Actor-Critic with Softmax Policies
가정: finiate set of action & continuous states
- softmax : Σj=1Keziezi
- guarantee the result of probability is positive and summed to one
- choice for policy parameterization(θ) for finite action: by Softmax
- π(a∣s,θ):=Σb∈Aeh(s,b,θ)eh(s,a,θ
critic은 현재 state에서 오직 하나의 feature vector만 필요하다
- ∇v^(s,w)=x(s) 이므로
- w←w+αwδ∇v^(S,w)
- 고로 critic's weight update는 alpha * TDR times the feature vector
action은 현재 state와 action에 종속적이기에 state-action feature vector가 필요하다
- h(s,a,θ):=θTxh(s,a)
- gradient: ∇lnπ(a∣s,θ)=xh(s,a)−Σhπ(b∣s,θ)xh(s,b)
- (state-action feature for the selected action) - (state-action feature multiplied by the policy summed over all actions)
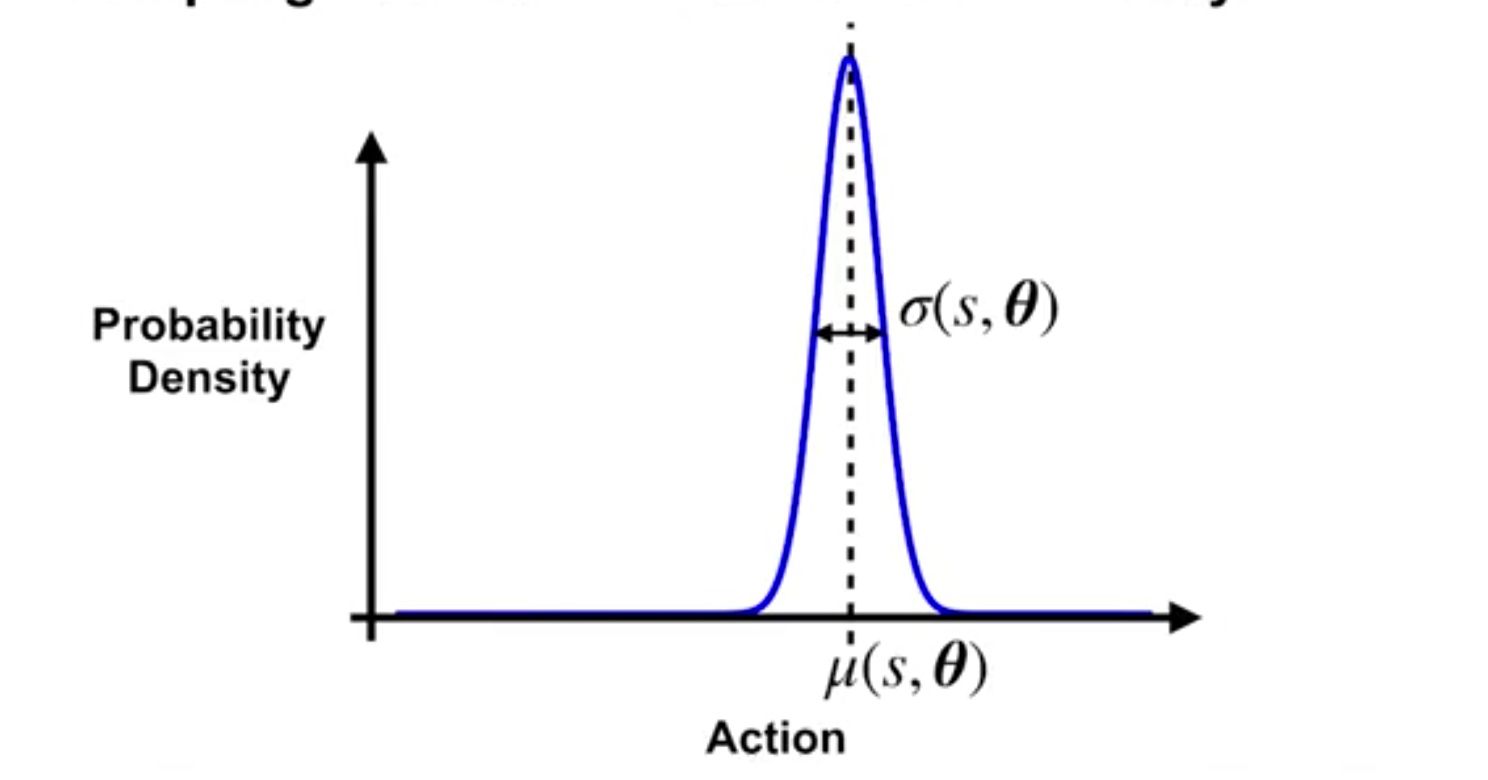
Gaussian Policies for Continuous Actions
Gaussian Distribution (=Normal Distribution)
- f(x)=σ2π1e−21(σx−μ)2
- μ == mean
- σ == variance of the distribution
Gaussian policy
- π(a∣s,θ):=σ(s,θ)2π1exp(−2σ(s,θ)2(a−μ(s,θ))2)
- μ(s,θ):=θμTx(s)
- σ:=exp(θσTx(s))
- θ:=[θμθσ]
action의 범위가 학습이 진행됨에 따라 점점 줄어들면서
각 상태 별 최적의 행동을 선택하게 한다
Gradient of the Log of the Gaussian Policy
- ∇lnπ(a∣s,θμ)=σ(s,θ)21(a−μ(s,θ))x(s)
- ∇lnπ(a∣s,θσ)=(σ(s,θ)2(a−μ(s,θ))2−1)x(s)

