[논문리뷰] Deep Residual Learning for Image Recognition (2016, Kaiming He et al.)
AI 논문리뷰(AI Paper)
Ⅰ. 논문 개요
본 논문은 Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun이 2016년 Microsoft Research에서 발표한 연구로, 딥러닝(Deep Learning) 모델의 심층화로 인한 학습 성능 저하 문제를 해결하기 위해 잔차 학습(Residual Learning) 개념을 제시하였다.
이 모델은 기존보다 훨씬 깊은 네트워크(152층 이상)를 안정적으로 학습시킬 수 있으며, ILSVRC 2015 이미지 분류 대회에서 1위를 차지하였다.
Ⅱ. 연구 배경
당시 딥러닝의 주된 발전은 네트워크의 깊이를 늘려 성능을 향상시키는 방향이었다. 그러나 VGGNet, GoogLeNet 등에서 이미 확인되었듯이, 일정 깊이 이상이 되면 학습이 오히려 어려워지고 정확도가 떨어지는 degradation problem(성능 저하 문제) 이 발생하였다.
이 문제는 단순한 과적합이 아니라, 깊은 신경망이 최적해에 도달하지 못하는 구조적 한계 때문이었다. 저자들은 이 현상을 해결하기 위해, 네트워크가 직접 입력값을 보정하는 형태로 학습하는 ‘잔차 학습(Residual Learning)’ 구조를 도입하였다.
깊어질수록 학습 오차가 커지는 현상 시각화
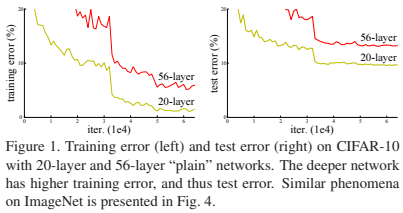
Ⅲ. 핵심 제안 및 구조
본 논문의 핵심 아이디어는 “원래의 목표 함수를 직접 학습하는 대신, 잔차(residual)를 학습한다”는 것이다.
즉, 각 블록이 단순히 ( H(x) )를 학습하는 것이 아니라,
의 형태로 학습하도록 설계하였다.
여기서 ( F(x) )는 학습해야 할 잔차 함수이며, ( x )는 입력값이다. 이 구조를 Residual Block(잔차 블록) 이라 한다.
잔차 블록 구조 요약
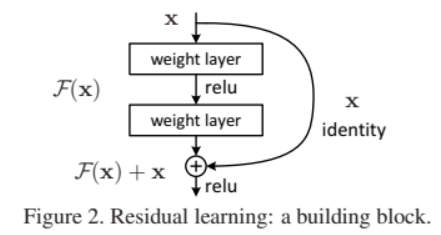
이때 ( F(x) + x )는 shortcut connection(지름길 연결) 을 통해 구현되며, 이는 추가적인 파라미터나 연산 복잡도를 거의 증가시키지 않는다.
저자들은 이 간단한 구조가 기존의 “plain network”보다 훨씬 안정적으로 학습되고, 깊이를 늘릴수록 성능이 개선됨을 실험으로 증명하였다.
ResNet은 크게 두 가지 형태의 블록으로 구성된다.
- Basic Block: 두 개의 3×3 Convolution(합성곱)으로 구성된 단순 구조
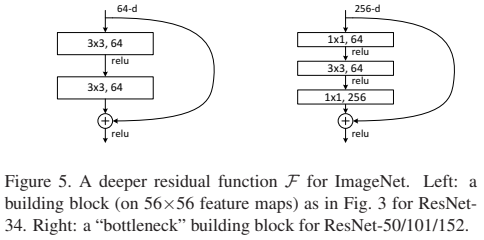
- Bottleneck Block: 1×1 → 3×3 → 1×1 Convolution으로 구성되어, 깊이를 늘리면서도 계산량을 줄이는 구조
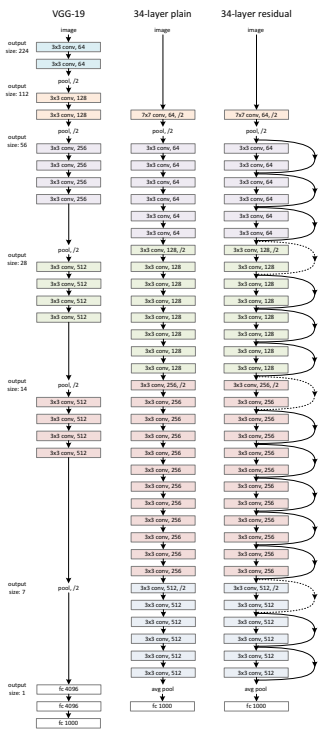
Figure 3. VGG-19, 34-layer plain, 34-layer residual 비교도
1×1 축소·복원으로 효율 확보.
Ⅳ. 주요 실험 및 결과
1. ImageNet 실험
ResNet은 18, 34, 50, 101, 152층 모델로 실험되었다.
- 34층 Plain Network 대비 34층 ResNet은 Top-1 Error 28.54% → 25.03%로 감소하였다.
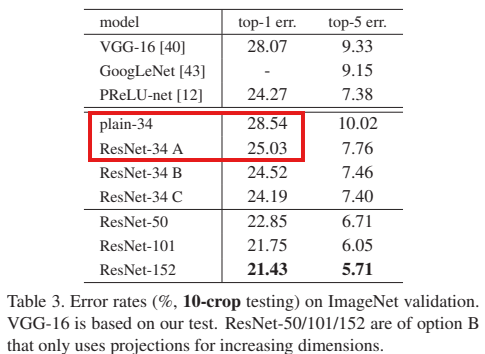
- 152층 모델은 VGG-19보다 깊지만 계산량은 오히려 40% 수준으로 효율적이었다.
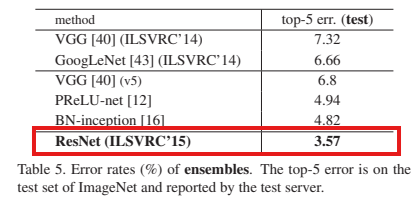
- Ensemble 모델은 Top-5 Error 3.57%로, ILSVRC 2015 1위를 기록하였다.
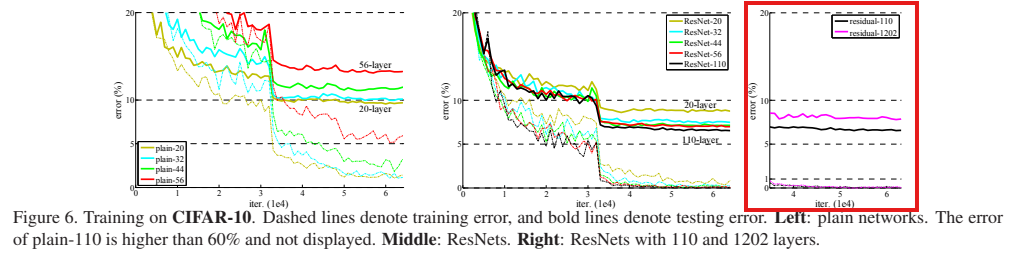
2. CIFAR-10 실험
ResNet은 20~1202층까지 실험되었으며, Plain Network는 깊어질수록 오히려 성능이 저하된 반면, ResNet은 깊어질수록 오류율이 지속적으로 낮아졌다.
특히 110층 ResNet은 6.43%의 테스트 오류율로 당시 최고 수준의 성능을 달성하였다.
최적화 용이성과 오버피팅 징후
3. 전이성 검증 (Object Detection)
ResNet-101은 Faster R-CNN 구조에 적용되어 COCO Dataset에서 27%의 상대적 향상(mAP 기준) 을 달성하였다.
이는 단순 분류뿐 아니라 탐지·분할 등 다양한 비전 과제에서의 일반화 능력을 입증하였다.
백본 교체 효과표. 분류 성능 개선이 다운스트림까지 전파

Ⅴ. 논의 및 한계
의의
ResNet은 딥러닝의 학습 한계를 극복한 대표적 구조로, 이후 DenseNet, EfficientNet, Vision Transformer 등 수많은 모델의 기반이 되었다.
잔차 연결 개념은 “정보의 흐름을 방해하지 않는 신경망 설계”라는 새로운 패러다임을 제시했다.
한계
- 지나치게 깊은 네트워크(예: 1000층 이상)는 CIFAR-10과 같은 소규모 데이터에서는 오히려 과적합(overfitting) 문제가 발생.
- Shortcut이 항상 최적이라는 보장은 없으며, 메모리 사용량 증가 및 병목 구조의 설계 난이도가 존재한다.
Ⅵ. 결론
ResNet은 “더 깊은 신경망이 반드시 더 어렵지 않다”는 사실을 증명한 혁신적 연구이다.
잔차 학습 구조는 이후 거의 모든 비전·자연어 처리 모델의 기본 단위로 자리 잡았으며, 딥러닝의 표준 아키텍처로 확립되었다.
한줄요약
“ResNet은 네트워크가 스스로의 오류(잔차)를 학습하도록 만들어, 딥러닝의 심층화 문제를 해결한 전환점이 되는 논문”
"Deep Residual Learning for Image Recognition" 핵심 단어 정리
| 핵심 단어 (Key Term) | 설명 (Explanation) |
|---|---|
| 잔차 학습 (Residual Learning) | 이전에 사용된 네트워크보다 상당히 깊은 네트워크의 훈련을 용이하게 하기 위해 계층이 잔차 함수 를 학습하도록 명시적으로 재구성하는 프레임워크입니다. |
| 성능 저하 문제 (Degradation Problem) | 네트워크 깊이가 증가함에 따라 정확도가 포화된 후 급격히 저하되는 현상이며, 이는 오버피팅이 아닌 더 높은 훈련 오차로 나타나는 최적화 난이도를 의미합니다. |
| ResNet (잔차 네트워크) | 잔차 학습 프레임워크를 사용하여 구축된 네트워크로, 최적화가 용이하여 깊이가 증가해도 정확도 이득을 얻을 수 있습니다. |
| 숏컷 연결 (Shortcut Connections) | 하나 이상의 레이어를 건너뛰는 연결로, 잔차 학습의 형태인 를 피드포워드 신경망에서 구현하는 방식입니다. |
| 항등 숏컷 (Identity Shortcut) | 숏컷 연결이 단순히 항등 사상 를 수행하는 것으로, 추가 매개변수나 계산 복잡도를 추가하지 않으면서 성능 저하 문제를 해결하기에 충분합니다. |
| 일반 네트워크 (Plain Networks) | 잔차 연결이 없는 기준선(baseline) 네트워크로, 깊이가 증가할 때 (예: 34-레이어) 18-레이어보다 더 높은 훈련 오차를 보여 성능 저하 문제를 겪습니다. |
| 경사 소실/폭발 문제 (Vanishing/Exploding Gradients) | 과거에는 깊은 네트워크의 수렴을 방해하는 문제였으나, 배치 정규화(BN) 및 정규화된 초기화를 통해 이미 대부분 해결되었으며, ResNet이 해결하려는 '성능 저하 문제'와는 별개의 문제입니다. |
| 보틀넥 아키텍처 (Bottleneck Architecture) | 50, 101, 152 레이어와 같이 매우 깊은 ResNet을 위해 사용된 3개의 레이어 스택( 합성곱) 디자인으로, 효율적인 계산을 위해 차원을 줄였다가 복원합니다. |
