Springboot
1.Springboot/ ThreadLocal

쓰래드 로컬을 알고있어야 하는 이유중 하나는 동시성 문제이다.동시성 문제?첫호출작업이 끝나기도 전에 동시에 다발적으로 호출하게되면 로그가 분리되지않고 떡져서 출력된다. 즉 어떠한 작업을 수행하는 스레드의 트랜젝션이 보장이 되지 않는것이다.이런 동시성 문제는 여러 쓰레드
2.Springboot/탬플릿 메서드 패턴
핵심기능 : 해당객체가 제공하는 고유의 기능부가기능 : 핵심기능을 보조하기 위해 제공되는 기능. 로그추적, 트랜잭션기능등등... 좋은 설계는 변하는 것과 변하지 않는 것을 분리하는것이다핵심기능은 변하고 부가기능은 대게 고정돼 있다. 이 둘을 분리해서 모듈화 해야한다.템
3.java리플렉션
자바가 기본으로 제공하는 JDK동적 프록시 기술이나 CGLIB같은 프록시 생성 오픈소스 기술을활용하면프록시 객체를 동적으로 만들어 낼 수 있다.리플랙션 기술을 사용하면 클래스나 메서드의 메타정보를 동적으로 획등하고 코드도 동적으로 호출 할 수 있다. 정적인 코드를 리
4.JDK동적프록시/CGLIB
프록시패턴을 적용하기 위해서는 저거용대상의 숫자만큼 많은 프록시 클래스를 만들어야 했다.프록시의 로직은 같은데 적용 대상만 차이가 있는것이다.이 문제를 해결해 주는 것이 동적 프록시 기술이다.동적 프록시 기술을 사용하면 개발자가 직접 프록시 클래스를 만들지 않아도 된다
5.Springboot프록시 팩토리
동적 프록시의 문제점인터페이스가 있는경우에는 JDK동적 프록시를 적용하고 그렇지 않은 경우에 CGLIB를 적용하려면 어떻게 해야할까?동시에 사용하는 경우에는 중복으로 만들어서 관리해야하나?특정 조건에 맞을때 프록시 로직을 적용하는 기능도 공통으로 제공되었으면스프링은 동
6.Springboot 빈 후처리기
@Bean이나 컨포넌트 스캔으로 스프링빈을 등록하면, 스프링은 대상객체를 생성하고 스프링 컨테이너 내부의 빈 저장소에 등록을 한다.그리고 이후에는 스프링 컨테이너를 통해 등록한 스프링빈을 조회해서 사용하면 된다.스프링이 빈 저장소에 등록할 목적으로 생성한 객체를 빈 저
7.@Aspect Springboot AOP 시작
스프링 애플리케이션에 프록시를 적용하려면 포인트컷과 어드바이스로 구성되어 있는 어드바이저를 만들어서 스프링빈으로 등록하면된다.그러면 나머지는 아ㅠ서 배운 자동 프록시 생성기가 모두 자동으로 처리해준다. 자동 프록시 생성기는 스프링 빈으로 등록된 어드바이저들을 찾고스프링
8.Spring Data REST
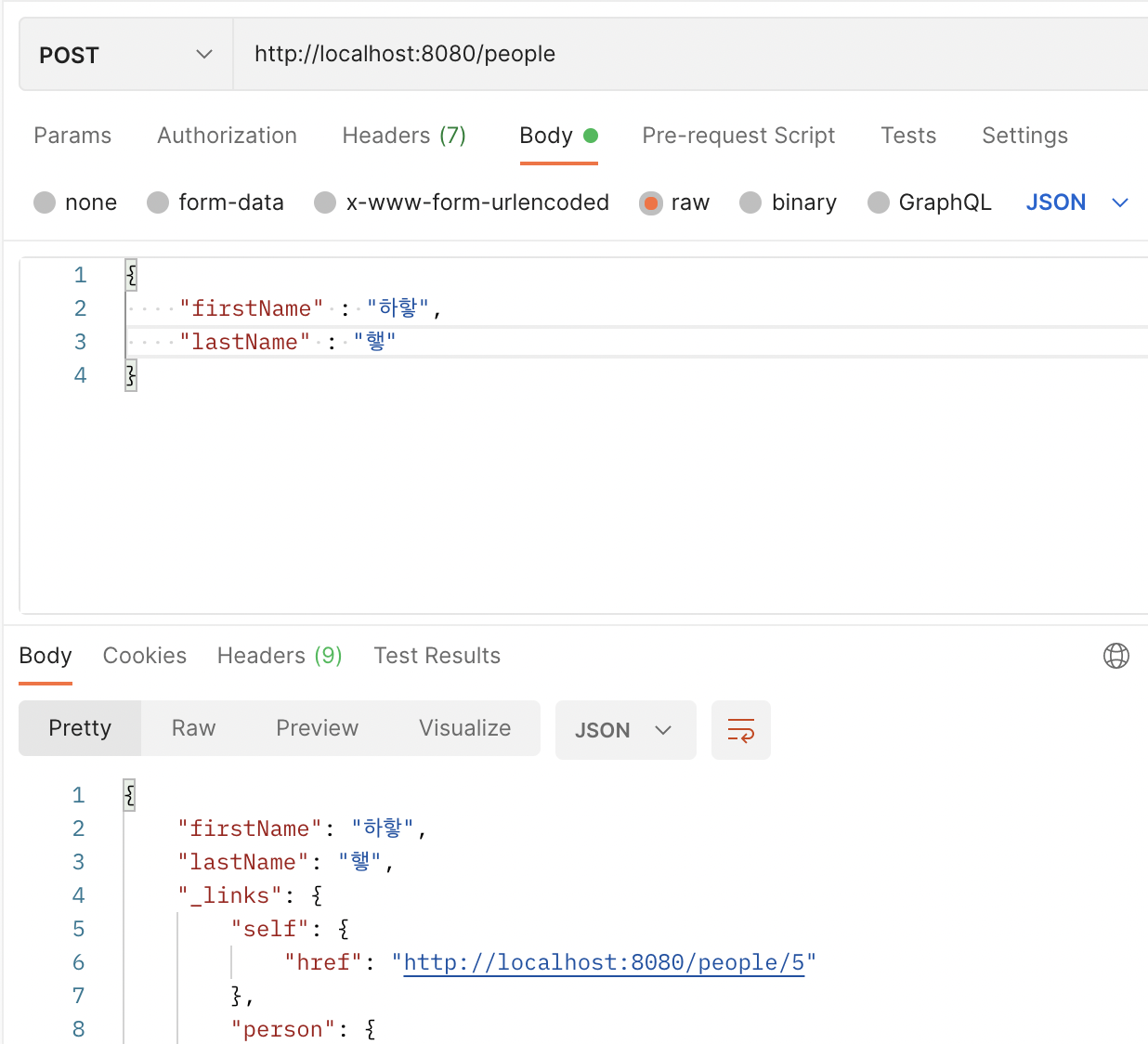
RESTFul 웹서비스는 HTTP Method를 통해 해당 자원에 대한 CRUD Operation을 적용하는 것을 의미합니다.기존에 Spring web을 사용하면 @RestController로 컨트롤러를 작성해서 사용해야하지만 Spring Data REST를 사용하면
9.Spring boot AOP
Springboot AOP AOP - 핵심 기능과 부가기능 애플리케이션 로직은 크게 핵심기능과 부가 기능으로 나눌 수 있다. 핵심기능은 해당 객체가 제공하는 고유의 기능이다. 부가기능은 핵심기능을 보자하기위해 제공되는기능이다.(로구추적기 등등..) 위 기능들이 하나
10.@Transactional원리
spring에서 디비접근시에 트랜잭션을 관리하는 방법은 아주 추상화가 잘 돼 있습니다. 바로 @Transactional 을 사용해주면 트랜잭션이 되기 때문입니다.이 마법의 내부를 공부해 봤습니다.데이터베이스 커넥션자바에서 데이터 베이스의 트랜잭션을 시작하는 유일한 방법
11.@Deprecated와 @deprecated
@Deprecated는 타입,필드,메소드등에 붙일수 있고 @Deprecated 표시되어 있는 메소드나 필드를 사용하면 빌드할 때 워닝메시지를 보여준다. 이 메소드는 없어질걸 알려주고 쓰지말라고 경고하는것@deprecated는 javadoc으로 이 메소드가 사라지는 이유
12.Springboot JUnit and Mockito
java 진영의 대표적인 test Framework단위 테스트를 위한 도구를 제공단위 테스트란?코드의 특정 모듈이 의도된 대로 동작하는지 테스트 하는 절차를 의미모든 함수와 메소드에 대한 각가의 테스트 케이스를 작성하는것어노테이션을 기반으로 테스트를 지원단정문으로 테스
13.JPA 복합키 작성기초
클라이언트 쪽에서 복합키의 정보를 모두 알지 않아도 간편하게 리소스 관리가 가능함 (ex: 책ID, 사용자ID)데이터를 식별할 수 있는 컬럼의 조합이 유니크하지 않을 때 (ex: 이름+저자+출판사로는 책 식별 불가할 수 있음. 동일한 명칭의 개정판이 나오기 때문)식별가
14.Spring boot-Cache Control Headers 하는법

요청 데이터가 무겁지만 변경이 잘 없는 데이터는 Headers에 케시컨트롤을 통해서 사용자와 서버가 서로 윈윈할수 있는 방법이 있다. 한번 최초 요청시에 request 요청이 캐싱돼서 이후 제요청시에는 http 통신을 하지 않고 클라이언트쪽에서 바로 캐싱돼서 데이터를
15.Springboot DataJPA 선택적으로 수정하기
프로그램을 작성하다보면 이런경우가 있다.dto로 작성된 필드가 있을수도 있고 없을수도 있는 상황에서 해당필드값들을 선택적으로 업데이트하고 만약에 값이 들어와 있지 않다면 그대로 값을 두는것이다.하지만 스프링에서 기존에 기본형태로 업데이트를 하는 방법은 Entity 객체
16.select시 update쿼리 날라갈때
가변 객체 을 Entity 필드로 사용해야할 경우 (@Convert) 무분별한 Dirty Checking을 막기 위해 equals를 꼭 Override 해야한다.그렇지 않을 경우 단순히 조회 로직에서도 Dirty Checking이 발생한다
17.DB 커넥션풀
db가 커넥션을 할때의 과정1\. 애플리케이션 로직이 db드라이버를 통해 커넥션을 조회한다.2\. db드라이버는 db와 tcp/ip 커넥션 연결을 한다.3\. db 드라이버는 id,pw와 기타 부가 정보를 db에 전달한다.4\. db는 id,pw를 통해 내부인증을 완료
18.Data Source 이해
커넥션을 얻는 방법은 JDBC 드라이버 매니저를 통해 획득하던지 커넥션 풀로 접근하는 두가지 방법이 있다. 전반적인 코드 변경이 일어난다.위 문제를 해결하기위해서 추상화를 해놨는데DaraSource를 통해 커넥션을 획득하는 방법을 추상화 해놓은 인터페이스가 있다.대부분
19.JPA /save , saveAll 사용시 주의 사항들
한 번에 많은 데이터를 데이터베이스에 저장하려고 할 때 일반적으로 데이터 하나당 insert를 날리는 것보다 값들을 묶어서 batch insert하는 경우가 더 성능이 좋다.그래서 흔히 사용하는 방법이 SaveAll을 사용하는데 해당 함수의 내부를 잘 모르고 사용하면
20.Thread starvation or clock leap detected, Dead Lock, hikari 오류 해결
CPU에 우리 스프링 프로젝트의 Thread들이 올라가서 작업을 하게 되고, 그러다 한 Thread내의 별도 Transaction에서 추가적인 SQL문 실행이 필요해지면서Thread가 Connection을 더 필요로 하는 상황이 생겼다. 우리 스프링 부트 프로젝트에서
21.Spring boot docker image로 배포시 타임존 설정 방법
해당 설정 추가\-Duser.timezone=Asia/Seoul 설정 추가
22.java 이미지 포맷 변환 / png to jpg
자바에서는 imageIO 클래스를 이용해 이미지를 컨트롤 할 수 있다.1\. 사용자가 파일 저장2\. 서버단에서 파일 전송 후 png 파일인 경우 파일 포맷을 변경3\. 변환된 jpg 파일 저장read 로 생성된 file 인스턴스로부터 이미지를 읽거나 지정된 Url을
23.SpringBoot/한글파일(.hwp) 데이터 바인딩 후 다운로드 하기
제가 하는 프로젝트에서 받은 요구사항이 자동으로 문서를 생성하고 다운로드까지 제공해야하는 요구사항이 있었습니다.한글 파일에 데이터 바인딩문서를 생성(다운로드)위와같은 절차를 거쳐야 하기 때문에 일반적인 static 파일을 view로 보여주는 요구사항과 비슷해보지만 정말
24.JPA CascadeType 종류와 부모 테이블 삭제
Cascade는 사전적의미로 종속, 계산식 폭포 등의 의미를 품고 있다. 이름에서 알수 있듯이 db 관계를 맺고 있는 테이블끼리 cascade를 한다는건 상위 테이블을 삭제하면 관계맺은 하위 테이블 까지 튜플이 같이 삭제된다는 뜻이 된다.JPA 라는 ORM 에서 Cas
25.Springboot + prometheus + grafana 모니터링 시스템 구축
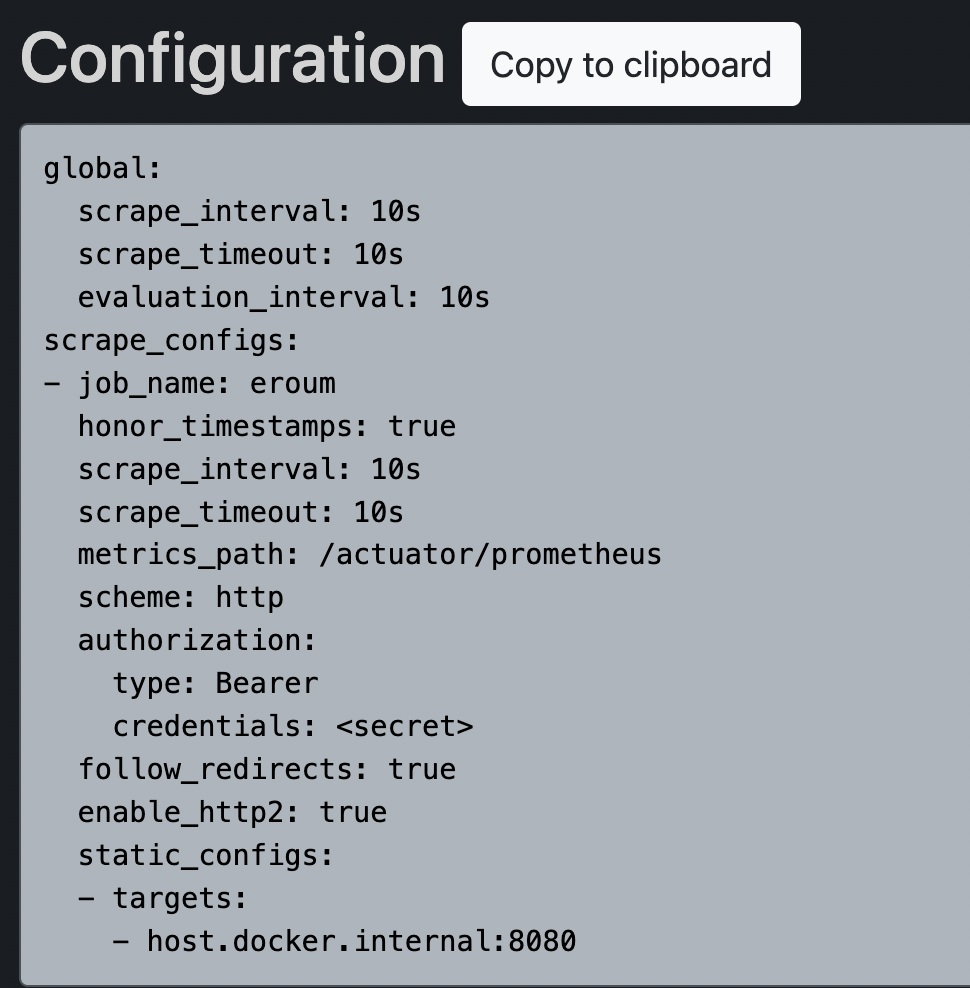
위 설정을 해주고 엔트포인트로 /actuator 로 접속되면 application/json+hal 타입에 해당 주소와 연관된 주소 리스트가 다음과 같이 나온다. 그리고 해당 리소스로 들어가면 실시간 어플리케이션 정보를 볼 수 있다.어플리케이션의 모든 정보를 공개하는것은
26.Grafana 활용기(Spring Boot)
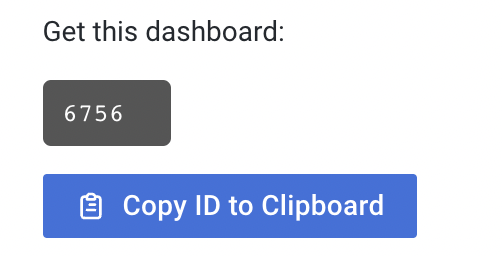
애플리케이션과 연동하는것은 이글에서 다루지 않겠습니다.그라파나를 쓰면서 느낀점들이나 알게된점들을 정리하는 글 입니다.https://grafana.com/grafana/dashboards/6756위 사이트로 들어가면 다음과 같은 id 또는 JSON 파일을 다운로
27.spring boot logback으로 error 로그만 파일로 남기기

해당 라이브러리는 spring-web에 들어있기때문에 따로 의존성을 설정해 둘 필요는 없습니다.property : xml 에서 사용할 변수값 선언appender : 기능단위 자바로치면 method 격이라고 생각하면됩니다.위 설정파일에서는 Console이라는 append
28.springboot + fluentd + mongoDB 연동
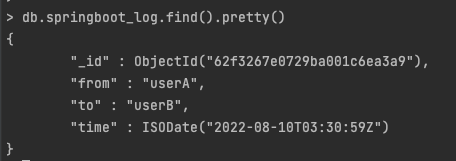
흔히 아는 ELK에 로그스테시와 같이 로그를 저장소에 적제하거나 필터링하고 어딘가로 전송해주는 큐 역할을 하는 툴입니다.해당 글에선 docker를 사용해서 할 예정입니다.fluent-plugin-mongo 여기서 해당 fluentd에는 몽고디비와 연결할수 있는 플러그인
29.Spring boot Static 필드에 @Value 사용
Static 필드에 @Value 값은 바인딩 될 수 없습니다. 정확한 이유는 잘 모르지만 제 생각엔 java에서 가장 먼저 jvm 이 가장 먼저 메모리에 띄우는 것들이 static 인데 메모리에 이미 올라간 상태로 @Value 로 바인딩하려니 안되는 것 같습니다. 쉽게
30.SpringBoot/java POI 이용해서 엑샐 생성하기
아파치에서 만든 java로 엑셀을 핸들링할 수 있게 해주는 라이브러리 입니다.기본 적인 사용법은 간단합니다.용어workbook하나의 엑셀파일을 의미합니다.가장 큰 단위로 생각 하면 됩니다.sheetsheet는 말그대로 엑셀 시트를 생성해 주는 것 입니다.Sheet sh
31.[JPA] @GeneratedValue의 Auto_increment 미적용 될때
a테이블과 b테이블을 각각 save를 사용해서 insert 하게되면 id값이 합쳐서 올라가는 현상이 있습니다.@GeneratedValue를 사용하면 default값으로 AUTO가 적용되고, AUTO는 IDENTITY를 기본으로 사용한다고 알고 있었는데, 실제로 적용되는
32.SpringSecurity 에서 WebSecurityConfigurerAdapter 가 deprecated됐다...

기존에 다음과같이 상속을 받아서 오버라이드하는 방식으로 구현돼 있었다.근데 이제 springboot가 2.7이 되고 시큐리티또한 버전업이되면서 변경사항이 많이 생겼다.바뀐 코드DaoAuthenticationProvider에 대한 설명UserDetails 는 UserDe
33.spring data jpa @Modifying

@Query 애노테이션을 사용하면서 데이터에 변경이 일어나는 INSERT, UPDATE, DELETE, DDL 에서 사용합니다. 주로 벌크 연산 시에 사용됩니다.벌크연산을 할 때는 JPA Entity LifeCycle을 무시하고 쿼리가 실행되기 때문에 해당 애노테이션을
34.스프링 db 트랜잭션
데이터를 저장할때 단순히 파일에 저장해도 되는데 데이터베이스에 저장하는 이유중 가장 대표적인 이유는 바로 데이터베이스는 트랜잭션이라는 개념을 지원하기 때문트랜잭션을 이름 그대로 번역하면 거래라는 뜻이다. 이것을 쉽게 풀어서 이야기하면 데이터 베이스에서 트랜잭션은 하나의
35.스프링 트랜잭션 - 리소스 동기화와 트랜잭션 프로세스
스프링이 제공하는 트렌젝션 매니저는 크게 2가지 역할을 합니다.1\. 트랜잭션 추상화2\. 리소스 동기화기본적으로 모든 db접근기술의 트렌젝션에 대한 코드는 db에 접근하는 방식에 따라 달라질 수 밖에 없습니다.그렇다면 예를 들어 jdbc의 트렌젝션을 사용하여 서비스로
36.Spring boot 백엔드 아키텍쳐 Infra Layer

infra layer는 다른 애플리케이션이나 데이터베이스등 외부 요소와 연결을 수행합니다. 예를들어 db서버와의 연결 Message Queue(kafka, rabbitMQ), 외부 API 요청방식 정의 등이 있습니다.DB로의 요청/응답 처리가장 흔히 사용되는 Jdbc라
37.Bucket4j 기본 개념 (Spring boot Rate Limiter

Token Bucket알고리즘의 아이디어 위에 구현된 rate limit 라이브러리 입니다. io.github.bucket4j.Bucket 인터페이스로 표시 됩니다.Token Bucket 알고리즘은 쉽게 말해서 패킷에 토큰을 심어놨다가 요청이 들어올때마다 하나씩 줄여서
38.CSRF 보호가 작동하는 방식
CSRF 보호가 작동하는 방식을 잘못 이해하면 활성화 해야 하는 시나리오에서 비활성화 하거나 그 반대의 상황이 많이 발생한다.다음과 같은 시나리오로 예를 들 수 있다.사용자가 파일을 관리할수 있기 인증/인가를받고 애플리케이션에 로그인한 상태에서 파일을 관리하기위해 서버
39.Spring boot Aop 사용시 request, response 객체 사용하기
Spring boot Aop 사용시 request, response 객체 사용하기
40.spring data jpa에서 Pk를 UUID로 관리해 보자
uuid와 uuid2의 차이점은 uuid는 RFC 4122 호환안됨 -> warn로그 쌓임BINARY(16)은 저장할 때 남는 길이는 RPAD 처리하고 저장하기때문에 예상치 못한값이 들어가고 조회할 수 없다.(필수설정)기본적으로 아이디 채번방식이 SEQUENCE를 제외
41.Gradle 정리

xml 기반 프로젝트 의존성 관리 도구해당 라이브러리를 사용하기 위한 다른라이브러리까지 저장소에서 다운받아 준다.전체적인 라이프사이클 관리 도구Maven LifecycleClean : 이전 빌드에서 생성된 파일들을 삭제하는 단계Validate : 프로젝트가 올바른지 확