off policy 방법에 대해 알아본다
Predicton 문제를 고려하여
target policy와 action policy가 고정된 상태로 가정한다
다시 말해, 또는 를 추정하지만
인 또다른 policy b를 따르는 에피소드가 있다고 가정한다
- target policy : (optimal policy)
- behavior policy :
coverage 보증의 가정
policy b로부터의 에피소드를 활용하여 policy 의 value를 추정하려면
policy 하에서 취해지는 모든 action이
최소한 조금씩이라도 policy b 하에서 취해질 필요가 있다
즉, policy 이 을 암시하는 것
coverage의 가정에 따르면
일 때 policy b는 무조건 확률론적이다
반면에 는 결정론적일 수 있다.
control에서 target policy는
전형적으로 action value function의 현재 추정값에 대해
결정론적인 탐욕적 정책이다
예를 들어, epsilon greedy policy같은 behavior policy가
확률론적 policy으로 남아있고 좀 더 탐험적인 반면에,
target policy는 결정론적인(deterministic) optimistic이 된다.
하지만 이 절에서는
정책 가 변하지 않고 고정된 상태에서
Prediction 문제를 다룬다
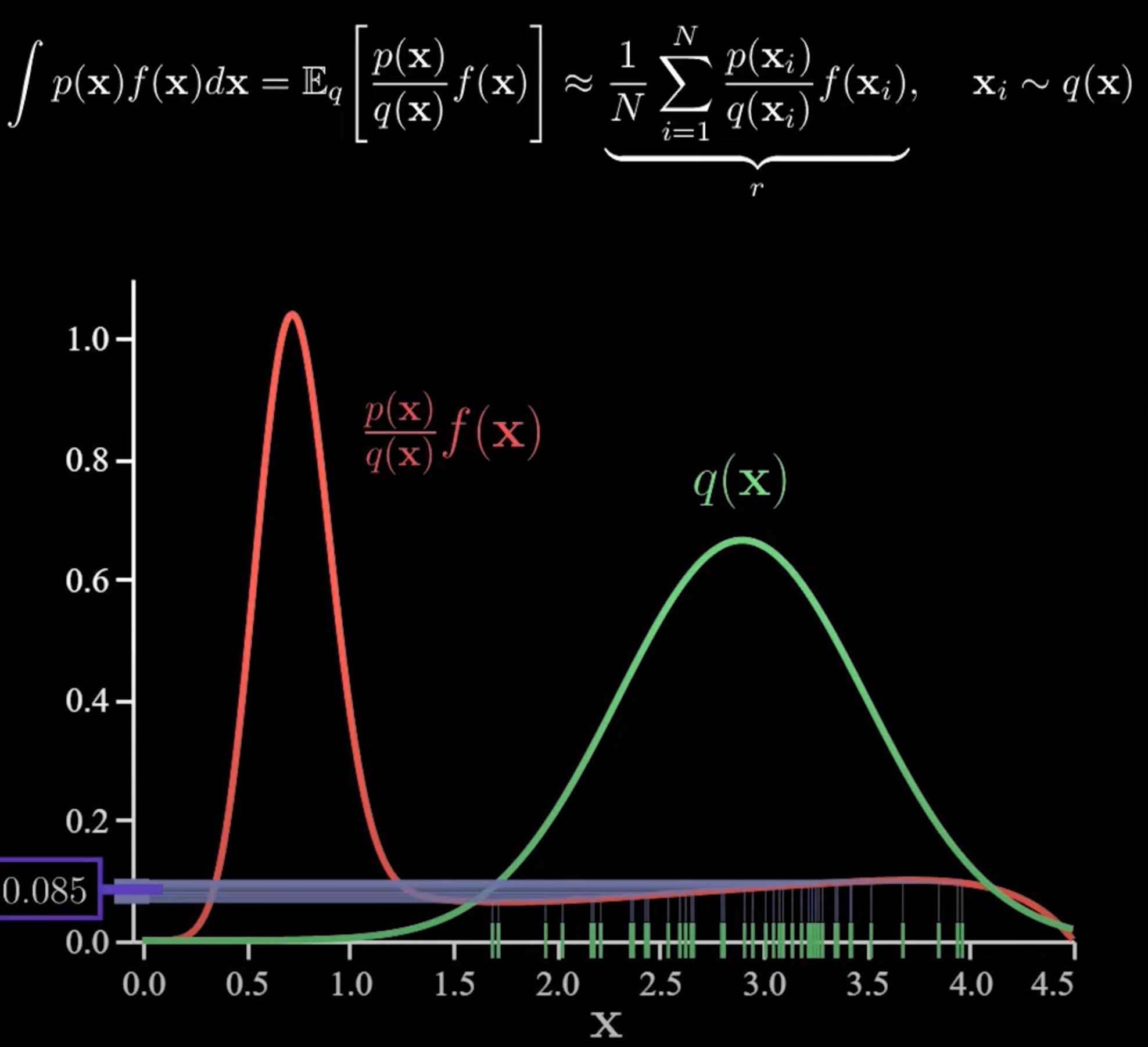
Importance Sampling
어떤 분포로부터 얻어진 표본이 주어질 때
그 표본을 이용하여 또 다른 분포에서 기댓값을 추정하는 방법
거의 모든 off-policy에서 사용되는 방법
importance-sampling ratio
- target policy와 behavior policy 하에서 발생하는
state-action의 궤적에 대한 상대적 확률
이 확률에 따라 가치에 가중치를 부여하는 방식으로
off-policy에 importance sampling을 적용할 수 있다