예측하는 방식으로 학습한 초거대 언어 모델입니다.GPT-3를 이전 모델과 구분짓는 가장 큰 특징은 규모(Scale) 입니다.파라미터를 GPT-2의 15억 개에서 GPT-3의 1,750억 개로 무려 10