
Estimating the Policy Gradient
We have to get the stocastic probability of gradient
Consider stocastic probability as non-biased estimates
Because Sum of states is impractical, Get rid of it
그래서 update rule은 다음과 같다.
즉 주어진 state와 action에 대한 stocastic probablity gradient를 계산하는 방법이다
- Gradient of the policy:
- 이미 policy와 parameterization을 알고 있기 때문에 gradient를 쉽게 계산할 수 있다.
- Estimate of the differential values:
- action value는 다양한 방식으로 추정할 수 있는데, 예로 differential action values를 학습하는 TD 알고리즘을 사용해볼 수 있다.
- log를 사용하는 이유: 0~1 사이의 확률을 0~ 사이로 변환하기 위해. 이를 통해 아주 큰 확률을 크게 표현할 수 있게 된다. 더불어 log를 사용하면 log 간 곱셈이 덧셈으로 치환되기에 이러한 이유에서 log를 사용한다.
Actor-Critic Algorithm
Actor-Critic Algorithm은 TD 기반
- actor == parameterized policy
- change policy to exceed the critics expectation
- update the policy parameters
- use TDR from critic:
- change policy to exceed the critics expectation
- critic == value function
- (evaluating the actions selected by the actor)
- update its value function to evalute actions selected by the actor(policy)
- semi-gradient TD 기반:
Approximating the Action Value in the Policy Update
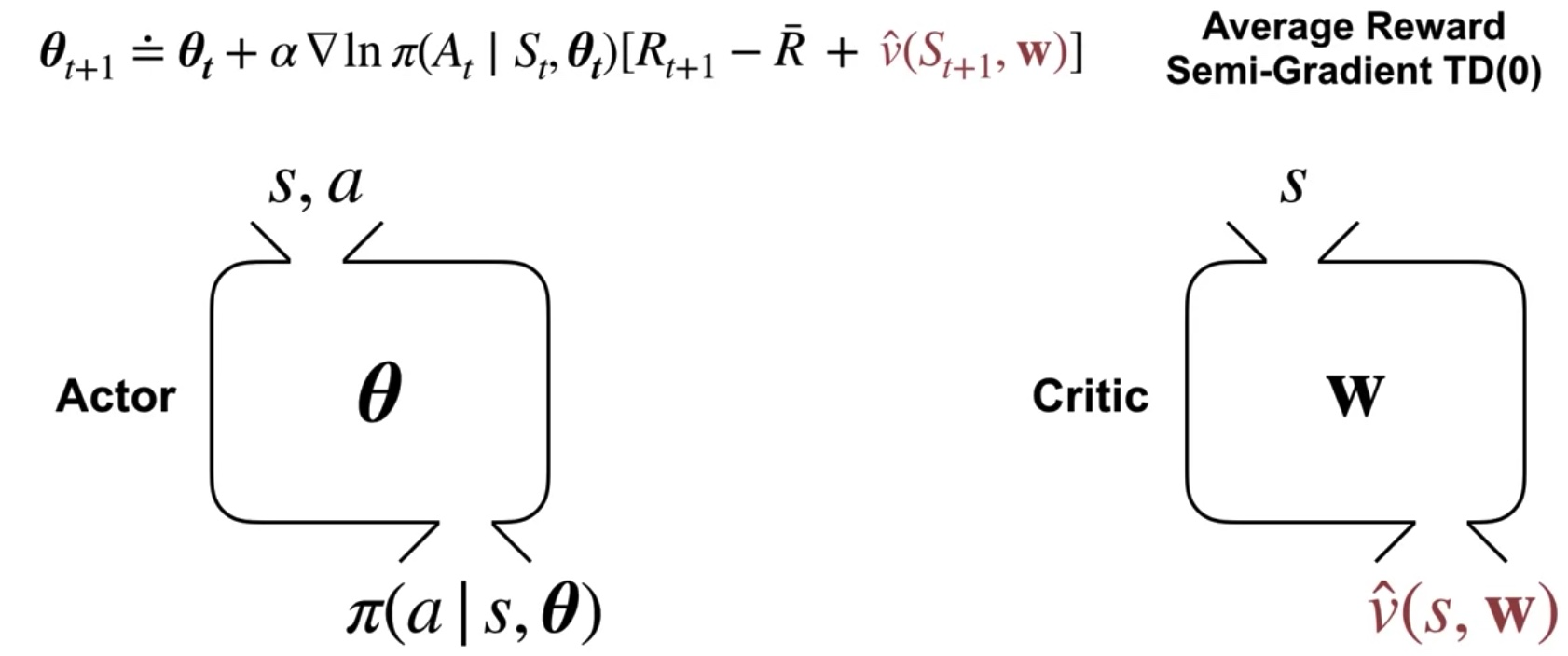
Subtracting the Current State's Value Estimate
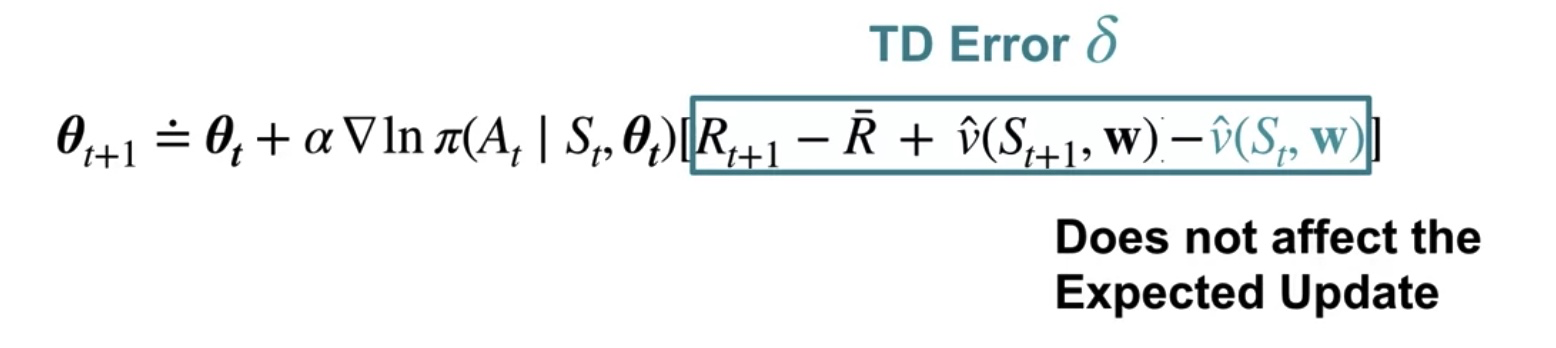

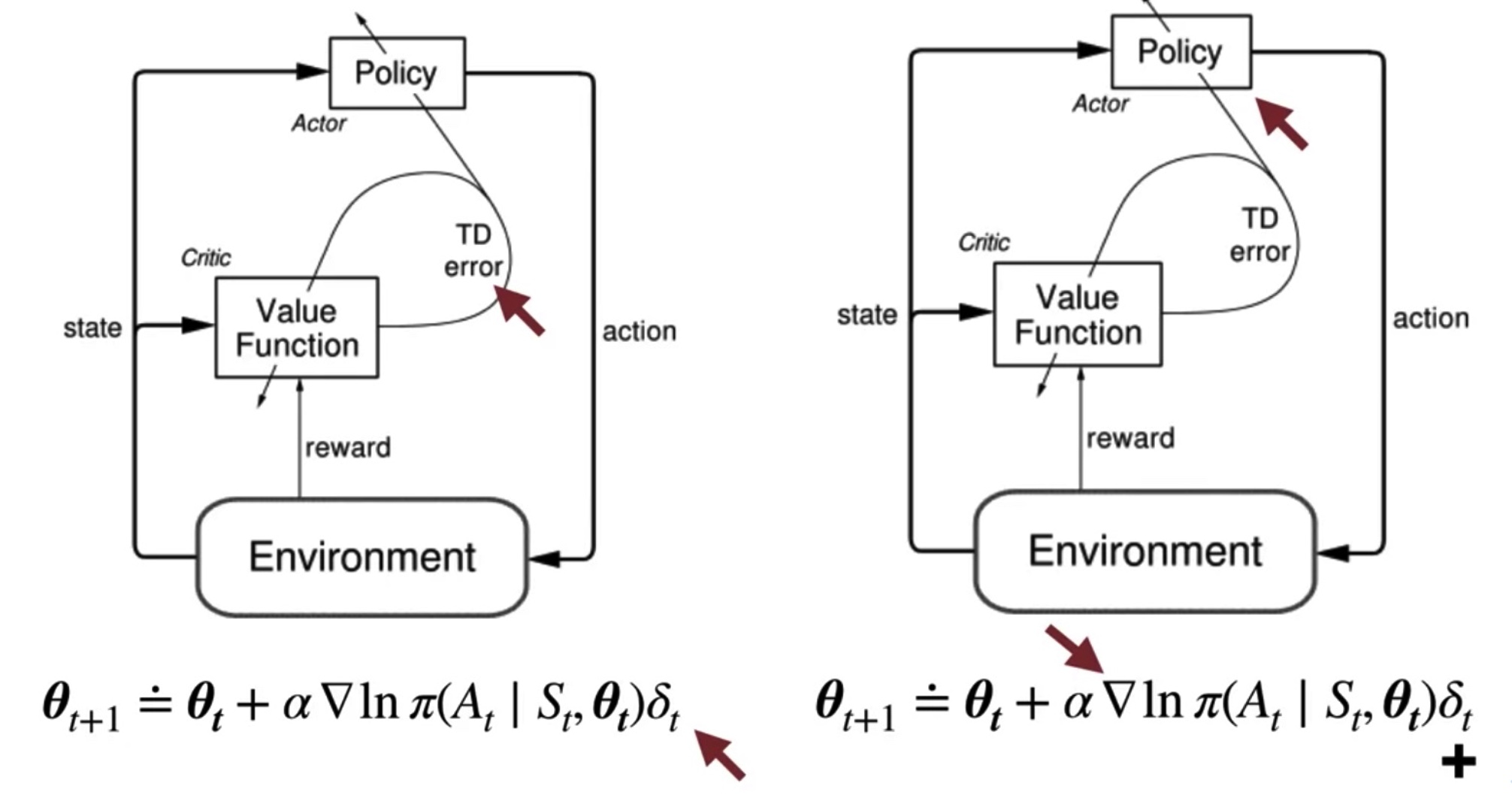
How the Actor and the Critic Interact
TD error is positive == selected action resulted in a higher value than expected
By updating, policy parameter changes to increase the probability of actions that were better than expected according to the critic
If the critic is disappointed and the TD error is negative,
then the probability of the action is decreased.
The actor and critic learn at the same time, constantly interacting

alive