
Policy iteration
value function 를 이용하여
policy 𝝅가 더 좋은 policy 𝝅'로 향상되고 나면
를 계산해서
𝝅'를 한 층 더 좋은 policy 𝝅''로 향상시킬 수 있다
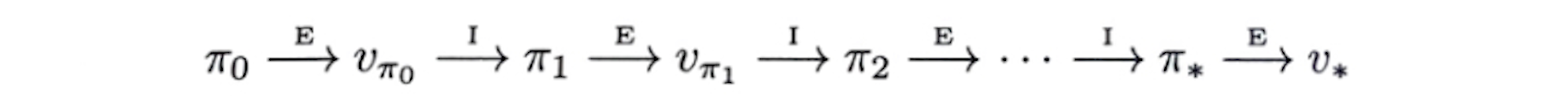
E는 policy evaluation을 나타내고 (preidction)
I는 policy improvement를 나타낸다 (control)
GPI : Generalized Policy Iteration
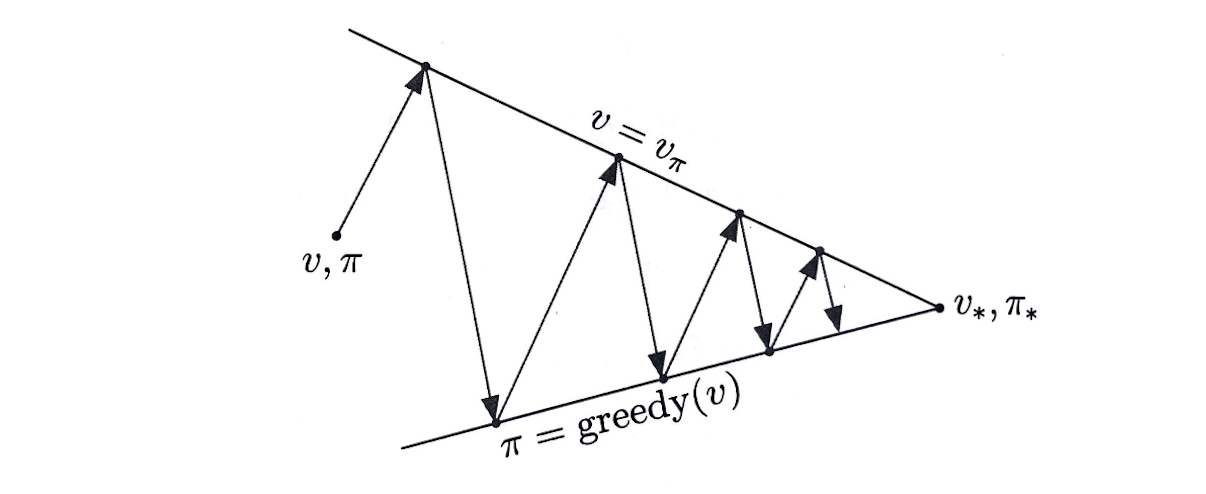
GPI에서 evaluation과 improvement 과정은
서로 경쟁하기도 하고 협력하기도 하는 것으로 비춰질 수 있다
하지만 장기적 측면에서 이 두 과정이 서로 상호작용하여
서로가 최적화된 양상을 띄게 된다
그것이 바로 optimal policy 및 optimal value function이다
Prediction과 Control
- Prediction: 주어진 policy를 기반으로 미래를 평가
- policy를 이용하여 value function을 갱신
- Control : 최고의 policy를 찾기 위해 미래를 최적화
- value function을 이용하여 policy를 갱신
Policy evaluation (prediction)
이렇게 policy 𝝅에 대해 state value function 를 계산하는 과정을
policy evaluation이라고 한다
이를 통해 현재의 policy가 좋은지/적합한지 평가한다

증명
을 만족하고
policy 𝝅를 따르는 모든 state가 더 이상 변하지 않는 마지막에 도달했음이 담보된다면
의 존재와 유일성 uniqueness가 보장된다
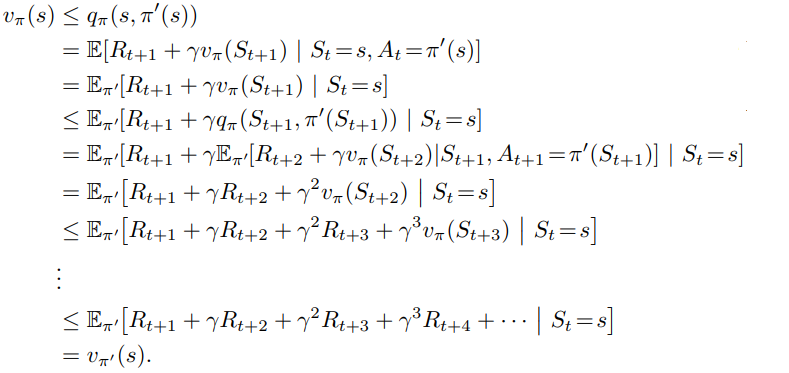
iterative policy evaluation
이렇게 를 계속, 무한하게 갱신하면
- -> -> -> ... -> -> ...
분명히 = 의 일정한 값을 갖는다
매번 로부터 을 연속적으로 구하기 위해
iterative policy evaluation은
모든 state s에게 동일한 작동 방식을 적용한다
이 때 state s의 이전 가치를 새로운 가치로 대체한다
이 새로운 가치는 s 이후에 나타내는 state들의
이전 가치와 즉각적인 보상의 기댓값을 이용하여 구한다
이러한 종류의 작동 방식을 기댓값 갱신 expected update라고 한다
이는 매번 모든 state에 대해서 일어난다
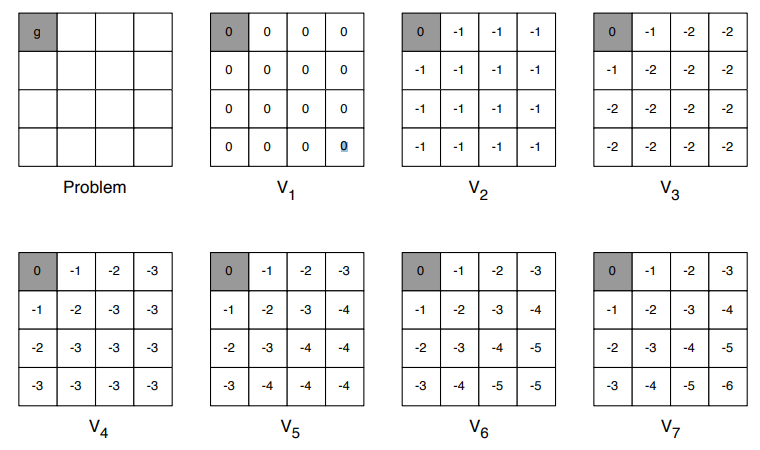
예시
-
환경에 대한 설명
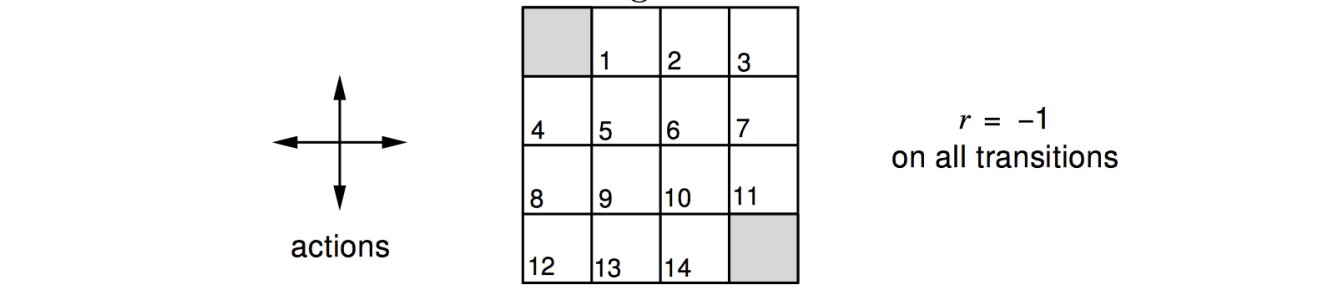
- 벽에 부딪히면 제자리로 돌아온다
- 목적지에 도착하기 전까지 모든 reward는 -1
- discount factor = 1
- agent는 uniform random policy를 따른다
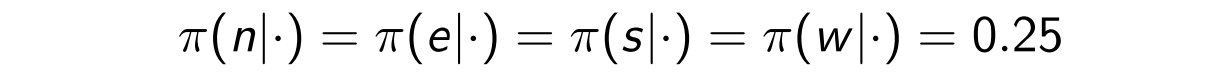
-
이 환경에 대한 policy evaluation 식은
아래 그림은 value function을 update하는
policy evalutation의 과정이다
마지막 k에서의 산출된 value function을 통해
policy를 구한다면 optimal policy를 얻을 수 있다

- k=0 :
- k=1 :
- 다만 시작점은 0이고 도착점도 0
- k=2 :
- 시작점과 도착점에 맞닿아 있는 칸의 경우, 가 -1.0이 아닌 0.0 이기에 새로 계산
Policy Improvement (control)
state s에서 현재 policy를 따르는 것이 얼마나 좋은지는
를 통해 알고 있지만,
policy 자체를 새롭게 바꾸는 것은 어떠한가?
더 좋은가, 더 나쁜가?
이 질문에 답하는 하나의 방법은
state s에서 action a를 선택하고
그 후에는 현재의 policy 𝝅를 따르는 것을 생각해보는 것.
이런 식으로 행동하는 것에 대한 value는 다음과 같다

argmax는 arguments of max로
여기서는 함수 를 최대로 만드는 s, a를 찾고자한다
여기서 를 계산 가능한 형태로 풀어서 쓰면 아래와 같다
는 transition probability 를 의미한다
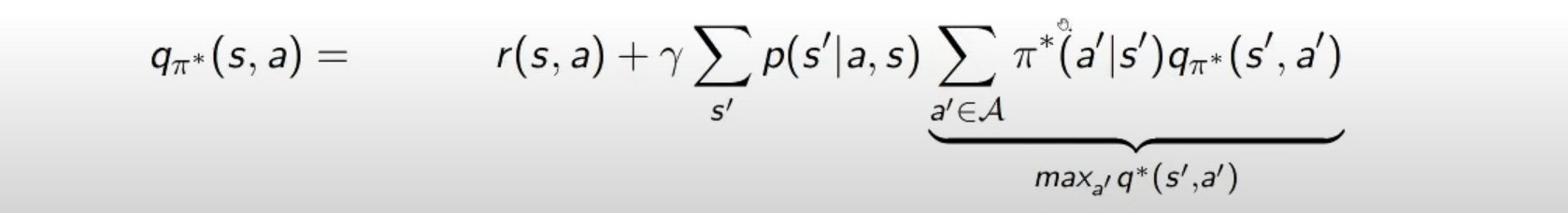
이 값이 보다 큰 지 작은 지를 판단하는 것이 핵심이다

만약 더 크다면,
즉 state s에서 action a를 한 번 선택하고 이후로 policy 𝝅를 따르는 것이
항상 policy 𝝅를 따르는 것보다 더 좋다는 것.
이 때는
state s에 놓일 때마다 action a를 선택하는 것이
여전히 더 좋은 선택이며
이 새로운 policy가 사실은
전반적으로 더 좋은 결과를 가져올 것이라고 기대하는 방법이 바로
policy improvement이다.
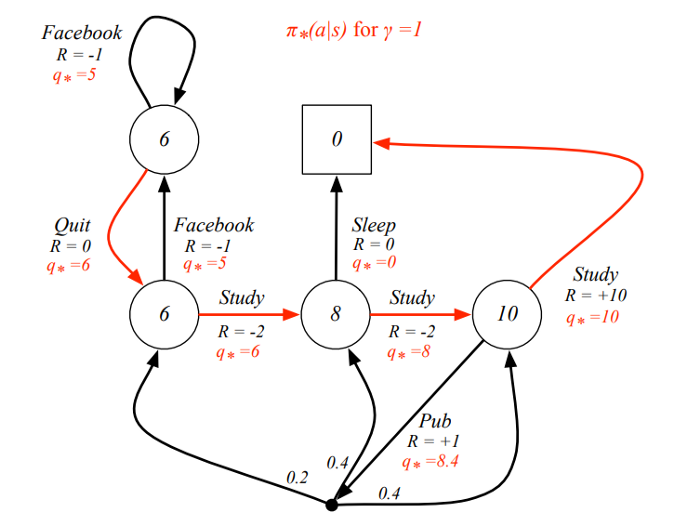
예시
여기서 빨간색 화살표는 optimal policy를 의미하며
agent가 이를 따라가면 maximum reward를 얻을 수 있다
각 state마다 있는 는
해당 action을 하였을 때 취하게 되는 maximum reward를 의미한다
보시다시피
optimal policy는
각 state에서 취할 수 있는 action 중에서
q value (state-action value function)가
높은 action을 행하고 있다
Value Iteration
policy iteration에서
매 주기마다 policy evalutation을 수행하려면
state 집합 전체 요소에 대해 일일이 계산을 한 번씩 수행해야하기에
오래 걸린다는 단점이 있다.
그래서 정확한 값으로 수렴할 때까지 기다리지 않고
중간에 멈추고 짧게 끝낼 필요성이 생겼다
즉, policy iteration의 수렴성은 보장되면서
중간에 중단해도 되는 방법을 찾아야 한다
이를 위해 value iteration을 도입한다
policy evalutation이 오직 한 번의 일괄 계산 이후에
(== 각 state를 한 번 갱신한 이후)
value function의 변화량을 계산해보고
그 변화량이 아주 작은 값 이내로 들어오면 반복을 멈춘다
policy iteration에서
policy evalutation에 k=1 step만 취했을 때
policy iteration == value iteration이 된다
아래는
policy improvement와
truncated policy evaluation을 결합한 알고리즘이다
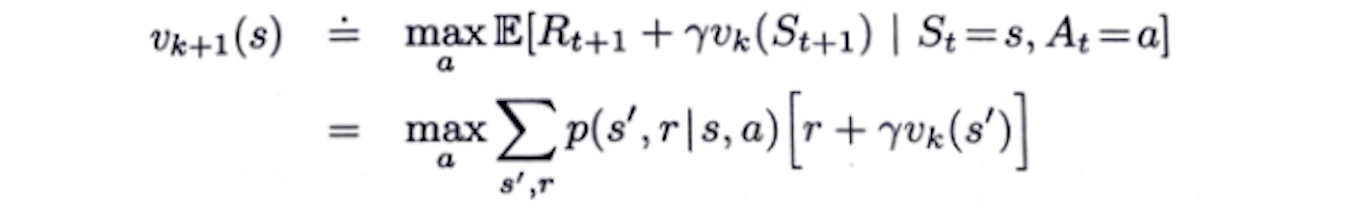

예시
이전의 환경과 동일한 환경에서
value iteration을 적용하면 다음과 같다
-
- =
- 시작점 g와 맞닿은 state의 경우 :
- 그 외의 state :
- 시작점 g와 맞닿은 state의 경우 :
과 는 확연히 값들이 상충된다
그에 반해 과 은 비슷한 양상을 보인다
이렇게 계속 진행하다가 과 가 거의 일치할 때 그만둔다
출처
