
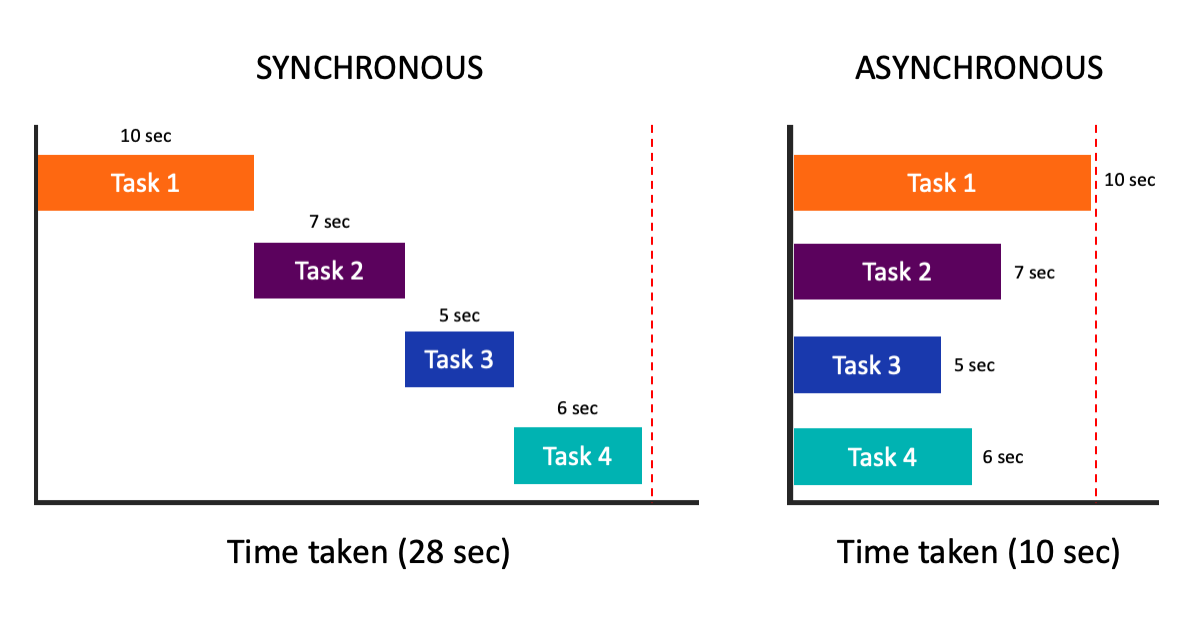
Sync와 Async
sync는 일이 순차적으로 진행되는 방식
async는 일이 동시에 진행되는 방식
DP 단점
DP가 MDP의 전체 state에 대한 계산 과정을 포함한다는 것
다시 말해,
state 집합에 대한 일괄 계산이 필요하다
state 집합의 크기가 매우 크다면
한 번의 일괄 계산도 할 수 없을 정도로
계산량이 많을 수 있다
(ex - 백게먼 게임은 개 state가 존재해서 1초에 백만 개의 state에 대해 value iteration update를 할 수 있다고 해도 한 번의 일괄 계산을 수행하는데 천 년 넘게 걸린다)
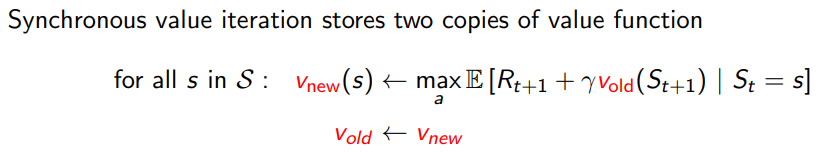
Asynchronous DP
Async DP 알고리즘는
state에 대해 체계적인 일괄 계산 sweep을 수행하지 않는
개별적인(in-place) 반복 DP 알고리즘이다
위의 sync value iteration은
<- 라는 에 대한 변화가 존재하지만
in-place value iteration은
오직 하나의 만 이용한다
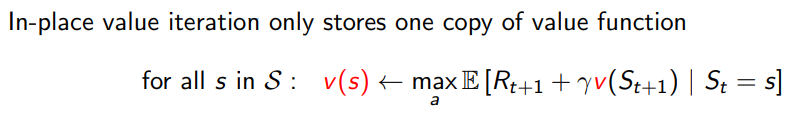
real-time
- 방식
- 오직 agent와 관련있는 state만 갱신한다
- ex) 만약 agent가 state dp 있다면
그 state value 또는 곧 가게 될 states에 대해서만 갱신한다
덕분에 계산할 양이 줄어서
실시간으로 상호작용하며 계산해낼 수도 있다
MDP 문제를 풀기 위해,
agent가 실제로 MDP를 경험하면서
동시에 반복적 DP 알고리즘을 실행할 수 있다
DP 알고리즘에서 update할 state를 결정하기 위해
agent의 경험을 할용할 수 있다
이와 동시에,
DP 알고리즘으로부터 얻는 최신 value와 policy에 대한 정보는
agent의 action을 결정하는데 참고할 수도 있다
sweepless
또 하나의 특징으로
update할 state를 선택하는데 있어
대단히 유연한 알고리즘이다
이를 sweepless DP라고도 부르며
순서를 무작위로 진행하거나
update 횟수를 state마다 조절하는 등
다양한 방식이 존재한다
- ex) Prioritised Sweeping
- state 선택에 벨만 에러의 절댓값을 사용
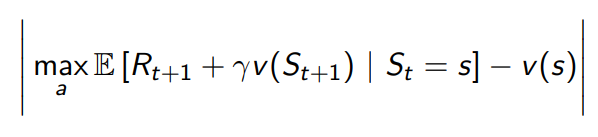
- 각 state에서 벨만 에러가 가장 높은 것을 backup 한다
- 각 backup 이후에 영향을 받은 state의 벪나 에러를 갱신한다
- (priority queue로 구현 가능)
- state 선택에 벨만 에러의 절댓값을 사용
수렴성
policy iteration에서
evalutation과 improvement가 교차하며 번갈아 수행된다
Async DP에서는 이 둘이 좀 더 촘촘하게 교차한다
어떤 경우에는 한 과정에서 오직 하나의 state만 갱신되고
바로 다른 과정으로 전환되기도 한다
두 과정이 어떻게든 계속 진행되어
모든 state가 갱신되기만 한다면
그 최종 결과는 일반적으로 모든 경우에 대해 동일하다
즉, 최종적으로 optimal value function과 optimal policy로 수렴한다
DP 정리
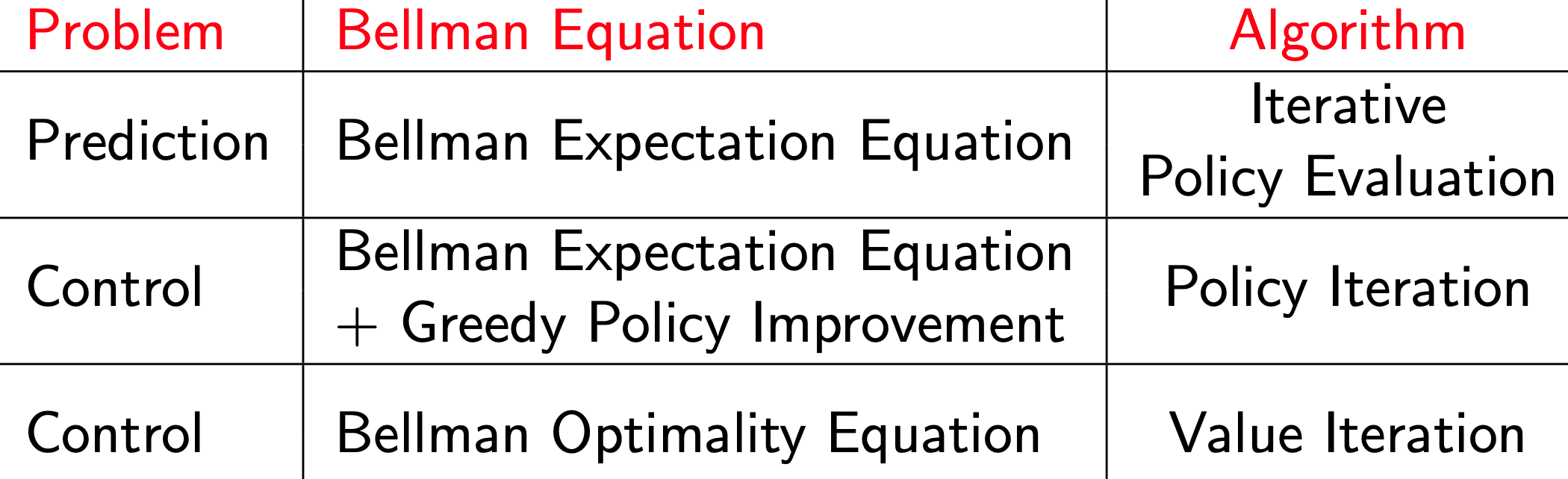
- m: action
- n: states
각 알고리즘의 시간복잡도는
그 알고리즘에서 사용한 value function이...
- state value function :
- action value function :
