최근 DB에 대한 공부를 진행하면서 JPA-DB 양쪽 도메인에 대한 지식 수준을 맞추는 것이 중요하다고 느꼈다. 관계형 데이터베이스와 객체지향 프로그래밍의 패러다임 차이는 분명하고, 두 패러다임 각각 장단점이 뚜렷하기 때문에 이를 절충할 수 있는 JPA에 대한 공부 또한 중요하다고 생각한다.
이번 포스팅에서는 부분범위 처리에 대해 알아보고, JPA에서 적용하는 방법에 대해 알아보고자 한다.
전체 범위 처리
전체 범위 처리는 테이블을 풀 스캔하여 필요한 Size 만큼의 데이터를 전송하는 것을 말한다.
도메인 모델과 실습 데이터는 이 포스팅에서 생성한 것을 사용하겠다.
SQL
SELECT * FROM COMMENT
ORDER BY createdAt DESC;
LIMIT 10;
/* 2000000 rows */
/* actual time=1173.309..1259.763 */
위 쿼리는 가장 최근 댓글 10개를 SELECT하는 쿼리이다.
createdAt 컬럼의 인덱스가 없을 경우, DB는 전체 테이블을 스캔한 다음 정렬 작업이 완료되어야 최종 결과 집합을 내놓을 수 있다.
JPA - findAll
테스트 실행 환경
- 총 메모리 : 512MB
- 테스트 이전 힙 영역 : 153MB
- 사용 가능 힙 영역 : 약 82MB
실행 쿼리 및 결과
실행시간
2023-12-17T21:47:15.527+09:00 INFO 7682 --- [ Test worker] i.StatisticalLoggingSessionEventListener : Session Metrics {
4121959 nanoseconds spent acquiring 1 JDBC connections;
0 nanoseconds spent releasing 0 JDBC connections;
6987625 nanoseconds spent preparing 1 JDBC statements;
1913913250 nanoseconds spent executing 1 JDBC statements;
0 nanoseconds spent executing 0 JDBC batches;
0 nanoseconds spent performing 0 L2C puts;
0 nanoseconds spent performing 0 L2C hits;
0 nanoseconds spent performing 0 L2C misses;
0 nanoseconds spent executing 0 flushes (flushing a total of 0 entities and 0 collections);
168708 nanoseconds spent executing 1 partial-flushes (flushing a total of 0 entities and 0 collections)
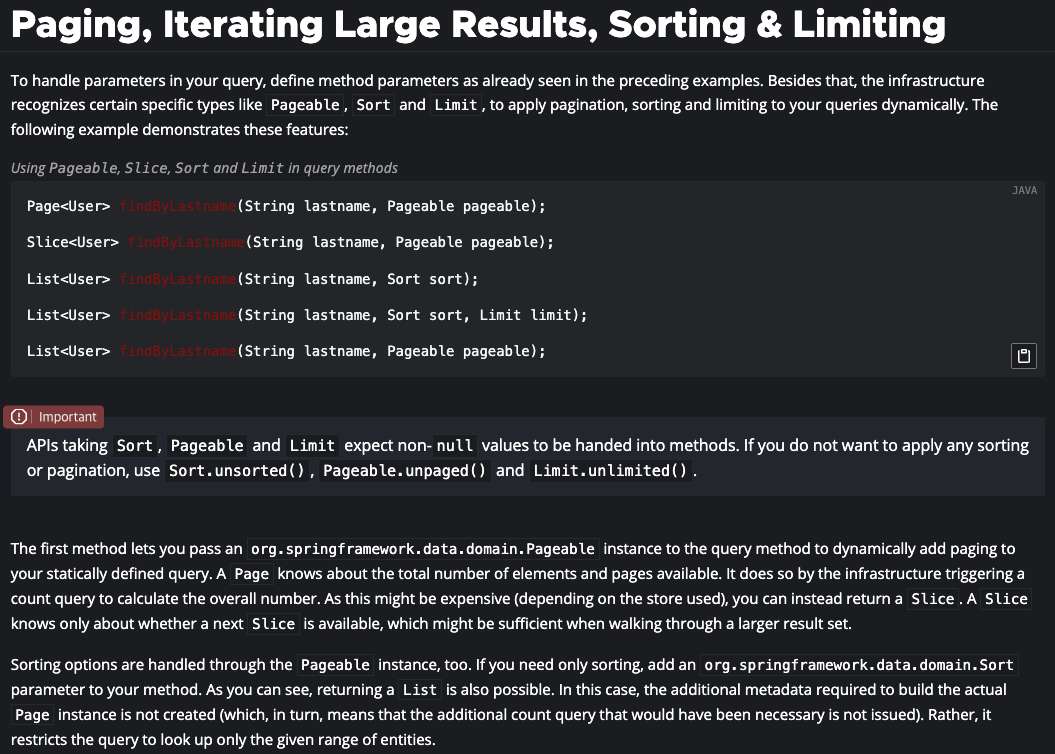
}JpaRepository를 상속한 CommentRepository의 findAll메서드를 실행하여 발생하는 쿼리를 로깅하는 테스트 결과다. 뒤에 설명할 Pageable, Page, Slice 없이 List 타입으로 findAll() 메소드를 사용했다.
그 결과, 힙 영역이 터져서 RuntimeException이 발생했다. COMMENT 테이블의 총 크기가 250MB 정도이기 때문에 어느정도 예상되는 상황이었다.
그래서 findAll은 신중하게 사용해야한다. 작은 테이블일 경우 모든 DB에서 처리하는 것보다 서버에서 작업을 처리하는게 효율적일 수도 있지만, 아닐 경우에는 자원의 낭비가 될 가능성이 크다. 개인적으로 JPA의 안티패턴 중에 하나라고 생각한다.
요구사항에 따라 다르겠지만, 서버에서 다량의 데이터를 한 번에 메모리로 적재해서 처리하는 방식은 여러모로 좋아 보이지는 않는다. 이를 회피하기 위해서는 부분 범위 처리를 알아야 한다.
부분범위 처리
부분범위 처리는 조건을 만족하는 Row 수가 정해둔 Size만큼 검색될 경우, 곧바로 결과를 보내는 것을 말한다.
공부를 하면서 부분범위 처리라는 말이 굉장히 애매했는데, 서버와 DB 각각의 입장에서 애매한 부분이 존재했다. 본 포스팅의 기반이 되는 이 책에서도 클라이언트 - WAS - DB의 N-tier 아키텍처의 경우, DB 커넥션 공유 문제로 인해 부분범위 처리가 어려울 것이라고 말하고 있다.
그래서 개인적으로 부분범위 처리는, 테이블 내 데이터를 모두 읽을 필요 없이, 즉, 앞쪽 일부만 출력하고 멈출 수 있는지가 핵심이라고 이해했다. 반드시 DB가 탐색 대상을 모두 탐색하지 않은 상태에서 데이터를 전송하는 것이 부분범위 처리가 아니라면, JPA도 인덱싱이나 적절한 쿼리를 통해 내가 이해한 부분범위 처리를 수행할 수 있기 때문이다.
DBMS(MySQL)
위 쿼리를 부분 범위 처리하기 위해서 쿼리의 관점에서 가능한 방법은 인덱싱이 가장 먼저 떠오른다.
CASE 1
CREATE INDEX idx_created_at ON Comment(createdAt);
SELECT * FROM COMMENT
ORDER BY createdAt DESC;
LIMIT 10;createdAt 컬럼의 인덱스를 생성하면 부분 범위 처리가 가능해진다. 인덱스는 해당 컬럼의 값에 따라 정렬된 상태로 인덱스 트리의 리프 노드에 저장이 되기 때문에, 해당 인덱스를 활용하여 ORDER BY를 해도 정렬 작업이 발생하지 않는다.
이 경우 LIMIT 10과 같은 조건이 붙어도 인덱스 순서대로 10개의 레코드만 읽으면 되기 때문에 전체범위를 처리할 필요가 없다.
CASE 2
SELECT * FROM COMMENT;
/* actual time : 762ms */
/* rows : 2000000 */
전체 레코드를 SELECT하는 간단한 쿼리다. 전체 테이블을 스캔 한 다음, 스캔한 순서대로 레코드를 반환한다. 하지만 DBMS는 200만 건을 스캔하기 전까지 기다리는 것이 아니라, 일정 Size에 도달하면 스캔한 row들을 순서대로 전송할 수 있다. 다만, 이는 DBMS와 서버 로직에 따라 다를 수 있다.
JPA
JPA를 활용해서 부분범위를 처리하는 방법은 다양하다.

위 표에서 Amount of Data Fetched라는 열에 주목해보자. JPA는 반환 타입에 따라 Fetch 전략이 다른 것을 알 수 있다. 이 Fetch 전략은 서버 메모리에 어떻게 데이터를 로드하는지에 대한 내용이고, JPA 입장에서 부분범위 처리에 관여할 수 있는 방법은 JPA의 구현체가 어떤 쿼리를 실행하냐에 달려있다.
List,Streamable: 전체 데이터셋을 한 번에 쿼리 -> 메모리에 로드 (time-intensive)Stream,Flux: 청크 사이즈 나눠서 데이터를 로드,Stream,Flux의 데이터 소비에 따라 커서가 DB에서 데이터를 Fetching 해오는 방식.Slice: Pageable.getPageSize() + 1만큼 로드, Pageable.getOffset()에서 시작.Page: Pageable.getPageSize()만큼 로드, Pageable.getOffset()에서 시작.
또한 Slice와 Page는 Offset 기반 쿼리이기 때문에 부분범위 처리가 어느정도 가능하다.
Pageable
페이지네이션을 구현하기 위해서 많이 사용되는 인터페이스이다. 페이지 번호, 페이지 크기, 정렬 방향을 캡슐화한 객체이다. 이를 통해 사용자는, 원하는 페이지 번호, 페이지 사이즈, 정렬 여부 및 방향 만 입력하면 페이징을 구현할 수 있다. 또한, 동적 쿼리도 구현이 가능하고 JpaRepository 메서드의 파라미터로 활용된다.
ex) findById(Long id, Pageable pageable)
Page, Slice, List의 경우 Pageable로 부분범위 처리가 가능하다.
Page와 Slice의 경우, 메타데이터에 대한 생성 여부에서 차이가 있다. 가령 총 페이지 수를 Page같은 경우 포함하고 있는데 이를 위해 COUNT문이 실행이 된다. 따라서 대규모 테이블일수록 Slice가 유리하다.
하지만, 둘 다 반쪽짜리 부분범위 처리라고 할 수 있다. Page의 경우 COUNT문까지 실행되기 때문에 부분범위 처리라고 보기에도 애매할 수 있다.
마무리
RDBMS의 관점에서 말하는 부분범위 처리와 코드 레벨에서 조절할 수있는 부분범위 처리는 적용할 수 있는 영역이 달라보인다. 웹 애플리케이션 입장에서는 DB가 어떤 식으로 데이터를 가져오는지 알 수 없다. 다만 JPA 구현체인 Hibernate가 DB로부터 전송받은 데이터를 메모리에 어떤 식으로 데이터를 로드하는지에 대한 구현은 처리할 수 있다. 또한 코드 레벨에서도 부분범위 처리를 위한 쿼리는 작성할 수 있기 때문에 부분범위 처리에 대한 개념을 알고, 이를 적절히 기술에 녹여낼 수 있으면 좋을 것 같다.
테스트
Page vs Slice
Page
코드
CommentRepository에 findAll 메소드를 다음과 같이 작성한다.
Page<Comment> findAll(Pageable pageable);테스트 코드로 실행 로그를 살펴보자.
@Test
@Transactional(readOnly = true)
void findAll_With_Page_Logging(){
//given
int testSize = 10;
int testPage = 1;
//when
Page<Comment> comments = commentRepository.findAll(PageRequest.of(testPage, testSize));
//then
assertThat(comments.getContent().size()).isEqualTo(testSize);
assertThat(comments.getNumber()).isEqualTo(testPage);
}로그
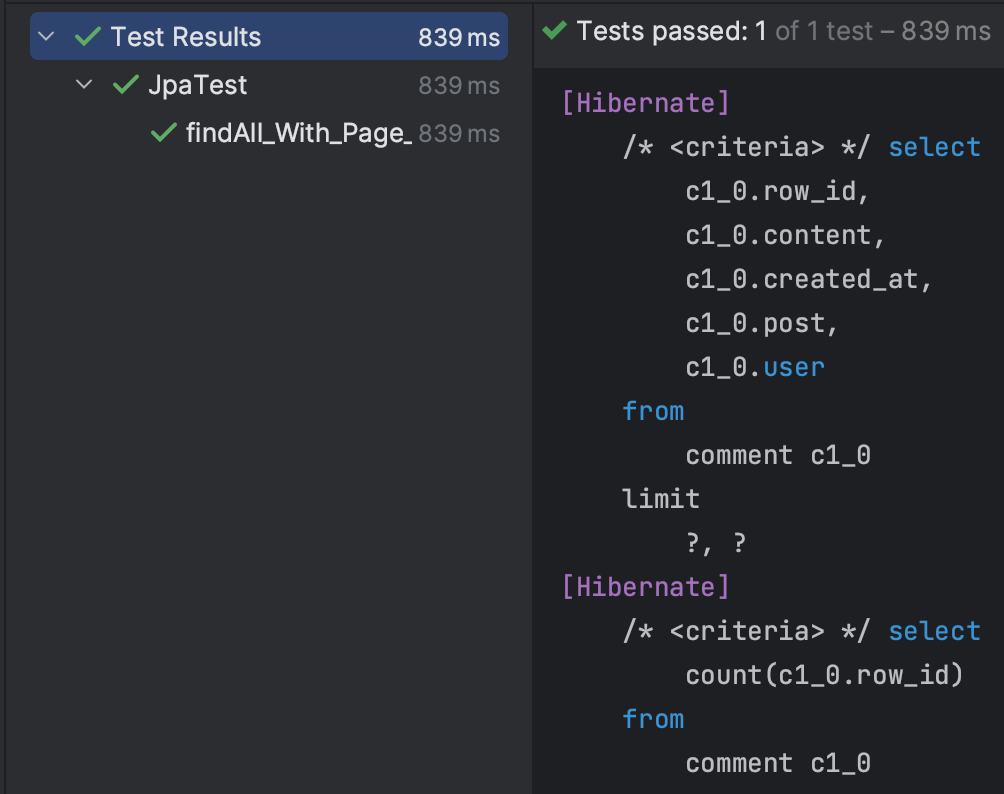
SQL은 예상한대로 COUNT문이 실행되었다. limit 조건에 들어갈 Offset과 결과 개수는 ?, ?라고 나와있는데, 하이버네이트가 Pageable 인터페이스를 통해 입력받은 값을 자동으로 바인딩한다. 이번 테스트 코드에서는 10, 10이 되겠다.

실행한 쿼리가 두 개(COUNT까지)이기 때문에, 2 JDBC statements가 준비되어 실행된 것을 확인할 수 있다. 시간은 약 0.06초 정도가 걸렸다.
Page
코드
findAll 메서드의 반환 타입을 Slice로 지정할 경우, JpaRepository의 findAll메서드와 타입 충돌이 일어나게 된다. 따라서 Slice용 findAll메서드를 재정의 해줘야한다.
Slice<Comment> findCommentsBy(Pageable pageable);나는 이런 식으로 작성했다. 테스트 코드는 Page때 작성했던 것과 동일하게 작성해주었다.
@Test
@Transactional(readOnly = true)
void findAllWithSlice(){
//given
int testSize = 10;
int testPage = 1;
//when
Slice<Comment> comments = commentRepository.findCommentsBy(PageRequest.of(testPage, testSize));
//then
assertThat(comments.getContent().size()).isEqualTo(testSize);
assertThat(comments.getNumber()).isEqualTo(testPage);
}로그
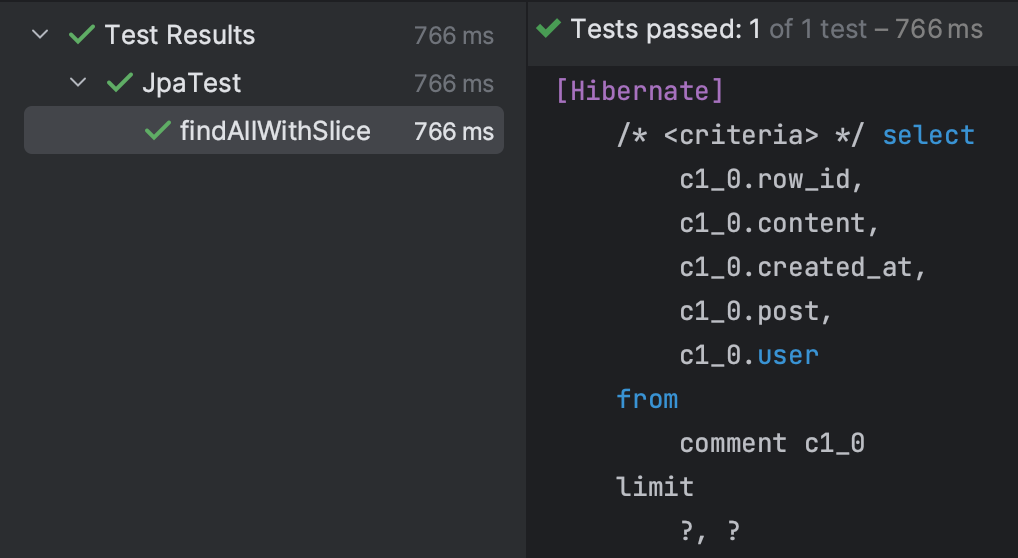
Page와 마찬가지로 Offset 기반 페이지네이션 쿼리가 실행되는 것을 확인할 수 있다. 하지만, Page때와는 다르게 COUNT문이 실행되지 않는다.

실행시간을 살펴보면 차이가 확실하게 보인다. 쿼리 실행 준비 + 실행 시간이 0.0093초로 이는 Page와 비교했을 때 약 6.5배 빠르다.
Stream
코드
@Query("SELECT c FROM Comment c")
Stream<Comment> streamAllComments();CommentRepository에 위와 같은 메서드를 선언한 다음, Stream 타입으로 반환할 경우, 어떤 식으로 데이터를 로드하는지 테스트한다.
@Test
@Transactional(readOnly = true)
void testStreamLoading(){
Stream<Comment> comments = commentRepository.streamAllComments();
try {
for (Comment comment : (Iterable<Comment>) comments::iterator) {
if (comment.getRowId() == 100) {
break; // rowId가 100이면 반복 중단
}
System.out.println("처리 중인 댓글: " + comment.getRowId());
}
} finally {
comments.close(); // 스트림 닫기
}
}테스트 결과 및 JDBC 실행 정보
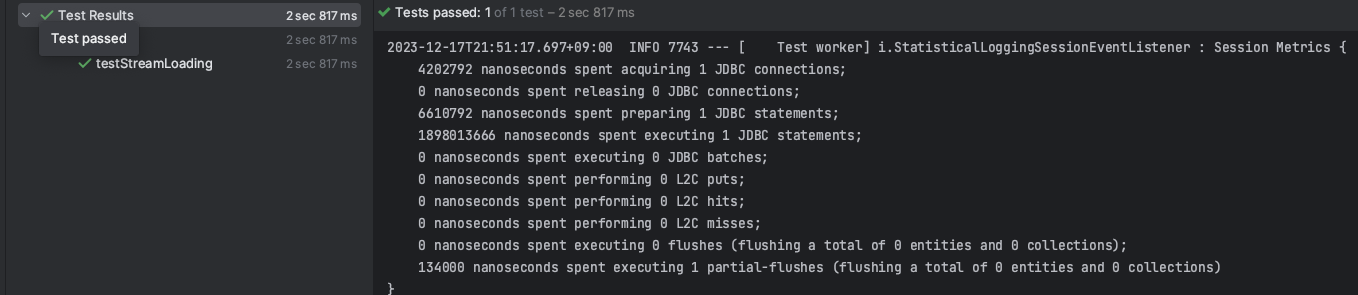
모든 데이터를 로드하지 않고, 커서가 필요한 만큼 Fetching하고 있기 때문에 메모리가 터지지 않는다. try-with-resources 구문으로 인해 Stream이 닫히면서, 테스트도 성공하고 있는데 Stream 고수들은 JPA를 더 다양하게 사용할 수 있을지도 모른다는 생각이 들었다.
참고
